搞懂 ELK 日志系统架构,这一篇就够了(含实战图解)
原创
搞懂 ELK 日志系统架构,这一篇就够了(含实战图解)
原创
随着系统架构的不断扩展和业务规模的迅猛增长,传统的日志管理方式已经难以应对海量分布式系统中的日志收集、查询和告警需求。为此,越来越多的企业开始引入成熟的日志系统方案,Elastic Stack(即 ELK + Beats) 便是其中最流行的一种。
本文将从日志系统的必要性讲起,深入剖析 ELK 各组件的工作原理、使用方式以及实际部署方式,帮助你全面理解并快速上手这一强大的日志平台。
为什么我们需要日志系统?
在现代微服务架构下:
- 业务发展迅猛,服务器节点数量爆炸式增长;
- 应用日志、访问日志、错误日志源源不断地产生;
- 开发人员需要登录多台服务器逐一排查问题,效率低、成本高。
因此,集中式日志系统 成为刚需,不仅能统一采集和处理日志,还能提升故障排查和运维效率。
什么是 Elastic Stack(ELK + Beats)
Elastic Stack 是一套开源的日志采集、处理、分析和可视化平台,通常包含以下几个核心组件:
组件 | 功能简介 |
|---|---|
Elasticsearch | 分布式搜索与分析引擎,负责存储和查询日志数据 |
Logstash | 日志收集、解析、清洗、转换的处理管道 |
Kibana | 可视化分析平台,提供丰富的 Web 仪表盘和搜索能力 |
Beats | 边缘代理,负责从数据源中轻量级采集日志并发送到Logstash或ES |
Beats:轻量级日志采集工具家族
Beats 是 Elastic 提供的一组用于不同场景的数据采集工具,常用的包括:
Beats 类型 | 功能描述 |
|---|---|
Filebeat | 读取日志文件,适合应用日志场景 |
Metricbeat | 采集系统、进程、磁盘、CPU 等指标数据 |
Packetbeat | 网络数据包监控工具,监控应用之间通信流量 |
Winlogbeat | 专门用于收集 Windows 事件日志 |
Auditbeat | 审计相关数据,如用户登录、文件更改等 |
Heartbeat | 用于服务存活状态的监测 |
ELK 系统的特点
Elastic Stack 作为日志平台,具备以下优势:
- 强大的日志采集能力:支持多种来源,几乎可以采集任何类型的数据;
- 稳定的传输机制:数据可安全传输至中心系统;
- 分布式架构:天生支持横向扩展,轻松应对海量日志;
- 强大的分析&可视化&告警能力:满足开发运维团队的深度分析需求。
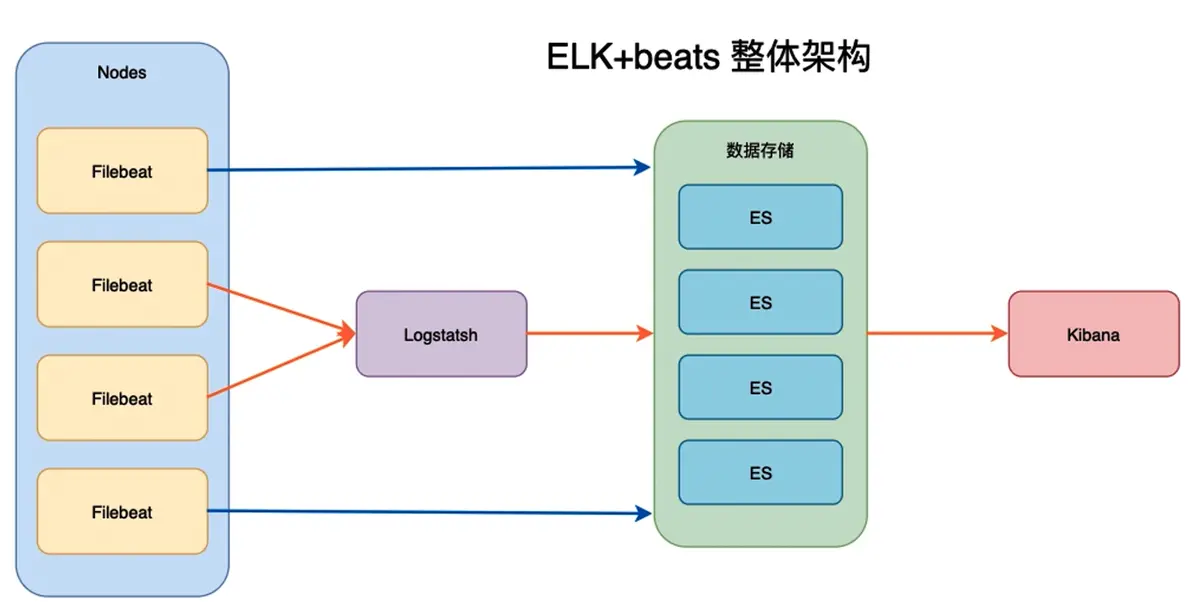
Filebeat 架构与工作原理详解
Filebeat 是最常用的日志采集工具,主要负责将日志文件数据发送到 Logstash 或 Elasticsearch。
Filebeat 的核心组件
- Prospector(勘测者):负责管理日志源,定位需要收集的文件;
- Harvester(收割机):负责读取具体日志文件内容,每个文件对应一个 Harvester。
Filebeat 工作流程
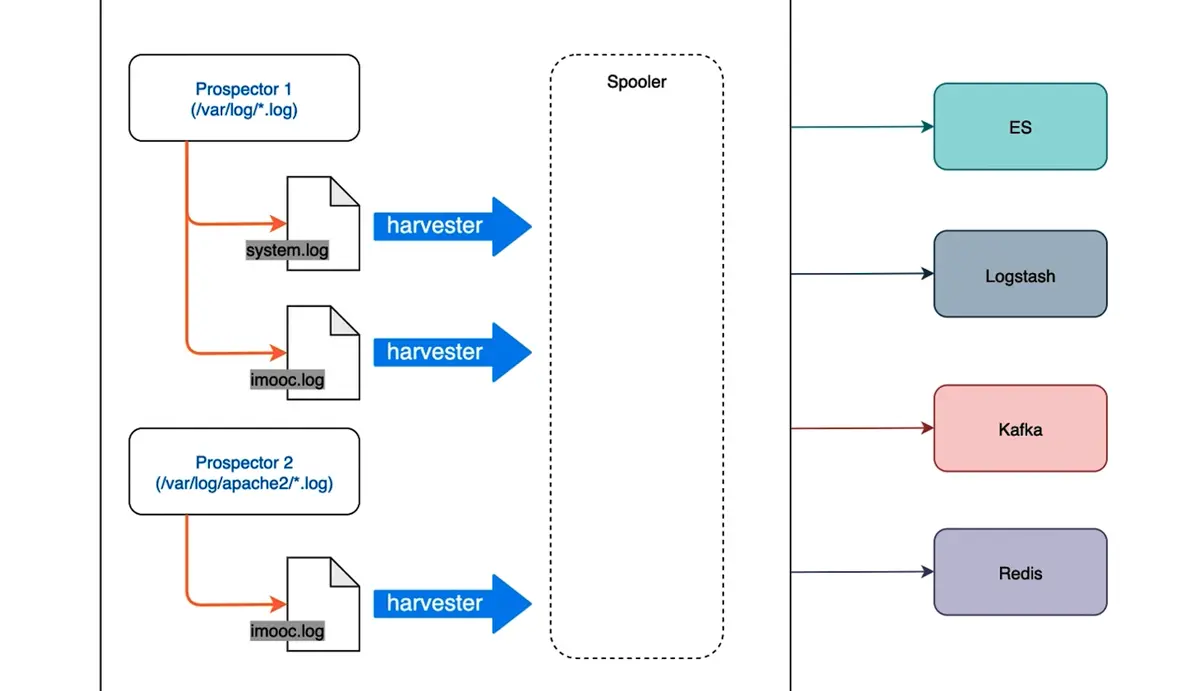
Filebeat 如何记录文件状态?
- 默认将状态信息记录在
/var/lib/filebeat/registry文件中; - 会记录“发送前的最后一行”,并在恢复时继续发送;
- 为每个文件生成唯一标识符,识别是否曾经采集过。
Filebeat 如何保证事件“至少被发送一次”?
- 每个事件的状态会本地保存;
- 未确认的事件会不断重试,直到成功;
- 即使在 Filebeat 重启后也会继续发送未确认数据。
这一机制保证了日志不会漏传,但有可能会重复(可通过后续处理规避)。
Filebeat 配置文件示例
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
output.logstash:
hosts: ["localhost:5044"]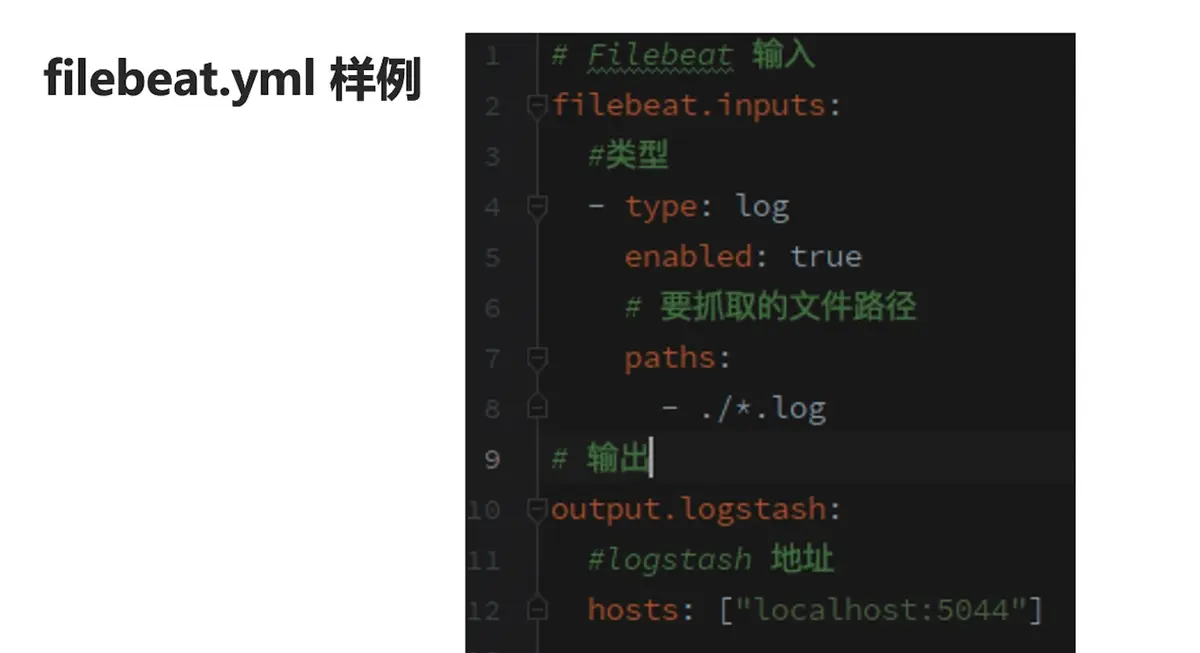
Filebeat 下载与启动
启动命令:
./filebeat -e -c filebeat.yml或使用 Docker 部署,参考:官方文档
Logstash 的三阶段处理流程
Logstash 的处理流程包括:
- Input:输入插件从各种数据源采集数据;
- Filter:使用插件对数据进行清洗、转换;
- Output:将清洗后的数据输出到目标系统(如 Elasticsearch、Kafka 等)。
常用的输入插件
file:从文件系统读取(支持类似tail -f);syslog:监听系统日志;beats:接收来自 Filebeat 的数据。
强大的 Filter 插件 —— Grok
grok 插件是日志结构化处理的核心,语法如下:
%{SYNTAX:SEMANTIC}举例:
%{LOGLEVEL:log_level} %{GREEDYDATA:log_message}它会将日志分解为结构化字段,非常适合后续索引和搜索。
输出插件
- 支持输出至 Elasticsearch、Kafka、Redis 等目标系统。
Kibana 可视化配置步骤
- 浏览器访问
http://localhost:5601/进入 kibana 页面,点击左上角的 Discover
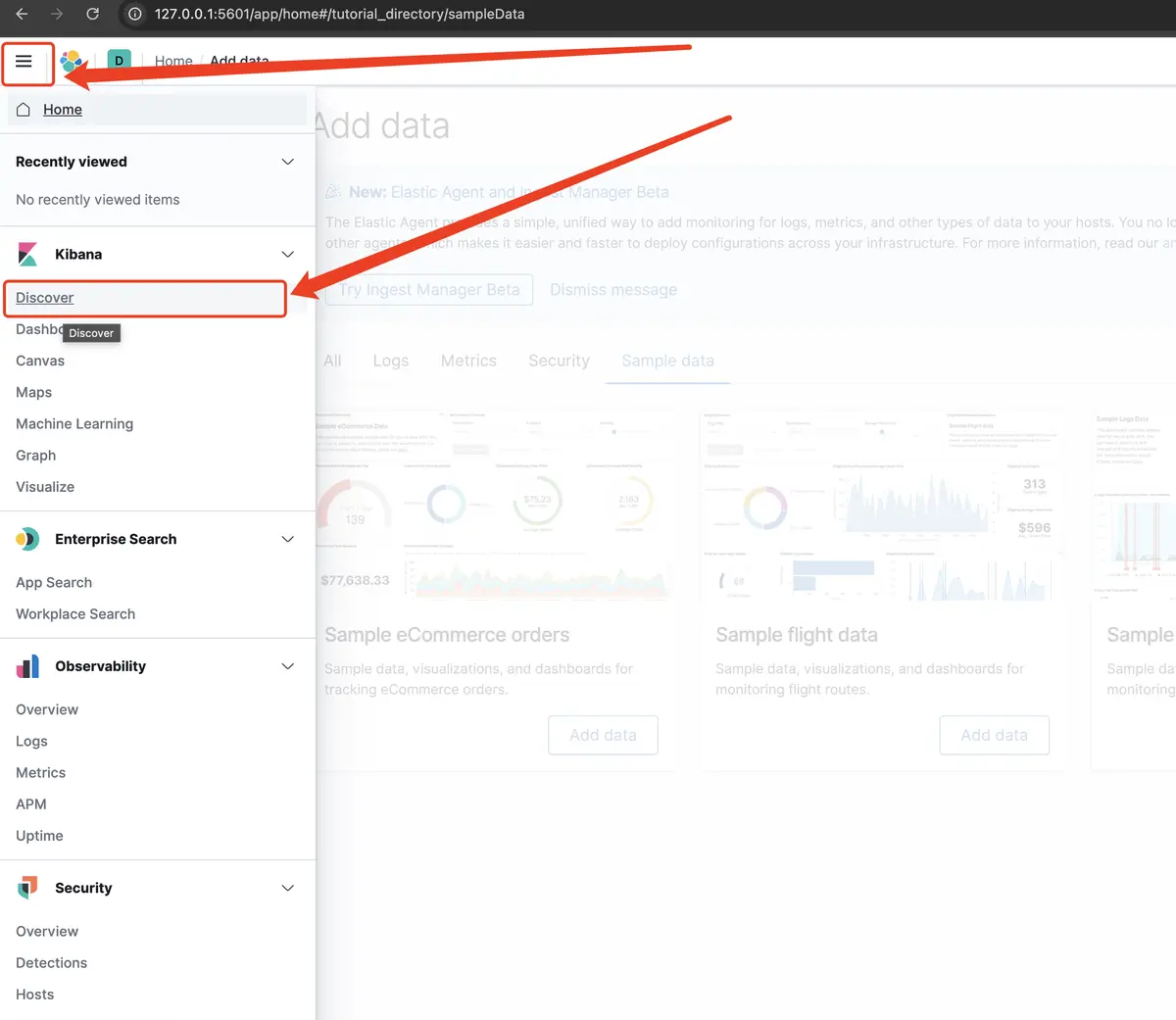
- 然后点击
Create index pattern
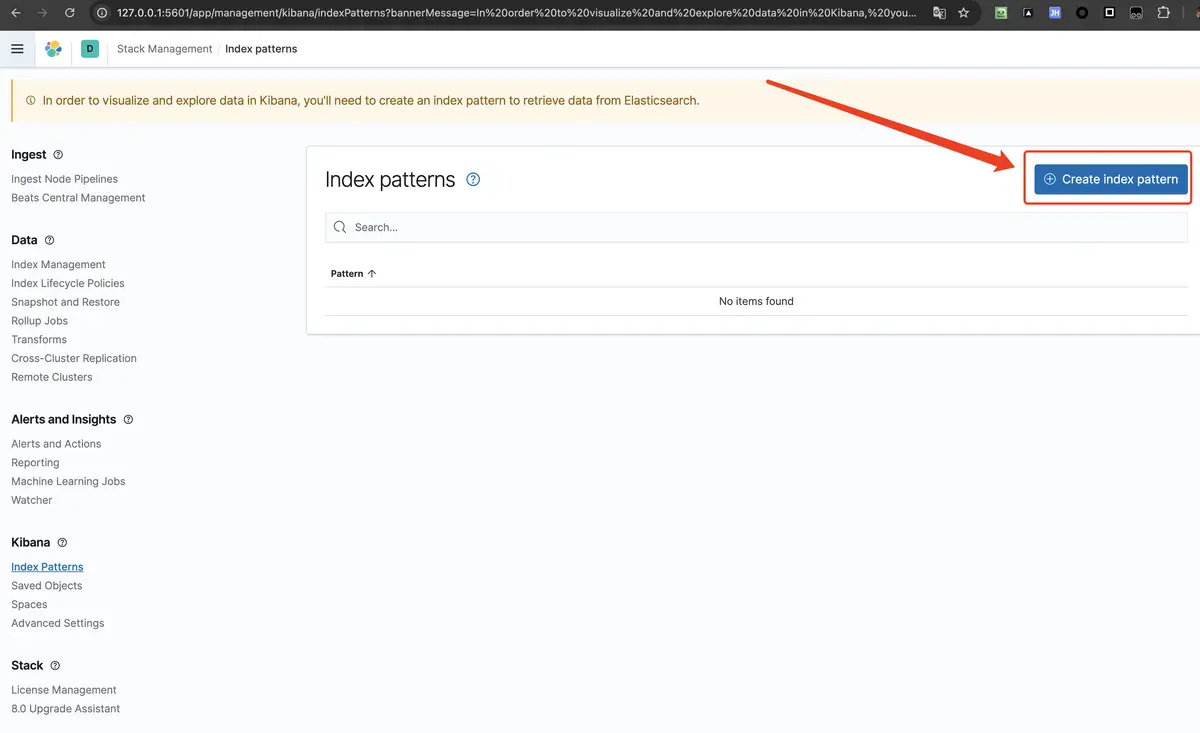
- 我们可以看到会存在我们在 logstash 中配置的 index,然后填写 index pattern,(当然需要与 logstash 中的索引要有关系)点击
Next step
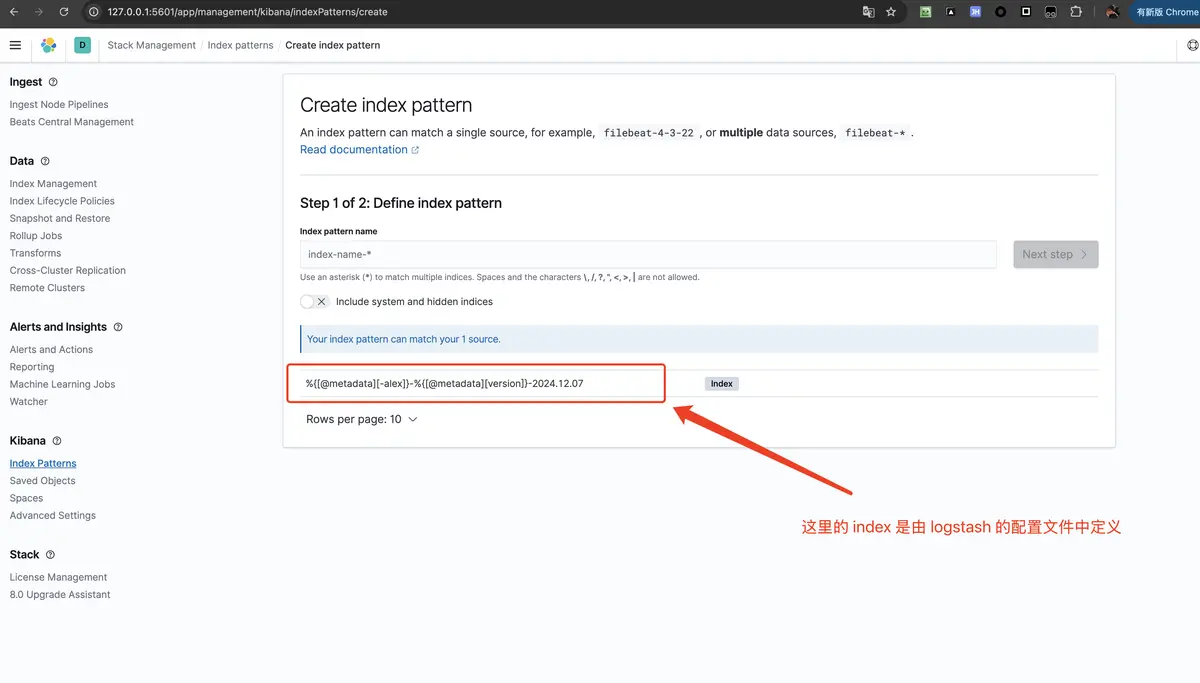
填写索引匹配规则
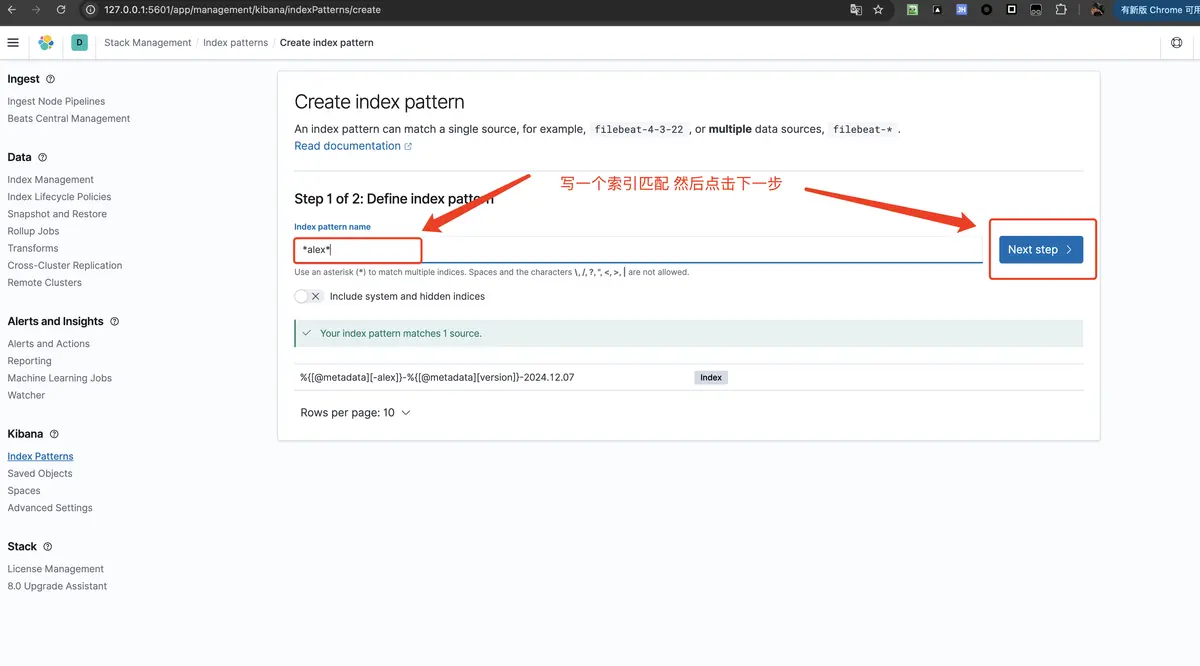
- 选择时间字段,然后点击
Create index pattern
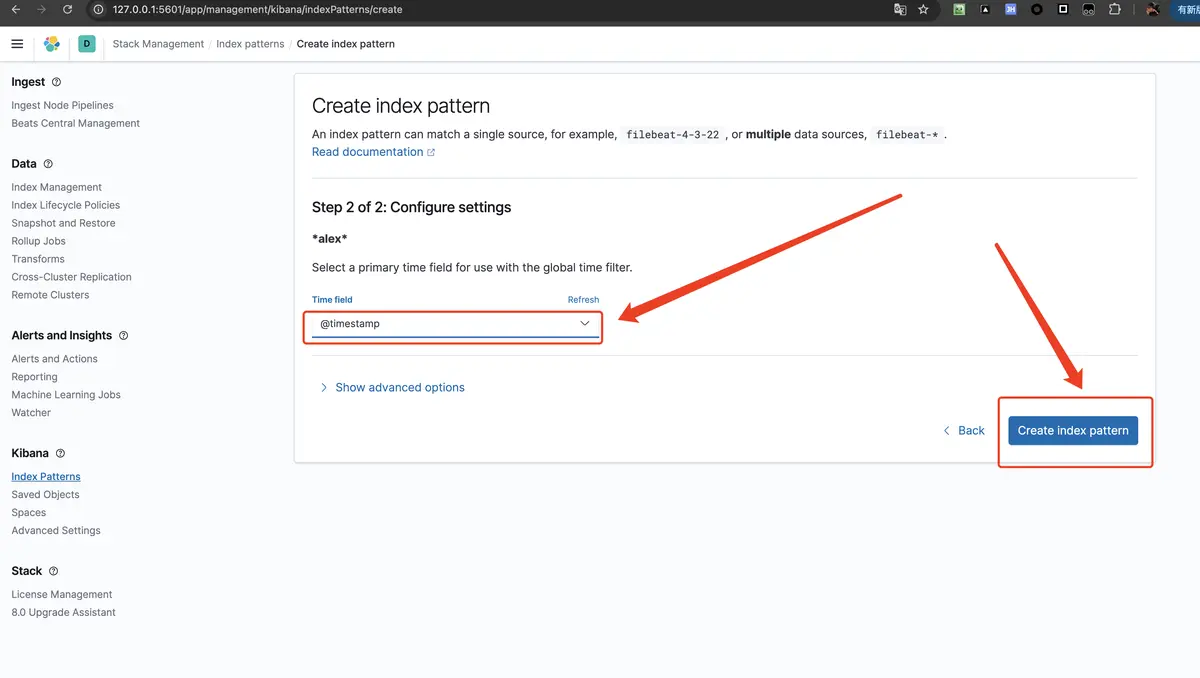
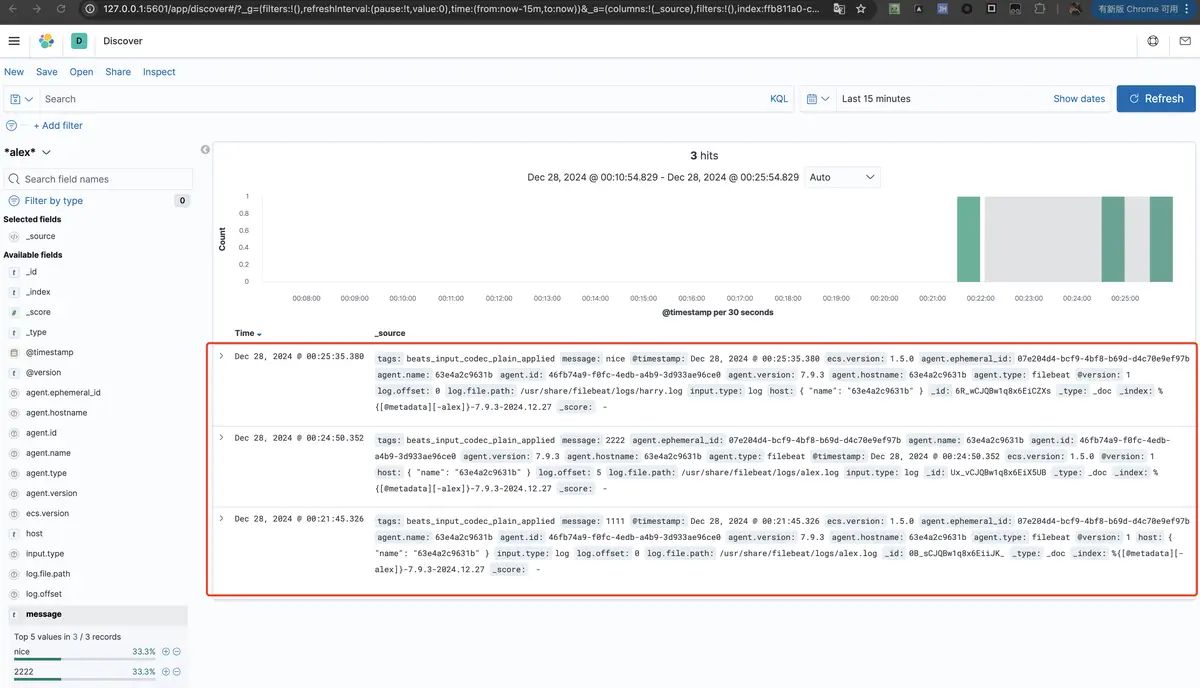
- 然后重新回到 Discover 页面,就可以看到我们导入的内容了
搭建
这里,我提供了 elk 的 docker-compose.yml 示例,以供你参考。如果你感兴趣,可以访问 https://github.com/pudongping/polyglot-script-box/tree/master/elk 获取完整的 docker-compose 配置信息。
services:
elasticsearch:
image: elasticsearch:7.9.3
ports:
- "9200:9200"
- "9300:9300"
volumes:
#配置目录
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
#数据目录
- ./elasticsearch/data:/usr/share/elasticsearch/data
#插件目录
- ./elasticsearch/plugins:/usr/share/elasticsearch/plugins
environment:
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
# 设置为单节点(非集群模式)
discovery.type: single-node
# 账号
#ELASTIC_USERNAME: ""
# 密码
#ELASTIC_PASSWORD: ""
network.publish_host: _eth0_
networks:
- elk-network
logstash:
image: logstash:7.9.3
ports:
- "5044:5044"
- "5001:5000"
- "9600:9600"
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml
- ./logstash/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
environment:
LS_JAVA_OPTS: "-Xms512m -Xmx512m"
networks:
- elk-network
kibana:
image: kibana:7.9.3
ports:
- "5601:5601"
volumes:
- ./kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
environment:
#ELASTICSEARCH_USERNAME: ""
#ELASTICSEARCH_PASSWORD: ""
ELASTICSEARCH_HOSTS: "http://elasticsearch:9200"
networks:
- elk-network
# 网络配置
networks:
elk-network: # 定义一个名为 elk-network 的网络
driver: bridge实践建议与总结
Elastic Stack 在日志收集、集中分析和可视化上提供了一套非常强大的方案,适合分布式系统中的复杂场景。我的经验是:
- 尽可能将日志标准化、结构化,方便后续检索和告警;
- 合理利用 Filebeat 的模块功能,节省重复造轮子的成本;
- Grok 表达式需谨慎优化,性能瓶颈常见于过滤阶段;
- 初次部署推荐使用 Docker Compose 管理,更快速上手。
通过这篇文章,相信你已经掌握了 ELK 的核心组件、工作流程及实战部署方式。如果你正面临日志混乱、排查困难的问题,不妨试试 ELK,它或许正是你理想的解决方案!
如需更进一步的使用指南或实战部署脚本,也欢迎留言交流~
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
