从 C 的栈到 C++ 的类:代码结构与封装的艺术

从 C 的栈到 C++ 的类:代码结构与封装的艺术

云泽808
发布于 2025-12-30 17:52:59
发布于 2025-12-30 17:52:59
前言
大家好啊,我是云泽Q,一名热爱计算机技术的在校大学生。近几年人工智能技术飞速发展,为了帮助大家更好地抓住这波浪潮,在开始正文之前,我想先为大家推荐一个非常优质的人工智能学习网站)。它提供了从基础到前沿的系列课程和实战项目,非常适合想要系统入门和提升AI技术的朋友,相信能对你的学习之路有所帮助。
一、类的定义
1.1 类定义格式
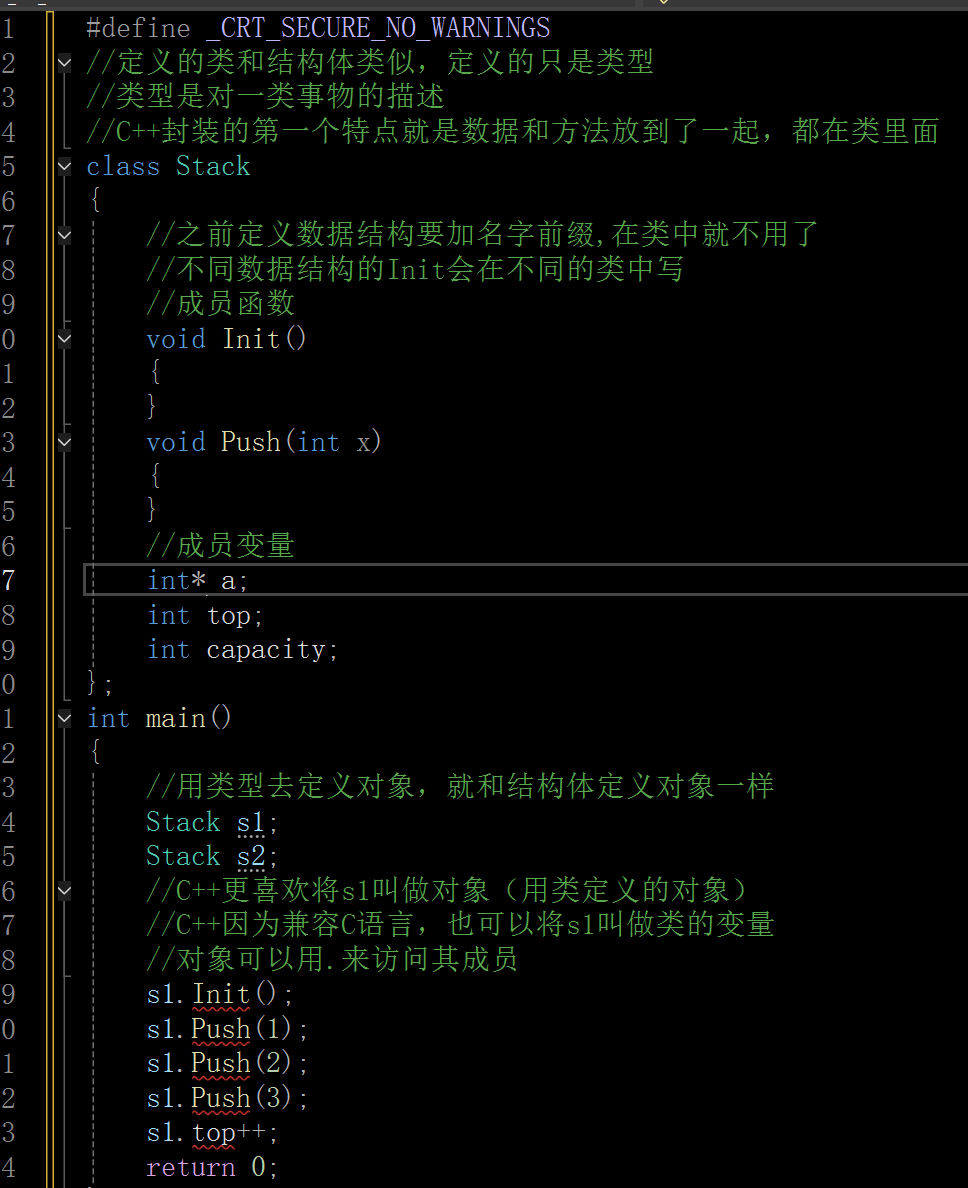
类可以按增强版的结构体来理解,它是一个复合类型,C++把语言原生代的一些类型叫做基本类型,例如int,double,char,指针。用类定义的叫做自定义类型
- class为定义类的关键字,Stack叫类的名字,{}中为类的主体,注意类定义结束时后面分号不能省略(与之相比命名空间定义的是一个域,不是一个新的类型,所以没有分号)。类体中内容称为类的成员:类中变量称为类的属性或成员变量;类中的函数称为类的方法或者成员函数。
在这里插入图片描述
C语言结构体的一大缺陷之一就是
在这里插入图片描述
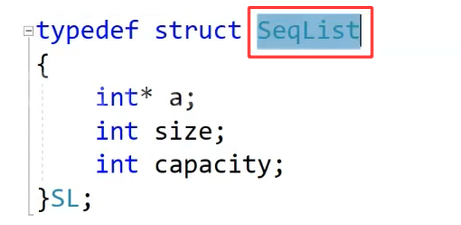
名称并不代表类型,加上struct才代表类型,写起来很麻烦,太长了,所以加了typedef来解决这样的问题 而C++设计的类就改进了,类名(Stack)就是类型,不需要加class关键字
第一张图访问不了成员变量和成员函数的原因是C++在这引入了一个封装的概念 C++自己而言,提的是面向对象,C语言是面向过程 面向对象有三大特性:封装,继承,多态 C语言在封装这里典型的特点就是,数据和方法是分离的,C++封装的第一个特点反之,C++封装的第二个特点就是访问限定符,见1.2。接下来推荐1.1,1.2结合来看
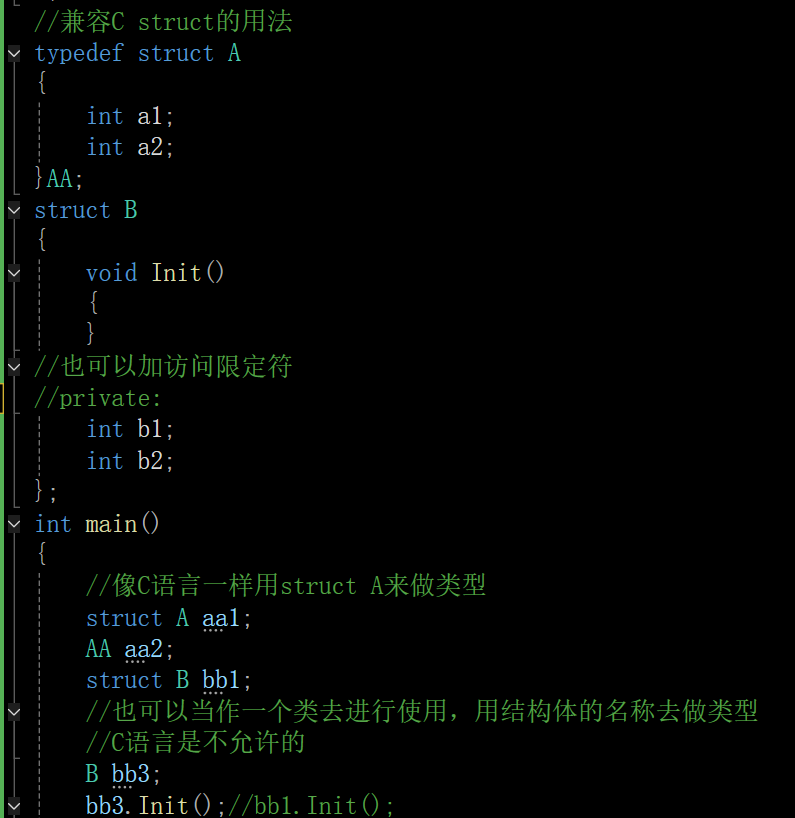
- C++中struct也可以定义类,C++兼容C中struct的用法,同时struct升级为了类,明显的变化是struct中可以定义函数,一般情况下还是推荐用class定义类
在这里插入图片描述
再补充一个特殊的点,在数据结构中定义链表节点的时候必须要像下图这样写

在这里插入图片描述
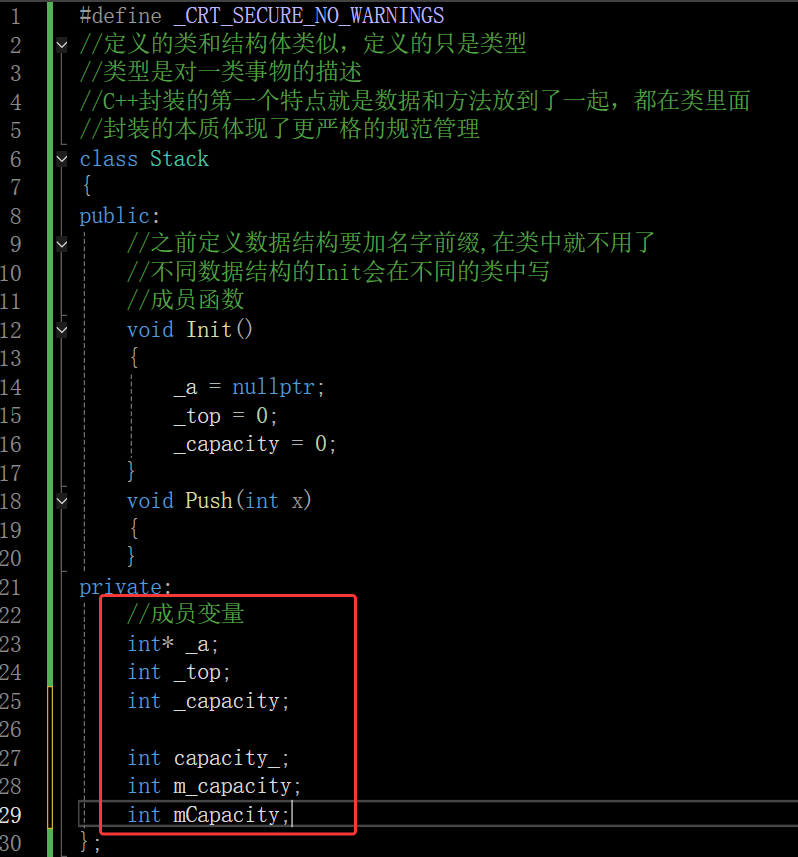
- 为了区分成员变量,一般习惯上成员变量会加一个特殊标识,如成员变量前面或者后面加_或者m开头,注意C++中这个并不是强制的,只是一些惯例,具体看公司的要求
在这里插入图片描述
如果不加这些额外的东西,有时候就会有这些场景
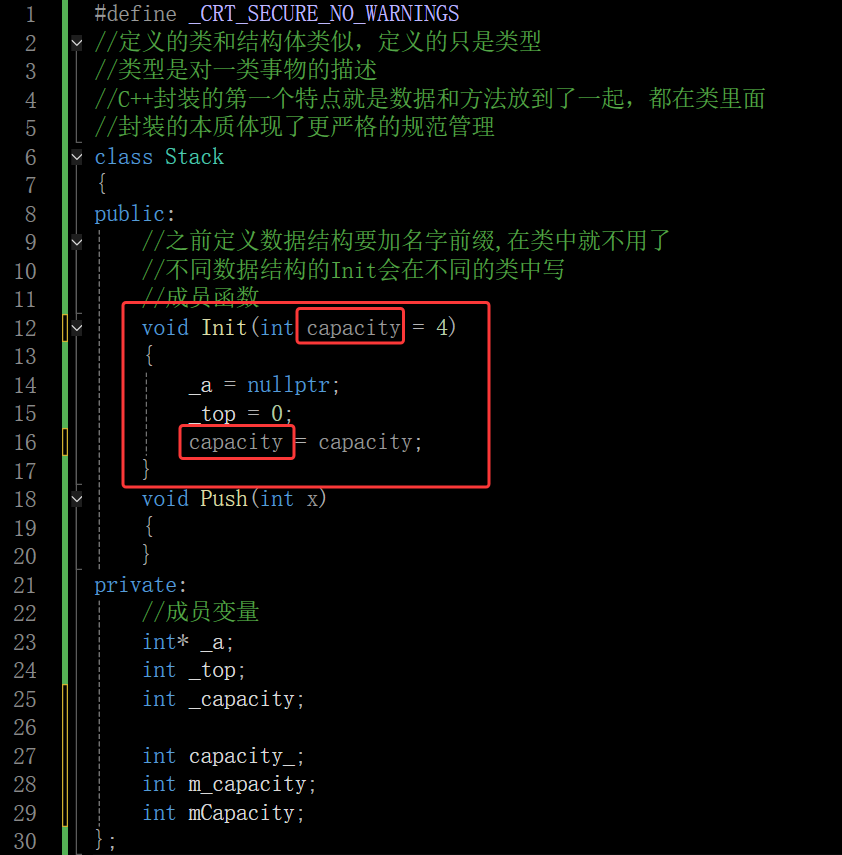
在这里插入图片描述
这时候形参和成员变量就不太分的清楚了 这里介绍两种大的规范,公司都会尊崇一种
//驼峰法(Windows) StackInit 类型 函数,单词首字母大写+单词首字母大写
// initCapacity 变量 单词首字母小写+单词首字母大写
//第二种规范(Linux) stack_init
// init_capacity- 定义在类里面的成员函数默认为inline,最终会不会称为内联还要看编译器裁决
1.2 访问限定符
- C++一种实现封装的方式,用类将对象的属性与方法(变量,函数)结合在一起,让对象更加完善,通过访问权限选择性的将其接口提供给外部的用户使用
访问限定符有3个,公有,私有和保护
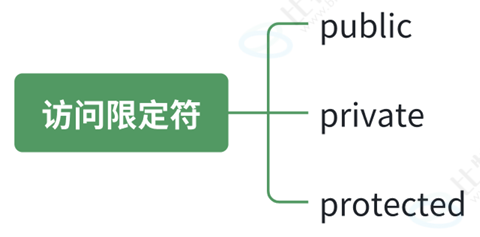
在这里插入图片描述
- public修饰的成员在类外都可以直接被访问;protected和private修饰的成员在类外不能直接被访问,protected和private是一样的,后面继承章节才能体现出他们的区别
- 访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止,如果后面没有访问限定符,作用域就到 } 即类结束
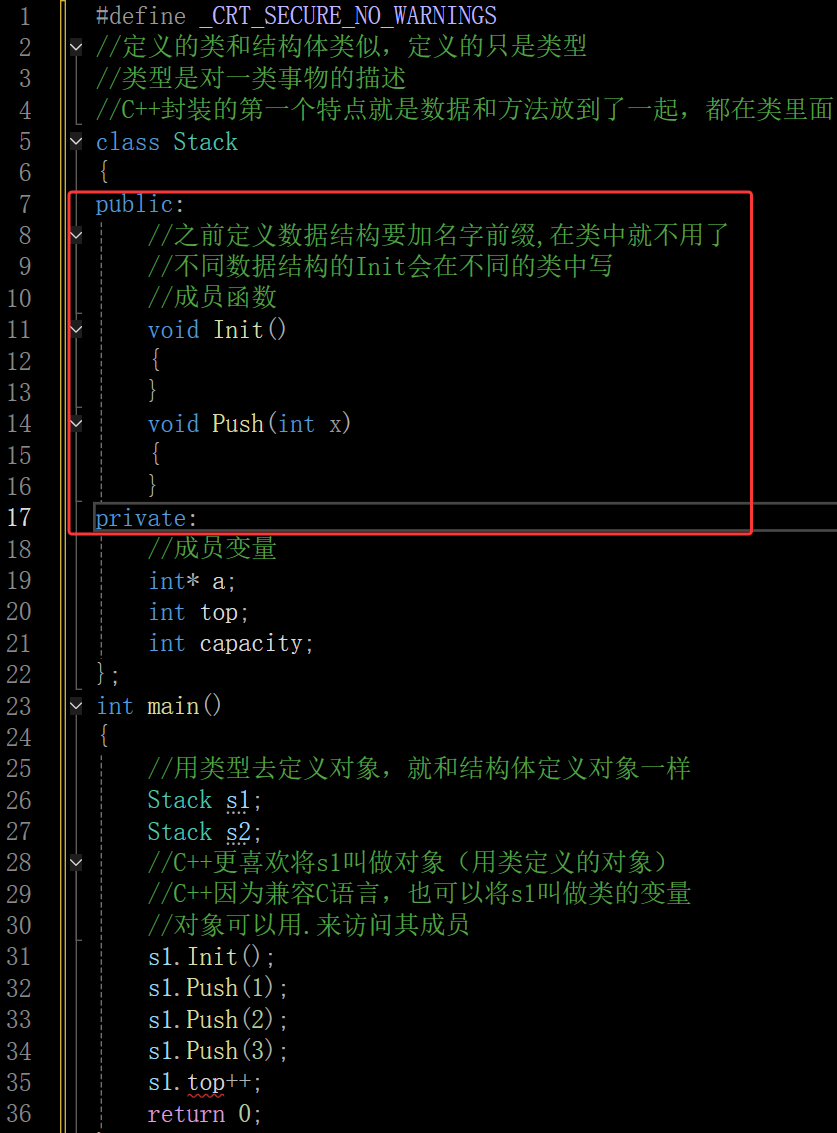
在这里插入图片描述
如图红框的区域就都是公有,从private:到 } 都是私有,定义多个公有,私有,保护也是没有问题的
- class定义成员没有被访问限定符修饰时默认为private,struct默认为public
- 一般成员变量都会被限制为private/protected,需要给别人使用的成员函数会放为public
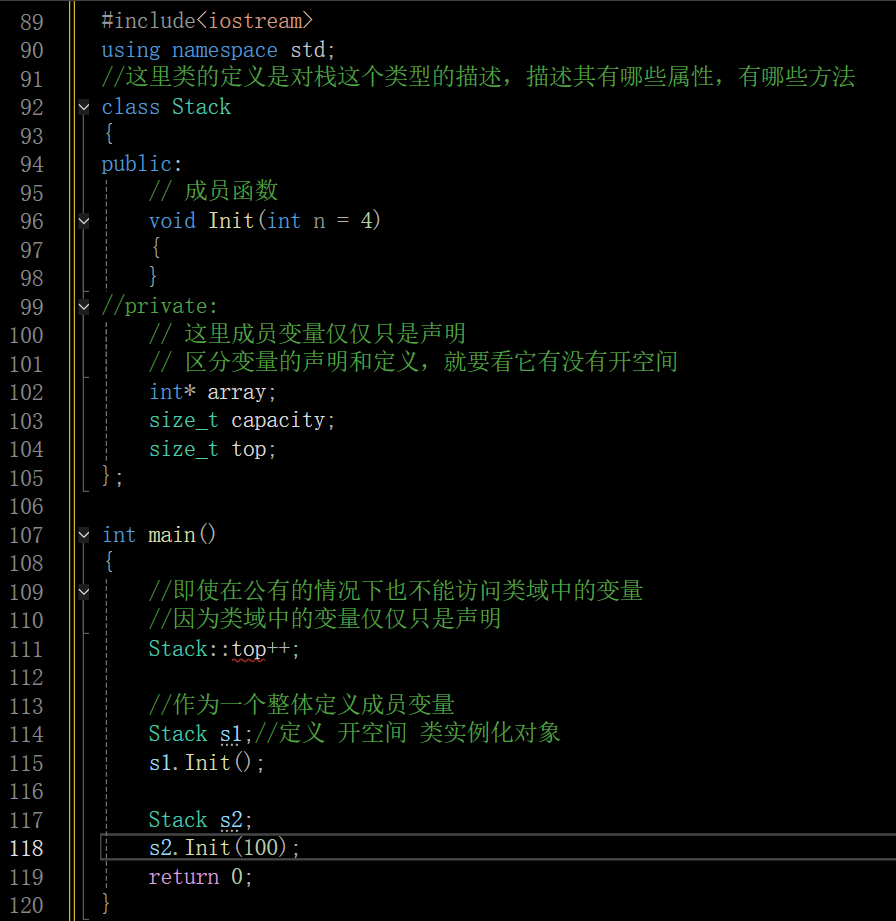
1.3 类域
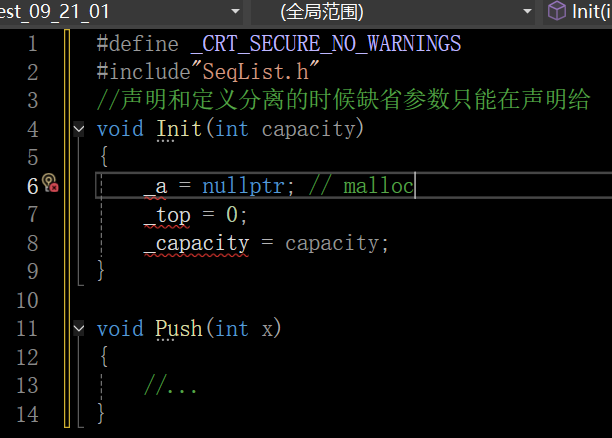
类是支持声明和定义分离的
- 类定义了一个新的作用域,类的所有成员都在类的作用域中,在类体外定义成员时,需要使用::作用域操作符指明成员属于哪个类域
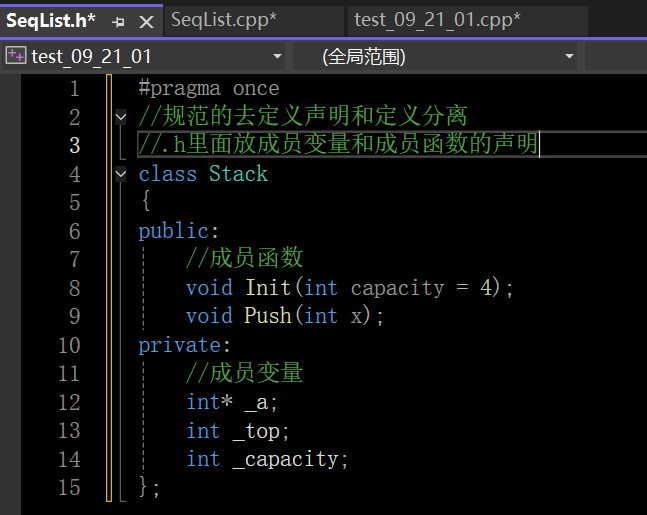
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
这样写编译是不会通过的,编译器会认为这是个全局函数(搜索变量的时候只会在局部搜索和全局搜索,不会去类中去找)
- 类域影响的是编译的查找规则,下面程序中Init如果不指定类域Stack,那么编译器就会把Init当成全局函数,那么编译时,就会报错。指定类域Stack,就表明Init这个函数是栈这个类的成员函数,此处做了声明和定义分离,这里搜索变量的原则就是先从局部搜索,再从全局搜索,同时会到类中去搜索
类之所以做声明和定义分离是为了方便维护和管理代码,有时候定义的类在项目中代码量很大,全部定义在.h里面是很不方便的
补充一下,在类里面是不存在两个同名的变量函数冲突的,他们的作用域是独立的,这里以栈和队列举例
class Stack
{
void Init();
void Push(int x);
};
class Queue
{
void Init();
void Push(int x);
};二、实例化
2.1 实例化概念
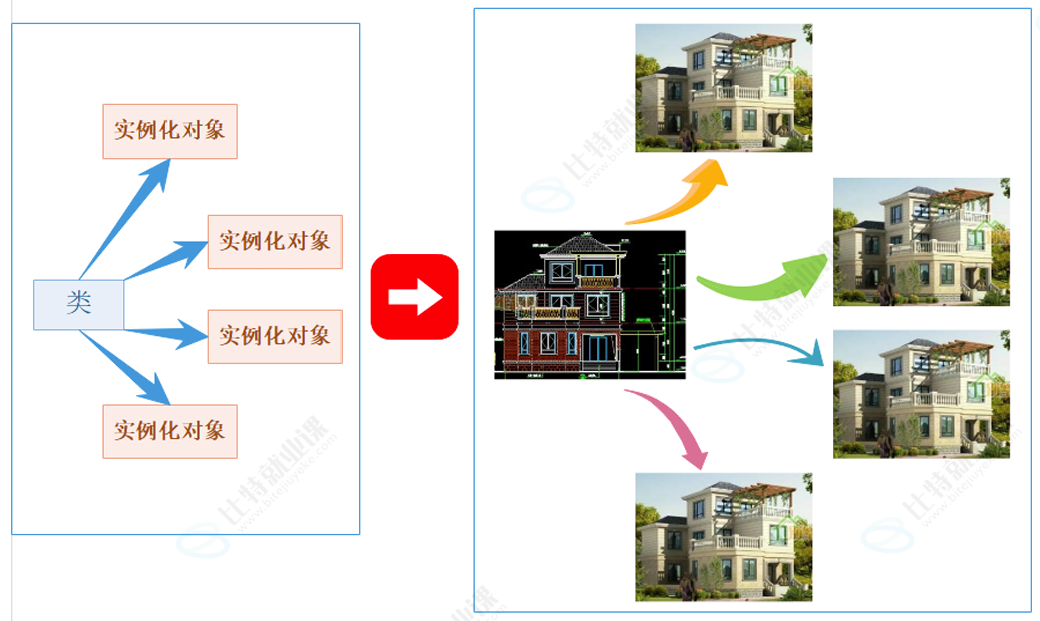
- 用类类型在物理内存中创建对象的过程,称为类实例化出对象
- 类是对象进行一种抽象描述,是一个模型一样的东西,限定了类有哪些成员变量,这些成员变量只是声明,没有分配空间,用类实例化出对象时,才会分配空间
- 一个类可以实例化出多个对象,实例化出的对象占用实际的物理空间,存储类成员变量。打个比方:类实例化出对象就像现实中使用建筑设计图建造房子,类就像是设计图,设计图规划了有多少个房间,房间大小功能等,但是并没有实体的建筑存在,也不能住人,用设计图修建出房子,房子才能住人。同样类就像设计图一样,不能存储数据,实例化出的对象分配物理内存存储数据
在这里插入图片描述
在这里插入图片描述
2.2 对象大小
类实例化出的每个对象,都有独立的数据空间,所以对象中肯定包含成员变量,那么成员函数是否包含呢?首先函数被编译后是一段指令,对象中没办法存储,这些指令储存储在一个单独公共的区域(代码段),那么对象中非要存储的话,只能是成员函数的指针。再分析一下,对象中是否有存储指针的必要呢,s1的top和s2的top不是同一个top,因为s1,s2对象的成员变量是独立的,各自的成员变量存各自的数据,但是s1的Init和s2的Init调用的是同一个函数(地址是一样的),成员变量不同要各自开空间,成员函数都是一样,如果在每个对象都存一份就是空间的浪费,可以把成员函数的指针存到对象之中,但这就很浪费了。再额外说一下,另外函数指针不需要存储的一个原因,函数指针是一个地址,调用函数被编译成汇编指令[call 地址],其实编译器在编译链接时,就要找到函数的地址,即成员函数的地址是在编译链接时确定的(如果有定义,在一个文件,就是编译时确定,如果只有声明,没有定义,就链接的时候确定),不是在运行时找,只有动态多态是在运行时找,就需要存储函数地址
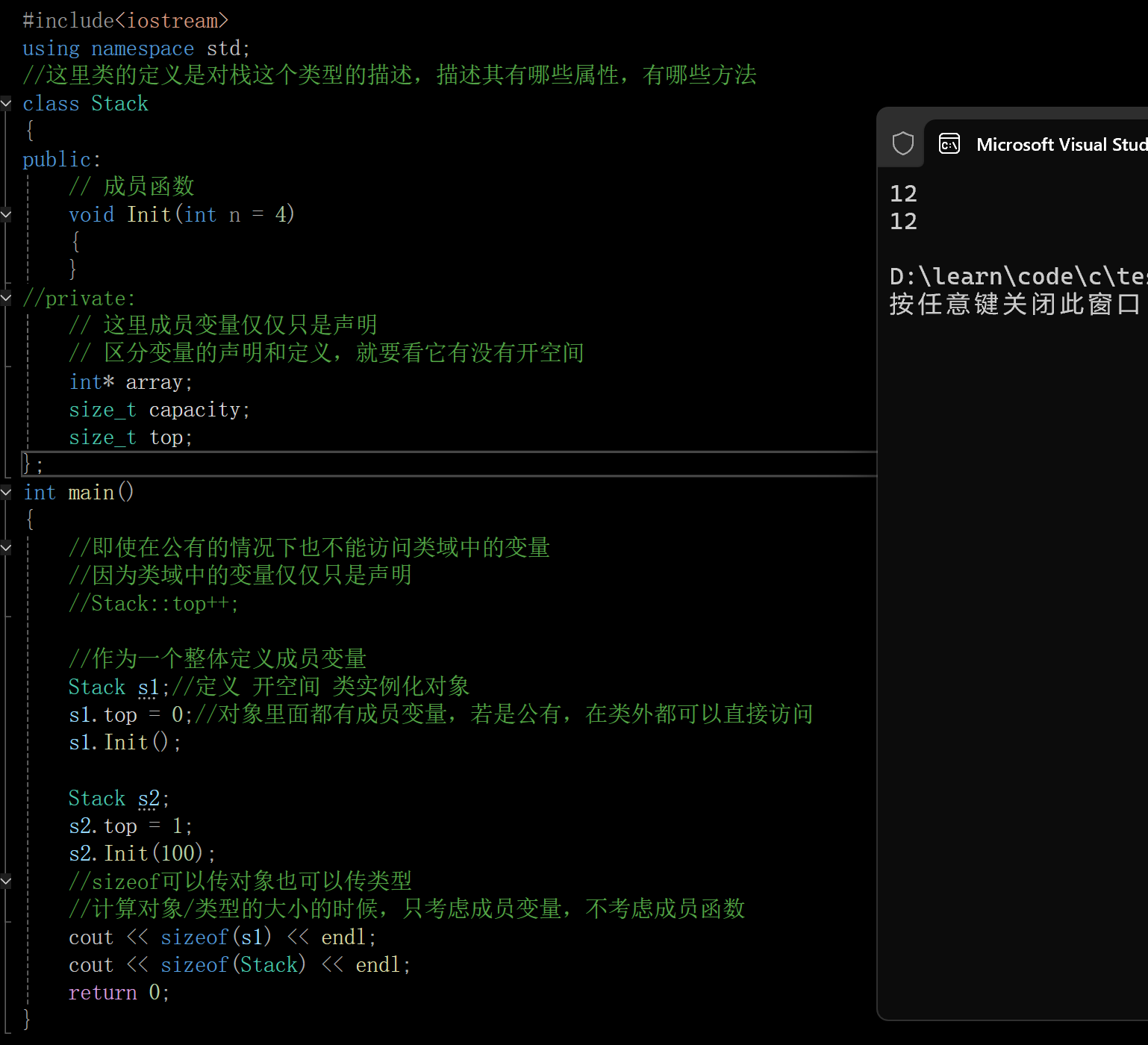
在这里插入图片描述
在这里插入图片描述
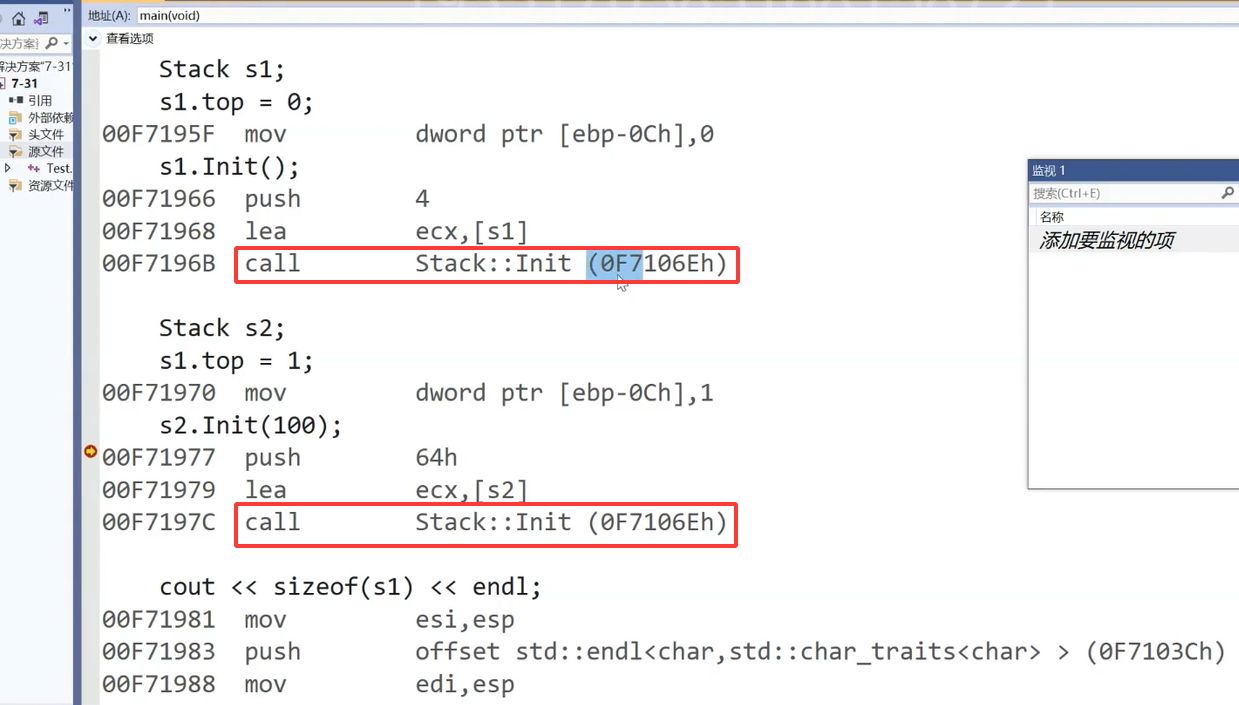
在 C++ 中,sizeof运算符既能接收对象也能接收类型作为操作数,核心源于其编译时计算的特性,具体可整合如下: sizeof是在编译阶段就确定结果的运算符,其计算不依赖程序运行时的状态。当作用于类型(如sizeof(Stack))时,编译器直接根据该类型的定义(如类Stack的成员变量布局),遵循内存对齐规则计算出该类型对象的内存占用大小 —— 此过程仅关注成员变量(成员函数存储在代码段,不占用对象内存)。 而当sizeof作用于对象(如sizeof(s1))时,编译器本质上仍是通过该对象的类型(如s1所属的Stack类型)来确定大小。它并非在运行时 “测量” 对象实际占用的内存,而是在编译时就依据其类型定义和内存对齐规则完成计算,结果与sizeof(Stack)完全一致。 这种特性使得sizeof的使用极为灵活:既可以直接针对类型计算(无需提前创建对象),也可以针对已存在的对象计算,且两种方式在本质上都是基于类型定义的编译时推导,与 C 语言结构体大小的计算逻辑(依赖成员布局和内存对齐)相通。
内存对齐:
- 第一个成员在与结构体偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
- 注意:对齐数 = 编译器默认的第一个对齐数与该成员大小的较小值
- VS中默认的对齐数为8
- 结构体总大小为:最大对齐数(所有变量类型最大者与默认对其参数取最小)的整数倍
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
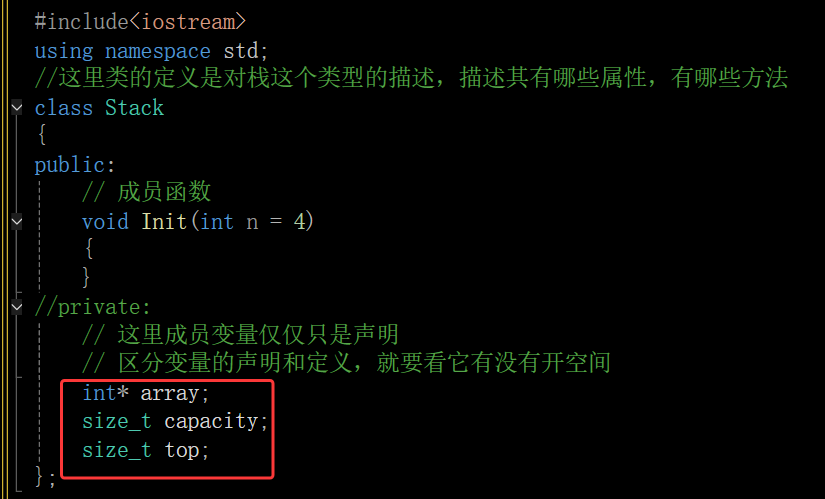
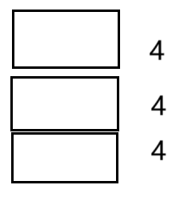
在这里插入图片描述
第一个成员变量array,在X86,32位下是4个字节,第二个成员capacity;是4个字节,相比VS下默认对齐数小,所以第二个成员还是4个字节,依次类推,最后对象整体还要对齐,最大对齐数(4)的整数倍,12是4的整数倍,没有问题
在这里插入图片描述
在这里插入图片描述
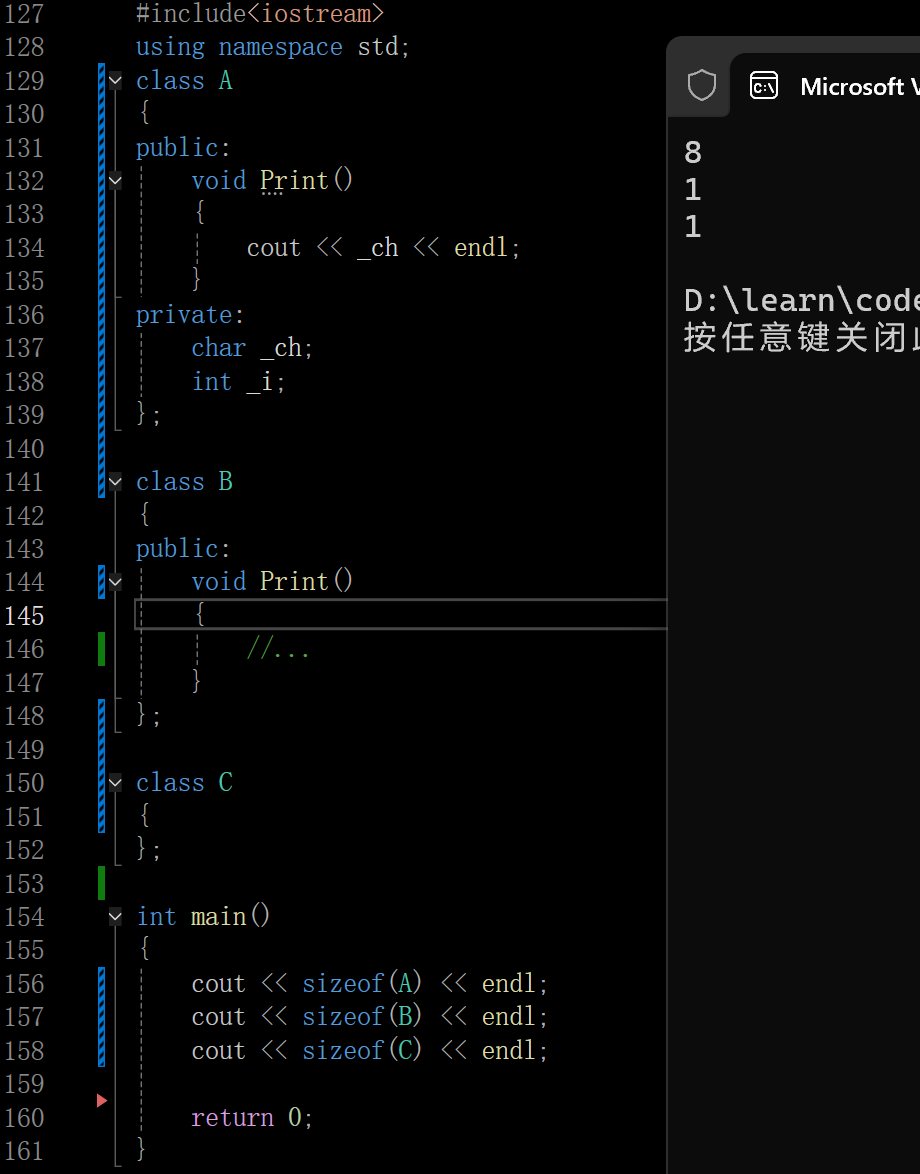
这里A的大小很好看
在这里插入图片描述
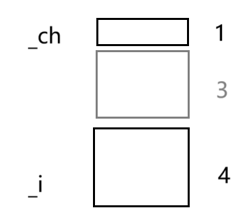
B和C一样大,C是空的,B中成员函数是不存在对象之中的,这里开一个字节是为了占位,不存储实际数据,表示对象存在过
B b1;//如果不开空间,无法判断这里B对象到底存在不存在
cout<<&b1<<endl;
//不开空间无法取地址 三、this指针
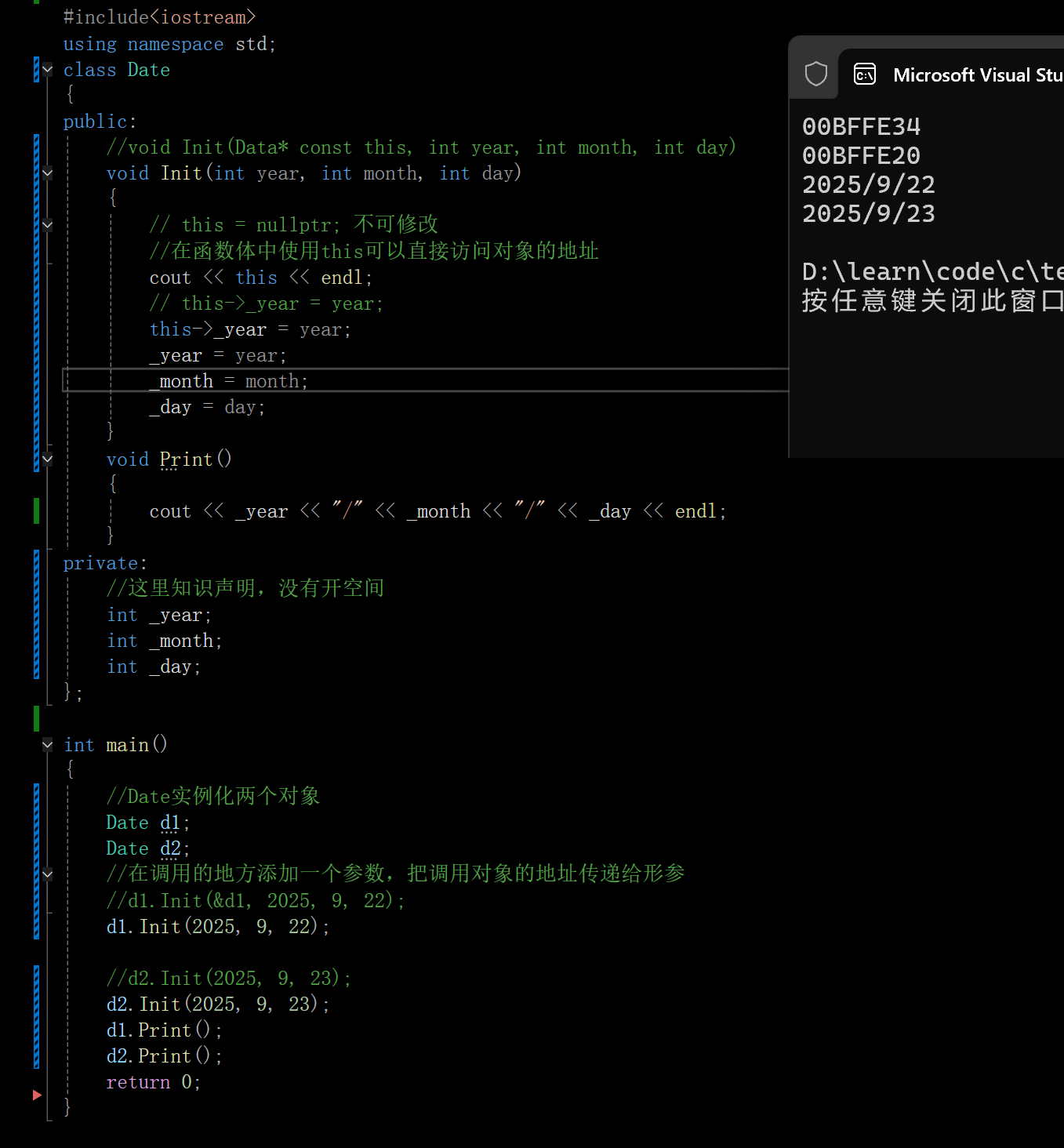
- Date类中有Init与Print两个成员函数,函数体中没有关于不同对象的区分,那当d1调用Init和Print函数时,该函数是如何知道应该访问的是d1对象还是d2对象呢?C++这里给了一个隐含的this指针解决这个问题。
- 编译器编译后,类的成员函数默认都会在形参的第一个位置,增加一个当前类类型的指针,叫做this指针。比如Date类的Init的真实原型为,void Init(Date* const this,int year,int month,int day),指针有两个const,一个是修饰指针本身,另一个是修饰指针指向的对象,* 的左边是修饰指向内容,* 的右边是修饰本身,也就是这个this指针自己是不能修改的 补充一点,const在,* 左边才涉及权限的放大与缩小
- 类的成员函数中访问成员变量,本质都是通过this指针访问的,如Init函数中给_year赋值,this->_year=year;
- C++规定不能在实参和形参的位置显示的写this指针(编译时编译器会处理),但是可以在函数体(类)内显示使用this指针
在这里插入图片描述
也就是在调用前之所以知道调用哪个对象的成员,是编译器将调用对象的地址传给了一个隐含的指针this,然后通过this来访问成员。达到了一个谁调用,就访问谁的成员变量的效果
在这里插入图片描述
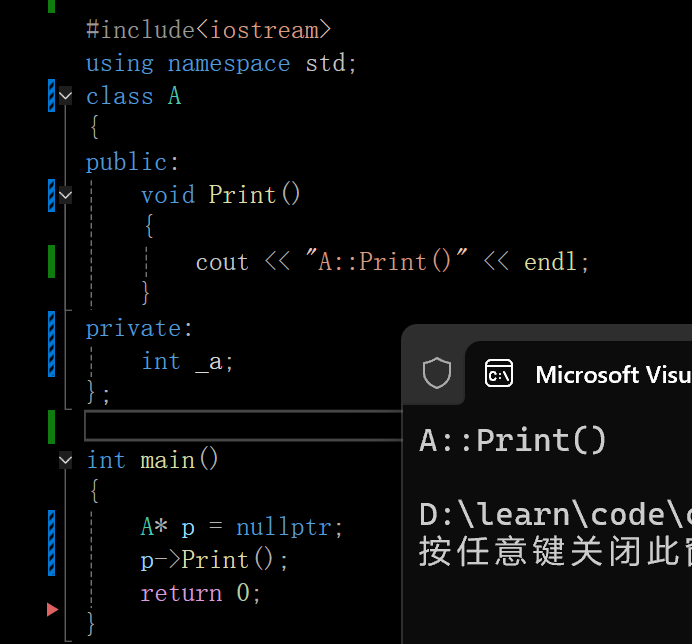
这道题看似有空指针的问题,然而却可以正确运行,指针越界不一定可以检查出来,但是空指针一定可以检查出来,所以该题就不是空指针的问题
这里看似对空指针进行解引用,这是表象。语法没有问题,本质要转换成指令,有没有解引用要看实际转换成指令的语法表达有没有需求 Print()这里要转换成call 函数地址,但是函数地址没有存到p指向的对象之中,函数的地址不是运行时去找的,是编译时就确定的,编译时编译函数拿到一段指令,有定义编译时就确定地址,只有声明的话链接时拿到地址,这里p的功能是传参,用对象调用,是取对象的地址传给this指针
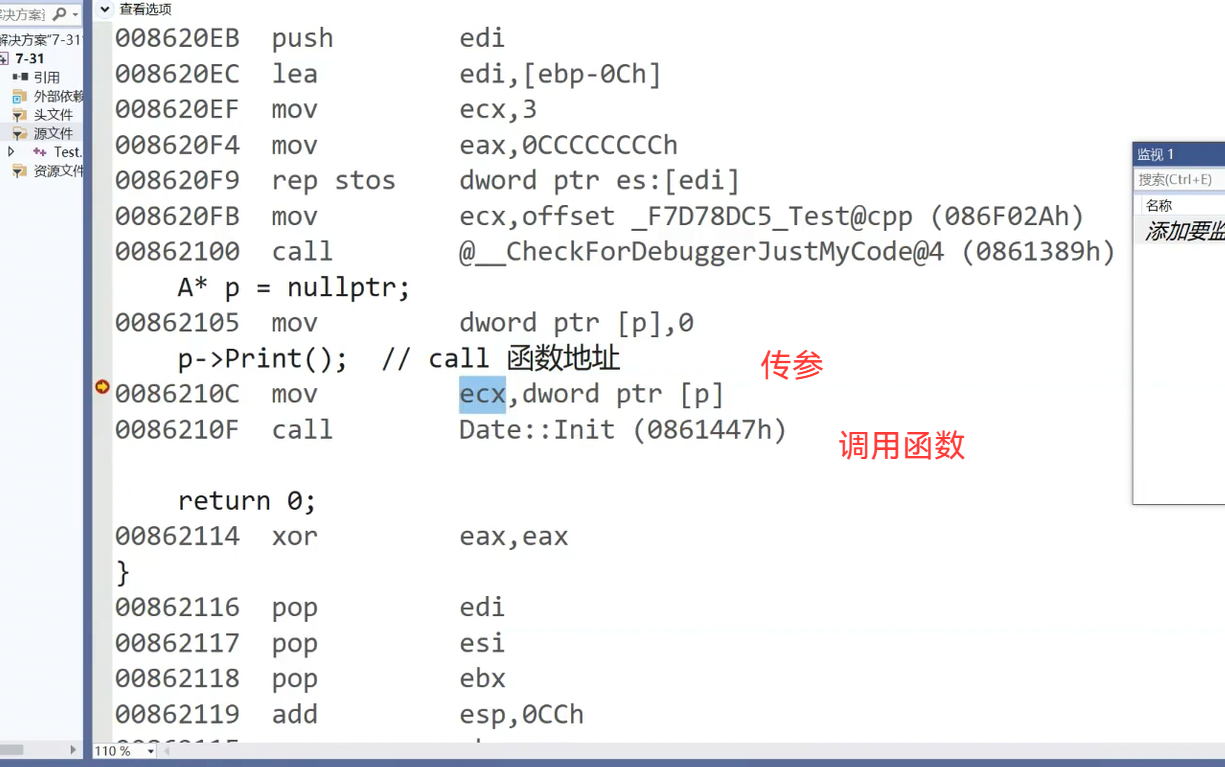
在这里插入图片描述
p本来就是对象的地址,将p的值传给一个叫ecx的寄存器,再通过寄存器传递,也就是说这里的this指针是空的
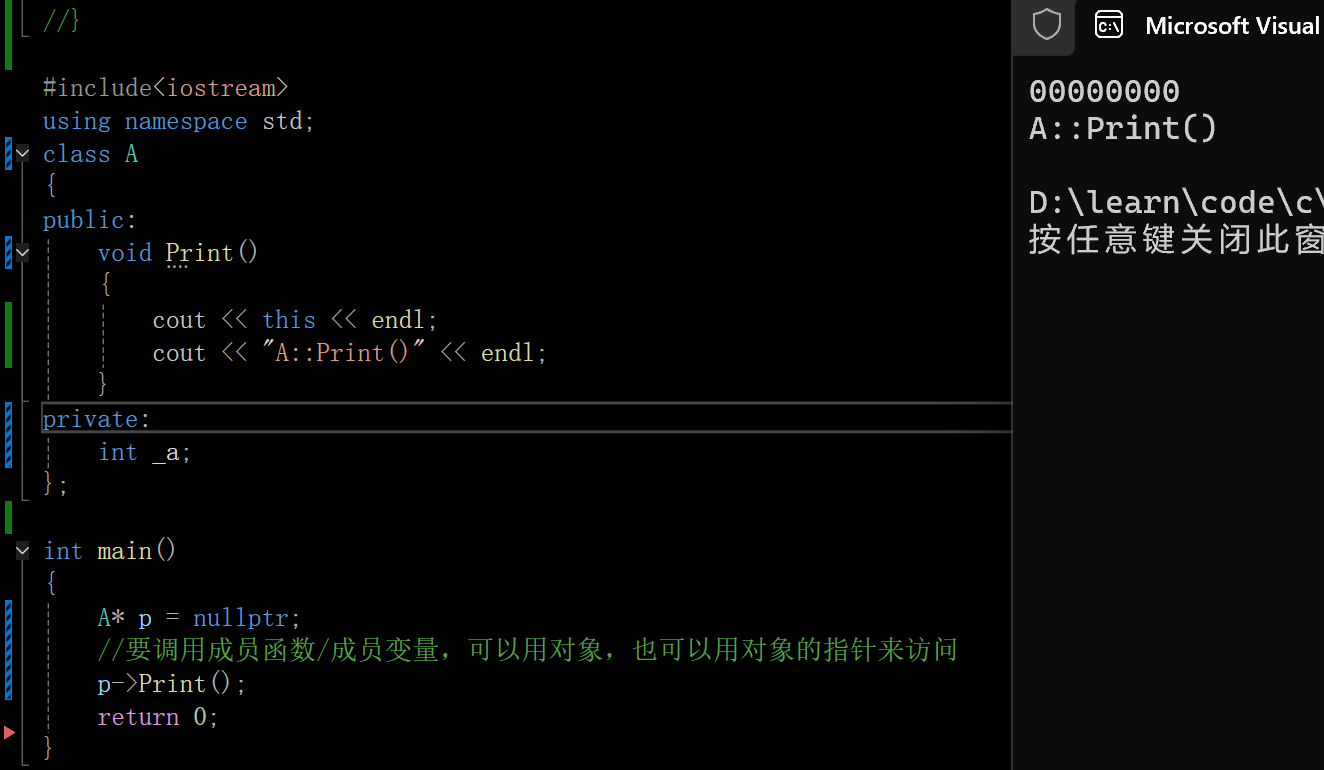
在这里插入图片描述
所以这个程序可以正常运行。空指针并不犯错,解引用空指针才犯错,接下来把p->Print();换为下面的代码,依旧可以正常运行
(*p).Print();p->Print() 的意思是:通过指针 p 调用它所指向的 A 类对象的 Print() 成员函数。 这相当于先对指针进行解引用(* p 得到指针所指向的对象),然后再访问成员。((* p).Print()),道理依旧一样,看似对空指针直接解引用了,但这只是语法的表象,编译器看到的这里的核心动作是调用Print();函数,但是函数的地址并没有存到(* p)的对象之中,没有存到对象之中就不去解引用了,单纯的调用函数是不需要对指针去解引用的,编译器不会先去解引用再取地址,可以理解编译器比你所在的维度更高
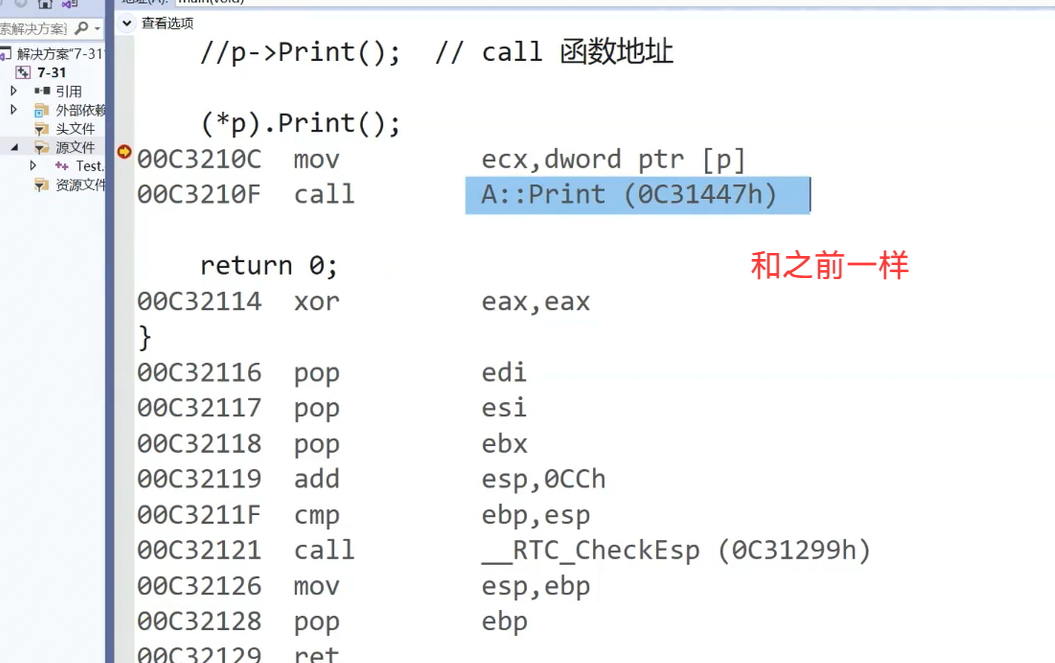
在这里插入图片描述
补充一下:编译器在遇到解引用空指针和野指针只能是运行错误,编译器无法直接检查出错,编译错误是检查语法错误,解引用空指针野指针不是语法错误,是运行逻辑错误
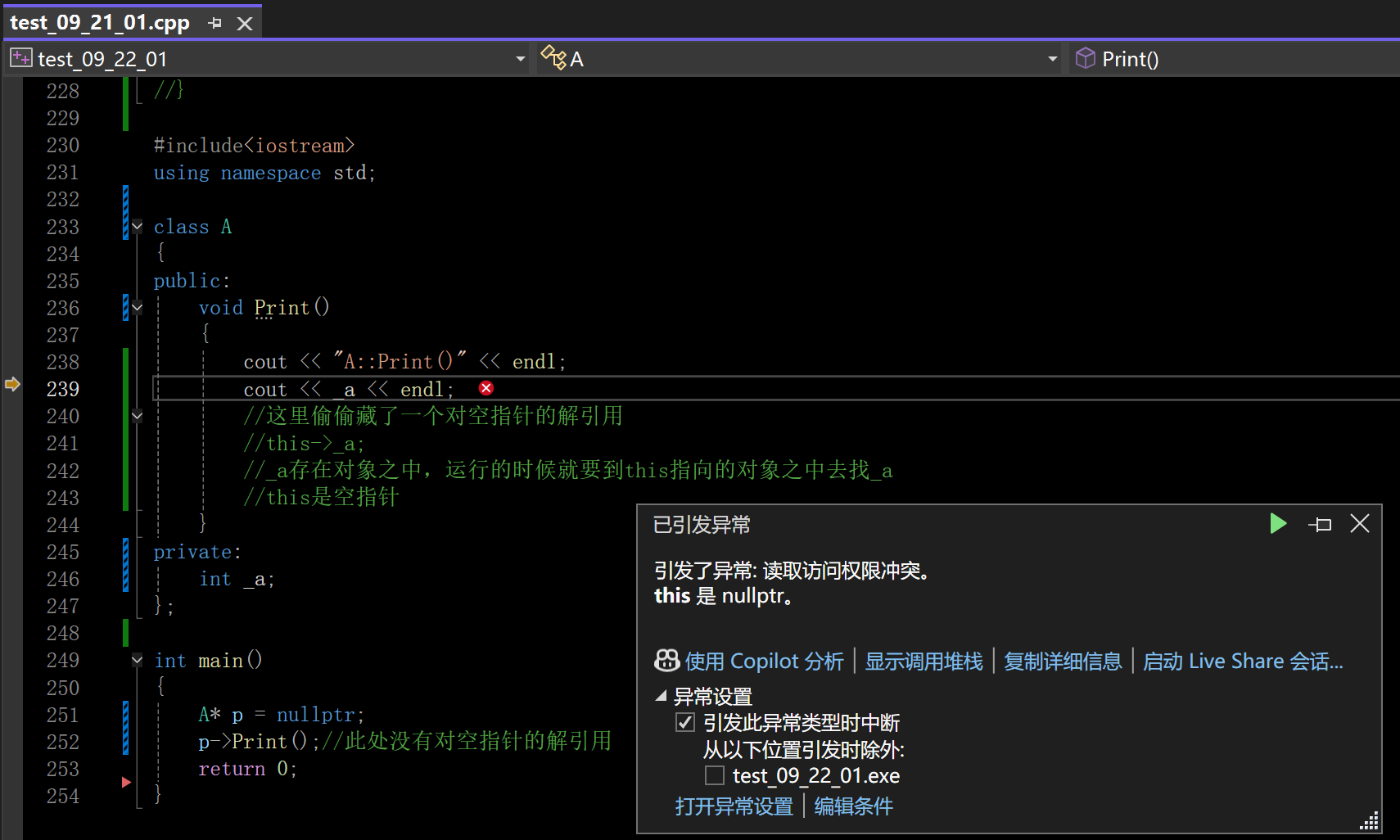
在这里插入图片描述
这题显然就是错的了,成员变量是存在对象之中的,所以有解引用
补充一下,this指针存在内存中的栈区(或寄存器),因为其是形参,形参和局部变量是类似的,形参的空间是在栈帧之中的。 因为this指针可能在函数中需要高频的访问,寄存器是比内存更快的,this指针也可能把对象的地址放到寄存器,不同的编译器实际情况不同。
四、C++和C语言实现Stack对比
- C++中数据和函数都放到了类里面,通过访问限定符进行了限制,不能再随机通过对象直接修改数据,这是C++封装的一种体现,这个是最重要的变化。这里的封装的本质是一种更严格规范的管理,避免出现乱访问修改的问题。
- C++中有一些相对方便的语法,比如Init给的缺省参数会方便很多,成员函数每次不需要传对象地址,因为this指针隐含的传递了,方便了很多,使用类型不再需要typedef用类名就很方便
虽然在C++入门阶段实现的Stack看起来变了很多,但是实质上变化不大,后面STL的文章中用适配器实现的Stack,方可感受C++的魅力
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-09-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号