基于大模型方法的文本信息抽取技术,实现高效、准确地从病历、化验单和检查报告等医疗文档中提取关键信息
原创
基于大模型方法的文本信息抽取技术,实现高效、准确地从病历、化验单和检查报告等医疗文档中提取关键信息
原创
中科逸视OCR专家
发布于 2025-12-24 19:03:34
发布于 2025-12-24 19:03:34
在数字化医疗时代,医院每天产生海量的非结构化文本数据,包括病历记录、化验报告和影像检查结论等。这些文本中蕴含的患者病史、诊断结果、用药信息和检验数值等关键字段,对临床决策、科研分析和医疗质量管理至关重要。传统的文本信息抽取方法面临着医疗文本专业性强、表述多样化和结构复杂等挑战。近年来,大模型凭借其强大的语义理解和生成能力,为医疗文本信息抽取带来了革命性的突破。
医疗文本信息抽取的传统局限与新兴需求
医疗文本具有高度专业性、表述规范性不一和上下文依赖性强等特点。传统的基于规则和词典的方法需要大量人工构建模式,泛化能力有限;而早期的机器学习方法又严重依赖标注数据,在医疗领域获取大规模高质量标注数据成本极高。
当前医疗文本信息抽取的核心需求包括:
- 病历文书中的关键信息提取:如主诉、现病史、既往史、诊断结论等
- 化验单的结构化解析:将检验项目、结果、单位和参考范围一一对应
- 检查报告的要点归纳:从影像学、病理学等报告中提取关键发现和诊断意见
- 多文档信息关联与整合:将分散在不同文档中的患者信息进行统一整合
从传统方法到大模型:技术路径的演进
1.传统方法主要依赖于:
- 基于规则/词典: 准确率高但召回率低,维护成本高,难以泛化。
- 基于传统机器学习(如CRF): 需要大量特征工程,对复杂语言模式处理能力有限。
- 基于小型预训练模型(如BioBERT): 在特定生物医学领域有提升,但参数量和通用知识仍有限,对零样本或少样本任务适应性弱。
2.大模型方法的核心优势:
- 海量先验知识: 在超大规模通用语料上预训练,内置了丰富的医学知识和语言模式,具备强大的语义理解与推理能力。
- 强大的上下文学习(ICL)与指令遵循(Instruction Following)能力: 仅需提供少量示例或清晰的指令,即可完成新字段的抽取,极大降低了对标注数据的依赖。
- 统一的序列到序列框架: 可将不同的抽取任务(如命名实体识别、关系抽取、事件抽取)统一为文本生成任务,简化了技术栈。
- 强大的泛化与适应性: 对不同的文档格式、表述变化和噪声具有更好的鲁棒性。
大模型:为医疗文本理解注入“智慧内核”
- 指令微调与任务对齐:构建高质量的医疗文本信息抽取指令数据集,通过监督微调(SFT)让模型精准掌握如“从这份出院小结中提取主要诊断和手术名称”、“找出化验单中所有超出参考范围的指标及其数值”等复杂任务要求。
- 结构化输出约束:设计特定输出模板与约束机制,确保模型不仅能找到信息,还能以规整的JSON、XML等格式输出,便于下游系统集成。
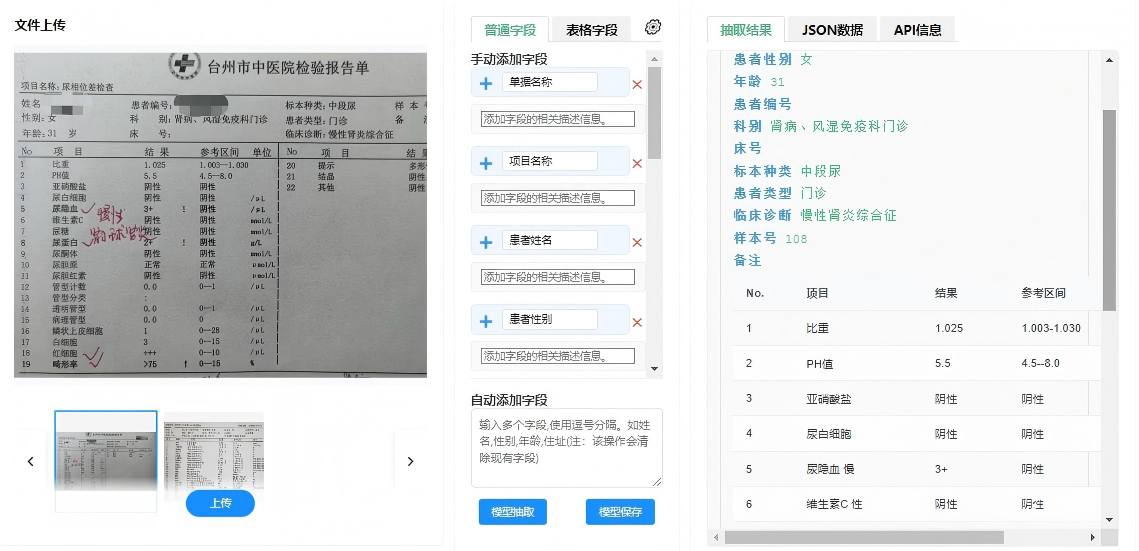
- 多模态信息融合:针对包含表格、图表、手写体的检查报告等,结合OCR(光学字符识别)技术,实现文本与版面信息的协同理解,提升如放射报告描述中关键病灶信息的提取精度。
方案实践:精准抽取,赋能场景
在实际应用中,用户或系统只需输入目标文档和所需的关键字段定义,该技术便能自动完成抽取:
- 住院病历:快速抽取患者基本信息、主诉、现病史、既往史、入院诊断、出院诊断、手术操作、用药清单等。例如,自动从长篇叙述中定位并结构化“既往史”中的高血压病史时长与用药情况。
- 化验报告:精准提取检验项目名称、结果数值、单位、参考范围及异常标志。面对同一项目多次检验结果,能按时间线排序,辅助趋势分析。
- 影像检查报告:抽取检查部位、技术名称、影像学所见(描述)及印象(结论)中的关键信息,如“肺结节的大小、位置、密度特征”。
- 跨文档关联:基于患者ID或时间序列,自动关联不同文档中的相关信息,形成患者纵向健康事件图谱。
基于大模型的医疗文本信息抽取技术正在深刻改变医疗数据的处理方式。通过充分发挥大模型在语义理解、少样本学习和多任务处理方面的优势,结合医疗领域知识和专业提示工程技术,可以高效、准确地从病历、化验单和检查报告等医疗文档中提取关键信息。这一技术不仅能够显著提升临床工作效率,降低人工成本,还能为临床决策支持、医学研究和医疗质量管理提供高质量的结构化数据基础。
未来,随着模型技术的持续进步、计算资源的优化以及医疗数据生态的完善,基于大模型的医疗文本信息抽取技术将在准确性、效率和实用性方面实现更大突破,最终推动医疗行业向更加智能化、精准化和个性化的方向发展。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号