数据编码 - 分布式架构协议设计考量


点击上方小坤探游架构笔记可以订阅哦
在如何进行架构契约的决策文章中, 我们阐述要在架构上做契约决策的what、why & how, 那么接下来我们就来看具体采用某种契约实现不同组件之间的交互需要注意哪些事情, 这里我们统称为数据编码, 如果你理解为组件交互协议, 那也没问题.
契约决策2W1H的回顾
为什么要在分布式架构层面上进行契约决策呢? 要想回答这个问题, 我们就需要明白为什么要将系统拆分为分布式系统呢? 可以想下, 我们要将系统进行拆分, 必然存在是为了解决我们系统中面临的某一个问题, 如果我们从架构层面上去看待这个问题, 那么它可以是高性能, 也可以是高可用等架构特征, 也就是为了满足某一急需解决的架构特征问题而考虑对系统进行拆分.
但不管是什么目标, 既然我们要进行拆分, 那么就需要考虑到系统组件之间的依赖, 也就是通过前面所说的静态耦合, 即拆分出来之后的系统需要依赖哪些组件才能跑起来; 其次是动态耦合, 也就是说系统运行起来之后, 需要依赖组件之间的协调、通信以及数据的完整性来完成系统对客户交付的目标.
由此将系统拆分为分布式的方式, 那么我们就需要考虑组件之间的耦合关系, 如果过度耦合就会导致系统某个组件发生变更, 会带动其他组件也一起发生变更, 随之而来的测试覆盖面也增加, 从而导致测试的范围也必须随着增加; 如果组件之间不进行耦合彼此独立, 那么也将无法实现系统对客户交付目标.
其实说了这么多无非就是一个目标, 通过架构层面的决策降低组件耦合的同时也需要考虑复杂度带来的变化, 从而控制变化影响的变更频率. 同样地, 在架构层面进行契约决策目标就是控制变更频率, 保持组件之间在合适的耦合范围内. 这就是我们所说的why.
当我们理解了背景之后, 那么什么是what呢? 相信你也能很容易去理解它, 一旦我们的系统拆分为分布式系统, 那么原本是通过函数调用, 现在需要通过彼此建立一个可以交流的“语言”来完成通信, 这是从组件通信层面; 另外一个是数据存储层面, 契约不单单是指组件之间的通信, 它也包含了数据, 比如我们前面说到的静态耦合依赖数据库存储的数据. 那么既然有数据, 总要借助硬件层面来进行存储, 于是就有了缓存或者磁盘的方式.因此这里我统称为数据编码格式来表示契约具体的落地实现方式. 我们可以说采用PB严格的契约格式来进行数据存储和传输, 也可以说采用JSON松散的契约格式来进行存储和传输.因此契约就是来描述各个组件之间通信的方式来表达依赖或者是传递信息.
而我们在架构层面上进行契约决策方法便是识别严格与松散契约在不同架构组件之间的通信的影响. 即如果是在同一个架构量子, 那么我们可以通过严格的契约方式来保证同一个架构量子内不同组件之间的“交流”都是高度保持一致; 而不同架构量子内不同组件我们建议是采用松散的契约方式进行“交流”, 目的是控制变更频率在自己的架构量子内, 不受外部架构量子的影响, 那么在我们具体实现协议的时候需要考虑什么问题呢?
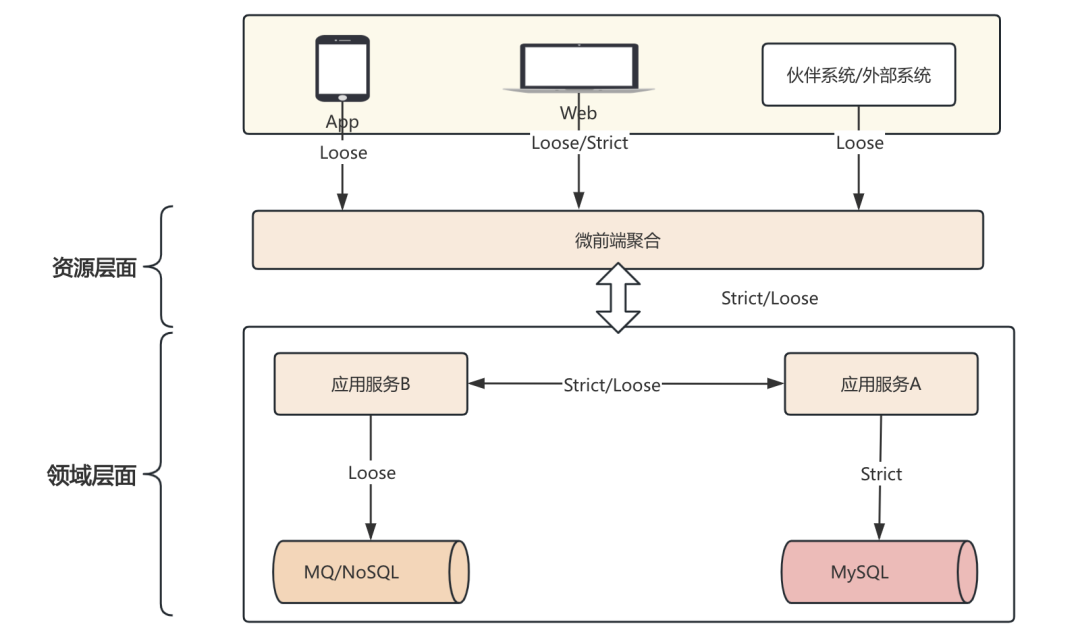
数据模型的读写时模式
之前有一篇文章我曾讲述了数据模型的读写时模式, 为什么要说这个呢? 其实它和我们谈的协议具体实现存在一定的联系, 我们可以简单回顾下数据模型的读写时模式是什么样的.
首先是数据模型的读时模式(Scheme-on-Read), 如果你熟悉mongodb数据库, 那么你一定会知道mongodb是采用BSON格式进行存储, 你也可以理解为JSON格式, 这个时候你发现JSON格式是属于我们上述讨论的松散契约方式, 也就是说我们可以定义一个用户信息的数据结构并采用JSON格式存储如下:
{
"id": 1,
"name": "xiaokun liu" // 包含了firstName
}那么这个时候前端想要多显示一个firstName, 怎么办呢? 这个时候我们不需要去更高数据库, 而是在应用程序中进行如下处理:
if (user && user.name && !user.first_name) {
user.first_name = user.name.split(" ")[0];
}这个时候你会看到松散契约带来的便利性, 它保持存储数据格式的一致性, 对外通过应用程序将变化控制在内部实现逻辑中.
那么什么是写时模式(Scheme-on-write)呢? 同样是上述的例子, 但是它与读时模式不同, 它要求数据写入必须是预定义结构, 比如这里如果我们采用MySQL来进行存储, 这个时候要多增加一个字段给到前端, 我们就需要通过DDL来改变MySQL预定义的数据结构, 如下:
ALTER TABLE users ADD COLUMN first_name varchar(50) DEFAULT NULL COMMENT 'user first name';
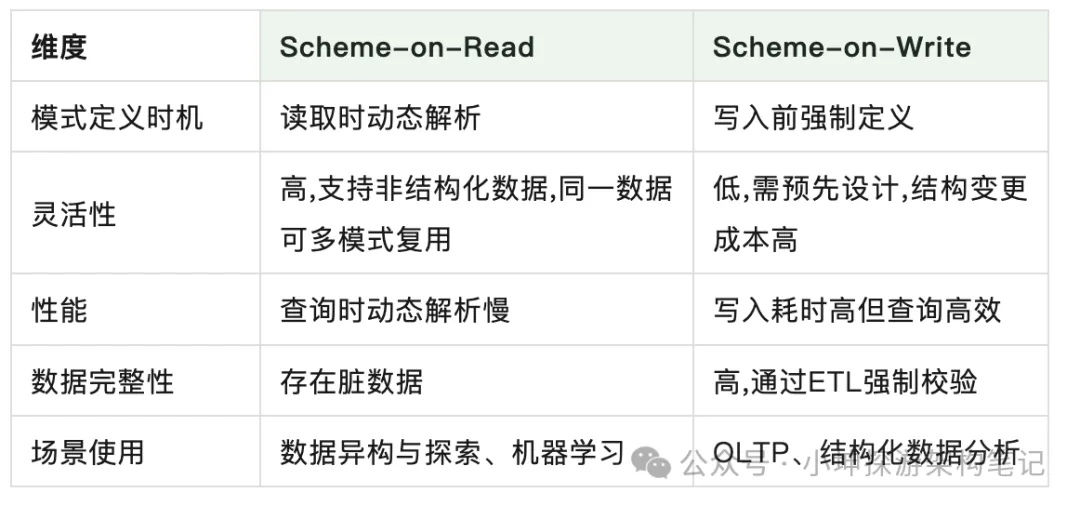
UPDATE users set first_name = substring_index(name, ' ', 1);不过相信你到时候应该是有点疑惑的, 因为你也许会问我用JSON也是可以加一个firstName字段, MySQL也可以不通过新增加一个firstName的列也可以在应用程序中控制, 是的, 没错. 但是你有没有想过一个问题, 既然存储是采用松散的契约方式存储, 那么必然有它采用松散契约方式的考量, 比如保证灵活性, 控制变更; 而采用MySQL的存储格式, 同样是为了保证双方数据对齐, 目的是做静态检查, 保证字段与类型对齐. 这里也给出读时与写时模式的对比:
图片
数据编码的前向与后向兼容
相信到这里我们已经明白架构决策、数据模型读写时模式含义, 那么接下来就是我们落地实现契约具体实现方式需要考虑的问题, 即前向兼容与后向兼容.
什么意思呢? 我们可以先看下面的例子如下, 在一个数据存储中, 架构中的A组件向存储写入数据X, 而B组件可以从相同的存储中读取数据X, 如果我们将存储介质进行泛化, 那么它还可以是一个网络通信管道, 如下:
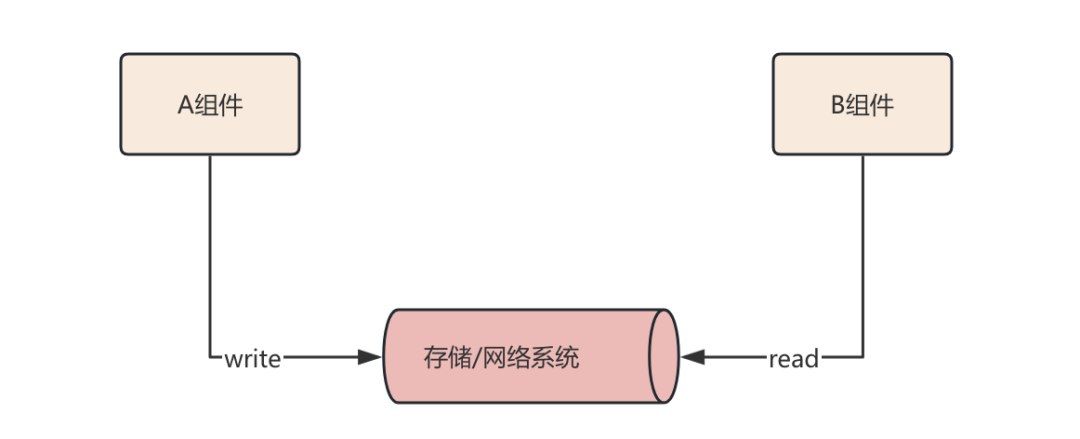
其实上述就是组件A与组件B之间进行数据通信的过程, 那么彼此之间必然需要建立起一个统一的交流“语言”, 而这个“语言” 我们会称之为协议.
如果A组件与B组件之间采用PB2格式的协议(严格契约的实现)进行通信, 那么假如其对应的协议定义如下:
message Person{
required string user_name = 1;
optional int64 favorite_number = 2;
repated string interests = 3;
}随着时间的推移, 假如A组件因业务需求变更, 其存储/发送的数据协议也会随之变更, 我们称之为模式演进, 也就是A写时模式发生变化, 需要增加一个firstName字段且必须为required, 即:
message Person{
required string user_name = 1;
optional int64 favorite_number = 2;
repated string interests = 3;
required string first_name = 4;
}那么这个时候B组件读取X数据的时候将会发生什么呢? 很明显就是解析失败无法读取到X的数据, 因为B组件还是沿用旧协议, 并没有发生更新, 这种就是没有做到前向兼容: 较旧的代码能够读取由较新代码写入的数据。
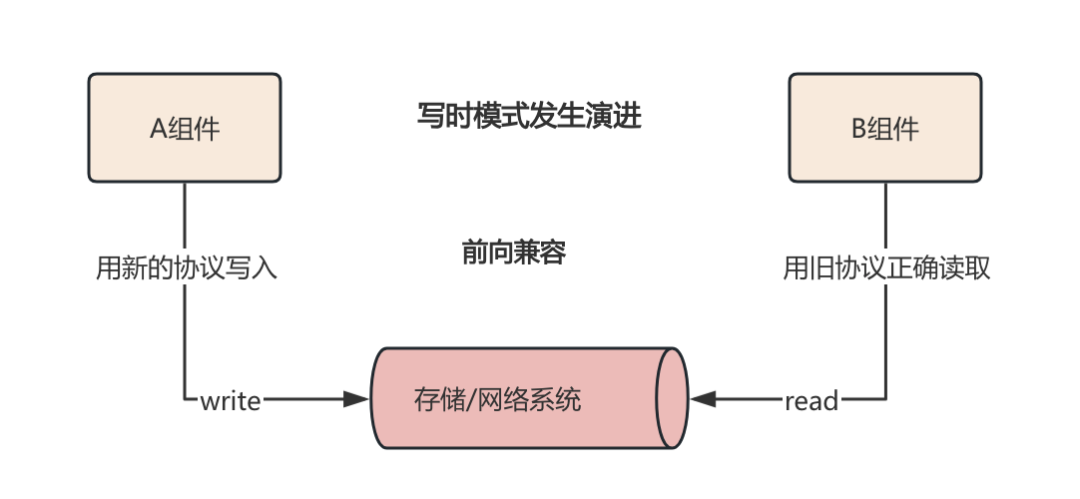
那么后向兼容呢? 就是上述反过来, 即用旧的协议写入数据, 并能够用新的协议正确读取出来, 即:
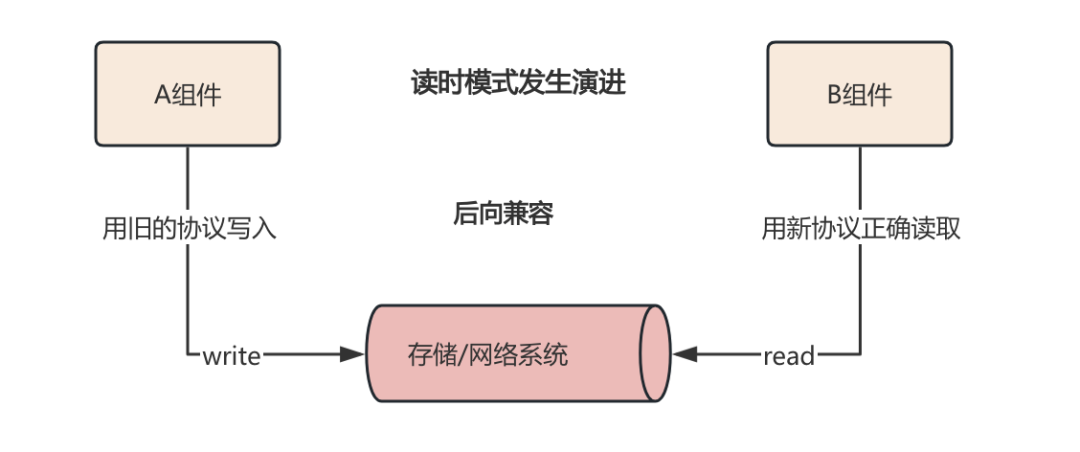
可以看到当我们的模式发生演进的时候, 我们就需要考虑前向兼容或者是后向兼容.这也是我们在设计具体契约协议时需要考虑不同数据模型的读写时模式, 关注模式的演进, 考虑协议在后续过程中的前后向兼容情况.
那么既然PB2格式无法满足前后向兼容, 于是才有了PB3的格式, PB3相比PB2格式少了一个required的修饰, 也就是说PB3的格式都是默认为optional, 也就是它是可选的, 不会强制要求一个字段是必须的, 相比PB2会更为宽松一些. 我们其实可以来看下PB结构的底层存储方式, 如下来自《设计数据密集系统》, PB协议会存储我们的tag、type以及数据值, 也就是说PB协议定义的属性名称并不影响其内部存储方式, 由此也给了我们一个信息: 那就是如果定义的tag对应的类型发生变化, 那么就会导致其他依赖这份PB3协议的其他组件会出现解析失败的情况, 比如上述的favorite_number调整为string那么就会出现解析错误的情况.
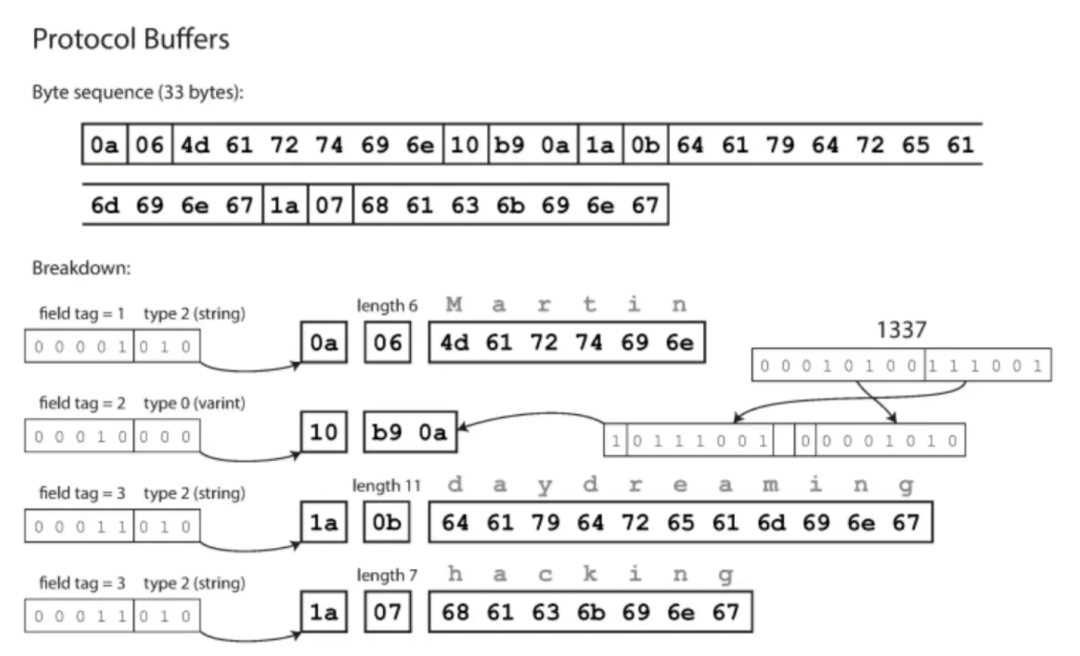
从上述其实可以看出, 在前面展示的模式中,每个字段都标记为 required (必需)或 optional(可选),但这对字段的编码方式并无影响(二进制数据中没有任何内容表明某个字段是否为必需)。两者的区别仅仅在于, required 会在运行时进行检查,如果该字段未设置则会失败,这对于捕捉错误很有用。
总结
最后我们做一个总结, 当我们在进行架构契约决策的时候, 纠结到底采用什么协议的时候, 我们可以考虑以下方法论:
- 首先, 明确当前架构需求背景, 澄清目标, 比如你的需求是需要满足什么架构特征;
- 其次, 梳理整个系统相关的组件之间的协作关系, 理清通信交互链路流程;
- 基于通信链路, 利用严格到松散的契约类型去分析我们组件之间耦合与变更频率带来的影响并记录问题以及解决方案, 编写ADR文档记录架构决策背景、解决方案以及为什么是这个方案;
- 最后是在具体落地的时候, 我们应当充分考虑协议实现的前后向兼容情况, 并在此基础上进行架构特征排序, 比如我当前的系统并不需要高性能而是可读性强, 那么这个时候也许JSON格式是一个更好的选择.
你好,我是疾风先生, 主要从事互联网搜广推行业, 技术栈为java/go/python, 记录并分享个人对技术的理解与思考, 欢迎关注我的公众号, 致力于做一个有深度,有广度,有故事的工程师,欢迎成长的路上有你陪伴,关注后回复greek可添加私人微信,欢迎技术互动和交流,谢谢!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号