triton 在模型推理中的应用
原创
triton 在模型推理中的应用
原创
liddytang
发布于 2025-06-20 11:58:11
发布于 2025-06-20 11:58:11
结合最近的实践经验,抛砖引玉浅聊triron在模型推理中的应用,主要从triton的基本原理、应用、关键参数配置等方面阐述。
一、基本原理
原理
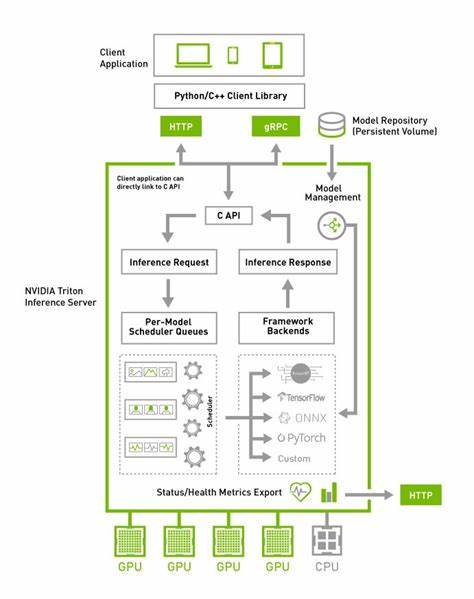
Triton 是 OpenAI 开发的一种编程语言和编译器,旨在简化 GPU 编程,特别是针对深度学习和高性能计算(HPC)中的自定义内核优化。它的设计目标是让没有 CUDA 经验的开发者也能高效编写高性能的 GPU 代码。以下是 Triton 的核心原理和关键特性:
1. 核心设计思想
- 简化 GPU 编程: Triton 抽象了 CUDA 的复杂性(如线程块、共享内存同步等),提供类似 Python 的语法,让开发者专注于计算逻辑而非硬件细节。
- 基于“块编程”模型: 程序以多维块(Tile)为单位操作数据,自动处理数据分块、并行化和内存管理,类似 CUDA 的线程层次,但更高级。
2. 关键原理与特性
(1)分块计算(Tiled Operations)
- 块(Tile)是 Triton 的基本执行单元,表示一个多维数据块(如 128x128 矩阵)。
- 编译器自动将操作映射到 GPU 的线程网格(Grid)和线程块(Block),无需手动管理线程调度。
(2)内存层次抽象
- 分级内存访问:
Triton 显式区分不同内存层级(如全局内存、共享内存、寄存器),通过修饰符(如
@triton.jit)提示编译器优化数据移动。
(3)自动并行化
- 程序ID与网格:
通过
triton.program_id(axis)标记并行维度,编译器自动生成并行执行的线程网格(类似 CUDA 的blockIdx.x)。
(4)融合操作(Operator Fusion)
- Triton 支持将多个逐元素操作(如矩阵乘+激活函数)融合为单个内核,减少内存往返开销。
(5)混合精度计算
- 原生支持 FP16/BF16/FP32 等数据类型,自动优化精度与性能的权衡。
优势
- 支持所有训练和推理框架:使用 Triton,部署基于任何主流框架的 AI 模型,包括 TensorFlow,PyTorch,Python,ONNX,NVIDIA® TensorRT™、RAPIDS™ cuML,XGBoost,scikit-learn RandomForest,OpenVINO,C++ 自定义框架等。
- 可在任何平台上实现高性能推理:借助动态批处理、并发执行、最佳模型配置,音视频串流输入支持,最大限度地提升吞吐量和资源利用率。Triton 支持所有 NVIDIA GPU,x86 和 Arm® 架构 CPU 以及 AWS Inferentia。
二、应用 & 特性
triton是一种支持单模型 、 多模型的云原生模型服务化框架,多模型、多框架(PyTorch/TensorFlow/ONNX等)并发推理,提供动态批处理(Dynamic Batching)、模型流水线,适用于云上高并发推理服务(如推荐系统、AIGC、自动驾驶)。
在Triton Inference Server中,Multi-Model(多模型)、Ensemble Model(集成模型)和BLS(Business Logic Scripting)Model是三种不同的模型管理方式,分别用于处理多模型部署、模型组合推理和自定义业务逻辑。
1. Multi-Model(多模型管理)
功能
- 同时加载和管理多个独立模型,支持不同框架(如 PyTorch、TensorRT、ONNX 等)。
- 各模型可独立配置硬件资源(GPU/CPU)、版本和调度策略。
配置方式
- 通过 模型仓库(Model Repository) 的目录结构管理:
model_repository/
├── model_A/ # 模型A
│ ├── 1/ # 版本1
│ │ └── model.onnx
│ └── config.pbtxt # 模型配置
├── model_B/ # 模型B
│ ├── 1/
│ │ └── model.plan # TensorRT 引擎
│ └── config.pbtxt关键配置项(config.pbtxt):
name: "model_A"
platform: "onnxruntime_onnx"
max_batch_size: 8
instance_group { count: 2 kind: KIND_GPU } # 指定GPU实例数使用场景
- 需要同时部署多个独立模型(如分类模型 + 检测模型)。
- 不同模型可能由不同团队开发,需独立更新。
- 资源隔离:对性能敏感的模型单独部署(Multi-Model),避免被其他模型拖累。
2. Ensemble Model(集成模型)
功能
- 将多个模型组合成一个逻辑上的“超级模型”,自动处理模型间的输入/输出传递。
- 避免客户端多次调用,减少网络开销(如预处理→模型A→模型B→后处理)。
配置方式
- 定义
config.pbtxt,指定数据流(DAG):
name: "ensemble_model"
platform: "ensemble"
input [{ name: "input", data_type: TYPE_FP32, dims: [224,224,3] }]
output [{ name: "output", data_type: TYPE_FP32, dims: [10] }]
ensemble_scheduling {
step [
{
model_name: "preprocess_model",
model_version: -1, # 最新版本
input_map { key: "raw_input" value: "input" },
output_map { key: "processed_data" value: "preprocessed" }
},
{
model_name: "inference_model",
input_map { key: "data" value: "preprocessed" },
output_map { key: "prediction" value: "output" }
}
]
}使用场景
- 多阶段任务(如图像预处理→模型推理→后处理)。
- 模型链式调用(如BERT输出→分类头)。
- 如果模型间是简单的线性流水线,用 Ensemble 更高效(无Python开销)。
3. BLS (Business Logic Scripting) Model
功能
- 通过 Python 脚本 实现自定义业务逻辑(如条件分支、动态模型调用)。
- 直接调用其他模型(类似 Ensemble),但支持更灵活的代码控制。
配置方式
- 使用
Python Backend,配置config.pbtxt:
name: "bls_model"
backend: "python"
input [{ name: "input", data_type: TYPE_STRING }]
output [{ name: "output", data_type: TYPE_FP32 }]backend模型下的 Model.py 示例
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
def execute(self, requests):
responses = []
for request in requests:
# 1. 获取输入
input = pb_utils.get_input_tensor_by_name(request, "input").as_numpy()
# 2. 动态调用其他模型
infer_request = pb_utils.InferenceRequest(
model_name="inference_model",
inputs=[pb_utils.Tensor("input", input)]
)
infer_response = infer_request.exec()
output = pb_utils.get_output_tensor_by_name(infer_response, "output")
# 3. 自定义逻辑(如过滤结果)
if output.as_numpy().max() < 0.5:
output = np.zeros_like(output)
responses.append(pb_utils.InferenceResponse([output]))
return responses使用场景
- 需要复杂逻辑(如动态模型选择、条件分支)。
- 与其他服务交互(如数据库查询后处理)。需要动态分支(如A/B测试)或外部服务调用时,选择 BLS。
三、triton 中实际应用性能关键参数
参数 | 说明 | 示例值 |
|---|---|---|
max_batch_size | 最大批处理大小(动态批处理需启用) | 8 |
max_sequence_length | 最大序列长度(影响 KV Cache 分配) | 4096 |
beam_width | 束搜索宽度(生成任务) | 1 或 4 |
preferred_batch_size | 优化批处理粒度(如 [4, 8, 16]) | [4, 8] |
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号