大模型应用:TTA文本驱动音频:MusicGen大模型参数调优+音频情绪可视化.23
原创
大模型应用:TTA文本驱动音频:MusicGen大模型参数调优+音频情绪可视化.23
原创
未闻花名
发布于 2026-02-20 10:53:49
发布于 2026-02-20 10:53:49
一、引言
随着语音大模型的普及,不管是TTS还是ASR,都与音频处理有着紧密的联系,AIGC的蓬勃发展,也催生了文本到音频(Text-to-Audio, TTA)的落地场景,音乐生成也走进了我们的实际应用。基于传统的信号合成技术凭借完全可控、轻量化的优势,在场景化音效补充中不可替代;而声乐大模型也是雨后勃发,以 MusicGen 为代表的 TTA 大模型,则通过海量数据训练实现了文本意图驱动的创意生成。
今天我们围绕声音的本质深度解析音频合成的核心逻辑,深度的理解一套融合MusicGen 大模型(创意核心)+ 传统信号合成(场景增强)+ 多维度可视化(效果验证) 的音频生成系统,涵盖模型原理、参数配置、执行流程、结果解读各个环节,从而达到从零掌握可控化、场景化的 AI 音频生成技术。

二、音频合成的核心
在开始讲解模型之前,我们得先拆解原测试音频生成器的核心原理,其实所有生成声音的本质,都是对波形的精准操控。代码能模拟会议和演示语音,关键靠这 4 个核心技术,也是我们后续生成优美音乐的基础:
1. 声音的本质
核心本质是频率、振幅与波形,声音是机械波的传播,我们听到的音调由频率决定,单位Hz:
- 低频(50-200Hz):低沉、厚重(如大提琴、男生语音)
- 中频(200-2000Hz):人声主导、清晰(如女生语音、钢琴中音区)
- 高频(2000Hz 以上):明亮、尖锐(如小提琴、鸟鸣、键盘敲击声)
- 振幅则决定音量大小,波形的高低。
正弦波是最基础的纯音,但真实声音或音乐不会是单一正弦波,而是由基频和谐波共同组成,比如钢琴的声音需要“基频 + 2 倍频 + 3 倍频 +...”共同组成。
2. ADSR 包络
让声音有呼吸感的关键,为什么同样是 100Hz 的频率,钢琴和小提琴的声音完全不同?核心在于ADSR 包络,模拟声音从“发声”到“消失”的生命周期:
- A(Attack)起音:声音从 0 达到最大音量的时间(如钢琴按键瞬间起音快,小提琴拉弦起音慢)
- D(Decay)衰减:音量从峰值降到持续音量的时间
- S(Sustain)持续:发声过程中音量稳定的阶段
- R(Release)释音:停止发声后音量降到 0 的时间
生成音乐时我们要调整 ADSR 参数,让声音更有乐器感,比如钢琴的起音快、释音中等,弦乐的起音慢、释音长。
3. 音色塑造
- 基频:声音的基础频率,决定音调高低
- 谐波:基频的整数倍频率,决定音色,比如吉他的谐波丰富,所以声音温暖
- 共振峰:人声/乐器的频率峰值,比如元音 a/i/u 的区别,就是共振峰分布不同
我们在生成音色时,通过调整基频(100-200Hz)、添加 2-4 次谐波,模拟不同说话人的音色;生成音乐时,我们可以通过定制谐波比例,模拟钢琴、吉他、合成器等不同乐器的音色。
4. 环境感营造
通过音效叠加,我们添加背景噪音、回响、环境音效(键盘声、咳嗽声),让模拟语音更真实,营造一些特定的背景环境感:
- 基础音(语音/乐器)结合环境音(噪音 / 场景元素)实现场景化声音
- 效果器(回响、混响、失真)给声音加空间感,比如回响模拟大房间的声学效果
生成优美音乐时,我们可以用这个原理添加自然环境音(雨声、风声)、音乐效果器(混响让声音更空灵),让音乐更有层次感。
三、音频合成应用
我们先直观的感受一下一段音乐的生成,初步的了解其中的集合的元素,基于以上介绍的合成核心的实际代码体现,逐步分析其中的细节知识点强化了解。
import numpy as np
import soundfile as sf
import os
from scipy import signal
class SceneAudioGenerator:
def __init__(self, sample_rate=44100, duration_minutes=5):
self.sample_rate = sample_rate # 音乐用44100Hz(比ASR的16000Hz更清晰)
self.duration_seconds = duration_minutes * 60
self.total_samples = int(self.duration_seconds * self.sample_rate)
def _create_adsr_envelope(self, num_samples, instrument="piano"):
"""优化ADSR参数,适配不同乐器"""
envelope = np.ones(num_samples)
total_time = num_samples / self.sample_rate
if instrument == "piano":
attack = 0.02 # 钢琴起音快
decay = 0.1 # 快速衰减
sustain = 0.3 # 持续音量低
release = 0.8 # 释音中等
elif instrument == "synth": # 合成器(冥想用)
attack = 0.5 # 起音慢,更舒缓
decay = 0.3 # 缓慢衰减
sustain = 0.6 # 持续音量高
release = 2.0 # 释音长,更空灵
# 计算各阶段样本数
attack_samples = int(attack * self.sample_rate)
decay_samples = int(decay * self.sample_rate)
release_samples = int(release * self.sample_rate)
sustain_samples = num_samples - attack_samples - decay_samples - release_samples
# 处理边界情况
sustain_samples = max(sustain_samples, 0)
if attack_samples + decay_samples + sustain_samples > num_samples:
release_samples = num_samples - attack_samples - decay_samples - sustain_samples
# 生成包络
if attack_samples > 0:
envelope[:attack_samples] = np.linspace(0, 1, attack_samples)
if decay_samples > 0:
start = attack_samples
end = start + decay_samples
envelope[start:end] = np.linspace(1, sustain, decay_samples)
if sustain_samples > 0:
start = attack_samples + decay_samples
end = start + sustain_samples
envelope[start:end] = sustain
if release_samples > 0:
start = attack_samples + decay_samples + sustain_samples
end = min(start + release_samples, num_samples)
if start < end:
envelope[start:end] = np.linspace(sustain, 0, end - start)
return envelope
def _generate_fractal_noise(self, duration_seconds, hurst=0.5, octaves=4):
"""生成分形噪声(自然环境音专用,比随机噪声更真实)"""
samples = int(duration_seconds * self.sample_rate)
noise = np.zeros(samples)
freq = 1.0
for _ in range(octaves):
t = np.linspace(0, duration_seconds * freq, samples, endpoint=False)
noise += np.sin(2 * np.pi * t * np.random.randn()) * (freq ** (-hurst))
freq *= 2
return noise / np.max(np.abs(noise)) * 0.1 # 降低音量
def _breathing_amplitude(self, duration_seconds):
"""生成呼吸节奏的音量曲线(4秒吸气+6秒呼气)"""
t = np.linspace(0, duration_seconds, int(duration_seconds * self.sample_rate))
breath_cycle = 10.0 # 呼吸周期10秒
# 吸气:0-4秒,音量从0.3→0.8;呼气:4-10秒,音量从0.8→0.3
cycle = np.where(t % breath_cycle < 4,
np.interp(t % breath_cycle, [0, 4], [0.3, 0.8]),
np.interp((t % breath_cycle) - 4, [0, 6], [0.8, 0.3]))
return cycle
def generate_meditation_music(self, filename="meditation_music.wav", nature_sound="rain"):
"""生成冥想音乐:合成器+自然环境音+呼吸节奏"""
print(f"🎵 生成冥想音乐:{filename}")
# 1. 生成基础合成器音色(五声音阶:C、D、E、G、A)
pentatonic_scale = [261.63, 293.66, 329.63, 392.00, 440.00] # C大调五声音阶(Hz)
bpm = 50 # 慢节奏
beat_duration = 60 / bpm # 每拍时长
num_beats = int(self.duration_seconds / beat_duration)
# 生成和弦序列(C-Am-F-G,舒缓经典)
chord_progression = [
[0, 2, 4], # C和弦:C-E-A
[1, 3, 0], # Am和弦:D-G-C
[3, 0, 2], # F和弦:G-C-E
[4, 1, 3] # G和弦:A-D-G
]
# 初始化音频
audio = np.zeros(self.total_samples)
current_sample = 0
# 生成和弦进行
for beat in range(num_beats):
chord = chord_progression[beat % len(chord_progression)]
chord_duration = beat_duration * 2 # 每个和弦占2拍
chord_samples = int(chord_duration * self.sample_rate)
for note_idx in chord:
note_freq = pentatonic_scale[note_idx]
# 生成音符波形(基频+谐波)
t = np.linspace(0, chord_duration, chord_samples, endpoint=False)
fundamental = np.sin(2 * np.pi * note_freq * t)
harmonic1 = np.sin(2 * np.pi * note_freq * 2 * t) * 0.3 # 2倍谐波(丰富音色)
harmonic2 = np.sin(2 * np.pi * note_freq * 3 * t) * 0.1 # 3倍谐波
note = fundamental + harmonic1 + harmonic2
# 应用ADSR包络(合成器音色)
envelope = self._create_adsr_envelope(chord_samples, instrument="synth")
note = note * envelope
# 叠加到主音频
if current_sample + chord_samples < self.total_samples:
audio[current_sample:current_sample+chord_samples] += note * 0.3
current_sample += chord_samples
# 2. 添加自然环境音(雨声/风声)
nature_duration = self.duration_seconds
if nature_sound == "rain":
nature_audio = self._generate_fractal_noise(nature_duration) # 分形噪声模拟雨声
elif nature_sound == "wind":
nature_audio = self._generate_fractal_noise(nature_duration, hurst=0.7, octaves=3) # 更平缓的噪声模拟风声
audio[:len(nature_audio)] += nature_audio
# 3. 应用呼吸节奏音量曲线
breathing_curve = self._breathing_amplitude(self.duration_seconds)
audio = audio * breathing_curve
# 4. 添加混响效果(模拟空旷空间)
audio = self._add_reverb(audio, delay=0.5, decay=0.7)
# 5. 标准化音量
audio = self._normalize_audio(audio)
# 保存文件
sf.write(filename, audio, self.sample_rate)
print(f"✅ 冥想音乐已保存:{filename}({self.duration_seconds:.1f}秒)")
return audio
def _add_reverb(self, audio, delay=0.3, decay=0.5):
"""优化混响效果,让音乐更空灵"""
delay_samples = int(delay * self.sample_rate)
delayed = np.zeros_like(audio)
delayed[delay_samples:] = audio[:-delay_samples] * decay
# 二次延迟(更真实的空间感)
delay2_samples = int(delay * 1.5 * self.sample_rate)
delayed2 = np.zeros_like(audio)
delayed2[delay2_samples:] = audio[:-delay2_samples] * decay * 0.6
result = audio + delayed + delayed2
return self._normalize_audio(result)
def _normalize_audio(self, audio):
"""标准化音量,避免削波"""
max_val = np.max(np.abs(audio))
if max_val > 0:
return audio / max_val * 0.8 # 保留20%余量,更柔和
return audio
# 生成冥想音乐(5分钟,雨声+合成器)
generator = SceneAudioGenerator(duration_minutes=5)
generator.generate_meditation_music("meditation_rain.wav", nature_sound="rain") 1. 采样率初始化
class SceneAudioGenerator:
def __init__(self, sample_rate=44100, duration_minutes=5):
self.sample_rate = sample_rate # 音乐用44100Hz(比ASR的16000Hz更清晰)
self.duration_seconds = duration_minutes * 60
self.total_samples = int(self.duration_seconds * self.sample_rate)采样率选择 44100Hz:
- 这是CD质量的采样率(44.1kHz)
- Nyquist频率为 22050Hz,完全覆盖人耳可听范围(20-20000Hz)
- 比语音识别常用的16000Hz更高,保留更多高频细节
- 计算公式:总样本数 = 时长(秒) × 采样率
2. ADSR包络生成器
def _create_adsr_envelope(self, num_samples, instrument="piano"):
"""优化ADSR参数,适配不同乐器"""
envelope = np.ones(num_samples)
total_time = num_samples / self.sample_rate
if instrument == "piano":
attack = 0.02 # 钢琴起音快
decay = 0.1 # 快速衰减
sustain = 0.3 # 持续音量低
release = 0.8 # 释音中等
elif instrument == "synth": # 合成器(冥想用)
attack = 0.5 # 起音慢,更舒缓
decay = 0.3 # 缓慢衰减
sustain = 0.6 # 持续音量高
release = 2.0 # 释音长,更空灵
.....ADSR包络原理:
- Attack(起音):声音从0上升到最大振幅的时间
- Decay(衰减):从最大振幅下降到持续电平的时间
- Sustain(持续):保持的音量电平
- Release(释音):音符结束后衰减到0的时间
不同乐器的ADSR参数对比:
- 钢琴: A=0.02s, D=0.1s, S=0.3, R=0.8s,快速起音、快速衰减,模拟真实钢琴的击弦机制
- 合成器: A=0.5s, D=0.3s, S=0.6, R=2.0s,缓慢起音、长释音,创造"飘渺空灵"的冥想效果
包络生成算法:
- 线性插值生成包络曲线
- 线性上升:envelope[:attack_samples] = np.linspace(0, 1, attack_samples)
- 线性下降:envelope[start:end] = np.linspace(1, sustain, decay_samples)
3. 分形噪声生成
def _generate_fractal_noise(self, duration_seconds, hurst=0.5, octaves=4):
noise = np.zeros(samples)
freq = 1.0
for _ in range(octaves):
t = np.linspace(0, duration_seconds * freq, samples, endpoint=False)
noise += np.sin(2 * np.pi * t * np.random.randn()) * (freq ** (-hurst))
freq *= 2分形噪声原理:
- 多个八度(octaves)的正弦波叠加
- 每个八度频率翻倍(1x, 2x, 4x, 8x...)
- 振幅按Hurst指数衰减:amp = freq ** (-hurst)
Hurst指数的作用:
- hurst=0.5:布朗噪声(Brownian noise),频率每翻倍,振幅减半
- hurst=0.7:更平缓的噪声,适合模拟风声
- 指数关系:1/f^h,h越大,低频成分越多
自然环境声模拟:
- 雨声:多频率成分叠加,nature_audio = self._generate_fractal_noise(nature_duration)
- 风声:更平缓的低频噪声,nature_audio = self._generate_fractal_noise(nature_duration, hurst=0.7, octaves=3)
4. 呼吸节奏音量曲线
def _breathing_amplitude(self, duration_seconds):
"""生成呼吸节奏的音量曲线(4秒吸气+6秒呼气)"""
t = np.linspace(0, duration_seconds, int(duration_seconds * self.sample_rate))
breath_cycle = 10.0 # 呼吸周期10秒
# 吸气:0-4秒,音量从0.3→0.8;呼气:4-10秒,音量从0.8→0.3
cycle = np.where(t % breath_cycle < 4,
np.interp(t % breath_cycle, [0, 4], [0.3, 0.8]),
np.interp((t % breath_cycle) - 4, [0, 6], [0.8, 0.3]))
return cycle生理呼吸模式:
- 正常冥想呼吸:吸气4秒 + 呼气6秒 = 10秒周期
- 呼吸比(吸气:呼气)= 4:6 ≈ 1:1.5
- 音量变化模拟呼吸强度:吸气时渐强,呼气时渐弱
5. 音乐生成核心算法
def generate_meditation_music(self, filename="meditation_music.wav", nature_sound="rain"):
"""生成冥想音乐:合成器+自然环境音+呼吸节奏"""
print(f"🎵 生成冥想音乐:{filename}")
# 1. 生成基础合成器音色(五声音阶:C、D、E、G、A)
pentatonic_scale = [261.63, 293.66, 329.63, 392.00, 440.00] # C大调五声音阶(Hz)
bpm = 50 # 慢节奏
beat_duration = 60 / bpm # 每拍时长
num_beats = int(self.duration_seconds / beat_duration)
# 生成和弦序列(C-Am-F-G,舒缓经典)
chord_progression = [
[0, 2, 4], # C和弦:C-E-A
[1, 3, 0], # Am和弦:D-G-C
[3, 0, 2], # F和弦:G-C-E
[4, 1, 3] # G和弦:A-D-G
]音阶和和弦设计:
- 五声音阶特点:无半音,和谐悦耳,适合冥想音乐
- 和弦进行:C - Am - F - G(经典四和弦进行)
波形合成技术:
- 谐波增强:添加2倍、3倍频谐波,丰富音色
- 谐波比例:基频:2倍:3倍 = 1:0.3:0.1,避免谐波过强
节奏控制:
- 慢节奏(50 BPM)适合冥想
- 和弦变化每2.4秒一次,缓慢过渡
6. 混响效果实现
def _add_reverb(self, audio, delay=0.3, decay=0.5):
delay_samples = int(delay * self.sample_rate)
delayed = np.zeros_like(audio)
delayed[delay_samples:] = audio[:-delay_samples] * decay
# 二次延迟
delay2_samples = int(delay * 1.5 * self.sample_rate)
delayed2 = np.zeros_like(audio)
delayed2[delay2_samples:] = audio[:-delay2_samples] * decay * 0.6简单混响算法:
- 主延迟:300ms,衰减50%
- 二次延迟:450ms(1.5倍),衰减30%(0.5×0.6)
- 公式:输出 = 原始 + 延迟1 + 延迟2
空灵感创造:
- 长延迟(500ms)+ 高衰减(70%)
- 模拟大空间(如教堂、山洞)的回声
7. 音量标准化
def _normalize_audio(self, audio):
"""标准化音量,避免削波"""
max_val = np.max(np.abs(audio))
if max_val > 0:
return audio / max_val * 0.8 # 保留20%余量,更柔和
return audio防止削波(Clipping):
- 找到音频的最大绝对值
- 缩放所有采样点到[-0.8, 0.8]范围
- 保留20%动态余量,避免数字过载
心理学考虑:
- 80%最大音量听起来更柔和
- 为后续处理(如EQ、压缩)留出空间
8. 完整信号处理流程

四、通过模型生成
接下来我们来分析一套融合MusicGen 大模型(创意核心)+ 传统信号合成(场景增强)+ 多维度可视化(效果验证) 的音频生成系统;
1. 核心概念
- 采样率(Sample Rate):本文采用 32000Hz(MusicGen 默认值),表示每秒采集 32000 个音频样本,越高则音质越好(但文件体积越大);
- Token 生成数:MusicGen 按 25Hz 的帧率生成 Token,因此max_new_tokens = 时长(秒) × 25;
- 分形噪声:区别于随机噪声,通过多倍频叠加生成更自然的雨声,符合真实物理环境的声音特征;
- 情绪特征映射:基于音频的客观特征(响度、节奏、频谱中心),量化映射为 “平静 / 快乐 / 激昂 / 悲伤”4 个主观情绪维度;
- Guidance Scale:TTA 模型的关键参数,控制文本提示对生成结果的约束强度(值越高,生成结果越贴合文本)。
2. MusicGen 模型介绍
MusicGen 是 Meta 推出的轻量级 TTA 大模型,本系统选用facebook/musicgen-small(1.5GB 级),兼顾效果与部署门槛:
- 架构:Encoder-Decoder 结构,文本 Encoder 将自然语言转为语义向量,音频 Decoder 基于语义向量生成音频 Token;
- Token 化:将音频波形转为离散 Token(类似 LLM 的文本 Token),通过自回归生成实现音频创作;
- 本地化部署:通过modelscope.snapshot_download实现模型缓存,避免重复下载,支持离线使用;
- 核心优化:代码中通过torch.no_grad()、模型评估模式(eval())降低显存占用,通过标准化(audio / audio_max * 0.9)避免音频削波。
3. 核心模块设计
本系统拆分为 3 个解耦模块,便于扩展和维护:
3.1 TTAAudioGenerator 模块
- 核心功能:MusicGen 模型调用、核心音频生成
- 关键函数/特性:generate_from_text(),支持自定义 temperature/guidance_scale,含异常捕获 + 静音兜底机制,确保程序稳定性
3.2 TraditionalAudioEnhancer 模块
- 核心功能:场景音效增强
- 关键函数/特性:_generate_fractal_rain_noise()(分形雨声生成,比随机噪声更自然);enhance_audio()(混响添加 + 音量标准化,避免音频失真)
3.3 AudioVisualizer 模块
- 核心功能:音频可视化 + 情绪分析
- 关键函数/特性:plot_spectrogram()(梅尔频谱绘制,展现频率分布);extract_emotion_features()(提取响度 / 节奏 / 频谱特征,映射为情绪得分)
4. 详细参数配置
4.1 全局配置
- SAMPLE_RATE = 32000:MusicGen 默认采样率,不可随意修改(模型训练时固定,修改会导致音频变速 / 变调);
- DURATION = 10:生成音频时长(秒),建议 5-30 秒(平衡效果与耗时);
- DEVICE = "cuda" if torch.cuda.is_available () else "cpu":优先使用 GPU 加速,无 GPU 时自动切换 CPU(速度较慢)。
4.2 MusicGen 生成参数
- temperature:
- 默认值为0.7,取值范围在0.1-1.0之间
- 作用说明:控制生成随机性,值越高创意性越强,值越低结果越稳定
- 调优建议:冥想音乐→0.6-0.8;电子舞曲→0.8-0.9
- top_k:
- 默认值为50,取值范围在10-100之间
- 作用说明:采样时仅保留概率前 k 的 Token,降低随机性
- 调优建议:保持默认即可
- top_p:
- 默认值为0.95,取值范围在0.8-1.0之间
- 作用说明:核采样,保留累计概率≥p 的 Token,平衡随机性与合理性
- 调优建议:保持默认即可
- guidance_scale:
- 默认值为3.0,取值范围在1.0-5.0之间
- 作用说明:文本约束强度,值越高生成结果越贴合文本描述,过高易导致音频不自然
- 调优建议:简单提示→2.0-3.0;复杂提示→3.0-4.0
4.3 传统音效增强参数
- rain_level:
- 默认值:0.1
- 作用说明:控制雨声强度(0-1 区间)
- 调优建议:冥想音乐→0.05-0.1;环境音乐→0.1-0.15
- everb_strength:
- 默认值:0.3
- 作用说明:控制混响强度(0-1 区间)
- 调优建议:空灵场景→0.3-0.4;紧凑场景→0.1-0.2
5. 执行流程
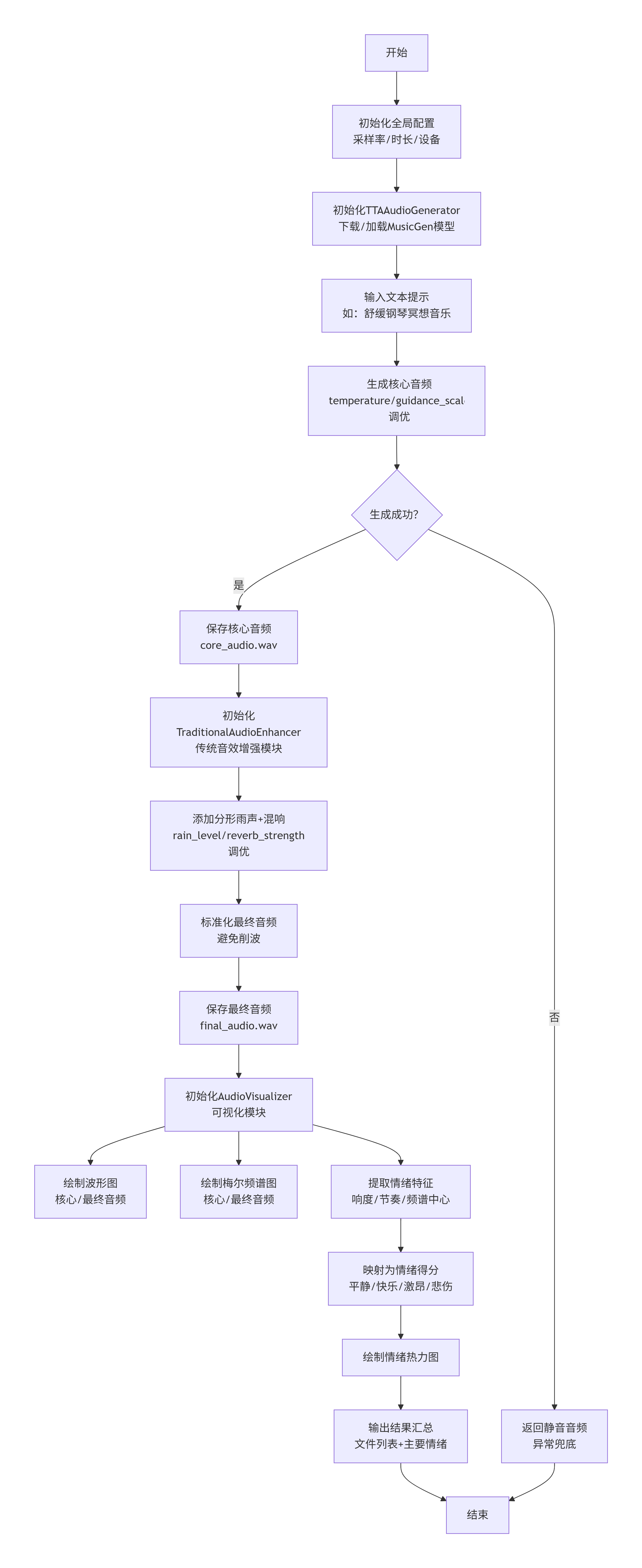
主要流程说明:
- 1. 初始化阶段:下载/加载MusicGen模型缓存→初始化处理器/模型→设置评估模式
- 2. 核心生成:文本提示预处理→Token生成→音频解码→标准化→输出核心音频
- 3. 音效增强:生成分形雨声→添加混响→音量标准化→输出最终音频
- 4. 结果保存:保存核心音频/最终音频为WAV文件
- 5. 可视化阶段:绘制核心/最终音频的波形图→绘制频谱图→提取情绪特征→绘制情绪热力图
- 6. 结果解析:输出情绪得分→识别主要情绪→汇总生成文件
6. 代码整体结构
6.1 全局配置
- 采样率:32000Hz(MusicGen默认)
- 生成时长:10秒
- 设备:优先使用CUDA
6.2 TTAAudioGenerator类
- 初始化:下载模型,加载模型和处理器,设置模型为评估模式。
- generate_from_text:根据文本提示生成音频,可以调整生成参数(temperature、guidance_scale等)。
- 生成过程:将文本转换为模型输入,生成音频token,然后解码为音频波形。最后对音频进行标准化(单声道,幅度归一化)。
6.3 TraditionalAudioEnhancer类
- 使用传统信号处理技术添加音效。
- 分形雨声:通过多个八度的正弦波叠加生成分形噪声,然后进行低通滤波,模拟雨声。
- 混响:简单的延迟线混响,将原始音频与延迟后的音频叠加。
- 增强函数:将雨声和混响效果添加到核心音频中。
6.4 AudioVisualizer类
- 波形图:显示音频幅度随时间的变化。
- 频谱图:使用梅尔频谱显示音频频率随时间的变化,梅尔频谱更符合人耳听觉。
- 情绪分析:提取音频的节奏、响度、频谱中心、频谱带宽等特征,映射到四个情绪维度(平静、快乐、激昂、悲伤)。
- 情绪热力图:用柱状图显示四个情绪维度的得分。
6.5 主流程
- 步骤1:用TTAAudioGenerator生成核心音频(core_audio.wav)
- 步骤2:用TraditionalAudioEnhancer增强音频(添加雨声和混响),保存为final_audio.wav
- 步骤3:可视化核心音频和最终音频的波形图和频谱图
- 步骤4:情绪分析,并绘制情绪热力图
7. 输出图例
7.1 波形图(waveform)
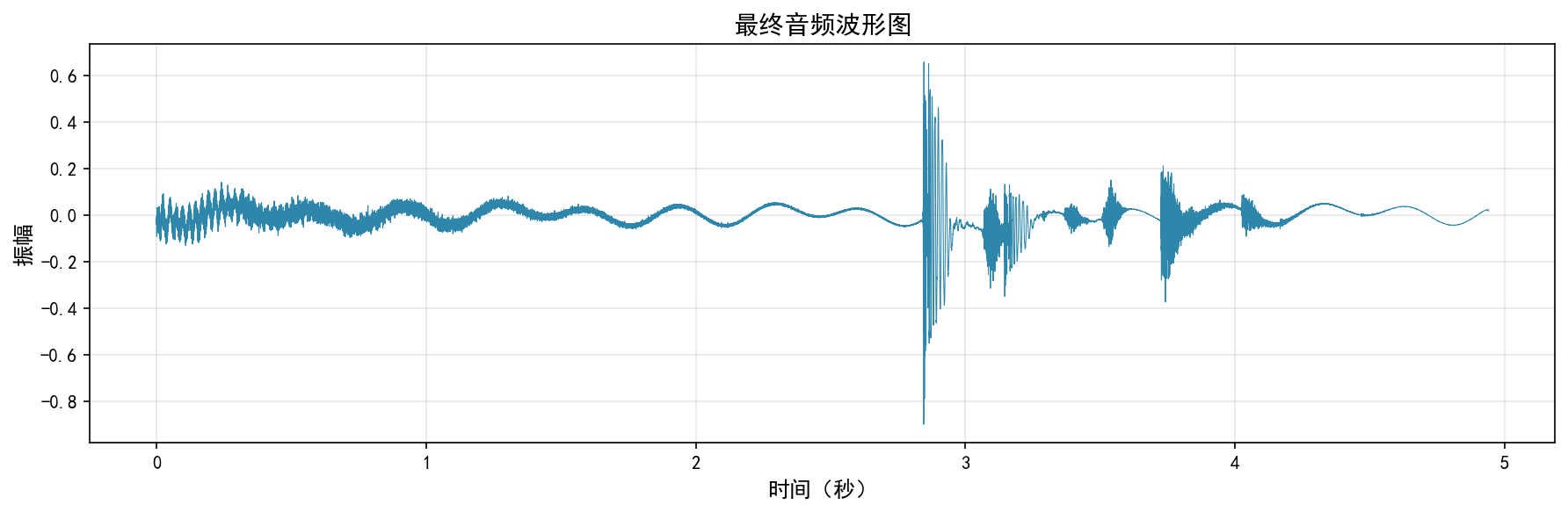
- 横轴:时间(秒)
- 纵轴:振幅(归一化到-1到1之间)
- 作用:观察音频的幅度变化,可以直观看到音频的响度变化和节奏。
7.2 梅尔频谱图(spectrogram)
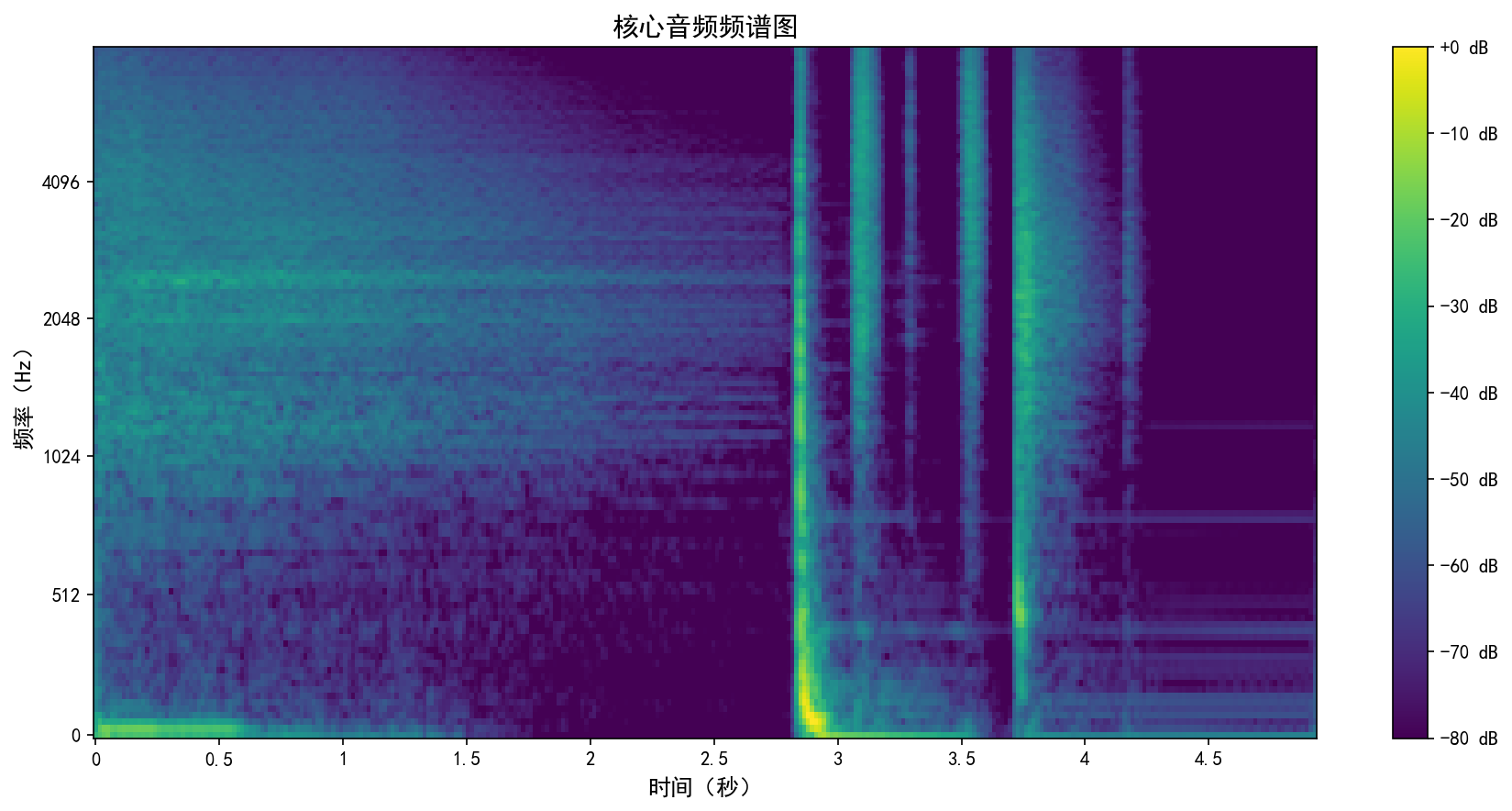
- 横轴:时间(秒)
- 纵轴:频率(Hz),但转换为梅尔刻度,更符合人耳对音高的感知。
- 颜色:表示能量(dB),颜色越亮表示该频率成分的能量越高。
- 作用:观察音频的频率成分随时间的变化,可以识别音高、和声、乐器等。
7.3 情绪热力图(emotion heatmap)
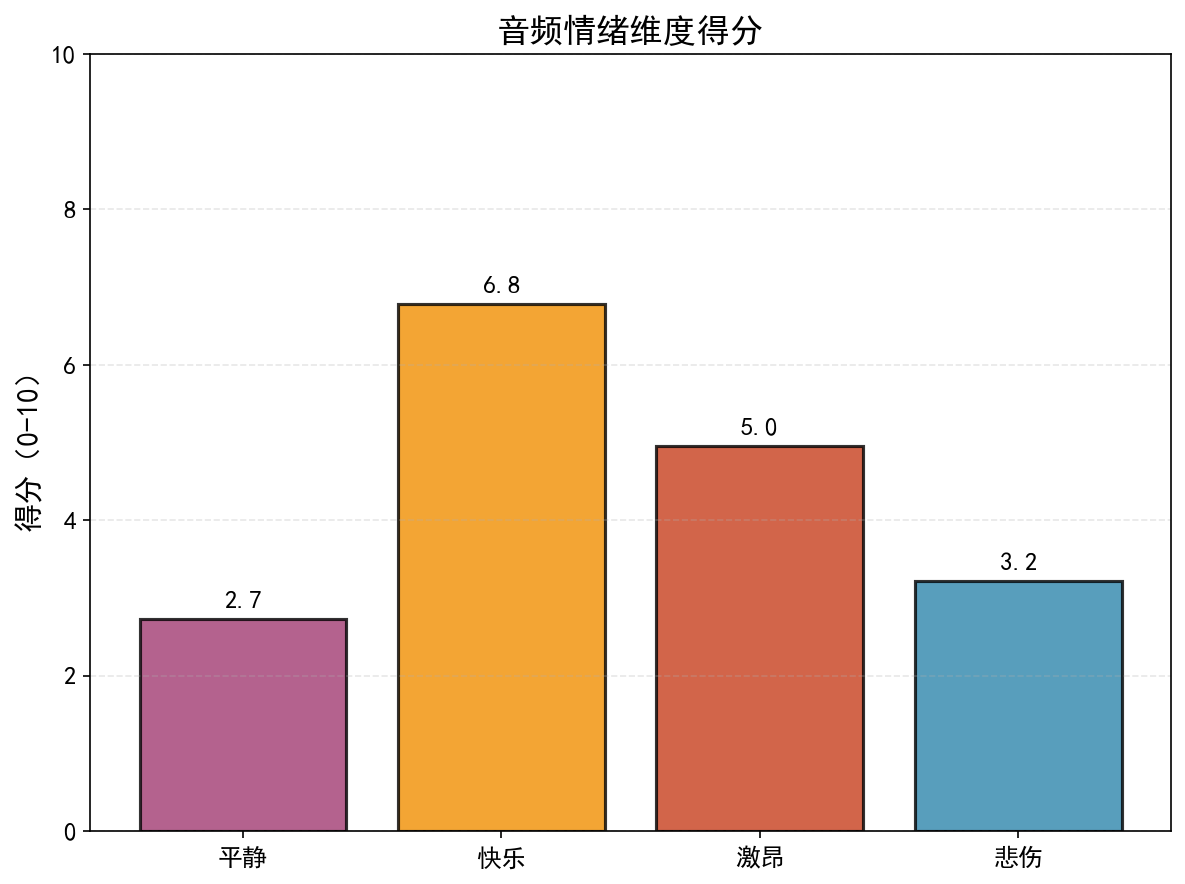
- 四个情绪维度:平静、快乐、激昂、悲伤。
- 每个维度得分在0-10之间,通过音频特征计算得到。
- 响度(RMS)高、节奏快则激昂得分高;节奏快、频谱中心高则快乐得分高;
情绪特征的映射:
- 平静:低响度、低节奏、窄带宽 -> 得分高
- 快乐:高节奏、高频谱中心 -> 得分高
- 激昂:高响度、高节奏 -> 得分高
- 悲伤:低频谱中心、低节奏 -> 得分高
五、总结
今天我们构建了一个完整的AI驱动音乐创作与分析流水线,创新性地融合了深度生成模型与传统信号处理技术。核心采用MusicGen大模型从文本描述生成基础音乐,再通过分形噪声合成和数字混响等传统方法增强场景效果,实现了“AI创意生成+人工精细化调整”的协作模式。
系统配备了多维分析模块,通过波形图、梅尔频谱图展示音频的时频特性,并创新性地从响度、节奏、频谱质心等声学特征中提取情绪维度得分,将主观感知转化为“平静/快乐/激昂/悲伤”的量化评估。该架构体现了生成式AI与经典数字信号处理的有机结合,既发挥了大模型的创造性,又保留了传统方法在特定音效上的精确可控性,为自动化音乐创作、情绪化配乐生成及音频分析提供了基础的框架支撑。
附录:完整的示例参考
import numpy as np
import torch
import soundfile as sf
import librosa
import librosa.display
import matplotlib.pyplot as plt
from scipy import signal
from transformers import AutoProcessor, MusicgenForConditionalGeneration
from modelscope import snapshot_download
# ====================== 全局配置 ======================
SAMPLE_RATE = 32000 # MusicGen默认采样率
DURATION = 10 # 生成音频时长(秒)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文显示
plt.rcParams['axes.unicode_minus'] = False # 负号显示
# ====================== 1. TTA大模型(MusicGen)生成核心音频 ======================
class TTAAudioGenerator:
def __init__(self, model_name="facebook/musicgen-small", cache_dir="D:\\modelscope\\hub"):
"""初始化MusicGen模型"""
try:
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print("加载模型和处理器...")
self.processor = AutoProcessor.from_pretrained(local_model_path)
self.model = MusicgenForConditionalGeneration.from_pretrained(local_model_path).to(DEVICE)
# 设置模型为评估模式
self.model.eval()
self.sample_rate = SAMPLE_RATE
print(f"✅ TTA大模型初始化完成:{model_name} (设备: {DEVICE})")
except Exception as e:
print(f"❌ 模型初始化失败: {e}")
raise
def generate_from_text(self, text_prompt, duration_seconds=10, **generation_kwargs):
"""
从文本生成核心音频
"""
try:
# 设置默认生成参数
default_kwargs = {
"do_sample": True,
"temperature": 0.7,
"top_k": 50,
"top_p": 0.95,
"guidance_scale": 3.0,
}
# 更新用户提供的参数
generation_kwargs = {**default_kwargs, **generation_kwargs}
# 计算生成token数
max_new_tokens = int(duration_seconds * 25)
generation_kwargs["max_new_tokens"] = max_new_tokens
print(f"🎵 生成音频: {text_prompt}")
print(f"📊 参数: temperature={generation_kwargs['temperature']}, "
f"guidance_scale={generation_kwargs['guidance_scale']}")
# 预处理文本
inputs = self.processor(
text=[text_prompt],
padding=True,
return_tensors="pt",
).to(DEVICE)
print("⏳ 生成中...")
# 生成音频
with torch.no_grad():
audio_values = self.model.generate(
**inputs,
**generation_kwargs
)
# 获取生成的音频数据
audio = audio_values[0].cpu().numpy().squeeze()
# 确保音频是单声道
if audio.ndim > 1:
audio = audio.mean(axis=0)
# 标准化音频到[-1, 1]范围
audio_max = np.max(np.abs(audio))
if audio_max > 0:
audio = audio / audio_max * 0.9
duration = len(audio) / self.sample_rate
print(f"✅ 生成完成: {duration:.1f}秒")
return audio
except Exception as e:
print(f"❌ 音频生成失败: {e}")
# 返回静音音频
return np.zeros(int(duration_seconds * self.sample_rate))
# ====================== 2. 传统信号合成:补充场景音效 ======================
class TraditionalAudioEnhancer:
def __init__(self, sample_rate=32000):
self.sample_rate = sample_rate
def _generate_fractal_rain_noise(self, duration_seconds, noise_level=0.1):
"""生成分形雨声"""
try:
samples = int(duration_seconds * self.sample_rate)
noise = np.zeros(samples)
freq = 1.0
octaves = 4
hurst = 0.5
for _ in range(octaves):
t = np.linspace(0, duration_seconds * freq, samples, endpoint=False)
noise += np.sin(2 * np.pi * t * np.random.randn()) * (freq ** (-hurst))
freq *= 2
# 低通滤波
if len(noise) > 0:
b, a = signal.butter(4, 1000, 'low', fs=self.sample_rate)
noise = signal.lfilter(b, a, noise)
noise_max = np.max(np.abs(noise))
if noise_max > 0:
noise = noise / noise_max * noise_level
return noise
except Exception as e:
print(f"❌ 雨声生成失败: {e}")
return np.zeros(int(duration_seconds * self.sample_rate))
def enhance_audio(self, core_audio, add_rain=True, add_reverb=True, rain_level=0.1, reverb_strength=0.3):
"""增强核心音频"""
try:
if len(core_audio) == 0:
return core_audio
enhanced_audio = core_audio.copy()
duration = len(core_audio) / self.sample_rate
# 添加雨声
if add_rain:
rain_noise = self._generate_fractal_rain_noise(duration, noise_level=rain_level)
if len(rain_noise) == len(enhanced_audio):
enhanced_audio += rain_noise
# 添加简单混响
if add_reverb and len(enhanced_audio) > 0:
delay_samples = int(0.3 * self.sample_rate)
if delay_samples < len(enhanced_audio):
delayed = np.zeros_like(enhanced_audio)
delayed[delay_samples:] = enhanced_audio[:-delay_samples] * reverb_strength
enhanced_audio = enhanced_audio + delayed
# 标准化
audio_max = np.max(np.abs(enhanced_audio))
if audio_max > 0:
enhanced_audio = enhanced_audio / audio_max * 0.9
print(f"✅ 音效增强完成")
return enhanced_audio
except Exception as e:
print(f"❌ 音效增强失败: {e}")
return core_audio
# ====================== 3. 音频可视化:波形+频谱+情绪 ======================
class AudioVisualizer:
def __init__(self, sample_rate=32000):
self.sample_rate = sample_rate
def plot_waveform(self, audio, save_path="waveform.png", title="音频波形图"):
"""绘制波形图"""
try:
if len(audio) == 0:
print("❌ 音频数据为空,无法绘制波形")
return
duration = len(audio) / self.sample_rate
if duration <= 0:
print("❌ 音频时长为0")
return
time = np.linspace(0, duration, len(audio))
plt.figure(figsize=(12, 4))
plt.plot(time, audio, color="#2E86AB", linewidth=0.5)
plt.title(title, fontsize=14)
plt.xlabel("时间(秒)", fontsize=12)
plt.ylabel("振幅", fontsize=12)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.close()
print(f"📊 波形图已保存:{save_path}")
except Exception as e:
print(f"❌ 波形图绘制失败: {e}")
def plot_spectrogram(self, audio, save_path="spectrogram.png", title="梅尔频谱图"):
"""绘制频谱图"""
try:
if len(audio) == 0:
print("❌ 音频数据为空,无法绘制频谱")
return
# 确保音频长度足够
if len(audio) < 512:
print("❌ 音频太短,无法计算频谱")
return
# 计算梅尔频谱
S = librosa.feature.melspectrogram(
y=audio,
sr=self.sample_rate,
n_mels=128,
fmax=8000,
hop_length=512
)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure(figsize=(12, 6))
img = librosa.display.specshow(
S_dB,
sr=self.sample_rate,
x_axis='time',
y_axis='mel',
fmax=8000,
cmap='viridis'
)
plt.colorbar(img, format='%+2.0f dB')
plt.title(title, fontsize=14)
plt.xlabel("时间(秒)", fontsize=12)
plt.ylabel("频率(Hz)", fontsize=12)
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.close()
print(f"📊 频谱图已保存:{save_path}")
except Exception as e:
print(f"❌ 频谱图绘制失败: {e}")
def extract_emotion_features(self, audio):
"""提取音频情绪特征"""
try:
if len(audio) == 0:
return {"平静": 5.0, "快乐": 5.0, "激昂": 5.0, "悲伤": 5.0}
features = {}
# 1. 响度(确保是标量)
rms = librosa.feature.rms(y=audio)[0]
features['loudness'] = float(np.mean(rms)) if len(rms) > 0 else 0.0
# 2. 节奏(确保是标量)
try:
tempo, _ = librosa.beat.beat_track(y=audio, sr=self.sample_rate)
features['tempo'] = float(tempo[0]) if isinstance(tempo, np.ndarray) and len(tempo) > 0 else float(tempo)
except:
features['tempo'] = 80.0 # 默认值
# 3. 频谱中心
try:
spectral_centroid = librosa.feature.spectral_centroid(y=audio, sr=self.sample_rate)[0]
features['spectral_centroid'] = float(np.mean(spectral_centroid))
except:
features['spectral_centroid'] = 1000.0
# 4. 频谱带宽
try:
spectral_bandwidth = librosa.feature.spectral_bandwidth(y=audio, sr=self.sample_rate)[0]
features['spectral_bandwidth'] = float(np.mean(spectral_bandwidth))
except:
features['spectral_bandwidth'] = 1000.0
# 映射到情绪维度(确保是标量)
emotion_scores = {}
# 平静:低响度+低节奏+窄带宽
calm = 10 - (features['loudness'] * 10) - (features['tempo'] / 20) - (features['spectral_bandwidth'] / 1000)
emotion_scores['平静'] = float(np.clip(calm, 0, 10))
# 快乐:高节奏+高频谱中心
happy = (features['tempo'] / 20) + (features['spectral_centroid'] / 1000)
emotion_scores['快乐'] = float(np.clip(happy, 0, 10))
# 激昂:高响度+高节奏
energetic = (features['loudness'] * 10) + (features['tempo'] / 20)
emotion_scores['激昂'] = float(np.clip(energetic, 0, 10))
# 悲伤:低频谱中心+低节奏
sad = 10 - (features['spectral_centroid'] / 1000) - (features['tempo'] / 20)
emotion_scores['悲伤'] = float(np.clip(sad, 0, 10))
print(f"📈 音频特征: 响度={features['loudness']:.3f}, "
f"节奏={features['tempo']:.1f}, "
f"频谱中心={features['spectral_centroid']:.0f}Hz")
return emotion_scores
except Exception as e:
print(f"❌ 情绪特征提取失败: {e}")
return {"平静": 5.0, "快乐": 5.0, "激昂": 5.0, "悲伤": 5.0}
def plot_emotion_heatmap(self, emotion_scores, save_path="emotion_heatmap.png"):
"""绘制情绪热力图"""
try:
# 确保数据是标量
emotions = list(emotion_scores.keys())
scores = []
for emotion in emotions:
score = emotion_scores[emotion]
# 确保是标量
if isinstance(score, (np.ndarray, list)):
score = float(score[0]) if len(score) > 0 else float(score)
else:
score = float(score)
scores.append(score)
colors = ['#A23B72', '#F18F01', '#C73E1D', '#2E86AB']
# 绘制柱状图
plt.figure(figsize=(8, 6))
bars = plt.bar(emotions, scores, color=colors, alpha=0.8, edgecolor='black', linewidth=1.5)
# 添加数值标签
for bar, score in zip(bars, scores):
plt.text(
bar.get_x() + bar.get_width()/2,
bar.get_height() + 0.1,
f"{score:.1f}",
ha='center', va='bottom',
fontsize=12,
fontweight='bold'
)
plt.title("音频情绪维度得分", fontsize=16, fontweight='bold')
plt.ylabel("得分(0-10)", fontsize=14)
plt.ylim(0, 10)
plt.grid(axis='y', alpha=0.3, linestyle='--')
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.close()
print(f"📊 情绪热力图已保存:{save_path}")
except Exception as e:
print(f"❌ 情绪热力图绘制失败: {e}")
# ====================== 4. 主流程:整合所有模块 ======================
def main():
print("=" * 60)
print("🎵 音乐生成与情绪分析系统 🎵")
print("=" * 60)
try:
# 1. 定义文本提示
text_prompt = "舒缓的钢琴冥想音乐,轻柔的雨声背景,40BPM"
print(f"\n🎯 音乐描述: {text_prompt}")
print(f"⏱️ 目标时长: {DURATION}秒")
# 2. TTA大模型生成核心音频
print("\n📥 步骤1: 初始化TTA大模型")
tta_generator = TTAAudioGenerator()
print("\n🎹 步骤2: 生成核心音频")
core_audio = tta_generator.generate_from_text(
text_prompt,
duration_seconds=DURATION,
temperature=0.8,
guidance_scale=3.5
)
# 保存原始生成的音频
if len(core_audio) > 0:
sf.write("core_audio.wav", core_audio, SAMPLE_RATE)
print(f"💾 核心音频已保存:core_audio.wav ({len(core_audio)}个采样点)")
else:
print("❌ 核心音频生成为空")
return
# 3. 传统信号合成增强音频
print("\n🎚️ 步骤3: 音效增强")
enhancer = TraditionalAudioEnhancer(sample_rate=SAMPLE_RATE)
final_audio = enhancer.enhance_audio(
core_audio,
add_rain=True,
add_reverb=True,
rain_level=0.05, # 降低雨声强度
reverb_strength=0.3
)
# 4. 保存最终音频
sf.write("final_audio.wav", final_audio, SAMPLE_RATE)
print(f"💾 最终音频已保存:final_audio.wav")
# 5. 可视化
print("\n📊 步骤4: 音频可视化")
visualizer = AudioVisualizer(sample_rate=SAMPLE_RATE)
# 可视化核心音频
visualizer.plot_waveform(core_audio, "core_waveform.png", "核心音频波形图")
visualizer.plot_spectrogram(core_audio, "core_spectrogram.png", "核心音频频谱图")
# 可视化最终音频
visualizer.plot_waveform(final_audio, "final_waveform.png", "最终音频波形图")
visualizer.plot_spectrogram(final_audio, "final_spectrogram.png", "最终音频频谱图")
# 提取情绪特征并可视化
print("\n🧠 步骤5: 情绪分析")
emotion_scores = visualizer.extract_emotion_features(final_audio)
print(f"🎭 情绪得分:")
for emotion, score in emotion_scores.items():
print(f" {emotion}: {score:.2f}")
# 找出主要情绪
main_emotion = max(emotion_scores, key=emotion_scores.get)
print(f"✨ 主要情绪: {main_emotion} ({emotion_scores[main_emotion]:.2f}分)")
visualizer.plot_emotion_heatmap(emotion_scores)
print("\n" + "=" * 60)
print("🎉 音乐生成流程完成!")
print("生成的文件:")
print(" - core_audio.wav (核心音频)")
print(" - final_audio.wav (最终音频)")
print(" - core_waveform.png (核心波形图)")
print(" - core_spectrogram.png (核心频谱图)")
print(" - final_waveform.png (最终波形图)")
print(" - final_spectrogram.png (最终频谱图)")
print(" - emotion_heatmap.png (情绪分析图)")
print("=" * 60)
except Exception as e:
print(f"\n❌ 程序执行失败: {e}")
import traceback
traceback.print_exc()
def quick_generate(prompt, duration=10, save_name="output"):
"""快速生成函数"""
print(f"\n🚀 快速生成: {prompt}")
generator = TTAAudioGenerator()
enhancer = TraditionalAudioEnhancer()
visualizer = AudioVisualizer()
# 生成音频
audio = generator.generate_from_text(
prompt,
duration_seconds=duration,
temperature=0.9,
guidance_scale=3.0
)
# 增强
audio = enhancer.enhance_audio(audio, add_rain=False, add_reverb=True)
# 保存
sf.write(f"{save_name}.wav", audio, SAMPLE_RATE)
print(f"✅ 已保存: {save_name}.wav")
# 快速可视化
visualizer.plot_waveform(audio, f"{save_name}_waveform.png")
# 情绪分析
emotion = visualizer.extract_emotion_features(audio)
print(f"情绪分析: {emotion}")
return audio
if __name__ == "__main__":
# 运行主流程
main()
# 示例:快速生成不同风格的音乐
print("\n" + "=" * 60)
print("🎵 示例:快速生成测试")
print("=" * 60)
# 测试不同风格
test_prompts = [
("欢快的电子舞曲,强节奏", "electronic_dance"),
("悲伤的小提琴独奏,慢节奏", "sad_violin"),
("激昂的摇滚吉他", "rock_guitar"),
("放松的环境音乐,自然声音", "ambient_nature"),
]
for prompt, name in test_prompts[:1]: # 只测试第一个以节省时间
quick_generate(prompt, duration=5, save_name=name)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号