StarRocks 性能实测:在 Coffee-shop Benchmark 中快 10 倍!
原创
StarRocks 性能实测:在 Coffee-shop Benchmark 中快 10 倍!
原创
StarRocks
发布于 2025-11-21 00:17:35
发布于 2025-11-21 00:17:35

在评估数据库性能时,如何同时衡量“算得快”和“算得省”一直是工程师关注的核心问题。
Coffee-shop Benchmark [1] 是由社区研究者提出的公开测试,用于评估不同数据库系统在计算密集型 Join 与 Aggregation 工作负载下的性能与成本表现。由于其查询设计兼具业务代表性与计算复杂度,能够较全面地反映分析型数据库在真实工作负载下的表现,因此被用于对比 Databricks、Snowflake、ClickHouse 等主流系统 [2–6]。
测试内容模拟了典型的零售与门店经营分析场景,涵盖销售趋势、利润分析、折扣策略等多种典型查询类型,能够较全面地反分析型数据库的执行性能与资源效率。
出于研究兴趣与工程验证,我们在相同的测试逻辑与实例规格下,复现了 Coffee-shop Benchmark 的 17 个查询 [1,4],并在 StarRocks 上完成了 500M、1B、5B 三种规模的数据集验证。
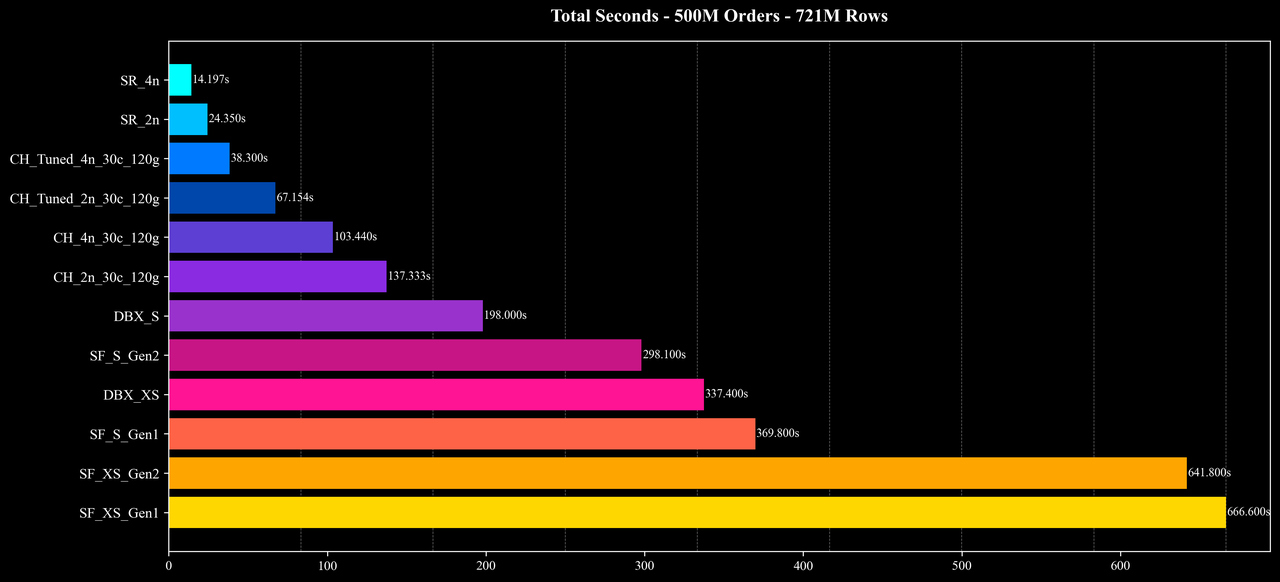
结果显示,在这些涉及大量 Join 与高基数聚合的复杂查询中,StarRocks 以更低的成本和更短的运行时间完成了全部测试,整体性能与成本效率较参考系统提升约 2–10 倍。
这一结果不仅验证了 StarRocks 在算子优化、向量化执行和资源调度方面的工程实力,也意味着在广告归因、用户画像、实时看板等典型场景中,企业可以用更少的资源获得更快的分析体验。
对关注实时分析性能与成本优化的开发者和架构师而言,这一测试结果为系统选型与性能评估提供了一个客观、可复现的参考,也进一步印证了 StarRocks 在 Lakehouse 架构下的高性价比优势。
数据集特征
Coffee-shop benchmark 的数据集包含一个事实表 (fact_sales )与两个维度表( dim_locations、dim_products)组成:
- 维度表:行数固定,不随数据规模变化。
dim_locations:1000 行
dim_products:26 行
- 事实表:fact_sales 的行数随规模不同而变化。 500M scale:0.72B rows 1B scale:1.44B rows 5B scale:7.2B rows
在查询类型上,Coffee-shop Benchmark 涵盖了两类典型的 Join 场景:
- 等值 Join:
fact_sales与dim_locations在location_id列上进行等值关联。该列为 VARCHAR 类型,能够有效验证系统在大规模分布式 Join 下的并行执行与数据分片效率。 - 范围 Join(Range Join):
fact_sales与dim_products通过name列关联,同时包含时间范围条件f.order_date BETWEEN p.from_date AND p.to_date。这种模式在实际业务中常见(如带有效期的商品维度表),能够检验系统对复杂 Join 条件的优化与执行效率。
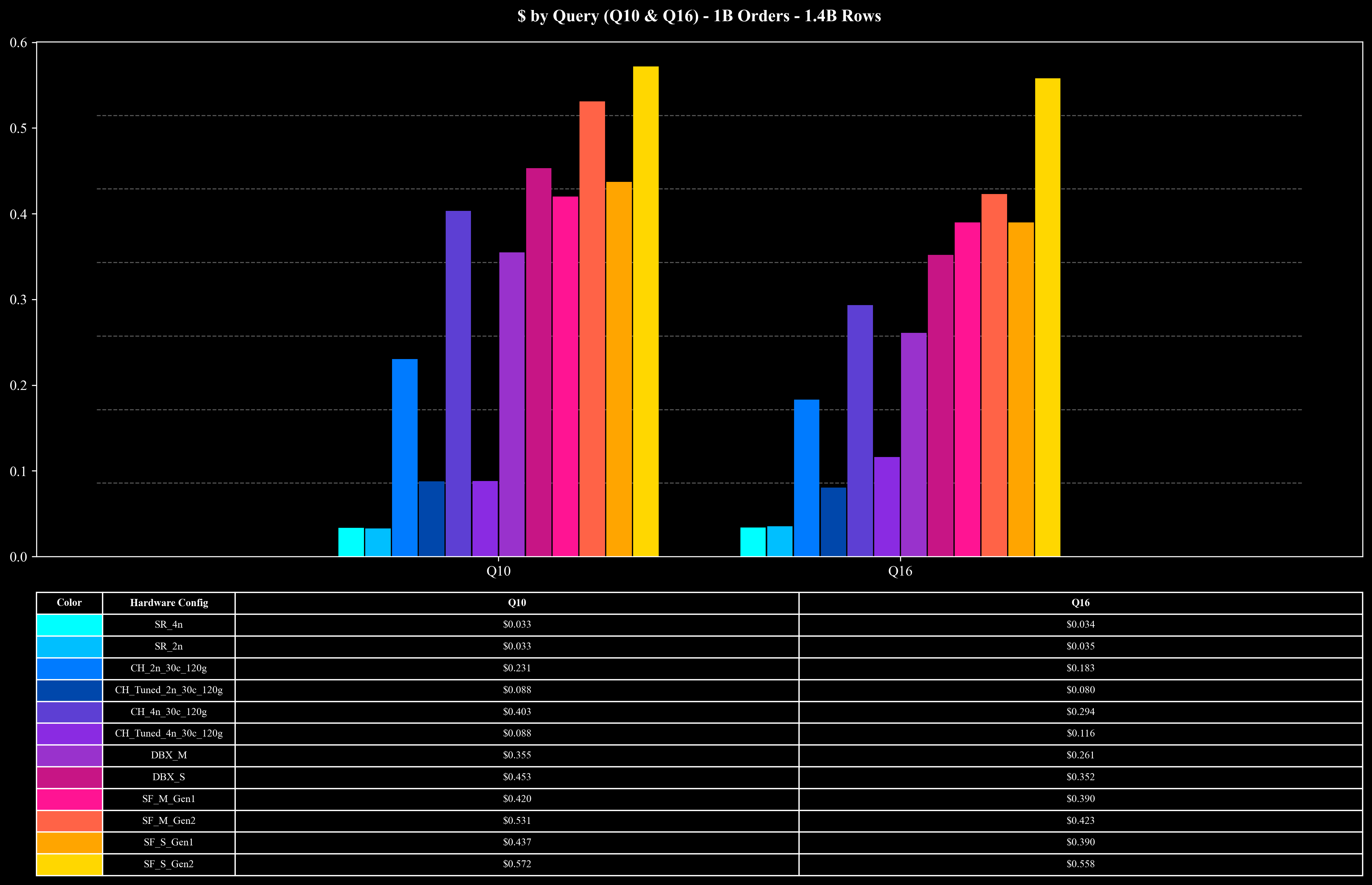
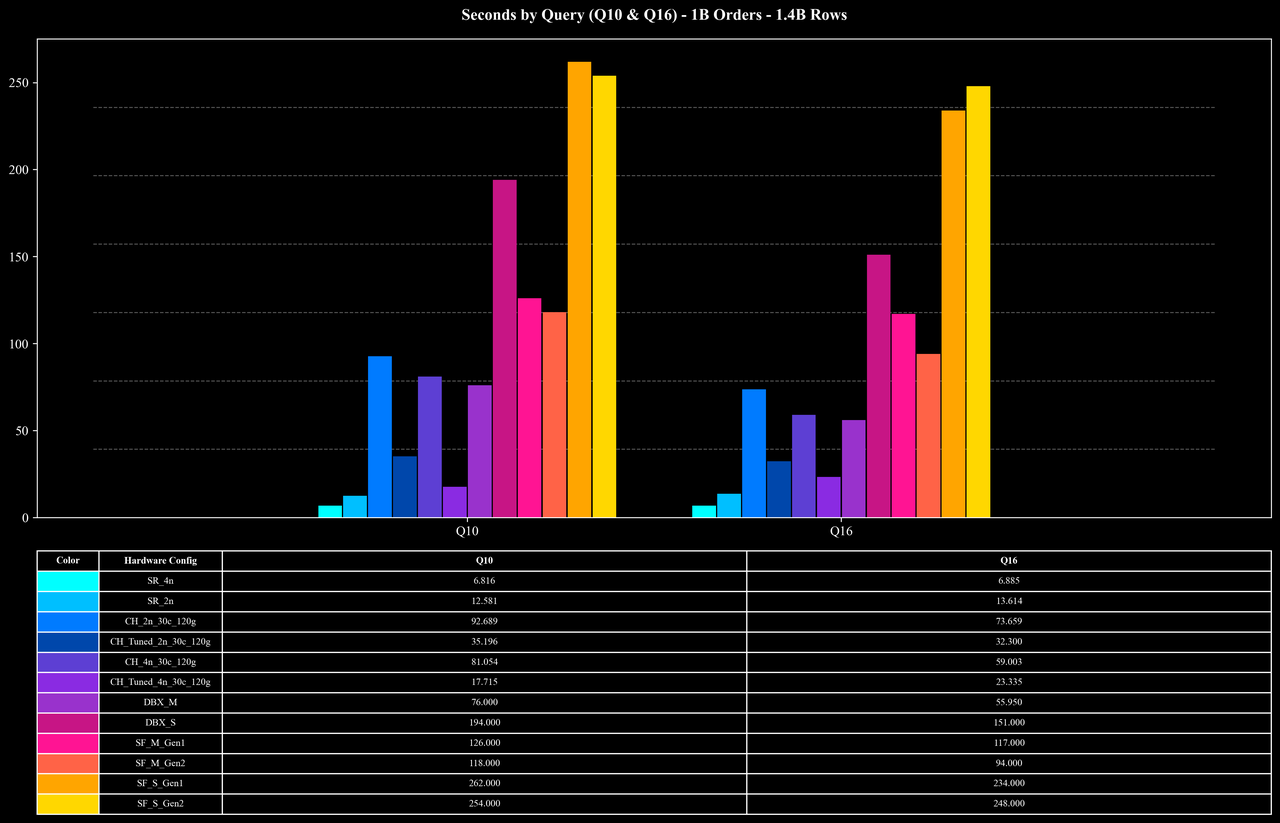
除 Join 外,17 个查询还覆盖了多种 Aggregation 模式。其中包括 COUNT DISTINCT 在内的多种聚合函数,并在不同列组合下进行 GROUP BY。其中最具挑战性的为 Q10 与 Q16,它们执行 COUNT(DISTINCT order_id) 并以多个列进行 GROUP BY。由于 order_id 的唯一值极多,平均每个 key 仅出现不到两次,这类查询对系统的中间聚合、去重和内存管理提出了极高要求。
在这类大量数据 Join 和高基数聚合场景中,StarRocks 在高效的 Hash Map 实现、多阶段聚合、Join Runtime Filter、低基数字典优化等机制协同作用下,能够在复杂的 Join 与聚合查询中稳定保持较高的性能与资源利用率。
测试环境
为确保测试结果具备可比性,我们采用了与前人研究相近的实例配置和数据分布方式:
- 实例配置 FE 节点:1 * m7g.2xlarge (8 vCPUs, 32GB Memory),负责查询解析、计划生成、调度与结果返回。 BE 节点:m7g.8xlarge (32vCPUs, 128GB Memory),负责查询执行。
500M scale:2 或 4 个实例。
1B scale:2 或 4 个实例。
5B scale:8 或 16 个实例。
- 建表策略:测试使用了 Order Key 与 Hash Bucket Key 的分布策略,具体的建表语句、导入和执行 Query 的脚本详见:Coffee Shop Benchmark on StarRocks。原始测试包含 “Clustered” 与 “Non-clustered” 两种布局,为了保持结果一致性,我们仅展示 Clustered 模式的结果。
- 数据导入:使用了 ClickHouse 公开的 Coffee-shop 数据集 [4]。借助 StarRocks 的存算分离架构,数据只需导入一次,即可在不同节点配置下进行测试。通过简单调整计算节点数量,即可完成 scale-in / scale-out,无需重复导入数据。
- 查询语句:完全复现原始 Coffee-shop Benchmark 的 17 个查询,仅对少量不兼容语法(如
CREATE OR REPLACE TABLE)进行等价替换,不改变语义与逻辑。 - StarRocks 版本:测试基于 StarRocks 4.0.1。除默认配置外,仅对
fact_sales表的(order_date, location_id)列进行了联合统计信息收集,以帮助优化器生成更优计划;其他参数均保持默认。
测试方法
每个查询执行 5 次,取最短一次结果作为 warm-cache 性能。
对比系统(ClickHouse、Snowflake、Databricks)的结果参考了已公开的研究与博客 [2–6],并在相同数据规模(500M、1B、5B)下进行对比,用于评估整体运行时间与成本效率。
测试结果
测试结果:500M Scale (0.72B Rows)
Total Cost
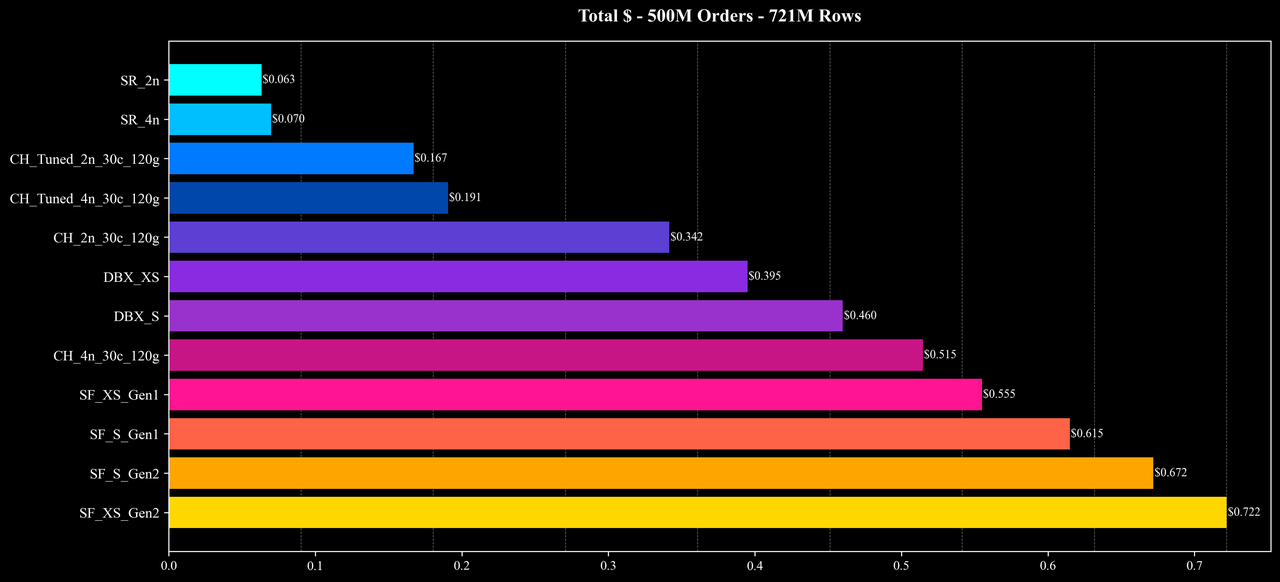
Total Runtime
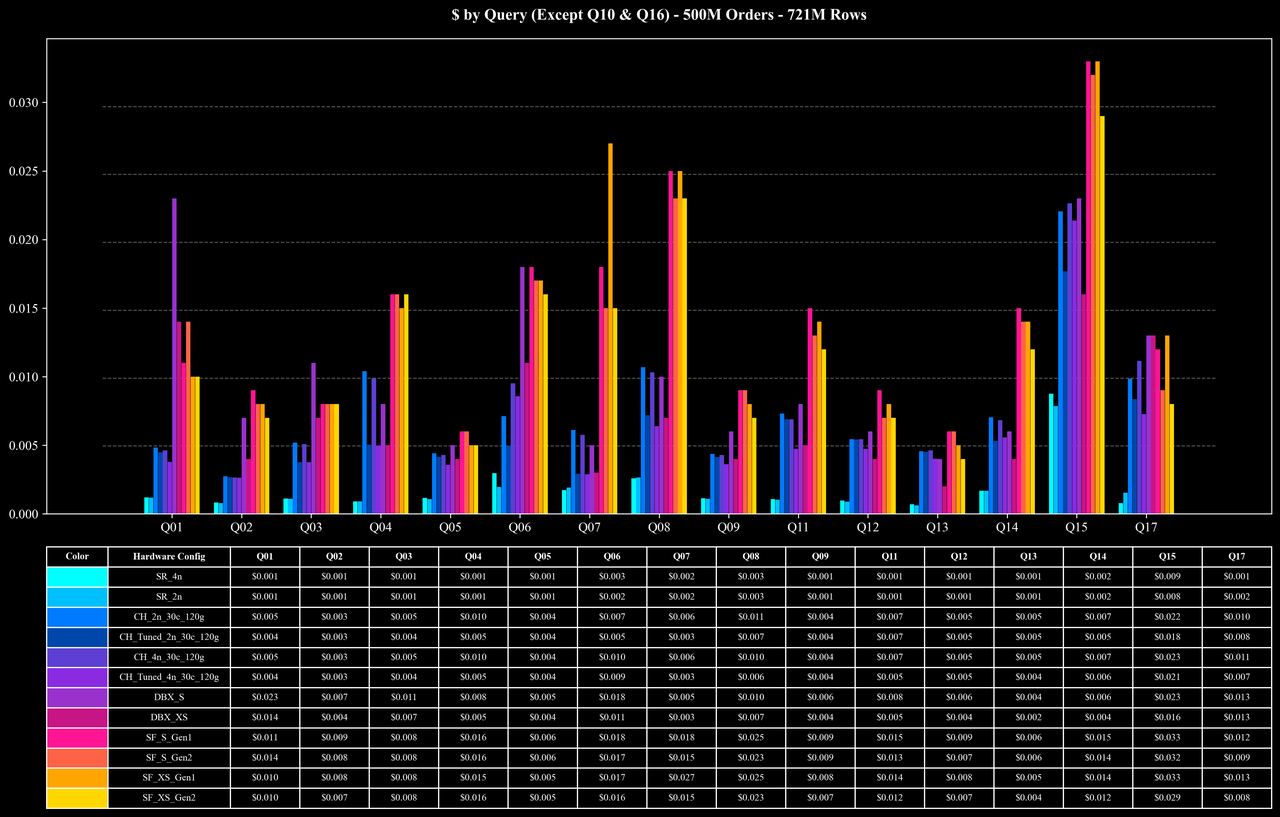
Cost per Query (Except Q10 & Q16)
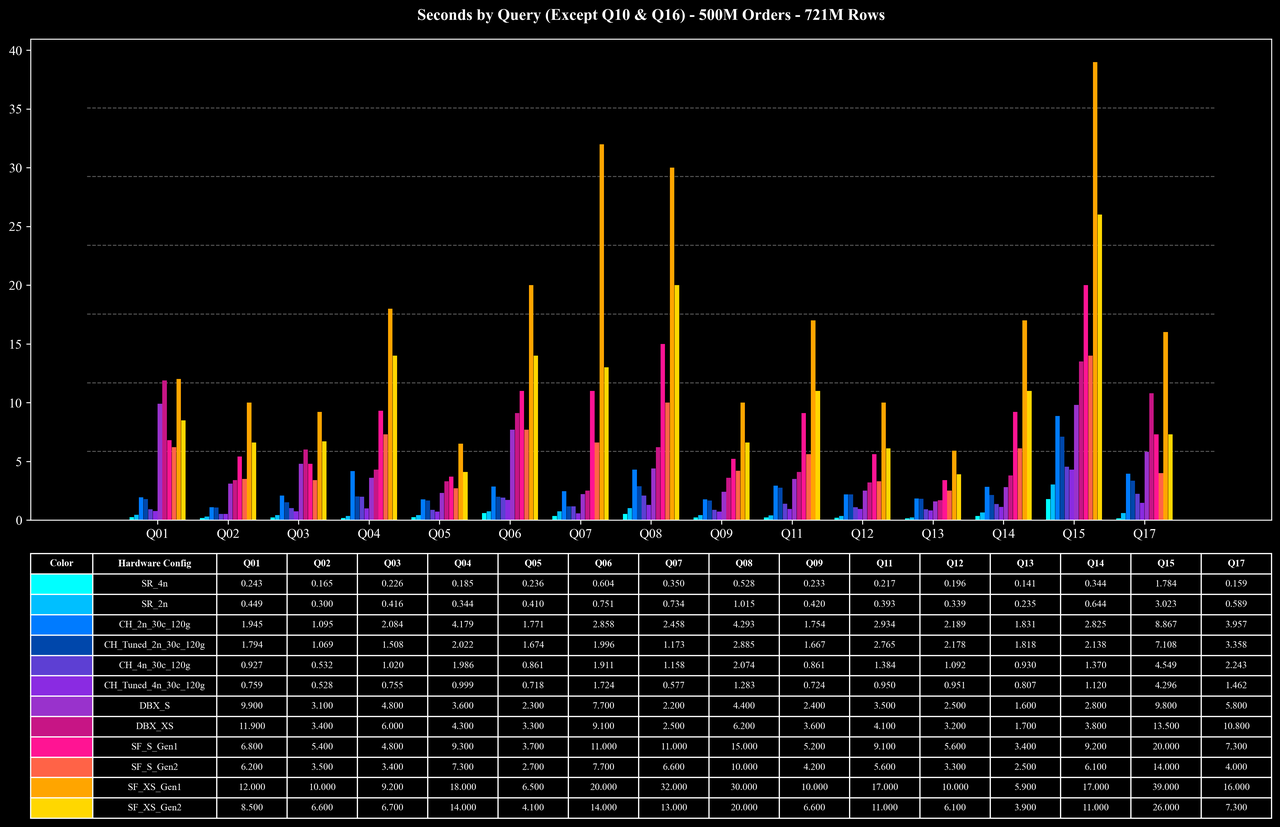
Runtime per Query (Except Q10 & Q16)
Cost per Query (Q10 & Q16 Only)
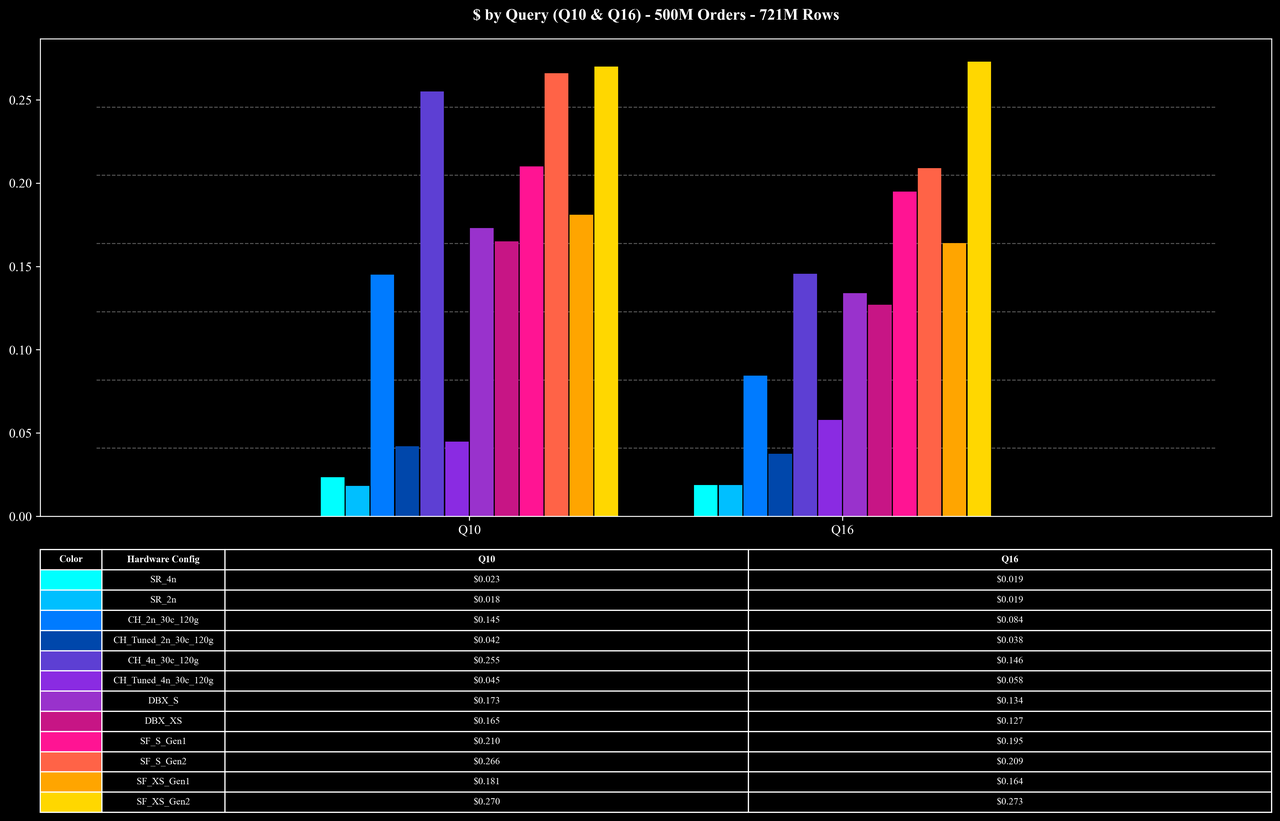
Runtime per Query (Q10 & Q16 Only)
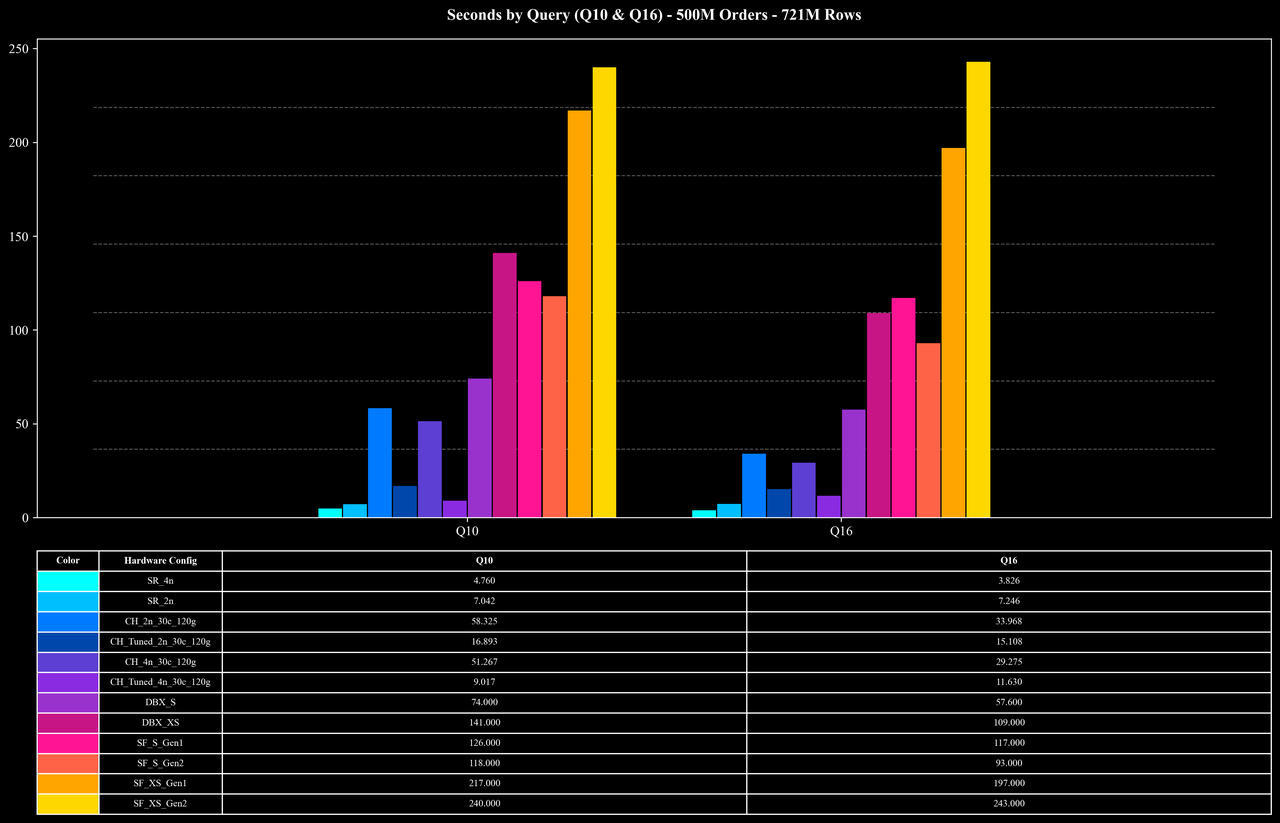
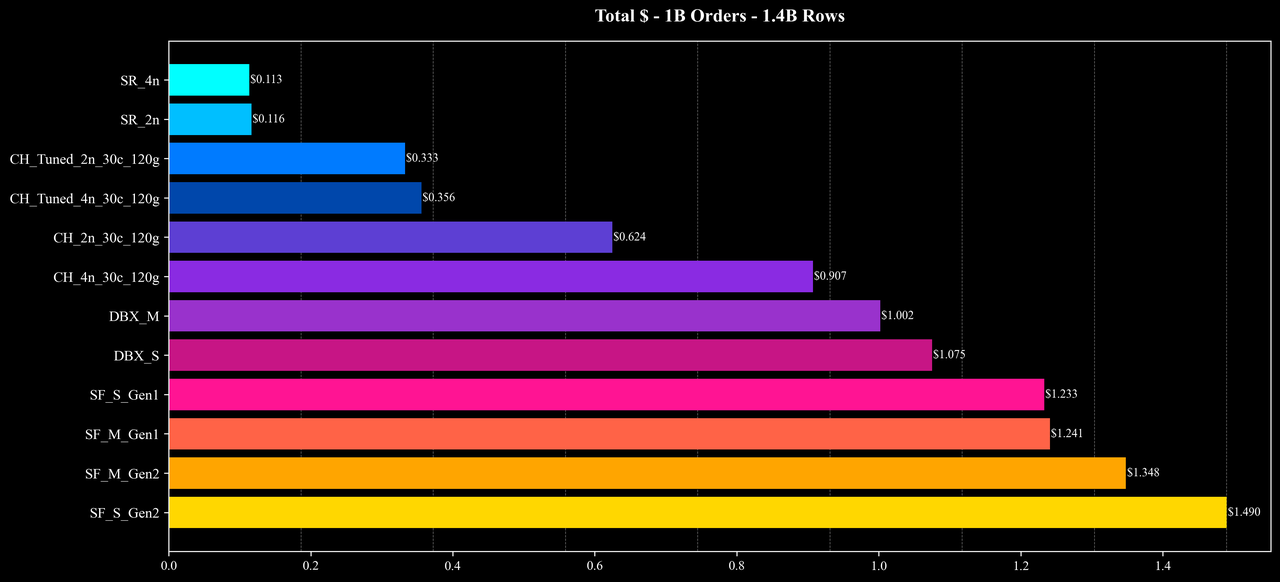
测试结果:1B Scale (1.44B Rows)
Total Cost
Total Runtime
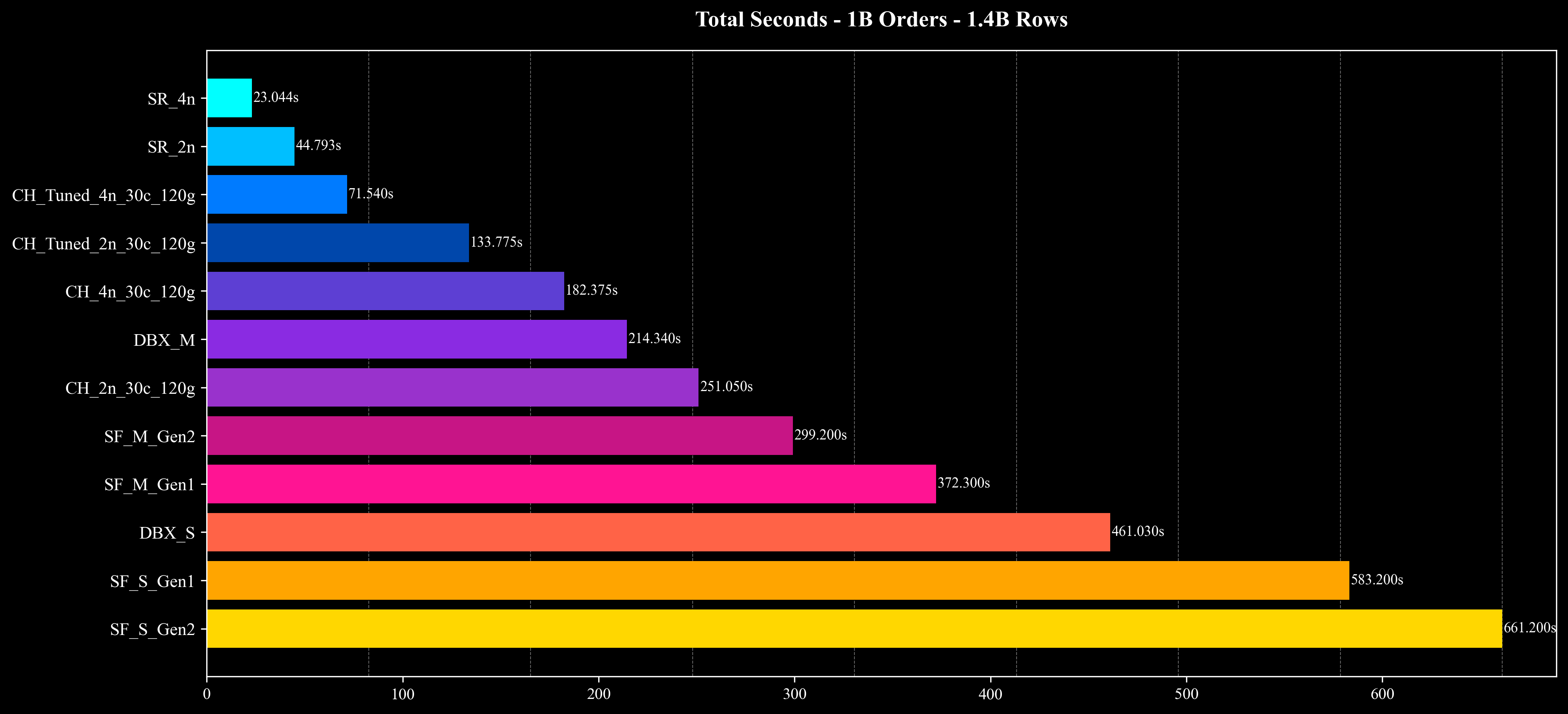
Cost per Query (Except Q10 & Q16)
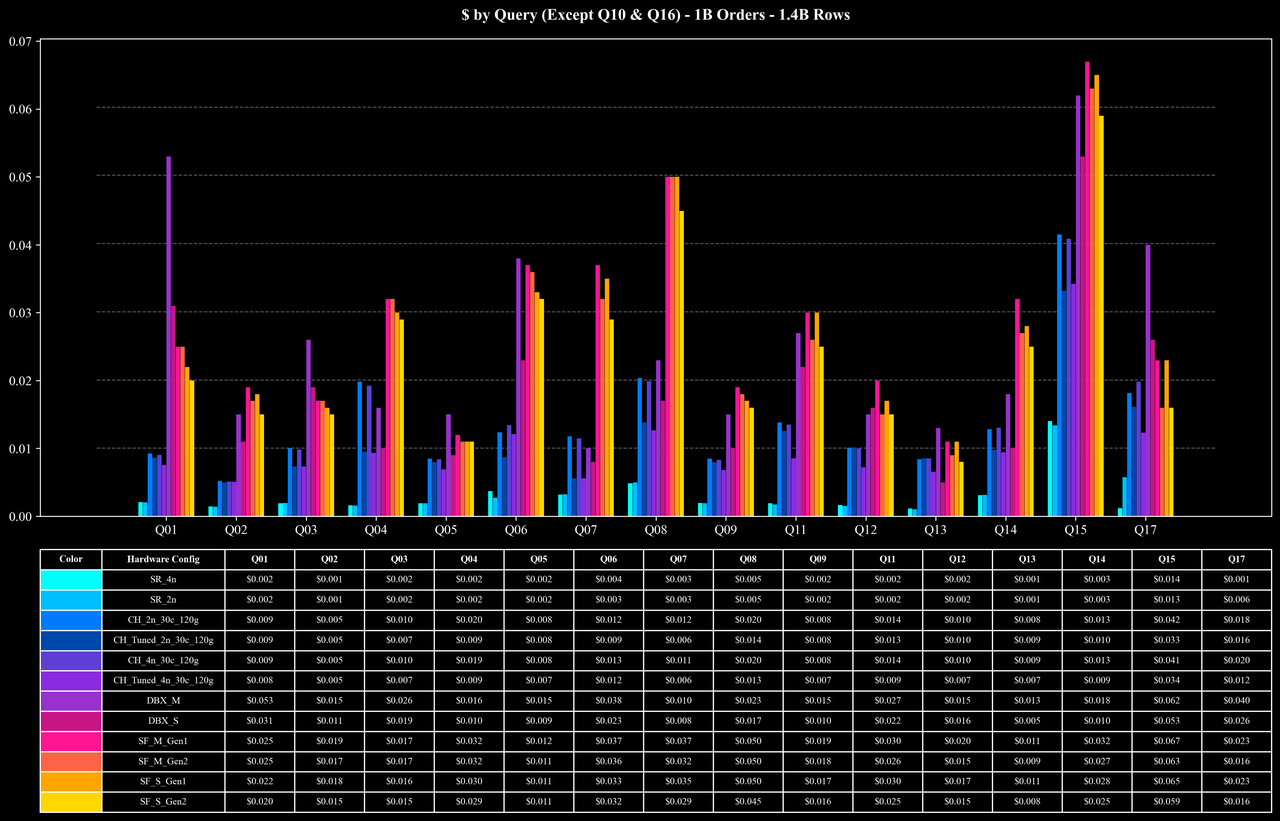
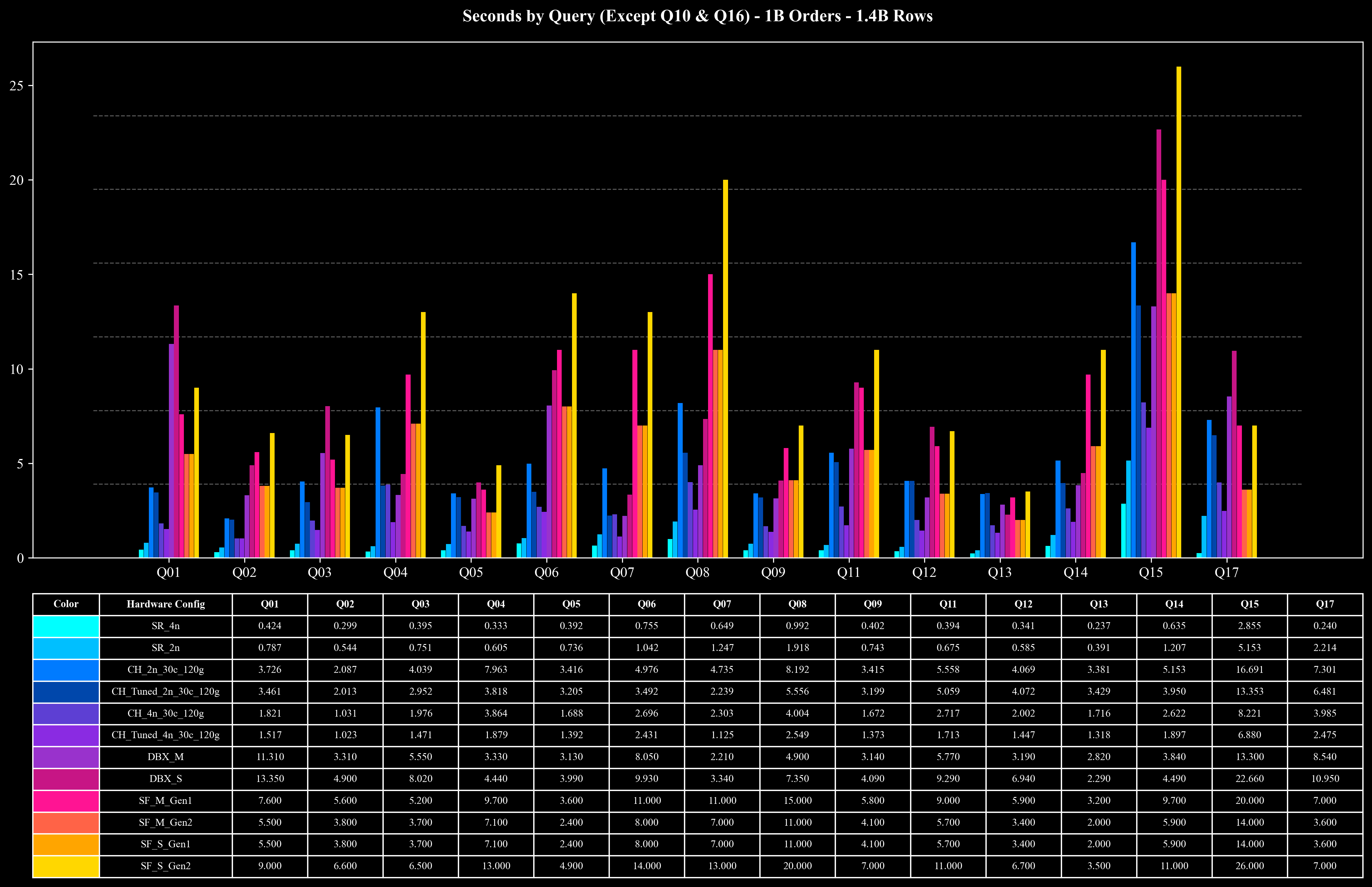
Runtime per Query (Except Q10 & Q16)
Cost per Query (Q10 & Q16 Only)
Runtime per Query (Q10 & Q16 Only)
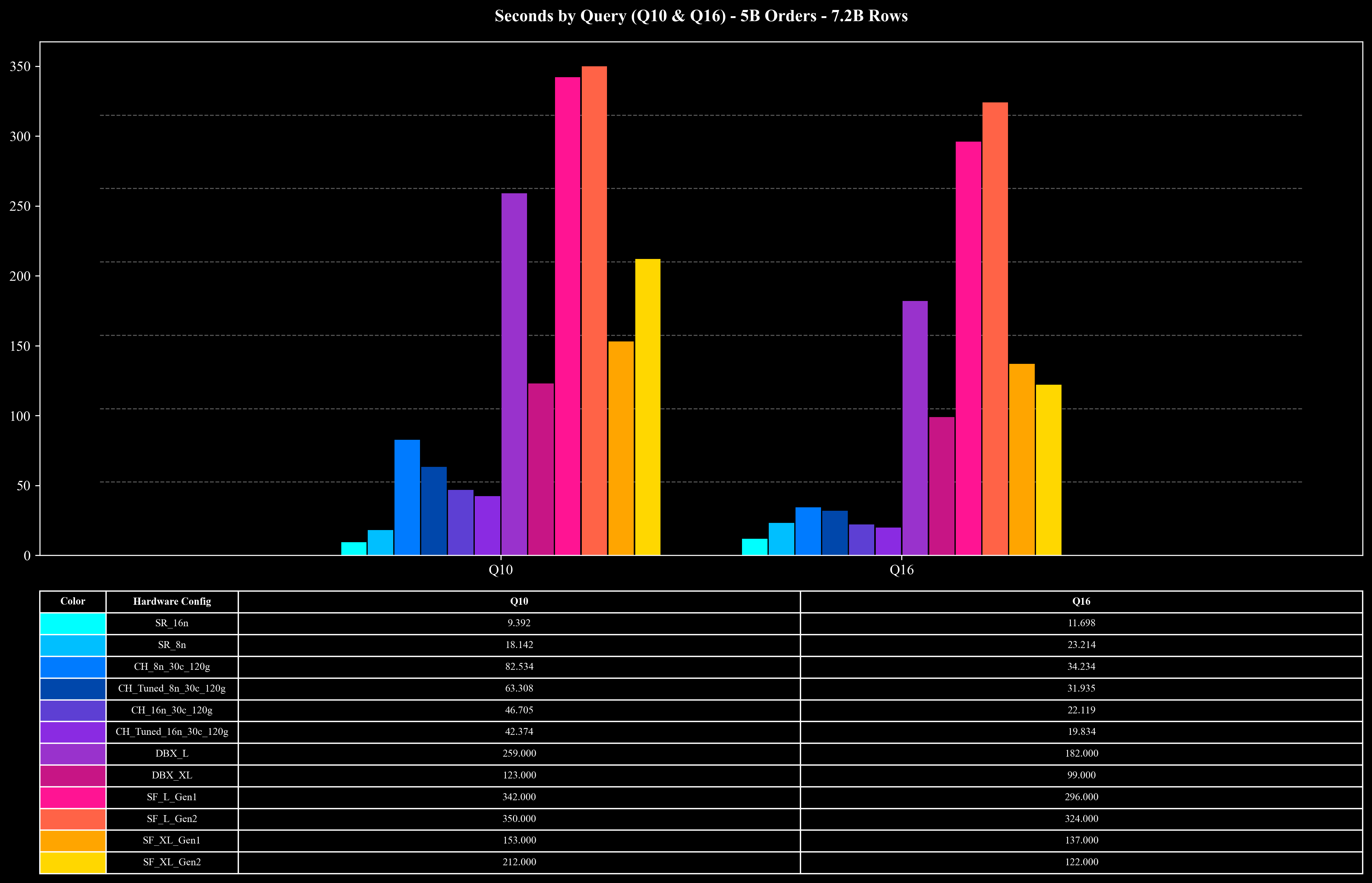
测试结果:5B Scale (7.2B Rows)
Total Cost
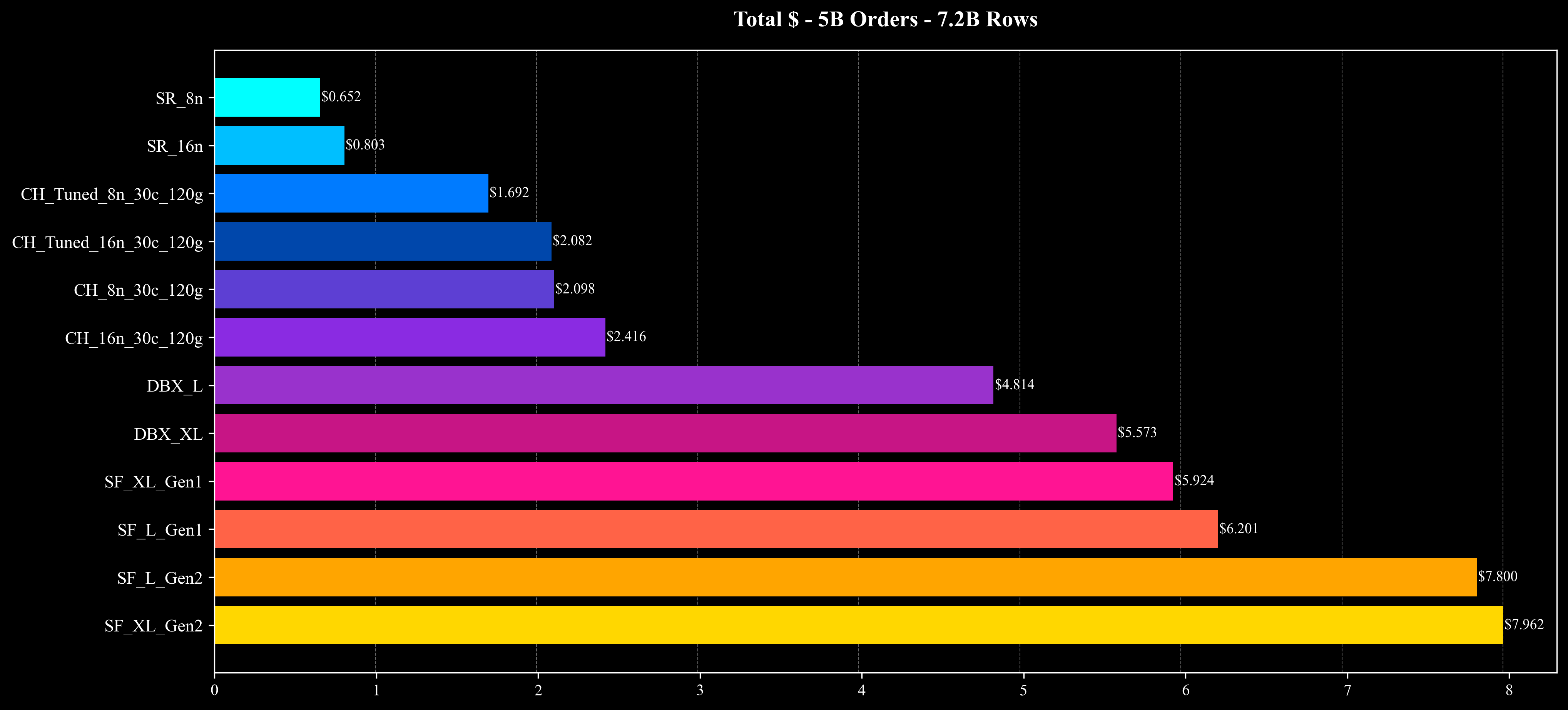
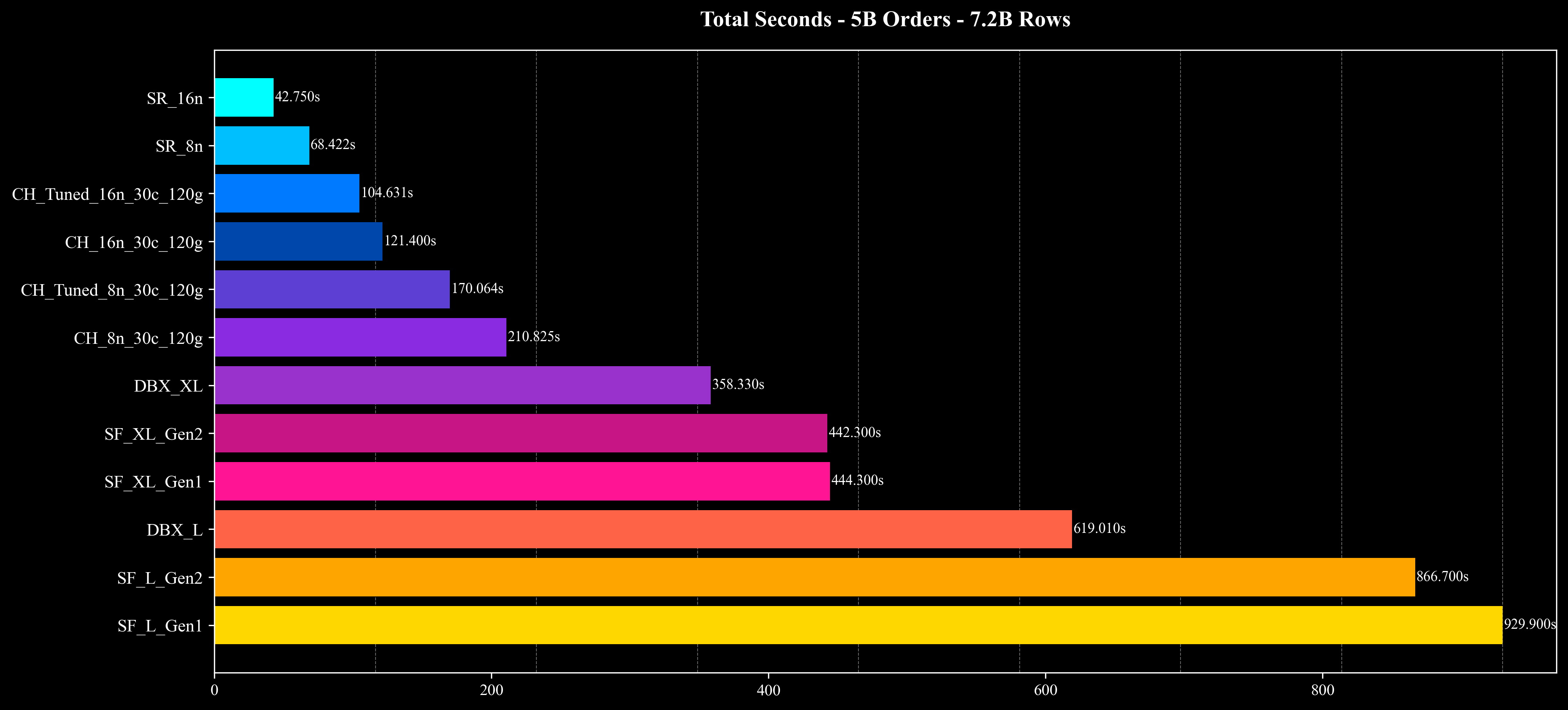
Total Runtime
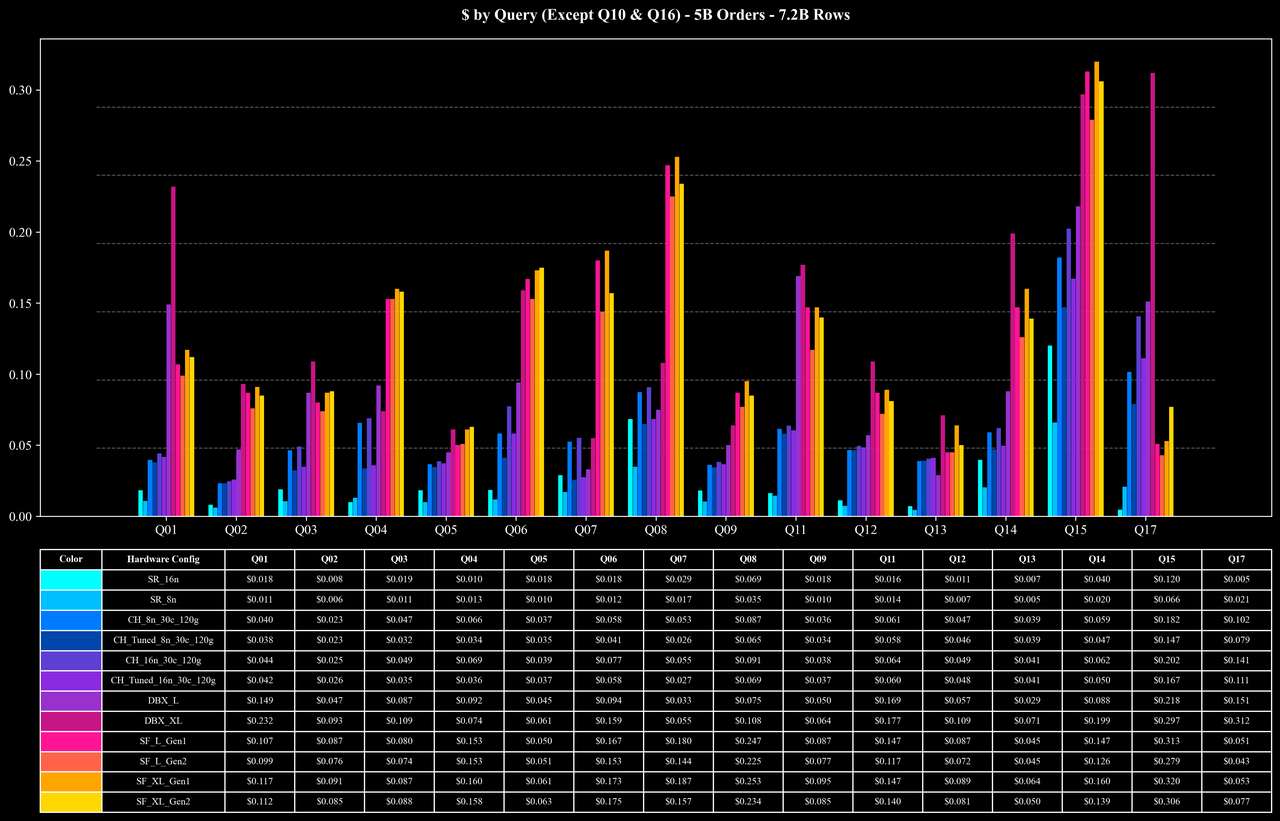
Cost per Query (Except Q10 & Q16)
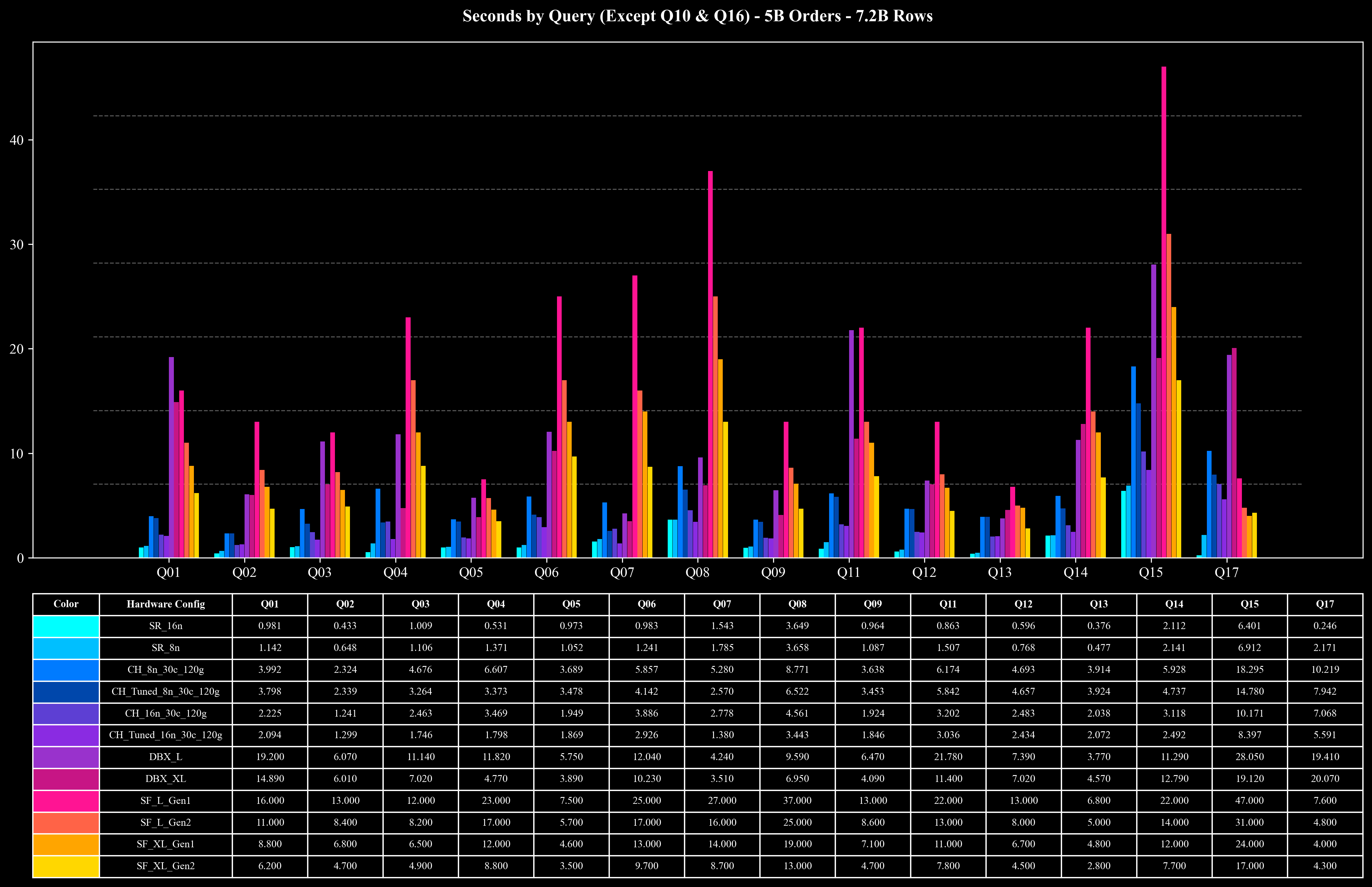
Runtime per Query (Except Q10 & Q16)
Cost per Query (Q10 & Q16 Only)
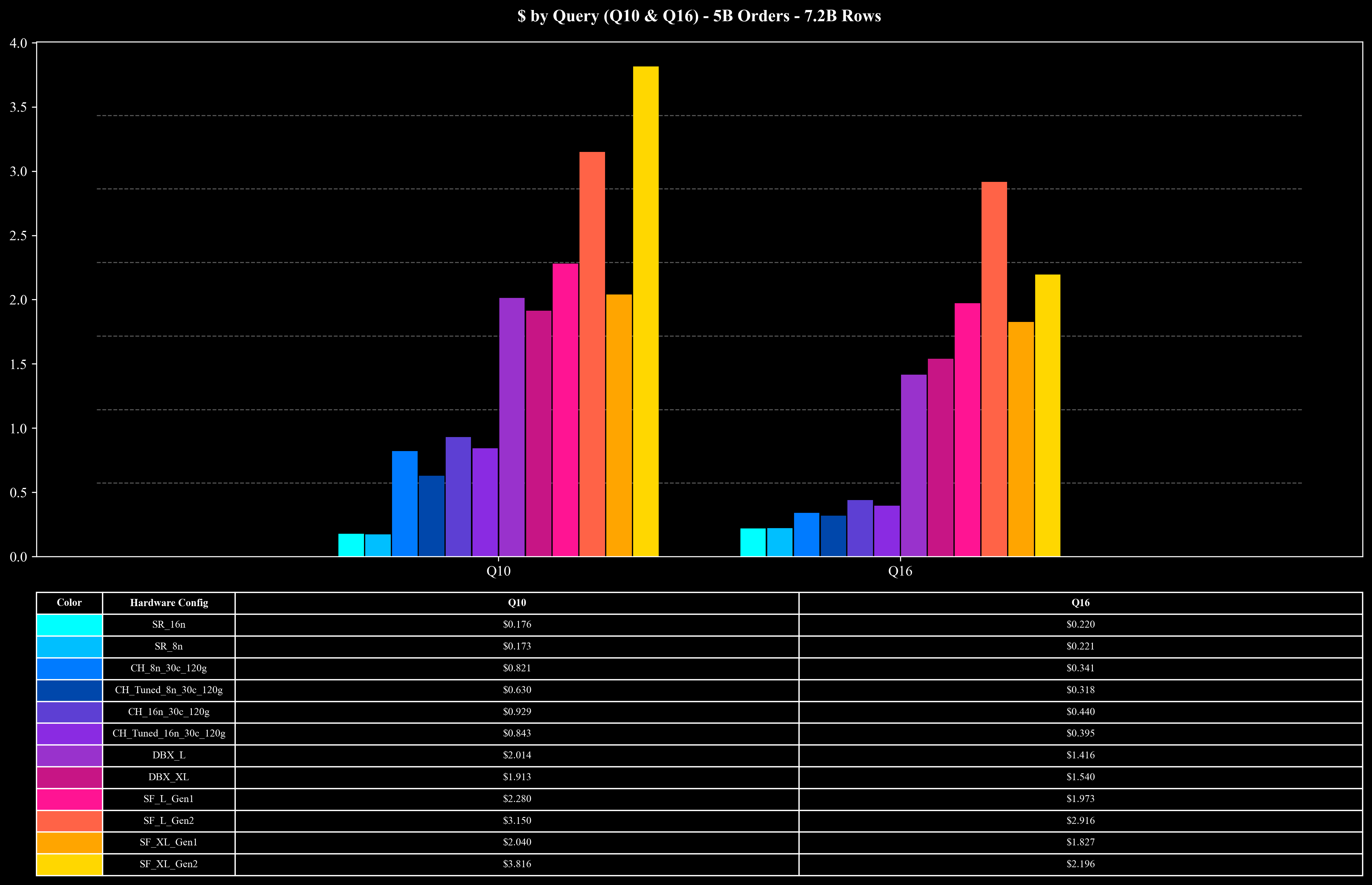
Runtime per Query (Q10 & Q16 Only)
结果分析
Coffee-shop Benchmark 共包含 17 个查询,覆盖 Join、Aggregation、窗口函数、排序等多种复杂操作。其中 Join 和 Aggregation 是大多数查询的主要计算瓶颈。
在 500M、1B、5B 三种数据规模下,StarRocks 均展现出出色的线性扩展性与资源利用效率:
- 大部分查询:在 500M 与 1B 规模下,平均查询耗时仅约 0.5 秒,在 5B 规模下也能在 1 秒左右 完成,性能稳定且具备良好的扩展性。
- 高负载查询(Q10、Q16):面对包含 7.2B 行数据的 Join 与高基数 COUNT DISTINCT 聚合,StarRocks 在 5 的规模下仅需约 10 秒即可完成查询,显著降低了执行开销。
- 整体性能与成本:在相近的硬件配置与相同的数据规模下,StarRocks 展现出较高的查询性能与成本效率优势,在多数场景下实现了明显的资源节省与执行性能提升。
这些结果表明,StarRocks 在复杂分析型负载下能够充分利用多节点计算资源,并在高 Join、高基数聚合场景中依旧保持稳定的性能与成本平衡。
进一步测试与说明
需要说明的是,Coffee-shop Benchmark 的维度表规模相对较小(分别为 26 行与 1000 行),主要用于验证以事实表为主的数据分析场景。
在更复杂的工业标准测试(如 TPC-DS)中,StarRocks 同样在多表 Join 与大规模聚合等高负载场景下表现稳定,继续保持出色的性能与成本效率平衡。
更多详细测试结果可参考 👉StarRocks TPC-DS Benchmark。
引用
- Coffee Shop Benchmark
- Databricks vs Snowflake SQL Performance Test, Day 1: 721M Rows Test
- Databricks vs Snowflake Gen 1 & 2 SQL Performance Test, Day 2: 1.4B & 7.2 Rows Test
- Coffee Shop Benchmark for ClickHouse
- Join me if you can: ClickHouse vs. Databricks & Snowflake - Part 1
- Join me if you can: ClickHouse vs. Databricks & Snowflake - Part 2
- Coffee Shop Benchmark on StarRocks
- StarRocks TPC-DS Benchmark
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号