【C++】14.容器适配器 | stack | queue | 仿函数 | priority_queue

【C++】14.容器适配器 | stack | queue | 仿函数 | priority_queue

Ronin305
发布于 2025-12-22 12:54:42
发布于 2025-12-22 12:54:42
1. 容器适配器
什么是适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设 计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
在C++中,容器适配器(Container Adapters) 是一种特殊的类模板,它们基于现有的标准容器(如 deque、vector、list)实现,通过限制或调整底层容器的接口,提供特定的数据结构和操作方式。容器适配器并不直接管理数据存储,而是通过组合现有容器来实现功能,仅暴露符合特定需求的接口。
容器适配器的核心特点
- 封装底层容器
容器适配器内部使用已有的容器(如
deque或vector)来存储数据,但隐藏了底层容器的复杂性,仅提供特定操作。 - 简化接口
仅暴露与特定数据结构相关的操作。例如,
std::stack只允许在栈顶插入或删除元素,而不需要直接访问中间元素。 - 灵活性
允许用户选择底层容器的类型(需满足特定操作要求)。例如,
std::stack默认使用deque,但也可以替换为vector或list。
常见的容器适配器
C++标准库中提供了三种主要的容器适配器:
容器适配器 | 功能描述 | 默认底层容器 | 核心操作 |
|---|---|---|---|
std::stack | 后进先出(LIFO)的栈 | deque | push(), pop(), top() |
std::queue | 先进先出(FIFO)的队列 | deque | push(), pop(), front(), back() |
std::priority_queue | 优先级队列(最大堆/最小堆) | vector | push(), pop(), top() |
底层容器的选择
容器适配器依赖底层容器实现存储,但不同适配器对底层容器的要求不同:
-
std::stack- 需要底层容器支持
push_back()、pop_back()和back()。 - 可用容器:
deque(默认)、vector、list。
- 需要底层容器支持
-
std::queue- 需要底层容器支持
push_back()(插入队尾)和pop_front()(删除队首)。 - 可用容器:
deque(默认)、list。 - 不可用
vector:因为vector的pop_front()是 O(n) 操作。
- 需要底层容器支持
-
std::priority_queue- 需要底层容器支持随机访问迭代器(用于堆操作)。
- 可用容器:
vector(默认)、deque。 - 不可用
list:因为list不支持随机访问。
容器适配器 vs 普通容器
特性 | 容器适配器 | 普通容器(如 vector) |
|---|---|---|
接口复杂度 | 简单,仅暴露特定操作 | 复杂,提供丰富的操作(如随机访问) |
灵活性 | 依赖底层容器的实现 | 直接管理数据存储 |
使用场景 | 特定数据结构(如栈、队列) | 通用数据存储和操作 |
2.STL标准库中stack和queue的底层结构
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为 容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认 使用deque,比如:
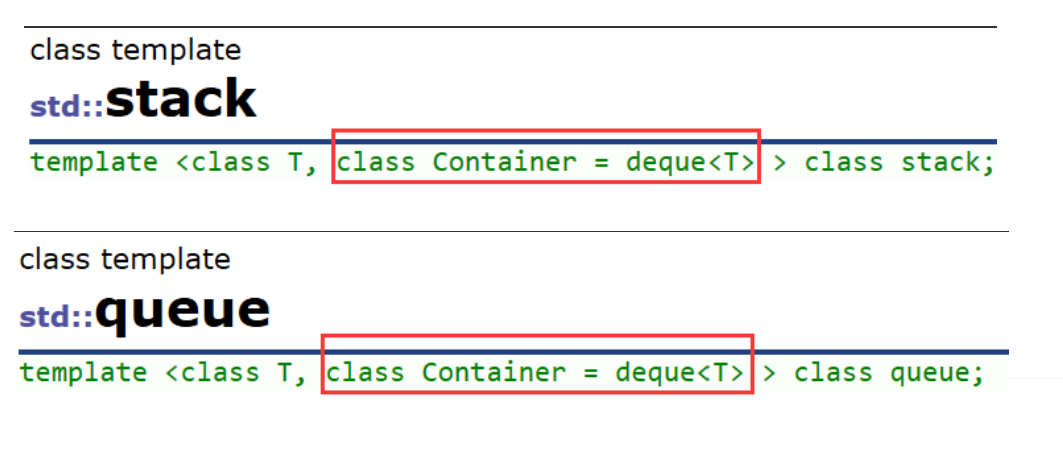
至于deque是什么,这个我们下文会讲
2.1 stack(后进先出,LIFO)
功能
- 后进先出的数据结构,支持在顶部插入和删除元素。
成员函数
-
push(val): 在栈顶插入元素。 -
pop(): 移除栈顶元素(不返回)。 -
top(): 返回栈顶元素的引用。 -
empty(): 检查栈是否为空。 -
size(): 返回元素数量。
在c语言数据结构中,我们有讲到过栈和队列,并且用c语言来模拟实现了一次,这里就不再过多介绍栈和队列了
对于stack的使用也是比较简单的具体可查看文档 stack的文档介绍
这里我们直接来模拟实现,记得我们在c语言实现栈的结构是这样定义的

这样定义的话,增删查改这些操作都需要自己去实现,C++中有没有什么更好的方法呢?就是我们上面提到的容器适配器,直接复用适配的容器来进行我自己的操作,这样不就简单多了
namespace Ro
{
template <class T, class Container = vector<T>>
class stack
{
private:
Container _con;
};
}哪些容器可以支持stack呢,其实只需要底层容器支持 push_back()、pop_back() 和 back(),就能够作为stack的底层容器,就比如vector,list,deque,我们可以在文档中看到,默认是使用deque作为默认容器的,但是目前我们还不了解deque,所以先用vector作为底层容器来模拟实现
namespace Ro
{
template <class T, class Container = vector<T>>
class stack
{
public:
void push(const T& val)
{
_con.push_back(val);
}
T& top()
{
return _con.back();
}
const T& top() const
{
return _con.back();
}
void pop()
{
_con.pop_back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}让别人来替我打工,简直是美滋滋
我们再来测试一下:
void test_stack()
{
stack<int> st;
st.push(1);
st.push(2);
st.push(3);
st.push(4);
while (!st.empty())
{
cout << st.top() << ' ';
st.pop();
}
cout << endl;
}
2.2 queue(先进先出,FIFO)
功能
- 先进先出的数据结构,支持在队尾插入元素,队首删除元素。
成员函数
-
push(val): 在队尾插入元素。 -
pop(): 移除队首元素(不返回)。 -
front(): 返回队首元素的引用。 -
back(): 返回队尾元素的引用。 -
empty(): 检查队列是否为空。 -
size(): 返回元素数量。
和stack一样,也是容器适配器,但是queue底层容器不支持vector,原因如下:
- 容器需支持
front()、back()、push_back()、pop_front()。 - 不可用
vector:因为pop_front()的时间复杂度为 O(n)。
namespace Ro
{
template<class T, class Container = list<T>>
class queue
{
public:
void push(const T& val)
{
_con.push_back(val);
}
void pop()
{
_con.pop_front();
}
T& front()
{
return _con.front();
}
T& back()
{
return _con.back();
}
const T& front() const
{
return _con.front();
}
const T& back() const
{
return _con.back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}这就是容器适配器,我们只需要给他一个适配的底层容器,就可以做到一样的操作,至于我是怎么做的,那是底层容器的事情,使用错误时,底层容器也会报错,例如我们这里使用vector作为底层容器,编译器是会给我们报错的

我们再来测试一下:
void test_queue()
{
queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
while (!q.empty())
{
cout << q.front() << ' ';
q.pop();
}
}
2.3 deque
那在这之前我们就要先来看看vector和list的优缺点,对比一下

deque呢其实就是vector和list的缝合,为什么这么说呢?我们接下来就来介绍一下
C++中的deque(双端队列)是一种序列容器,允许在容器的前端和后端高效地插入和删除元素,同时支持快速的随机访问。以下是关于deque的详细介绍:
定义与特点
- 双端队列:deque是“double-ended queue”的缩写,它允许在序列的两端(前端和后端)进行快速的插入和删除操作。
- 随机访问:支持通过下标(
operator[])或迭代器快速访问任意位置的元素,时间复杂度为O(1)。 - 动态大小:
deque的大小可以动态增长或缩小,以适应元素的插入和删除。 - 非连续内存:与
vector不同,deque的内存不是连续分配的,而是由多个固定大小的内存块(通常称为“缓冲区”或“块”)组成,这些块通过一个中央控制器(如指针数组)管理。
底层实现
- 分段连续存储:
deque采用分段连续存储策略,每个内存块的大小固定,通常为512字节或4096字节(具体取决于编译器和平台)。 - 中央控制器:维护一个指向每个内存块起始地址的数组或链表,以及每个块的大小信息。
- 动态扩展:当需要插入新元素且当前块已满时,
deque会分配一个新的内存块,并更新中央控制器以包含新块的地址。
总结一下其实就是:
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
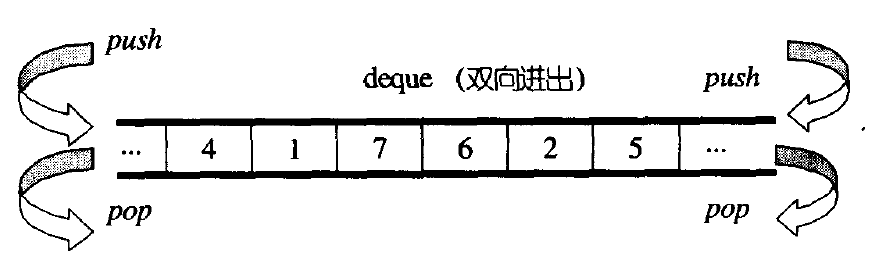
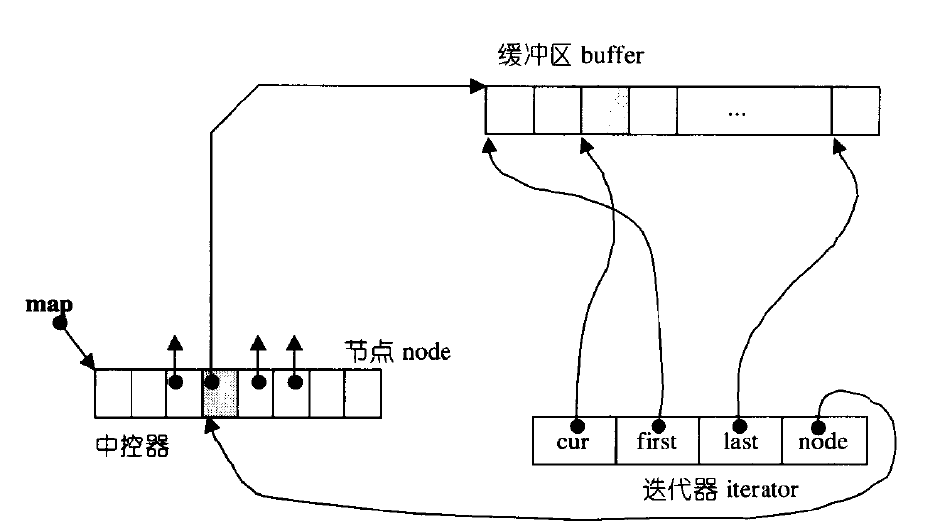
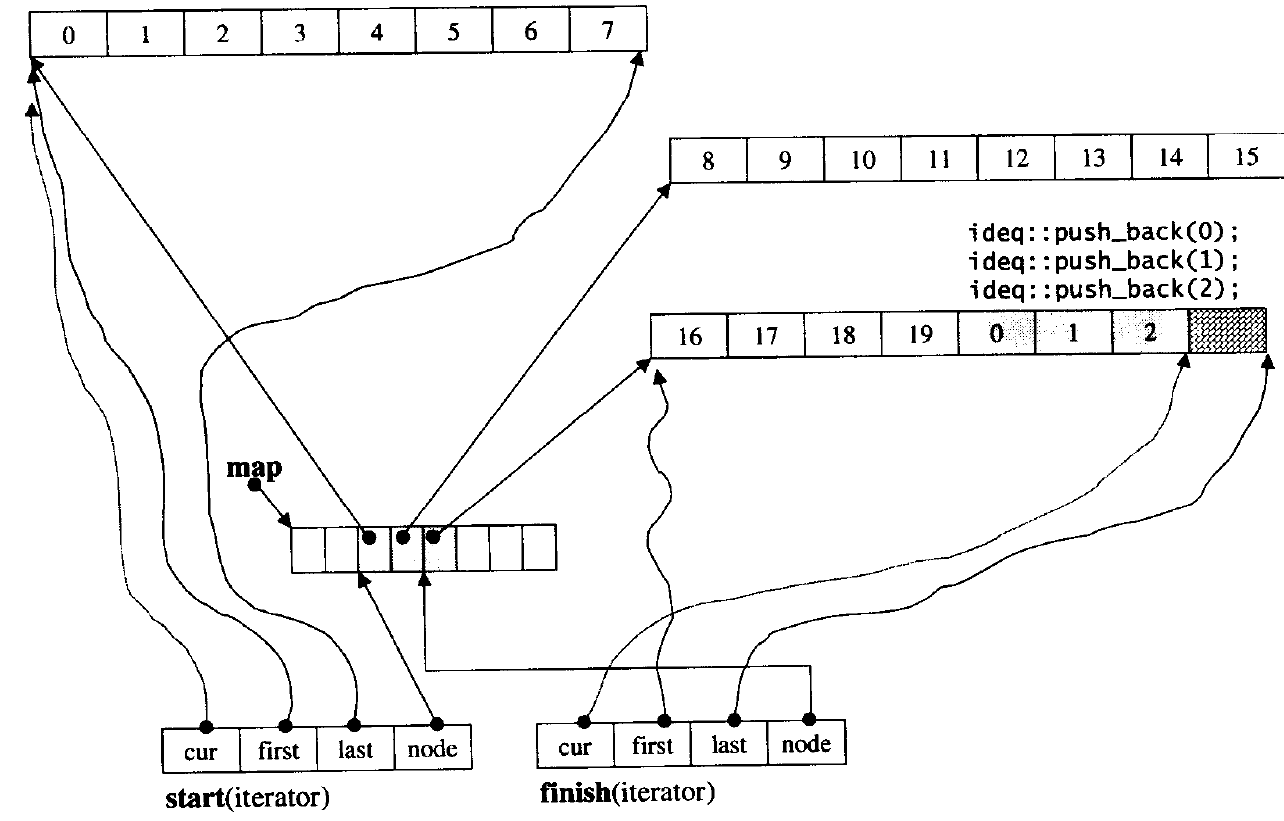
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
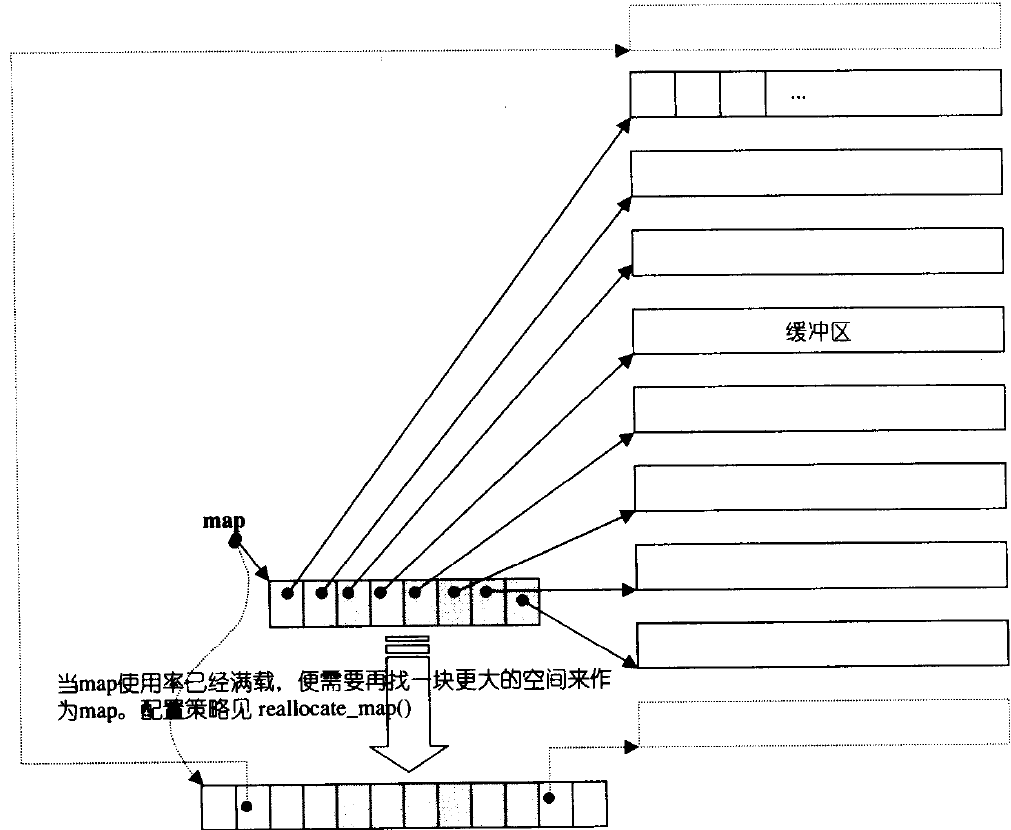
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
那deque是如何借助其迭代器维护其假想连续的结构呢?
// 简化的迭代器结构(仅展示核心成员)
template<typename T>
struct _Deque_iterator
{
T* _M_cur; // 指向当前元素
T* _M_first; // 指向当前内存块的起始位置
T* _M_last; // 指向当前内存块的结束位置(实际是末尾的下一个位置)
_Map_pointer _M_node; // 指向中央控制器的某个条目(管理内存块的指针数组)
};_M_cur
含义:指向当前迭代器所在位置的元素。
作用:直接访问当前元素的值(通过*it或it->操作)。
示例:
deque<int>::iterator it = dq.begin();
int val = *it; // 通过_M_cur获取值_M_first
- 含义:指向当前内存块(缓冲区)的起始位置。
- 作用:
- 判断迭代器是否在当前块的起始位置(如
it == _M_first)。 - 当迭代器需要向前移动(如
--it)时,若当前处于块的起始位置,则需要跳转到前一个内存块。
- 判断迭代器是否在当前块的起始位置(如
_M_last
- 含义:指向当前内存块(缓冲区)的结束位置(实际是末尾的下一个位置)。
- 作用:
- 判断迭代器是否在当前块的末尾(如
it == _M_last - 1)。 - 当迭代器需要向后移动(如
++it)时,若当前处于块的末尾,则需要跳转到下一个内存块。
- 判断迭代器是否在当前块的末尾(如
_M_node
- 含义:指向中央控制器(
_Map_pointer类型,通常是一个二级指针)。 - 作用:
- 中央控制器是一个指针数组,每个条目指向一个内存块。
- 通过
_M_node可以访问到当前内存块在中央控制器中的位置。 - 当迭代器需要在内存块之间跳转时,通过
_M_node找到相邻内存块的地址。
迭代器的关键操作
1. 自增操作(++it)
-
_M_cur向后移动(_M_cur++)。 - 若
_M_cur == _M_last,说明已到当前块的末尾:- 通过
_M_node找到下一个内存块的地址。 - 更新
_M_first、_M_last和_M_cur,使其指向下一个块的起始位置。
- 通过
2. 自减操作(--it)
-
_M_cur向前移动(_M_cur--)。 - 若
_M_cur < _M_first,说明已到当前块的起始位置:- 通过
_M_node找到前一个内存块的地址。 - 更新
_M_first、_M_last和_M_cur,使其指向前一个块的末尾。
- 通过
3. 随机访问(it + n)
- 计算目标位置相对于当前块的位置偏移。
- 若目标位置跨越多个内存块,则调整
_M_node到目标块,并更新_M_first、_M_last和_M_cur。
deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。 与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。 但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。结合了deque的优点,而完美的避开了其缺陷。
3.仿函数
1. 什么是仿函数?
仿函数(Functor) 是一个行为类似函数的对象,它通过重载 operator() 运算符实现函数调用功能。仿函数本质上是类或结构体对象,可以像普通函数一样被调用,但具有对象的状态保存能力。
2. 仿函数与普通函数的区别
特性 | 普通函数 | 仿函数 |
|---|---|---|
状态保存 | 无法保存状态(无成员变量) | 可以保存状态(通过成员变量) |
灵活性 | 固定逻辑 | 可通过构造函数参数动态配置逻辑 |
模板参数传递 | 无法直接作为模板参数传递 | 可以作为模板参数传递(类型) |
内联优化 | 可能无法内联 | 更易被编译器内联优化 |
3. 如何定义仿函数?
只需在类或结构体中重载 operator() 运算符即可。
示例:实现加法仿函数
class Add
{
public:
// 构造函数可接受参数(例如固定加数)
Add(int value) : _value(value) {}
// 重载 operator()
int operator()(int x) const {
return x + _value;
}
private:
int _value; // 保存状态
};
// 使用仿函数
Add add5(5);
int result = add5(10); // 输出 15
还可以这样写:
class Add
{
public:
// 重载 operator()
int operator()(int x, int y) const
{
return x + y;
}
};
// 使用仿函数
Add add5;
int result = add5(10, 5); // 输出 15还可以作为模板参数来使用,举个例子就可以看出来了
struct Greater
{
bool operator()(int a, int b) const
{
return a > b; // 降序
}
};
struct Less
{
bool operator()(int a, int b) const
{
return a < b; // 升序
}
};
vector<int> vec = { 3, 1, 4, 1, 5 };
sort(vec.begin(), vec.end(), Greater());
//sort(vec.begin(), vec.end(), Less());
for (int e : vec)
{
cout << e << ' ';
}
cout << endl;这里我们想让它降序就传Greater对象,想升序就传Less对象,这样就可以更方便,底层实现的时候就不用写一个升序版本的排序,又写一个降序版本的排序,省去了麻烦,也让代码没那么冗余
我们来运行一下看看
降序:

升序:

4.仿函数的优势
状态保存 可通过成员变量记录中间状态(例如计数器、缓存数据)。
class Counter
{
public:
Counter() : _count(0) {}
void operator()(int x)
{
_count += x;
}
int get() const { return _count; }
private:
int _count;
};
std::vector<int> data = {1, 2, 3};
Counter cnt;
cnt = std::for_each(data.begin(), data.end(), cnt);
std::cout << cnt.get(); // 输出 6模板兼容性
仿函数是类型,可直接作为模板参数传递(例如 std::set 的比较器)。
template<typename T, typename Compare>
class PriorityQueue
{
// 使用 Compare 仿函数类型定义比较逻辑
};性能优化 仿函数比函数指针更易被编译器内联优化。
再次强调需要注意仿函数不是函数
仿函数本质:通过重载 operator() 实现函数行为的对象。
4. priority_queue(优先级队列)
简单来说优先级队列其实就是我们之前数据结构章节讲的堆。
优先级队列(priority_queue) 是一种容器适配器,其元素按优先级顺序出队。与普通队列(先进先出)不同,优先级队列每次取出的是优先级最高的元素。在C++标准模板库(STL)中,priority_queue 默认基于最大堆实现,堆顶元素为最大值。

我们直接来模拟实现一下
namespace Ro
{
template<class T>
struct Greater
{
bool operator()(const T& a, const T& b) const
{
return a > b; // 降序
}
};
template<class T>
struct Less
{
bool operator()(const T& a, const T& b) const
{
return a < b; // 升序
}
};
template<class T, class Container = vector<T>, class Compare = Less<T>>
class priority_queue
{
public:
private:
Container _con;
};
}仿函数在这里就起到作用了,不然我们模拟实现还要分别实现大堆和小堆两种,这里我们和官方文档一样,也再增加一个类模板,我们想要大堆就传Less对象的仿函数,想要小堆就传Greater对象的仿函数。这里你可能觉得Less是比较升序的,Greater是比较降序的,那么大堆不应该传Greater,小堆不应该传Less吗
在C++的priority_queue中,最大堆使用std::less作为比较函数,而最小堆使用std::greater,这一设计看似与直觉相悖,但实际与堆的优先级判定逻辑和内部维护机制密切相关。以下是详细解释:
核心原因:比较函数定义的是父节点的优先级关系
priority_queue的底层实现通过堆结构维护元素顺序。比较函数的作用是判断父节点是否应保留其位置,而非直接决定元素的绝对顺序。具体规则如下:
1. 最大堆(大顶堆)与 std::less<T>
- 目标:堆顶元素始终为最大值。
- 比较逻辑:
当插入新元素时,堆的调整需要保证父节点 ≥ 子节点。
使用
std::less<T>时,若父节点<子节点(比较返回true),则触发交换,将较大的子节点上浮,最终形成最大堆。 // 伪代码:堆调整逻辑 if (compare(parent, child)) { // 若父节点 < 子节点(std::less返回true) swap(parent, child); // 交换父子节点,保证父节点更大 }
2. 最小堆(小顶堆)与 std::greater<T>
- 目标:堆顶元素始终为最小值。
- 比较逻辑:
使用
std::greater<T>时,若父节点>子节点(比较返回true),则触发交换,将较小的子节点上浮,最终形成最小堆。 if (compare(parent, child)) { // 若父节点 > 子节点(std::greater返回true) swap(parent, child); // 交换父子节点,保证父节点更小 }
类比排序:比较函数方向的反转
在排序中,std::less用于升序(从小到大),而std::greater用于降序(从大到小)。但在堆中,比较函数的逻辑被反转,因为它直接决定父节点与子节点的相对关系:
场景 | 比较函数 | 排序结果 | 堆类型 | 堆调整目标 |
|---|---|---|---|---|
升序排序 | std::less<T> | 元素从小到大排列 | 最大堆 | 父节点 ≥ 子节点(堆顶最大) |
降序排序 | std::greater<T> | 元素从大到小排列 | 最小堆 | 父节点 ≤ 子节点(堆顶最小) |
- 关键区别: 排序中的比较函数直接决定相邻元素的顺序,而堆中的比较函数决定父子节点的优先级关系。
push:
// 向上调整
void AdjustUp(size_t child)
{
size_t parent = (child - 1) / 2;
Compare com;
while (child > 0)
{
//if(_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& val)
{
_con.push_back();
AdjustUp(_con.size() - 1);
}我们尾插一个数据就需要向上调整,来满足父子的关系
top:
const T& top() const
{
return _con.front();
}empty:
bool empty() const
{
return _con.empty();
}size:
size_t size() const
{
return _con.size();
}pop:
// 向下调整
void AdjustDown(size_t parent)
{
size_t child = parent * 2 + 1;//大堆时默认左孩子比右孩子大,小堆时默认左孩子小
Compare com;
while (child < _con.size())
{
//if (child < _con.size() && _con[child] < _con[child + 1])
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
{
child++;
}
//if(_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
assert(!empty());
swap(_con.front(), _con.back());
_con.pop_back();
AdjustDown(0);
}需要注意的是,优先级队列为空时不能pop,所以我们加个断言
至于实现细节和逻辑我们在之前的数据结构堆中有讲过,这里就不再多介绍。
我们再来测试一下:
Ro::priority_queue<int> pq;
pq.push(1);
pq.push(2);
pq.push(3);
pq.push(4);
pq.push(5);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
stack.h:
namespace Ro
{
template <class T, class Container = vector<T>>
class stack
{
public:
void push(const T& val)
{
_con.push_back(val);
}
T& top()
{
return _con.back();
}
const T& top() const
{
return _con.back();
}
void pop()
{
_con.pop_back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
void test_stack()
{
stack<int> st;
st.push(1);
st.push(2);
st.push(3);
st.push(4);
while (!st.empty())
{
cout << st.top() << ' ';
st.pop();
}
cout << endl;
}
}queue.h:
namespace Ro
{
template<class T, class Container = list<T>>
class queue
{
public:
void push(const T& val)
{
_con.push_back(val);
}
void pop()
{
_con.pop_front();
}
T& front()
{
return _con.front();
}
T& back()
{
return _con.back();
}
const T& front() const
{
return _con.front();
}
const T& back() const
{
return _con.back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
void test_queue()
{
queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
while (!q.empty())
{
cout << q.front() << ' ';
q.pop();
}
}
}priority_queue.h:
namespace Ro
{
template<class T>
struct Greater
{
bool operator()(const T& a, const T& b) const
{
return a > b; // 降序
}
};
template<class T>
struct Less
{
bool operator()(const T& a, const T& b) const
{
return a < b; // 升序
}
};
template<class T, class Container = vector<T>, class Compare = Less<T>>
class priority_queue
{
public:
// 向上调整
void AdjustUp(size_t child)
{
size_t parent = (child - 1) / 2;
Compare com;
while (child > 0)
{
//if(_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 向下调整
void AdjustDown(size_t parent)
{
size_t child = parent * 2 + 1;//大堆时默认左孩子比右孩子大,小堆时默认左孩子小
Compare com;
while (child < _con.size())
{
//if (child < _con.size() && _con[child] < _con[child + 1])
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
{
child++;
}
//if(_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void push(const T& val)
{
_con.push_back(val);
AdjustUp(_con.size() - 1);
}
void pop()
{
assert(!empty());
swap(_con.front(), _con.back());
_con.pop_back();
AdjustDown(0);
}
const T& top() const
{
return _con.front();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号