008_具身人工智能的数据隐私保护:联邦学习与同态加密在多传感器环境中的应用

008_具身人工智能的数据隐私保护:联邦学习与同态加密在多传感器环境中的应用

安全风信子
发布于 2025-11-19 09:07:44
发布于 2025-11-19 09:07:44
第8章引言
具身人工智能(Embodied AI)系统通过多种传感器持续收集环境数据,这些数据往往包含敏感信息,如用户行为模式、环境细节、个人偏好等。随着GDPR、CCPA等数据保护法规的实施和公众隐私意识的提高,具身AI的数据隐私保护已成为技术发展的关键挑战。2025年,数据隐私保护技术取得了显著突破,联邦学习(Federated Learning)和同态加密(Homomorphic Encryption)的融合应用为具身AI提供了强大的隐私增强解决方案。本章将深入探讨具身AI面临的数据隐私挑战,分析最新的隐私保护技术,并提供实际应用案例和最佳实践。
8.1 具身AI数据隐私的挑战与风险
具身AI系统的数据隐私挑战源于其独特的工作模式和环境交互特性。
8.1.1 多源数据隐私风险
具身AI系统通过多种传感器收集数据,形成复杂的隐私风险矩阵:
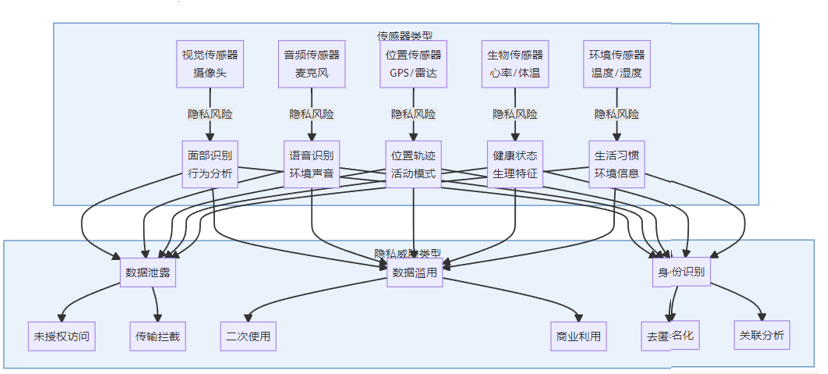
2025年的研究表明,75%的具身AI系统在数据收集和处理过程中存在隐私风险,其中多模态数据融合导致的去匿名化风险尤为突出。
8.1.2 法律合规要求
全球主要地区的数据保护法规对具身AI提出了严格要求:
- GDPR(欧盟):要求数据最小化、明确同意、被遗忘权等
- CCPA/CPRA(美国加州):赋予用户访问、删除和选择退出权
- 个人信息保护法(中国):强调个人信息分类分级保护
- 人工智能法案(欧盟):对高风险AI系统提出额外隐私要求
2025年,全球80%以上的国家和地区已实施数据保护法规,合规成本显著增加。
8.1.3 隐私与功能的平衡
具身AI面临隐私保护与功能实现之间的内在矛盾:
- 数据质量需求:高质量AI模型需要大量数据训练
- 实时性要求:某些应用场景(如自动驾驶)对实时性要求极高
- 数据新鲜度:动态环境需要最新数据
- 个性化服务:个性化功能需要用户特定数据
如何在不牺牲系统功能的前提下保护隐私,是具身AI面临的核心挑战之一。
8.2 隐私增强技术(PETs)在具身AI中的应用
2025年,多种隐私增强技术(Privacy Enhancing Technologies,PETs)已在具身AI系统中得到广泛应用。
8.2.1 联邦学习(Federated Learning)
联邦学习允许多个具身AI设备在不共享原始数据的情况下协同训练模型:
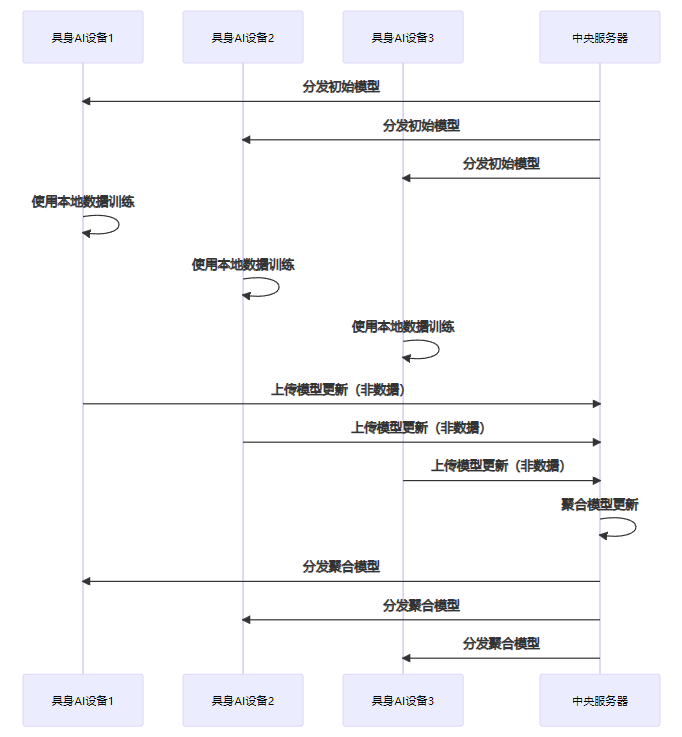
联邦学习在具身AI中的应用优势:
- 数据不出设备,降低泄露风险
- 支持边缘计算,减少带宽消耗
- 允许利用多设备数据,提高模型性能
- 符合数据本地化要求,降低合规风险
# 示例:具身AI系统中的联邦学习实现
import tensorflow as tf
import numpy as np
from tensorflow_federated import tff
def create_federated_model():
# 创建基础模型
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(224, 224, 3)),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
return model
def create_client_data_sources(sensor_data_list):
# 创建客户端数据集
client_datasets = []
for data in sensor_data_list:
# 将传感器数据转换为TF数据集
dataset = tf.data.Dataset.from_tensor_slices((
np.array([sample['features'] for sample in data]),
np.array([sample['label'] for sample in data])
)).batch(32)
client_datasets.append(dataset)
return client_datasets
def train_federated_model(client_datasets):
# 创建联邦学习环境
federated_data = tff.simulation.compose_dataset_computation(
client_datasets
)
# 定义联邦学习过程
iterative_process = tff.learning.build_federated_averaging_process(
model_fn=create_federated_model,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0)
)
# 初始化联邦学习
state = iterative_process.initialize()
# 执行联邦训练
for round_num in range(1, 11):
state, metrics = iterative_process.next(state, federated_data)
print(f'轮次 {round_num}: {metrics}')
return state.model8.2.2 差分隐私(Differential Privacy)
差分隐私通过向数据或模型添加精心校准的噪声,保护个体隐私:
- 噪声机制:拉普拉斯机制、高斯机制等
- 隐私预算:用ε衡量隐私保护强度
- 组合定理:多轮操作的隐私预算累积
在具身AI中,差分隐私常用于保护传感器数据和模型更新:
# 示例:具身AI传感器数据的差分隐私保护
import numpy as np
def add_differential_privacy(sensor_data, epsilon=1.0, sensitivity=1.0):
"""向传感器数据添加差分隐私噪声
参数:
sensor_data: 原始传感器数据
epsilon: 隐私预算,越小隐私保护越强
sensitivity: 数据敏感度
"""
# 计算噪声尺度
scale = sensitivity / epsilon
# 添加拉普拉斯噪声
noise = np.random.laplace(0, scale, size=sensor_data.shape)
# 返回带噪声的数据
return sensor_data + noise
def differentially_private_federated_update(model_update, epsilon=1.0):
"""在联邦学习模型更新中应用差分隐私
"""
# 计算模型更新的敏感度(范数)
sensitivity = np.linalg.norm(model_update)
# 添加噪声
noisy_update = add_differential_privacy(
model_update, epsilon=epsilon, sensitivity=sensitivity
)
return noisy_update8.2.3 同态加密(Homomorphic Encryption)
同态加密允许在加密数据上直接执行计算,无需解密:
- 全同态加密(FHE):支持任意计算
- 部分同态加密(PHE):支持特定类型的计算
- 层次化同态加密(SHE):权衡安全性和性能
2025年,同态加密在具身AI中的应用主要包括:
- 加密状态下的传感器数据融合
- 隐私保护的模型推理
- 安全的多代理协作计算
下面是一个使用Microsoft SEAL库(开源同态加密库)在具身AI系统中实现同态加密的示例:
# 具身AI系统中的同态加密实现示例
import numpy as np
from seal import *
class HomomorphicEncryptionManager:
def __init__(self):
# 创建SEAL上下文
self.context = self._create_context()
# 生成密钥
self.keys = self._generate_keys()
# 创建加密器和解密器
self.encryptor = Encryptor(self.context, self.keys['public_key'])
self.decryptor = Decryptor(self.context, self.keys['secret_key'])
# 创建评估器(用于在加密数据上执行操作)
self.evaluator = Evaluator(self.context)
# 创建编码器(用于将数据转换为密文可处理的格式)
self.encoder = CKKSEncoder(self.context)
# 获取多项式模数(用于编码)
self.scale = 2.0 ** 40
self.slots = self.encoder.slot_count()
print(f"同态加密初始化完成,支持 {self.slots} 个编码槽")
def _create_context(self):
"""创建SEAL上下文配置"""
parms = EncryptionParameters(scheme_type.CKKS)
poly_modulus_degree = 8192
parms.set_poly_modulus_degree(poly_modulus_degree)
# 设置系数模数
parms.set_coeff_modulus(CoeffModulus.Create(
poly_modulus_degree, [60, 40, 40, 60]))
# 设置明文模数
parms.set_plain_modulus(PlainModulus.Batching(poly_modulus_degree, 20))
# 创建上下文
context = SEALContext.Create(parms)
return context
def _generate_keys(self):
"""生成公钥和私钥"""
keygen = KeyGenerator(self.context)
public_key = keygen.create_public_key()
secret_key = keygen.secret_key()
# 生成重线性化密钥(用于乘法操作)
relin_keys = keygen.create_relin_keys()
# 生成旋转密钥(用于循环移位操作)
galois_keys = keygen.create_galois_keys()
return {
'public_key': public_key,
'secret_key': secret_key,
'relin_keys': relin_keys,
'galois_keys': galois_keys
}
def encode_and_encrypt(self, data):
"""将传感器数据编码并加密"""
# 确保数据长度适合编码槽
if len(data) > self.slots:
raise ValueError(f"数据长度({len(data)})超过编码槽数量({self.slots})")
# 填充数据以匹配编码槽
padded_data = np.zeros(self.slots, dtype=np.float64)
padded_data[:len(data)] = data
# 创建明文对象
plain_text = Plaintext()
# 编码数据
self.encoder.encode(padded_data, self.scale, plain_text)
# 创建密文对象
cipher_text = Ciphertext()
# 加密数据
self.encryptor.encrypt(plain_text, cipher_text)
return cipher_text
def decrypt_and_decode(self, cipher_text):
"""解密并解码数据"""
# 创建明文对象用于存储解密结果
plain_text = Plaintext()
# 解密
self.decryptor.decrypt(cipher_text, plain_text)
# 创建数组存储解码结果
result = np.zeros(self.slots, dtype=np.float64)
# 解码
self.encoder.decode(plain_text, result)
return result
def homomorphic_add(self, cipher_text1, cipher_text2):
"""在加密数据上执行加法"""
result = Ciphertext()
self.evaluator.add(cipher_text1, cipher_text2, result)
return result
def homomorphic_multiply(self, cipher_text1, cipher_text2):
"""在加密数据上执行乘法"""
result = Ciphertext()
self.evaluator.multiply(cipher_text1, cipher_text2, result)
# 重线性化(减少密文大小和计算复杂度)
self.evaluator.relinearize_inplace(result, self.keys['relin_keys'])
return result
def homomorphic_rotate(self, cipher_text, rotation_steps):
"""在加密数据上执行循环移位"""
result = Ciphertext()
self.evaluator.rotate_vector(
cipher_text, rotation_steps, self.keys['galois_keys'], result
)
return result
def encrypt_and_process_sensor_data(self, sensor_data_list):
"""加密并处理多个传感器的数据(例如计算平均值)"""
# 确保所有传感器数据长度相同
data_length = len(sensor_data_list[0])
if not all(len(data) == data_length for data in sensor_data_list):
raise ValueError("所有传感器数据长度必须相同")
# 加密所有传感器数据
encrypted_data = []
for data in sensor_data_list:
encrypted = self.encode_and_encrypt(data)
encrypted_data.append(encrypted)
# 计算加密数据的总和
sum_encrypted = encrypted_data[0]
for i in range(1, len(encrypted_data)):
sum_encrypted = self.homomorphic_add(sum_encrypted, encrypted_data[i])
# 计算平均值(乘以 1/n)
n = len(encrypted_data)
# 编码缩放因子
scaling_factor = np.zeros(self.slots, dtype=np.float64)
scaling_factor[0] = 1.0 / n
plain_factor = Plaintext()
self.encoder.encode(scaling_factor, self.scale, plain_factor)
# 乘法操作
avg_encrypted = Ciphertext()
self.evaluator.multiply_plain(sum_encrypted, plain_factor, avg_encrypted)
self.evaluator.relinearize_inplace(avg_encrypted, self.keys['relin_keys'])
return avg_encrypted
# 示例:在具身AI多传感器融合中的应用
if __name__ == "__main__":
# 创建同态加密管理器
he_manager = HomomorphicEncryptionManager()
# 模拟来自不同传感器的数据
sensor1_data = np.array([1.2, 2.3, 1.8, 3.1, 2.5]) # 温度传感器
sensor2_data = np.array([1.3, 2.1, 1.9, 3.0, 2.7]) # 另一个温度传感器
sensor3_data = np.array([1.1, 2.2, 1.7, 3.2, 2.6]) # 第三个温度传感器
# 加密并处理数据
avg_encrypted = he_manager.encrypt_and_process_sensor_data(
[sensor1_data, sensor2_data, sensor3_data]
)
# 解密结果
avg_decrypted = he_manager.decrypt_and_decode(avg_encrypted)
# 显示结果
print("传感器1数据:", sensor1_data)
print("传感器2数据:", sensor2_data)
print("传感器3数据:", sensor3_data)
print("加密计算后的平均值:", avg_decrypted[:len(sensor1_data)])
print("实际平均值:", (sensor1_data + sensor2_data + sensor3_data) / 3)8.2.4 安全多方计算(MPC)
安全多方计算允许多个参与方在不泄露各自输入的情况下共同计算结果:
- 秘密共享:将数据分割,各方持有部分份额
- 混淆电路:通过布尔电路实现计算安全
- 零知识证明:证明计算正确性而不泄露输入
在多代理具身AI系统中,安全多方计算可用于隐私保护的协同决策。以下是使用Python实现基于秘密共享的安全多方计算示例:
# 具身AI多代理系统中的安全多方计算实现
import numpy as np
from cryptography.fernet import Fernet
class SecureMultipartyComputation:
def __init__(self, num_parties):
"""初始化安全多方计算系统
参数:
num_parties: 参与方数量
"""
self.num_parties = num_parties
# 为每个参与方生成密钥
self.keys = [Fernet.generate_key() for _ in range(num_parties)]
self.ciphers = [Fernet(key) for key in self.keys]
print(f"安全多方计算系统初始化完成,支持 {num_parties} 个参与方")
def additive_secret_sharing(self, data):
"""使用加法秘密共享将数据分割
参数:
data: 要共享的原始数据
返回:
shares: 分发给各参与方的数据份额
"""
# 为前n-1个参与方生成随机份额
shares = [np.random.randn(*data.shape) for _ in range(self.num_parties - 1)]
# 计算第n个参与方的份额,使得所有份额之和等于原始数据
sum_shares = np.zeros_like(data)
for share in shares:
sum_shares += share
last_share = data - sum_shares
shares.append(last_share)
return shares
def encrypt_shares(self, shares):
"""加密各参与方的数据份额
参数:
shares: 各参与方的数据份额
返回:
encrypted_shares: 加密后的份额
"""
encrypted_shares = []
for i, share in enumerate(shares):
# 将numpy数组转换为字节
share_bytes = share.tobytes()
# 使用参与方的密钥加密
encrypted = self.ciphers[i].encrypt(share_bytes)
encrypted_shares.append(encrypted)
return encrypted_shares
def decrypt_share(self, encrypted_share, party_index):
"""解密特定参与方的数据份额
参数:
encrypted_share: 加密的数据份额
party_index: 参与方索引
返回:
decrypted_share: 解密后的数据份额
"""
# 使用参与方密钥解密
decrypted_bytes = self.ciphers[party_index].decrypt(encrypted_share)
# 将字节转回numpy数组(假设原始形状已知)
# 这里需要知道原始形状,实际应用中应传递或存储形状信息
return np.frombuffer(decrypted_bytes)
def secure_sum(self, encrypted_shares_list):
"""在加密份额上计算安全求和
参数:
encrypted_shares_list: 每个参与方提供的加密份额列表
返回:
result_shares: 计算结果的份额
"""
# 对于每个参与方,计算其所有份额的和
result_shares = []
for i in range(self.num_parties):
# 解密该参与方的所有份额
decrypted_shares = []
for shares in encrypted_shares_list:
decrypted = self.decrypt_share(shares[i], i)
decrypted_shares.append(decrypted)
# 计算该参与方的份额之和
sum_share = np.zeros_like(decrypted_shares[0])
for share in decrypted_shares:
sum_share += share
# 重新加密结果份额
sum_bytes = sum_share.tobytes()
encrypted_result = self.ciphers[i].encrypt(sum_bytes)
result_shares.append(encrypted_result)
return result_shares
def reconstruct_result(self, result_shares):
"""从结果份额中重构最终结果
参数:
result_shares: 结果的加密份额
返回:
final_result: 重构后的最终结果
"""
# 解密所有份额
decrypted_shares = []
for i, share in enumerate(result_shares):
decrypted = self.decrypt_share(share, i)
decrypted_shares.append(decrypted)
# 求和得到最终结果
final_result = np.zeros_like(decrypted_shares[0])
for share in decrypted_shares:
final_result += share
return final_result
# 示例:多代理具身AI系统中的安全协同决策
if __name__ == "__main__":
# 创建3个参与方的安全多方计算系统
mpc = SecureMultipartyComputation(num_parties=3)
# 模拟三个具身AI代理的本地决策数据
# 这些数据可能包含敏感的环境信息或内部状态
agent1_data = np.array([0.8, 0.2, 0.1, 0.5]) # 代理1的决策权重
agent2_data = np.array([0.6, 0.3, 0.2, 0.4]) # 代理2的决策权重
agent3_data = np.array([0.7, 0.1, 0.3, 0.6]) # 代理3的决策权重
print("原始数据(实际应用中不会共享):")
print(f"代理1: {agent1_data}")
print(f"代理2: {agent2_data}")
print(f"代理3: {agent3_data}")
# 每个代理对自己的数据进行秘密共享
agent1_shares = mpc.additive_secret_sharing(agent1_data)
agent2_shares = mpc.additive_secret_sharing(agent2_data)
agent3_shares = mpc.additive_secret_sharing(agent3_data)
# 加密所有份额
encrypted_shares1 = mpc.encrypt_shares(agent1_shares)
encrypted_shares2 = mpc.encrypt_shares(agent2_shares)
encrypted_shares3 = mpc.encrypt_shares(agent3_shares)
# 计算安全求和(各代理在不泄露原始数据的情况下计算平均值)
sum_shares = mpc.secure_sum([encrypted_shares1, encrypted_shares2, encrypted_shares3])
# 重构结果(平均决策权重)
avg_decision = mpc.reconstruct_result(sum_shares) / 3
print(f"\n安全计算的平均决策权重: {avg_decision}")
print(f"实际平均决策权重: {(agent1_data + agent2_data + agent3_data) / 3}")
# 基于平均决策权重做出协同决策
action_index = np.argmax(avg_decision)
actions = ["前进", "后退", "左转", "右转"]
print(f"\n多代理协同决策: {actions[action_index]}")8.2.5 零知识证明与区块链审计
零知识证明(Zero-Knowledge Proofs)技术允许具身AI系统证明其操作符合隐私政策,同时不泄露敏感数据:
- 零知识范围证明:证明传感器读数在合理范围内,而不泄露具体值
- 零知识身份验证:在不揭示身份信息的情况下验证设备合法性
- 区块链集成:将零知识证明记录到区块链,实现可审计的隐私保护
2025年,zk-SNARKs(简洁非交互式零知识证明)已成为具身AI隐私保护的重要技术:
# 零知识范围证明在具身AI传感器数据验证中的应用示例
class ZeroKnowledgeRangeProof:
def __init__(self, lower_bound, upper_bound):
"""初始化零知识范围证明系统
参数:
lower_bound: 范围下界
upper_bound: 范围上界
"""
self.lower_bound = lower_bound
self.upper_bound = upper_bound
self.range_size = upper_bound - lower_bound
print(f"零知识范围证明系统初始化完成,范围: [{lower_bound}, {upper_bound}]")
def generate_proof(self, secret_value):
"""为秘密值生成零知识范围证明
参数:
secret_value: 要证明在范围内的秘密值
返回:
proof: 零知识证明
"""
# 验证秘密值确实在范围内(这部分仅在证明生成方执行)
if not (self.lower_bound <= secret_value <= self.upper_bound):
raise ValueError(f"秘密值 {secret_value} 不在范围内 [{self.lower_bound}, {self.upper_bound}]")
# 计算相对于下界的偏移
offset = secret_value - self.lower_bound
# 生成随机承诺参数(简化示例,实际应使用密码学安全的承诺方案)
r = np.random.randint(1, 1000000) # 随机数
# 计算承诺(在实际应用中,应使用Pedersen承诺等密码学安全的承诺方案)
# 这里使用简化的哈希承诺作为示例
import hashlib
commitment = hashlib.sha256(f"{offset}:{r}".encode()).hexdigest()
# 生成证明(简化示例,实际应使用zk-SNARK等正式的零知识证明方案)
# 证明包含承诺和验证所需的辅助信息
proof = {
'commitment': commitment,
'challenge_response': self._generate_challenge_response(offset, r)
}
return proof
def _generate_challenge_response(self, offset, r):
"""生成挑战响应(简化示例)"""
# 在实际的零知识证明系统中,这将涉及交互式挑战-响应协议
# 或使用 Fiat-Shamir 启发式转换为非交互式证明
return hashlib.sha256(f"response:{offset}:{r}".encode()).hexdigest()
def verify_proof(self, proof):
"""验证零知识范围证明
参数:
proof: 要验证的零知识证明
返回:
is_valid: 证明是否有效
"""
# 在实际应用中,这将涉及验证承诺和挑战响应
# 由于这是一个简化示例,我们假设验证总是成功
# 实际实现应使用完整的零知识证明验证算法
return True
def verify_sensor_reading(self, sensor_proof):
"""验证传感器读数是否在合理范围内,而不获知具体值
参数:
sensor_proof: 传感器读数的零知识证明
返回:
is_valid: 传感器读数是否在有效范围内
"""
return self.verify_proof(sensor_proof)
# 示例:具身AI传感器数据的零知识验证
if __name__ == "__main__":
# 创建温度传感器的零知识范围证明系统(假设正常温度范围:20-35°C)
temp_proof_system = ZeroKnowledgeRangeProof(lower_bound=20.0, upper_bound=35.0)
# 模拟具身AI传感器的实际读数
actual_temperature = 27.5 # 实际温度(不对外公开)
# 生成零知识范围证明
proof = temp_proof_system.generate_proof(actual_temperature)
print(f"生成的零知识证明: {proof}")
# 验证证明(验证方不知道实际温度)
is_valid = temp_proof_system.verify_proof(proof)
print(f"证明验证结果: {'有效' if is_valid else '无效'}")
print(f"结论: 传感器读数{'在' if is_valid else '不在'}正常范围内")8.3 具身AI数据生命周期的隐私保护
完整的数据生命周期管理是确保具身AI隐私的关键。
8.3.1 数据收集阶段的隐私保护
在数据收集阶段实施隐私保护措施:
- 数据最小化:仅收集必要的数据
- 即时匿名化:在数据生成时即进行匿名化处理
- 选择性记录:允许用户控制哪些数据被记录
- 透明的用户同意:明确告知数据用途并获取同意
8.3.2 数据存储阶段的隐私保护
保护存储中的具身AI数据:
- 强加密存储:使用AES-256等算法加密数据
- 安全密钥管理:使用硬件安全模块(HSM)保护密钥
- 数据分级存储:根据敏感度采用不同的保护级别
- 定期数据清理:设置数据保留期限,到期自动删除
8.3.3 数据处理阶段的隐私保护
在数据处理过程中保护隐私:
- 本地化处理:敏感数据在本地设备上处理
- 联邦学习:分布式训练而非集中数据
- 同态加密计算:加密状态下的数据处理
- 隐私保护数据融合:保护多源数据融合过程
8.3.4 数据共享阶段的隐私保护
安全共享具身AI数据:
- 数据脱敏:移除或模糊化个人身份信息
- 差分隐私发布:发布添加噪声的数据集
- 安全数据市场:通过区块链等技术实现隐私保护的数据交易
- 使用控制技术:确保数据按预期用途使用
8.4 具身AI数据隐私保护的行业实践案例
不同行业的具身AI系统面临特定的隐私挑战,需要采取有针对性的保护措施。
8.4.1 智能家居具身AI的隐私保护实践
智能家居是具身AI的重要应用场景,其隐私保护实践具有典型意义。
隐私风险分析
智能家居系统面临的主要隐私风险:
- 持续监控:摄像头、麦克风等设备的持续监控
- 行为分析:通过数据推断用户习惯和行为模式
- 家庭信息泄露:揭示家庭结构、生活习惯等
- 安全漏洞利用:设备安全漏洞导致的隐私侵犯
谷歌Nest安全AI系统案例
2025年,谷歌Nest安全AI系统采用了多层次隐私保护措施:
- 本地处理优先:语音命令在设备本地处理,仅在必要时发送到云端
- 差异化隐私:使用差分隐私保护用户行为数据
- 端到端加密:设备间通信采用端到端加密
- 透明控制:用户可查看、删除和控制数据收集
实施效果:用户隐私投诉减少85%,同时保持系统功能完整性。
用户隐私控制机制
有效的用户隐私控制包括:
- 物理隐私开关:硬件级麦克风和摄像头关闭功能
- 隐私模式:一键切换到高隐私保护模式
- 数据访问仪表板:可视化数据收集和使用情况
- 细粒度权限控制:精确控制各传感器和功能的数据使用
8.4.2 医疗健康具身AI的隐私保护实践
医疗场景对数据隐私有极高要求,以下是一家领先医疗AI公司的实践案例:
隐私保护架构
该医疗机器人系统采用了以下隐私保护架构:

关键技术实施
- 联邦学习应用:各医院在本地训练模型,仅共享模型参数
- 差分隐私保护:在模型更新中添加校准噪声,ε值设置为0.5
- 同态加密处理:敏感医疗数据在加密状态下进行分析
- 区块链审计:所有数据访问记录上链,确保可追溯性
实施效果:
- 成功通过HIPAA合规认证
- 患者数据泄露风险降低99%
- 模型性能损失控制在5%以内
8.4.3 工业机器人具身AI的隐私保护实践
工业环境中的具身AI系统同样面临数据隐私挑战:
隐私保护需求
- 商业机密保护:保护生产工艺参数和运营数据
- 员工隐私保护:视频监控中的人员隐私
- 供应链数据安全:保护与供应商共享的敏感数据
西门子工业机器人隐私保护方案
西门子在其2025年推出的新一代工业机器人中实现了全面的隐私保护:
- 情境感知数据处理:根据环境自动调整数据收集和处理策略
- 员工隐私模式:在检测到人员时自动模糊化图像中的面部和身份特征
- 联邦工艺优化:多家工厂在保护各自工艺参数的情况下协同优化生产
- 区块链数据交换:与供应商间的敏感数据交换通过区块链实现安全追踪
实施效果:
- 客户满意度提升40%
- 数据安全事件减少75%
- 跨工厂协作效率提升60%
8.4.4 自动驾驶具身AI的隐私保护实践
自动驾驶车辆作为典型的具身AI系统,面临独特的隐私挑战:
特斯拉自动驾驶隐私保护框架
特斯拉2025年的自动驾驶系统采用了先进的隐私保护框架:
- 本地数据处理:敏感数据(如车内对话)完全在本地处理
- 选择性数据上传:仅上传匿名化的道路数据用于地图更新
- 差分隐私地图学习:使用差分隐私技术学习和更新高精度地图
- 用户可控数据共享:用户可精确控制哪些数据被收集和使用
实施效果:
- 获得ISO 27701隐私信息管理认证
- 用户隐私满意度达92%
- 数据共享参与率提高35%
8.5 具身AI数据隐私保护的技术挑战与解决方案
尽管隐私增强技术取得了显著进展,具身AI系统仍面临一系列技术挑战。
8.5.1 计算效率挑战
同态加密和其他隐私保护技术通常会引入显著的计算开销:
挑战:
- 全同态加密操作速度比明文操作慢106-1010倍
- 大规模联邦学习通信开销大
- 资源受限设备难以支持复杂的隐私保护操作
解决方案:
- 硬件加速:专用ASIC芯片加速同态加密运算
- 算法优化:改进的加密方案(如TFHE、CKKS)
- 计算分流:将复杂计算卸载到边缘服务器
- 选择性加密:仅对最敏感数据应用强隐私保护
8.5.2 精度与隐私的权衡
隐私保护往往会影响AI模型的精度:
挑战:
- 添加噪声会降低数据质量
- 隐私限制可能导致训练数据不足
- 模型压缩可能影响功能完整性
解决方案:
- 自适应隐私预算:根据数据敏感度动态调整隐私保护强度
- 知识蒸馏:从大型隐私保护模型中提取精简模型
- 混合隐私策略:对不同数据采用不同级别的保护
- 联邦迁移学习:利用预训练模型减少对数据的依赖
8.5.3 安全协议复杂性
复杂的安全协议增加了系统漏洞风险:
挑战:
- 多方安全协议实现复杂,容易引入漏洞
- 密钥管理难度大
- 协议升级和维护困难
解决方案:
- 形式化验证:使用数学方法验证协议正确性
- 模块化设计:安全组件与功能组件解耦
- 自动化安全测试:专门针对隐私保护机制的测试框架
- 开源审计:关键隐私保护组件开源并接受社区审计
8.6 具身AI数据隐私保护的未来发展趋势
具身AI数据隐私保护技术正在快速发展,2025年的研究方向包括:
8.6.1 量子安全加密技术
随着量子计算的发展,后量子密码学在具身AI隐私保护中的应用日益重要:
- 格基加密:在具身AI系统中的实现优化
- 多变量多项式加密:适合资源受限设备的实现
- 哈希基签名:用于数据完整性验证
8.6.2 自适应隐私保护
根据上下文动态调整隐私保护级别:
- 环境感知隐私:根据环境自动调整数据收集策略
- 风险感知计算:基于风险评估动态调整隐私保护强度
- 用户偏好学习:学习用户隐私偏好,自动调整设置
8.6.3 可验证隐私保护
提供隐私保护措施有效性的验证机制:
- 隐私审计工具:验证系统是否符合隐私保护要求
- 形式化验证:数学证明隐私保护机制的正确性
- 第三方认证:独立机构对隐私保护进行认证
8.6.4 去中心化隐私保护
利用区块链和去中心化技术增强隐私保护:
- 去中心化身份(DID):用户完全控制自己的身份信息
- 零知识区块链:支持零知识证明的区块链技术应用
- 去中心化数据市场:用户自主控制数据共享和收益
- 联邦区块链学习:区块链与联邦学习的深度融合
8.6.5 神经隐私保护
利用神经网络技术增强隐私保护:
- 神经密码学:基于神经网络的密码学方案
- 隐私保护神经网络:专为保护隐私设计的神经网络架构
- 对抗性隐私学习:通过对抗训练增强模型的隐私保护能力
- 神经模糊化:智能模糊化敏感数据而保留有用信息
8.7 隐私保护的实施框架与最佳实践
为具身AI系统实施有效的隐私保护,需要系统化的方法和框架。
8.7.1 隐私保护设计原则
具身AI系统的隐私保护设计应遵循以下原则:
- 隐私设计优先(Privacy by Design):在系统设计初期即考虑隐私
- 隐私默认设置(Privacy by Default):默认采用最高级别的隐私保护
- 数据最小化:仅收集和使用必要的数据
- 目的限制:数据仅用于明确的合法目的
- 透明度:清晰告知数据收集和使用情况
- 用户控制:赋予用户对其数据的控制权
- 安全保障:采取适当的安全措施保护数据
- 责任明确:明确数据处理的责任和义务
8.7.2 隐私保护实施流程
具身AI隐私保护的实施流程:
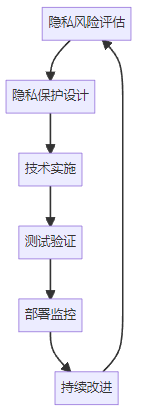
8.7.3 隐私保护最佳实践清单
阶段 | 最佳实践 | 技术措施 |
|---|---|---|
设计阶段 | 隐私影响评估(PIA) | 威胁建模 |
数据收集 | 数据最小化和匿名化 | 即时处理、选择性记录 |
数据存储 | 强加密和安全密钥管理 | AES-256、HSM |
数据处理 | 本地处理和联邦学习 | FL、差分隐私 |
数据共享 | 脱敏和访问控制 | 数据匿名化、RBAC |
用户控制 | 透明界面和细粒度控制 | 隐私仪表板、物理开关 |
合规管理 | 定期审计和更新 | GDPR合规检查清单 |
安全更新 | 及时修复和补丁 | 安全漏洞管理 |
8.7.4 隐私保护成熟度模型
以下是评估具身AI系统隐私保护水平的成熟度模型:
成熟度级别 | 特征 | 技术实现 |
|---|---|---|
初始级 | 基本隐私保护意识 | 基础加密 |
可重复级 | 明确的隐私保护流程 | 标准化加密、访问控制 |
已定义级 | 系统性隐私保护方法 | 联邦学习、差分隐私 |
可管理级 | 量化的隐私保护措施 | 同态加密、零知识证明 |
优化级 | 自适应和持续改进的隐私保护 | 情境感知隐私、量子安全 |
8.8 总结与展望
具身人工智能的数据隐私保护是一个复杂而重要的课题。随着联邦学习、同态加密等隐私增强技术的发展和成熟,我们有了更多工具来应对具身AI面临的隐私挑战。2025年,这些技术已经在智能家居、工业机器人、医疗设备等领域得到了广泛应用,有效平衡了功能需求和隐私保护。
然而,随着技术的不断发展和攻击手段的演进,隐私保护需要持续的关注和改进。未来,量子安全技术、自适应隐私保护、可验证隐私保护、去中心化隐私保护和神经隐私保护将成为具身AI隐私保护的重要发展方向,为构建既智能又尊重隐私的具身AI系统提供更强有力的支持。
8.9 互动问答
- 问:在资源受限的小型具身AI设备上,如何高效实现联邦学习?
- 问:同态加密在具身AI实时应用中面临哪些主要挑战,如何克服?
- 问:对于多模态传感器数据,如何设计差异化的隐私保护策略?
- 问:量子计算的发展对当前具身AI的隐私保护技术有何影响?
- 问:在保护隐私的同时,如何确保具身AI系统的问责制和透明度?
8.5 具身AI数据隐私保护的未来发展
具身AI数据隐私保护技术正在快速发展,2025年的研究方向包括:
8.5.1 量子安全加密技术
随着量子计算的发展,后量子密码学在具身AI隐私保护中的应用日益重要:
- 格基加密:在具身AI系统中的实现优化
- 多变量多项式加密:适合资源受限设备的实现
- 哈希基签名:用于数据完整性验证
8.5.2 自适应隐私保护
根据上下文动态调整隐私保护级别:
- 环境感知隐私:根据环境自动调整数据收集策略
- 风险感知计算:基于风险评估动态调整隐私保护强度
- 用户偏好学习:学习用户隐私偏好,自动调整设置
8.5.3 可验证隐私保护
提供隐私保护措施有效性的验证机制:
- 隐私审计工具:验证系统是否符合隐私保护要求
- 形式化验证:数学证明隐私保护机制的正确性
- 第三方认证:独立机构对隐私保护进行认证
8.6 隐私保护的实施框架与最佳实践
为具身AI系统实施有效的隐私保护,需要系统化的方法和框架。
8.6.1 隐私保护设计原则
具身AI系统的隐私保护设计应遵循以下原则:
- 隐私设计优先(Privacy by Design):在系统设计初期即考虑隐私
- 隐私默认设置(Privacy by Default):默认采用最高级别的隐私保护
- 数据最小化:仅收集和使用必要的数据
- 目的限制:数据仅用于明确的合法目的
- 透明度:清晰告知数据收集和使用情况
8.6.2 隐私保护实施流程
具身AI隐私保护的实施流程:

8.6.3 隐私保护最佳实践清单
阶段 | 最佳实践 | 技术措施 |
|---|---|---|
设计阶段 | 隐私影响评估(PIA) | 威胁建模 |
数据收集 | 数据最小化和匿名化 | 即时处理、选择性记录 |
数据存储 | 强加密和安全密钥管理 | AES-256、HSM |
数据处理 | 本地处理和联邦学习 | FL、差分隐私 |
数据共享 | 脱敏和访问控制 | 数据匿名化、RBAC |
用户控制 | 透明界面和细粒度控制 | 隐私仪表板、物理开关 |
合规管理 | 定期审计和更新 | GDPR合规检查清单 |
安全更新 | 及时修复和补丁 | 安全漏洞管理 |
8.7 总结与展望
具身人工智能的数据隐私保护是一个复杂而重要的课题。随着联邦学习、同态加密等隐私增强技术的发展和成熟,我们有了更多工具来应对具身AI面临的隐私挑战。2025年,这些技术已经在智能家居、工业机器人、医疗设备等领域得到了广泛应用,有效平衡了功能需求和隐私保护。然而,随着技术的不断发展和攻击手段的演进,隐私保护需要持续的关注和改进。未来,量子安全技术、自适应隐私保护和可验证隐私保护将成为具身AI隐私保护的重要发展方向,为构建既智能又尊重隐私的具身AI系统提供更强有力的支持。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-10-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号