使用 Elastic Workflows 构建自动化
原创
使用 Elastic Workflows 构建自动化
原创
点火三周
发布于 2026-02-08 11:41:47
发布于 2026-02-08 11:41:47
Elastic Workflows 是一个内置于 Elasticsearch 平台的自动化引擎。您可以在 YAML 中定义工作流,包括触发条件、执行步骤和具体动作,平台负责执行。工作流可以查询 Elasticsearch、转换数据、基于条件分支、调用外部 API,并通过您已配置的连接器与 Slack、Jira、PagerDuty 等服务集成。
在这篇博客中,我们将介绍 Workflows 的核心概念,并一起构建一个示例工作流。
Workflows 以声明方式在 YAML 中定义
工作流是可组合的。您定义应该发生的事情,平台则处理执行、错误恢复和日志记录。每个工作流都用 YAML 定义,并存放在 Kibana 中。
一个工作流由几个关键部分组成:触发器、输入和步骤。
触发器 决定工作流何时运行。警报触发器在 Kibana 警报规则触发时运行,具有完全访问警报上下文的权限。计划触发器基于间隔或 cron 模式运行。手动触发器通过 UI 或 API 按需运行。一个工作流可以有多个触发器。
输入 定义可以在运行时传递给工作流的参数。这让您可以创建可重用的工作流,根据调用方式接受不同的值。
步骤 是工作流执行的动作。它们按顺序执行,每个步骤可以引用前一步骤的输出。步骤类型包括:
- 内部动作:在 Elasticsearch 和 Kibana 内执行的操作,如查询索引、运行 Elasticsearch Query Language (ES|QL) 查询、创建案例或更新警报。
- 外部动作:在外部系统上执行的操作,如发送 Slack 消息或创建 Jira 工单。您可以使用 Elastic 中配置的任何连接器,灵活地通过 HTTP 步骤调用任何 API 或内部服务。
- 流程控制:使用条件、循环和并行执行定义工作流逻辑。
- AI:从提示 大型语言模型 (LLM) 到将代理作为工作流步骤,解锁代理性工作流用例。
实践:创建您的第一个工作流
让我们构建一个展示核心功能的工作流:操作 Elasticsearch 索引、条件逻辑和步骤之间的数据流。我们将创建一个简单的演示,设置国家公园索引、加载示例数据并进行搜索。
启用 Workflows
Workflows 在 Elastic 9.3(技术预览版)中可用。进入 Stack Management → Advanced Settings,启用 Elastic Workflows:
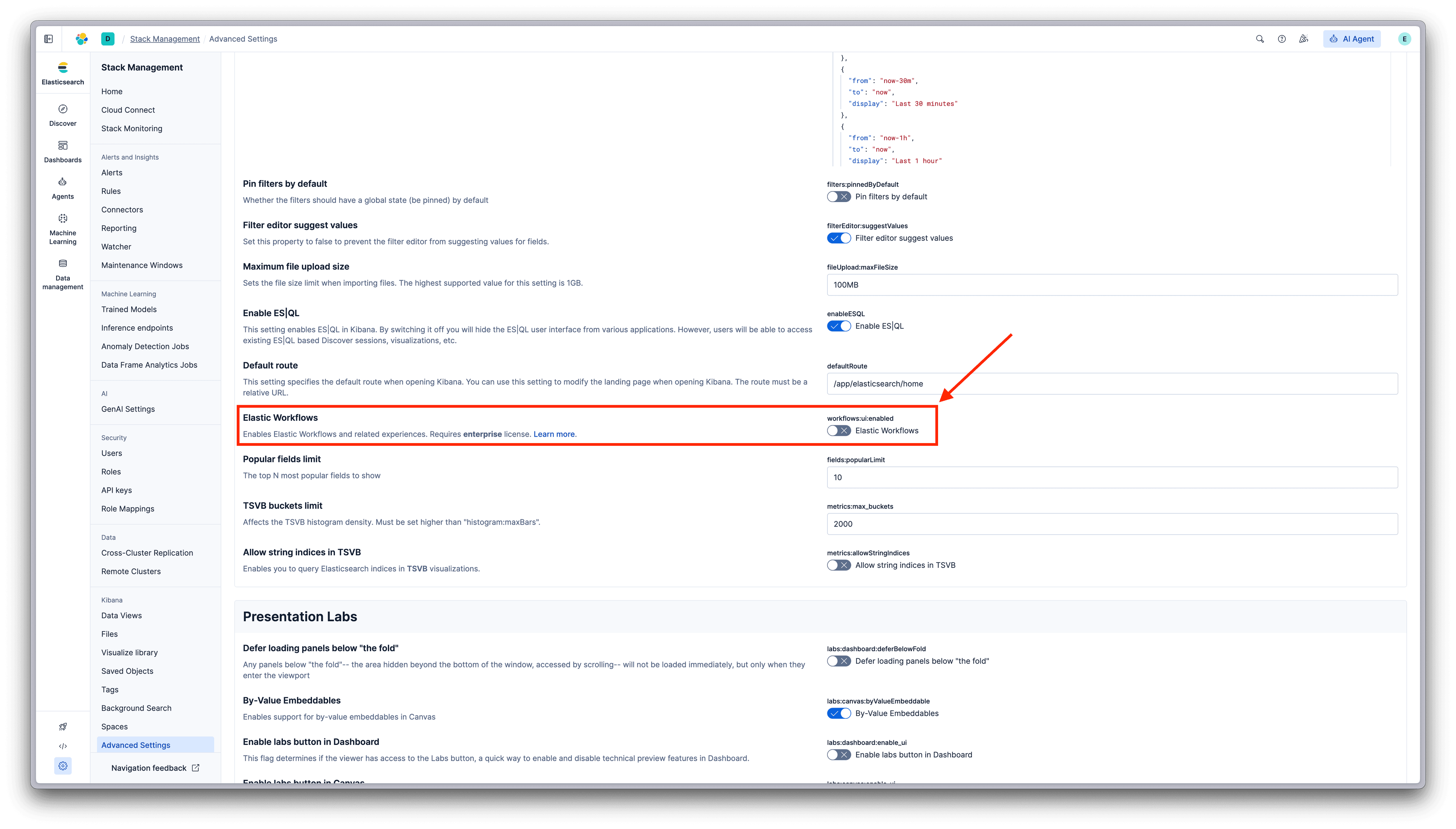
启用 Elastic Workflows
创建一个工作流
在 Kibana 中导航到 Workflows。如果这是您第一次使用,您将看到开始屏幕:
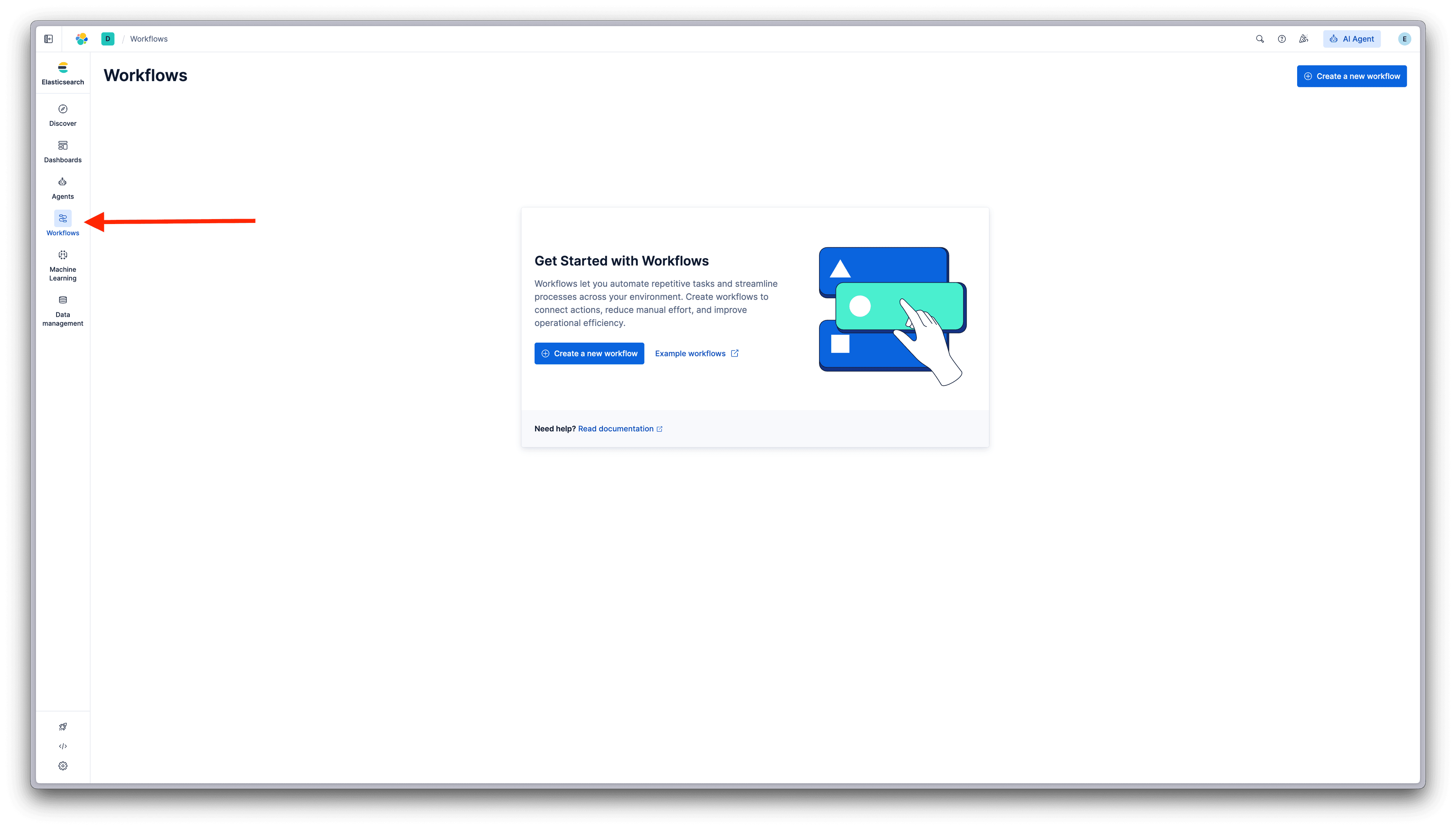
创建新的 Elastic Workflow
点击 Create a new workflow 打开编辑器。您还可以探索 Example workflows 来查看 Elastic Workflow Library,这是一个可用于搜索、可观测性和安全性用例的工作流集合。
工作流编辑器
编辑器提供 YAML 编辑,带有自动补全和验证功能。开始输入步骤类型时,会出现建议。使用 快速操作菜单(Cmd+K / Ctrl+K)按类别浏览可用的触发器、步骤和动作:
工作流编辑器
构建工作流
以下是我们的国家公园演示工作流:
name: National Parks Demo
description: Creates an Elasticsearch index, loads sample national park data, searches for parks, and displays the results.
enabled: true
consts:
indexName: national-parks
triggers:
- type: manual
steps:
- name: get_index
type: elasticsearch.indices.exists
with:
index: '{{ consts.indexName }}'
- name: check_if_index_exists
type: if
condition: 'steps.get_index.output: true'
steps:
- name: index_already_exists
type: console
with:
message: 'index: {{ consts.indexName }} already exists. Will proceed to delete it and re-create'
- name: delete_index
type: elasticsearch.indices.delete
with:
index: '{{ consts.indexName }}'
else:
- name: no_index_found
type: console
with:
message: 'index: {{ consts.indexName }} not found. Will proceed to create'
- name: create_parks_index
type: elasticsearch.indices.create
with:
index: '{{ consts.indexName }}'
mappings:
properties:
name:
type: text
category:
type: keyword
description:
type: text
- name: index_park_data
type: elasticsearch.index
with:
index: '{{ consts.indexName }}'
id: yellowstone
document:
name: Yellowstone National Park
category: geothermal
description: "America's first national park, established in 1872, famous for Old Faithful geyser and diverse wildlife including grizzly bears, wolves, and herds of bison and elk."
refresh: wait_for
- name: search_park_data
type: elasticsearch.search
with:
index: '{{ consts.indexName }}'
query:
term:
_id: yellowstone
- name: log_results
type: console
with:
message: 'Found {{ steps.search_park_data.output.hits.total.value }} park with doc id of yellowstone.'这个工作流展示了几项功能:
- 常量: 定义可重复使用的值,如
indexName,在整个工作流中引用。 - Elasticsearch 操作: 检查索引是否存在,删除它,创建它并设置映射,索引一个文档并进行搜索。
- 条件逻辑与分支: 如果索引存在,记录消息并删除它。如果不存在,记录未找到的消息。无论如何,继续创建索引。
- 数据流: 每个步骤通过
steps.<name>.output引用前一步骤的输出。
注意这里的 {{ }} 语法。这是用于在步骤之间传递数据的 Liquid 模板语法。consts 包含工作流常量,steps.<name>.output 引用前一步骤的输出。
运行工作流
保存工作流,点击 Save 按钮旁的 Play 按钮执行它。
工作流开始执行,您将看到执行视图。每个步骤在侧边栏中按顺序显示,显示状态和时间:
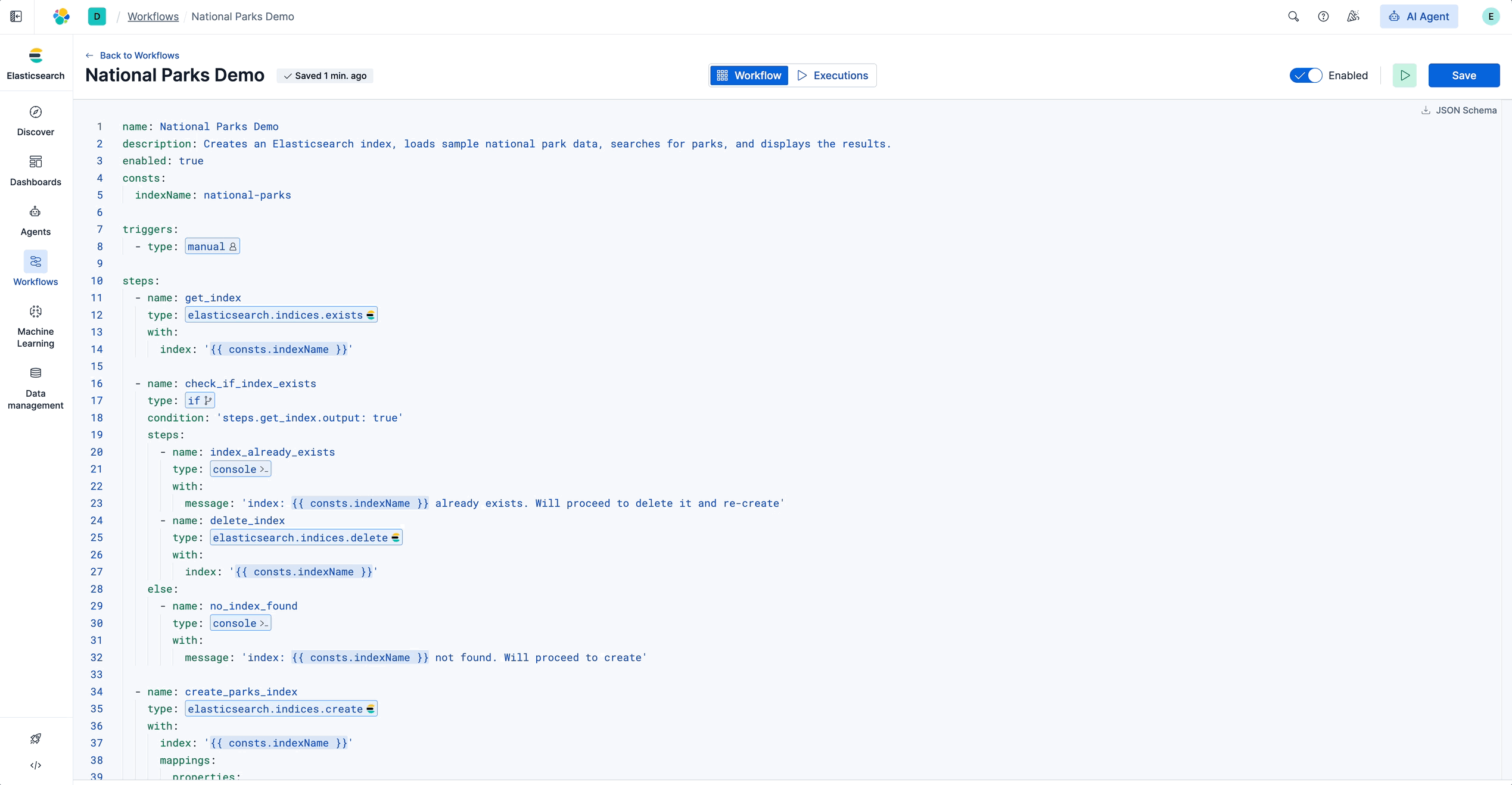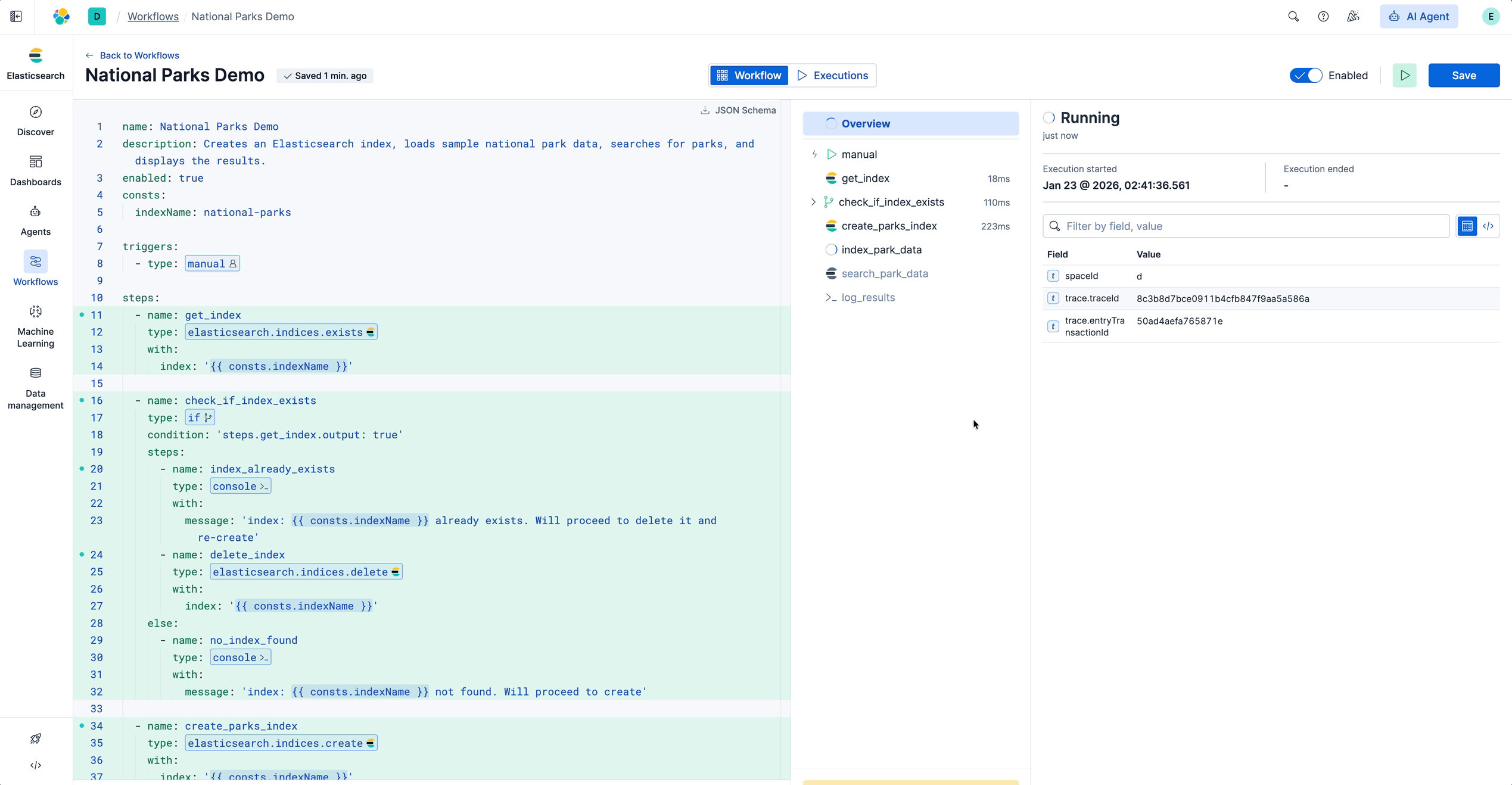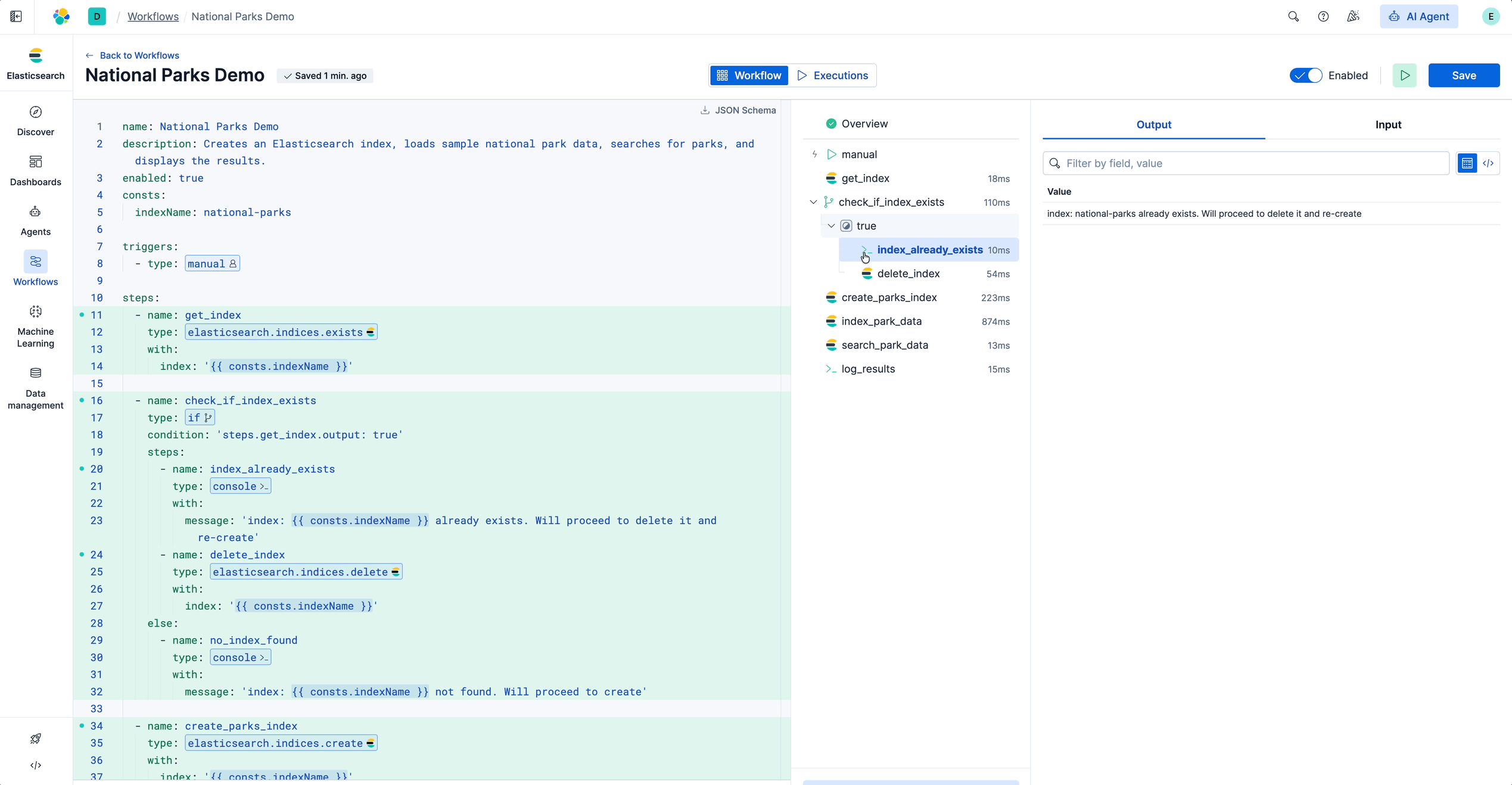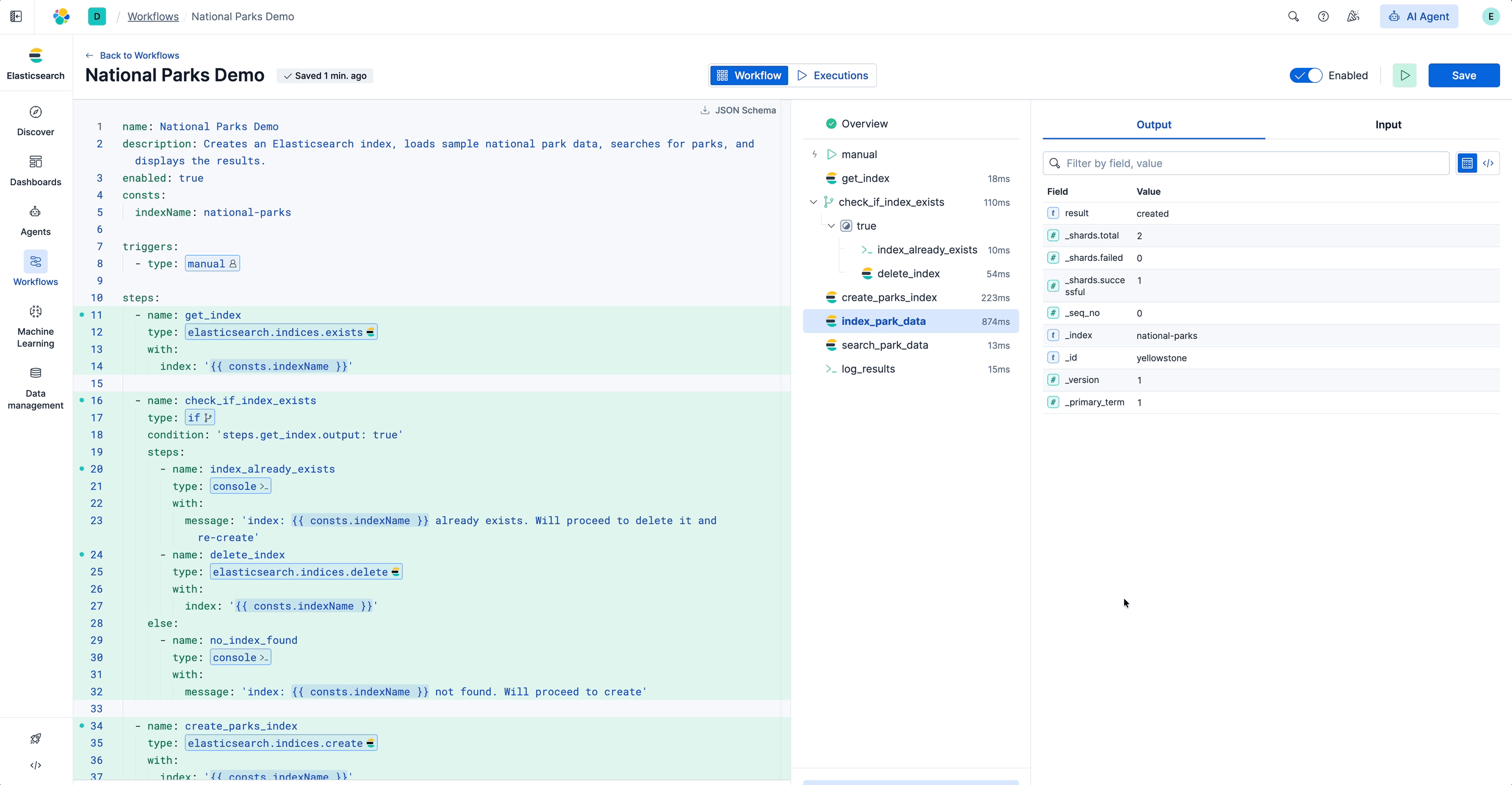
运行工作流
点击任意步骤查看其输入和输出。侧边栏清晰显示了工作流在每个步骤接收和产生的数据。这使得调试变得简单:您可以看到输入、输出以及如果步骤失败,问题出在哪里。
扩展工作流
让我们通过 AI 和外部通知来扩展这个工作流。我们将添加一个步骤,用 LLM 生成关于公园的诗歌,然后将其发送到 Slack。
在 log_results 之后添加这些步骤:
- name: generate_poem
type: ai.prompt
with:
prompt: >
Write a short, fun poem about {{ steps.search_park_data.output.hits.hits[0]._source | json }}.
Include something about its famous features. No other formatting.
- name: share_poem
type: slack
connector-id: my-slack-connector
with:
message: |
🏔️ *Poem of the Day about Yellowstone*
{{ steps.generate_poem.output.content }}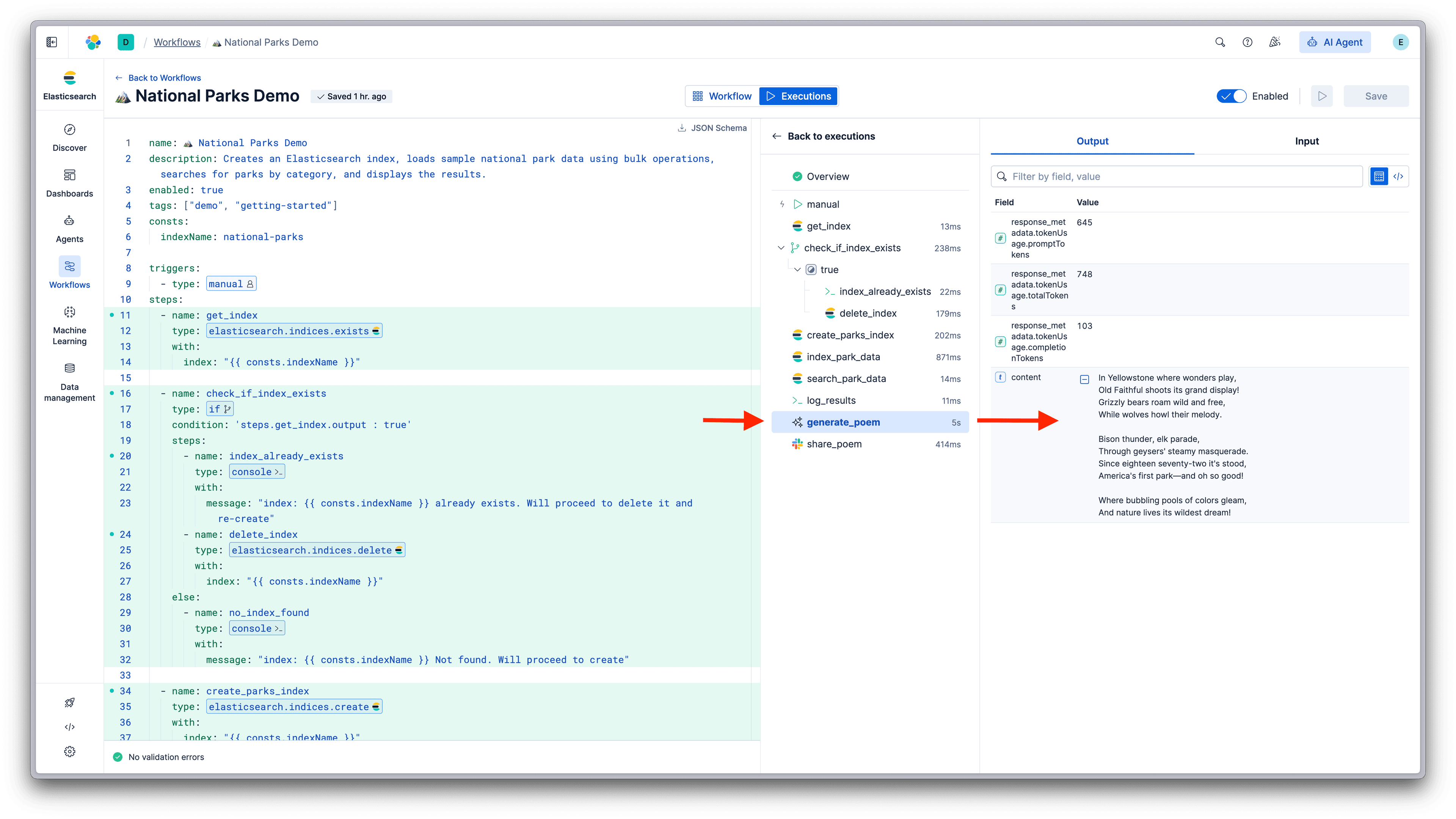
启用 Elastic Workflow
现在,工作流创建索引、加载数据、搜索数据、用 AI 生成诗歌,并分享至 Slack。相同的模式贯穿始终:添加步骤,引用其输出,并让工作流处理执行。
这是一个简单的示例,但相同的方法可以扩展到实际用例。将国家公园替换为安全警报、可观测性指标或 Elasticsearch 中的任何数据。将诗歌替换为 AI 摘要或评估。将 Slack 替换为 Jira、PagerDuty 或您配置的任何连接器。
Workflows 和 Elastic Agent Builder
国家公园示例演示了 Workflows 的核心组件:触发器、步骤、条件逻辑、数据流、AI 提示和外部通知。这些组件可以结合起来构建自动化,协调 Elasticsearch、Kibana、外部系统和 AI 内的结果。
这涵盖了步骤已知的过程。但对于那些不确定的过程呢?其中正确的动作取决于您发现了什么,而您发现的又取决于您在哪里寻找?
这就是 Agent Builder 扩展自动化能力的地方。一个植根于您的操作环境的代理可以执行通常由分析师或开发人员手动完成的初步分析或调查。它可以探索、跨数据源推理并揭示发现。然后工作流继续执行接下来的结构化步骤。
Workflows 与 Agent Builder 集成,且集成是双向的。
作为工作流步骤的代理
使用 ai.agent 步骤类型在工作流中调用代理:
- name: analyze
type: ai.agent
with:
agent_id: my-analyst-agent
message: 'Analyze this data and recommend next steps: {{ steps.search.output | json }}'代理使用其配置的工具来查询索引、关联数据并跨结果进行推理。工作流等待发现并继续执行下一步。
作为代理工具的工作流
工作流还可以作为工具暴露给 Agent Builder,允许代理在需要采取行动时调用它们。
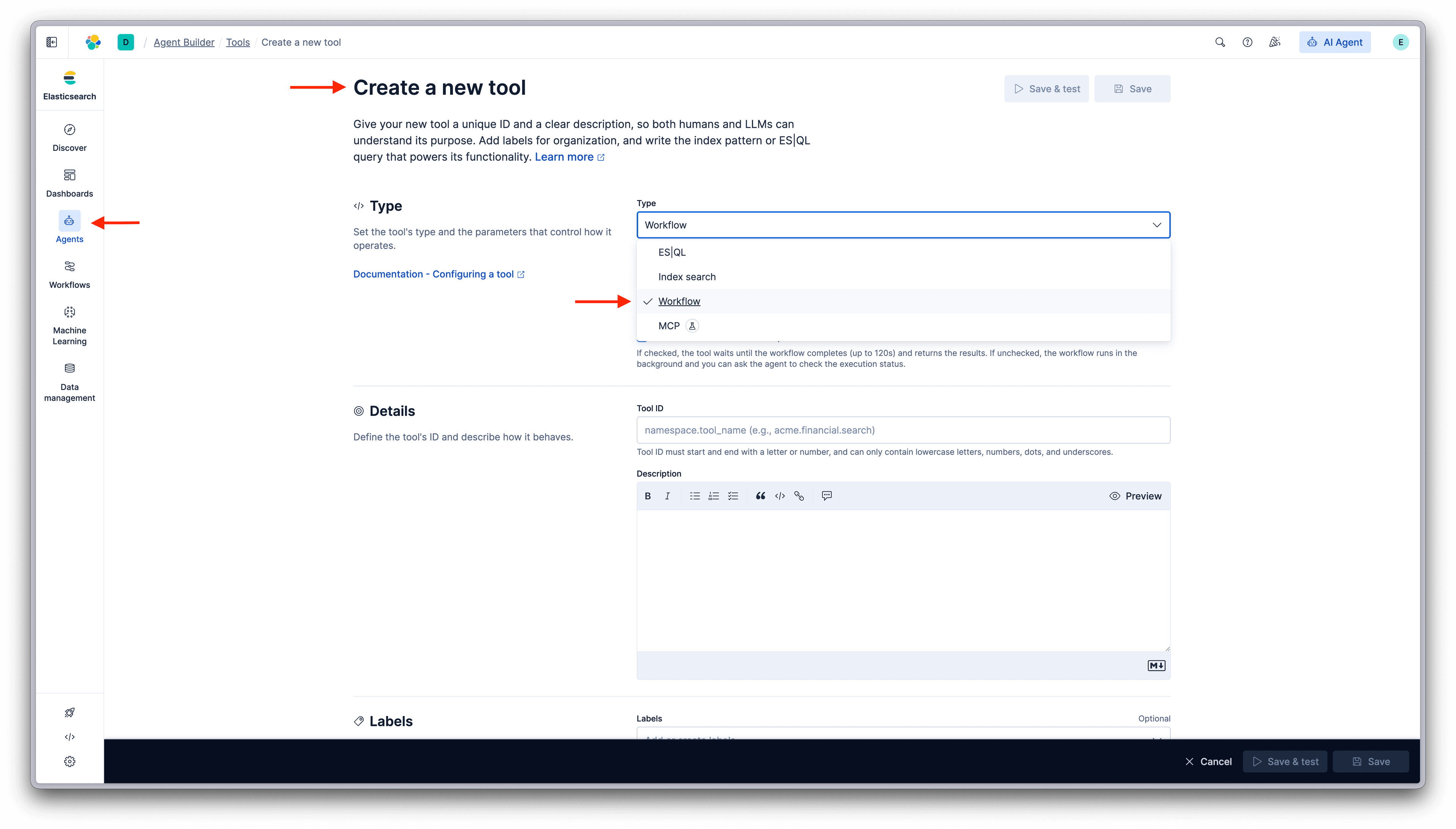
作为代理工具的工作流
这种模式在代理确定应该做什么时非常有用,但执行应该遵循一个已知且可重复的过程。代理非常适合推理、探索和判断,尤其是在信息不完整或不断变化时。工作流则非常适合执行涉及多个步骤、外部系统和状态更改操作的已建立程序。
通过将工作流暴露为工具,您可以将决策与执行分开。代理可以得出需要特定结果的结论,如声明事件或启动响应,然后将执行委派给编码正确动作顺序的工作流。该工作流负责跨系统的协调,每次都应用相同的逻辑,并使结果可观察和可审计。
这也实现了重用和一致性。相同的工作流可以由不同的代理调用或手动运行,同时实施共享的过程和控制集。无需教每个代理如何安全正确地执行复杂操作,这个责任集中在一个地方。
结合起来,这创造了一个明确的契约。代理决定何时需要采取行动。工作流确保每次行动都遵循正确的过程。
展望未来
这个技术预览将 Workflows 确立为 Elasticsearch 平台的核心能力。基础已经建立:触发器、步骤、数据流、AI 集成和与 Agent Builder 的双向连接。
接下来的发展将基于此基础,扩展工作流的创作方式及其展示位置。除了新的步骤类型和更广泛的连接器支持,Workflows 将支持多种创作模式。这些包括自然语言意图,AI 帮助将您的目标转化为可行的工作流,以及可视化的拖放构建器。随着这些功能直接嵌入到 Elastic 的特定解决方案体验中,它们不仅改变了工作流的构建方式,还改变了工作的实际完成方式。
对于开发者而言,这意味着超越对话的 AI 助手。能够实际执行操作的代理:查询系统、更新记录、触发流程并返回结果。可靠执行支持的推理。
在可观测性中,这意味着从日志、指标和跟踪中关联信号。揭示可能的根本原因。协调补救步骤。无需等待人工干预即可在检测与解决之间闭环。
在安全性中,这意味着警报触发后即刻开始调查。通过内部和外部来源的上下文充实发现。跨工具协调响应操作。更新案例并通知相关人员。过去需要手动完成的工作,现在由自动化处理。
您今天学习的模式直接适用于这些体验。Workflows 是使它们成为可能的自动化层。
开始使用 Elastic Workflows
Elastic Workflows 目前作为技术预览版提供。通过 Elastic Cloud 试用 开始,并查看 文档 或 示例工作流库 了解更多信息。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号