数据孤岛不是问题,“数据脏乱差”才是真正障碍, ETL价值重估
原创
数据孤岛不是问题,“数据脏乱差”才是真正障碍, ETL价值重估
原创
用户7966476
发布于 2025-09-30 15:51:03
发布于 2025-09-30 15:51:03
数据孤岛不是问题,“数据脏乱差”才是真正障碍, ETL价值重估
在过去十几年里,企业在谈数据时最常提到的一个词是“数据孤岛”。ERP、CRM、OA、SCM……每一个系统都像是一个“烟囱”,数据难以互通,信息共享不足,导致业务协同效率低下。这类问题确实存在,但近几年在企业数字化转型的过程中,人们逐渐发现:相比“孤岛”,更棘手的问题其实是数据质量。
很多 CIO 直言,企业内部的数据并不是没有流动,而是“流动的是脏水”。数据冗余、缺失、冲突、延迟、口径不一致……这些“脏乱差”的现象直接削弱了决策的可信度。无论是 BI 报表还是 AI 模型,输入的是“垃圾”,输出的也只能是“垃圾”。于是,一个更深层次的议题被推到了台前:如何让数据真正“干净”,从而支撑企业级的业务真相?
为什么“数据脏乱差”成为全球性难题?
在全球范围内,数据质量早已成为企业数据治理的首要议题。Gartner 的研究报告指出,企业平均会因为数据质量问题造成 15%-25% 的运营成本浪费。而在金融、制造、零售等行业,这个比例甚至更高。
造成这一现象的原因主要有三点:
- 系统建设阶段的多样化 很多企业信息化经历了十几年的演进,不同阶段引入的系统供应商、数据标准、建模方式各不相同,导致源头上的口径不统一。
- 业务规则与现实偏差 企业在实际运行中常常会因为业务流程变更、员工习惯差异、跨部门协作等原因,导致同一字段存在多种记录方式。例如客户名称,有的用简称,有的用全称,还有的带符号或拼音。
- 数据更新与同步不及时 在多系统并行时,数据的写入频率、同步机制不同步,常出现“时间差”。例如库存系统显示有货,而电商前台却显示缺货,最终直接影响客户体验。
可以说,数据孤岛更多是“点与点之间的连通”问题,而“数据脏乱差”则是“水质”的问题。如果水质本身不干净,就算修通了所有管道,企业最终喝到的也还是“污水”。
ETL:让数据从“原料”到“真相”
ETL(Extract-Transform-Load)诞生于上世纪 80 年代,最初是为了支持数据仓库建设而产生的。经过数十年的发展,它已经成为全球公认的数据加工和质量保障的“基础设施”。ETL 的价值,正是将“原始的、分散的、脏乱差”的数据,转化为“干净的、统一的、可信的”数据资产。
从方法论上看,ETL 对数据质量提升的贡献主要体现在三个方面:
- 抽取(Extract):确保源数据的完整性 在抽取阶段,ETL 工具会对数据源进行校验,确保数据可以被完整获取。例如:日志缺失、表字段缺少、主键不唯一等问题,都能在抽取时被发现并记录,避免“带病”进入后续流程。
- 转换(Transform):核心的数据清洗与治理
转换是最复杂也是最关键的一步。这里涉及:
- 格式标准化:不同系统的日期、货币、编码方式不同,统一标准是第一步。
- 去重与合并:同一客户在不同系统中可能有多条记录,通过匹配规则和主数据管理(MDM)机制进行整合。
- 数据补全与修复:通过参考外部表或算法,对缺失值进行合理填充。
- 业务规则校验:例如,合同金额是否与订单金额一致,库存数是否为非负值等。
这一环节让原始数据真正“变干净”。
- 加载(Load):保证落地数据的一致与可追溯 在加载到目标系统时,ETL 不仅仅是“搬运”,还会通过审计日志、版本控制、错误回滚机制,确保进入数据仓库或数据湖的内容“可解释”“可回溯”。
真实案例:从“脏数据”到业务价值
在欧美金融机构中,ETL 被普遍用于应对合规性挑战。以反洗钱(AML)为例,银行需要实时监控客户交易,但客户资料往往存在缺失或不一致。通过 ETL,将来自 CRM、支付网关、核心账务系统的数据统一清洗,才能构建一个完整、可信的客户画像,满足监管要求。
在国内制造企业的案例中,某大型装备制造公司在使用 BI 系统时,发现同一款产品在不同车间的产量统计差异巨大。经排查,问题不在 BI,而在于源数据:不同车间的操作员对“报工单”字段填写习惯不同。通过 ETL 建立标准化映射和校验规则,企业才得以获得真实产能,并进一步用于优化排产。
这些案例说明,只有干净的数据才能反映业务的真相。任何依赖“脏乱差”数据的分析,最终只会误导管理层。
ETL 与现代数据架构的结合
有人会问,随着云计算、数据湖、实时流处理的出现,ETL 是否已经过时?答案是否定的。事实上,ETL 在全球范围内正在与新一代架构融合,演变出更灵活的形态:
- ELT 模式:在云数据仓库(如 Snowflake、BigQuery)中,更强调先加载再转换。但无论是 ETL 还是 ELT,本质都是“数据清洗与治理”的过程。
- 流式 ETL:在实时场景(IoT、互联网推荐系统)中,ETL 可以以流处理的方式运行,保证秒级的数据清洗与同步。
- 结合数据治理平台:现代 ETL 工具与元数据管理、主数据管理(MDM)、数据质量监控等平台结合,形成完整的“数据运营”体系。
这意味着,ETL 不仅没有过时,反而在全球范围内获得了新的生命力,成为企业数字化战略中的关键支撑点。
基于国产ETLCloud 的数据清洗探索
随着国产化替代与自主可控的推进,企业在 ETL 工具选择上也越来越关注本土化方案。传统的国际产品虽然功能强大,但在价格、服务响应、国产操作系统与数据库兼容性方面存在不小挑战。
ETLCloud社区版本 作为国内最专业的且可以免费使用的 ETL 平台,正是在这一背景下应运而生。它在多个方面回应了企业的痛点:
- 全国产环境适配:支持在国产操作系统、数据库、中间件上平稳运行,满足信创环境要求。
- 丰富的数据清洗能力:内置大量转换算子,涵盖格式转换、去重、校验、聚合、映射等常见场景。
- 大规模任务编排:支持数千任务并行调度,已在金融、制造行业的复杂项目中落地。
- 可视化与可扩展性:图形化界面降低使用门槛,同时开放 API 与插件机制,方便与企业现有平台融合。
值得注意的是,ETLCloud 并非只是简单的“搬运工具”,而是强调“数据质量保障”。
例如在某金融机构项目中,ETLCloud 被用于替代国外老牌 ETL 产品,成功支撑 2000+ 流程的平稳迁移,部署节点接近 20 个,实现了全链路的数据清洗与加工,完全满足监管合规与业务分析需求。
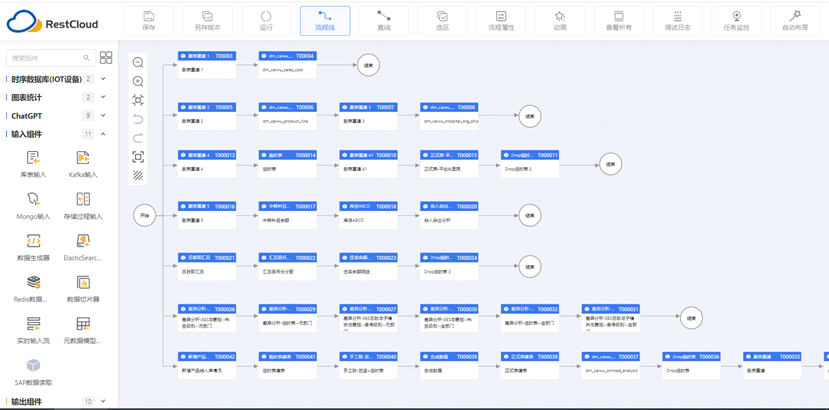
(ETLCloud通过图形化的方式构建数据清洗流程)
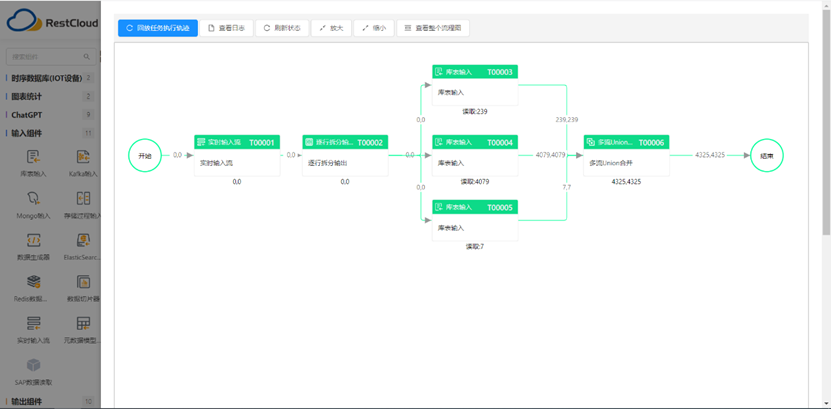
(ETLCloud可以实时监控数据传输过程)
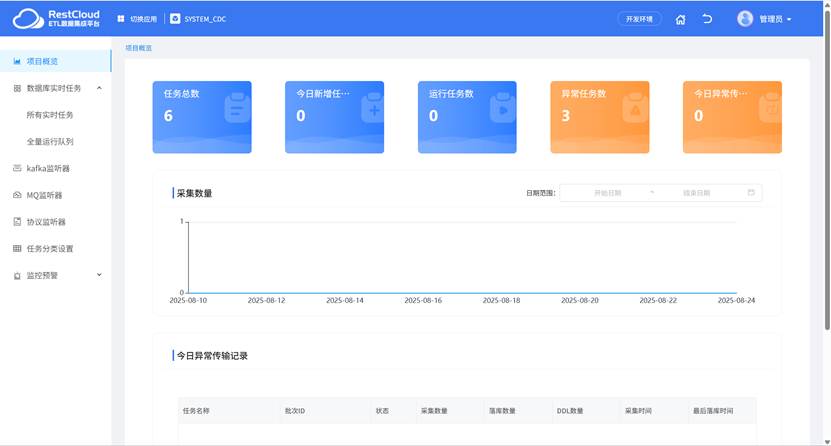
(同时支持CDC实时数据集成,让数据在企业内实时流动)
总结
今天企业的数据问题,并不是“有没有互通”的问题,而是“互通的数据是否可信”的问题。换句话说,数据孤岛不是终极难题,数据‘脏乱差’才是真正的障碍。
ETL 的价值在于为企业提供“干净的数据”,让 BI、AI、实时分析真正建立在可靠的基础之上。无论是在欧美的金融合规场景,还是在中国制造业的数字化车间,结论都是一致的:数据质量,才是企业能否获得真实业务洞察的关键。
而在国产化趋势下,像 ETLCloud 这样的本土 ETL 平台,正在成为越来越多企业的选择。它不仅帮助企业打破“脏乱差”的困境,更为未来的数据治理和数字化转型奠定坚实基础。
干净的数据,才有干净的真相。 这句话,看似朴素,却是当下企业走向数据驱动的核心要义。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号