理解Linux文件系统——通过磁盘结构


前言
在上一篇博客中,我们讨论了进程与被打开文件之间的关系,那没被打开的文件呢?
没被打开的文件就需要文件系统来管理了。
需要明确的是文件系统不是指Linux本身,而是Linux操作系统中用于管理和组织文件的一种机制。

一、磁盘
想要搞清楚文件系统,咱们还是有必要了解一下磁盘的基本构造,毕竟文件系统是建立在磁盘之上的,没有磁盘也就谈不上文件操作。
目前在个人电脑上我们很难见到磁盘了,但在企业端,磁盘凭借着高性价比依旧是存储的主流。
1.磁盘的物理结构
①磁盘是由磁头和盘面两部份组成,一片磁盘的上下两面都可以存放数据。
②磁头和盘面是没有接触的(因此磁盘要防止抖动),每一个磁面都配有一个磁头。
③通过电机驱动,磁盘是在不停旋转的,磁头在不停摆动。
例如曾经DVD中的光盘在播放时也是在不停旋转,磁头摆动。不同的是光盘是单面的。
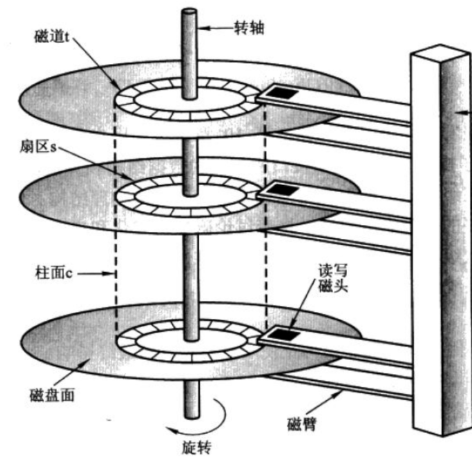
2.磁盘的存储结构
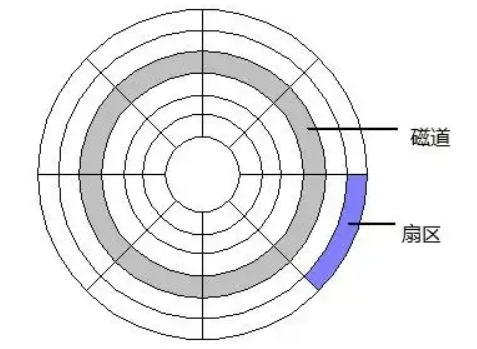
1)磁道:同心的圆环,每一个圆环就是一个磁道。
2)扇区:被扇形切割的圆环,每个圆环弧段就是一个扇区。
扇区是磁盘寻址的基本单位,每个扇区都有着512Byte空间。
通过控制材料密度,实现不同大小的扇区存储同样容量的数据。为什么这样做?每一段扇区存储大小相同,方便后续存储地址的划分和编址。(现已有技术可使不同大小的扇区有不同的存储容量,以实现单片存储最大化)
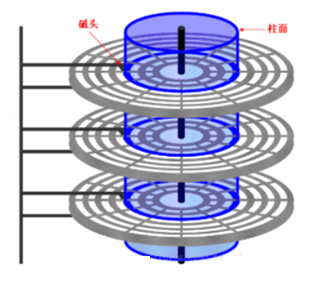
3)柱面:将一摞磁盘的同心磁道宏观上看作一个柱体,按磁道的的半径不同,一摞磁盘中柱面的个数与磁道个数相等。故柱面的本质就是磁道。
为什么要有柱面这个概念?
现实中磁盘通常是一摞存放的,磁盘通过电机驱动不停旋转,而磁头也是通过电机在来回抖动。一摞磁盘上的磁头都是通过同一个电机驱动,所以每个磁头都是共进退,通过引入柱面来方便实际描述数据在哪里,比如数据在哪个柱面的哪个盘面的哪个扇区。
在磁盘中定位扇区——CHS定位法
那么如何在磁盘中定位任何一个扇区?

柱面号(Cylinder)、磁头号(Head)和扇区号(Sector),上述这种采取硬件的基本定位方式叫做:CHS定位法
3.磁盘的逻辑结构
1)磁盘的线性结构
不知到在看的读者有没有接触过卷尺,如下图:

卷尺在平时存放时里面的钢片是卷起来的,类似螺旋的卷状。使用时拉拽钢片,拉出的钢片却是笔直的线性的。
磁盘也是一样,将磁盘抽象成线性结构,从逻辑上把整个磁盘看作一个数组sector arr [n];其中每一个元素就对应一个扇区。这样说十分抽象,下图较为清晰的展现这一过程。
我们以两片,四面,每面三圈磁道的磁盘为例,假设将该磁盘强行拉扯成线性结构:

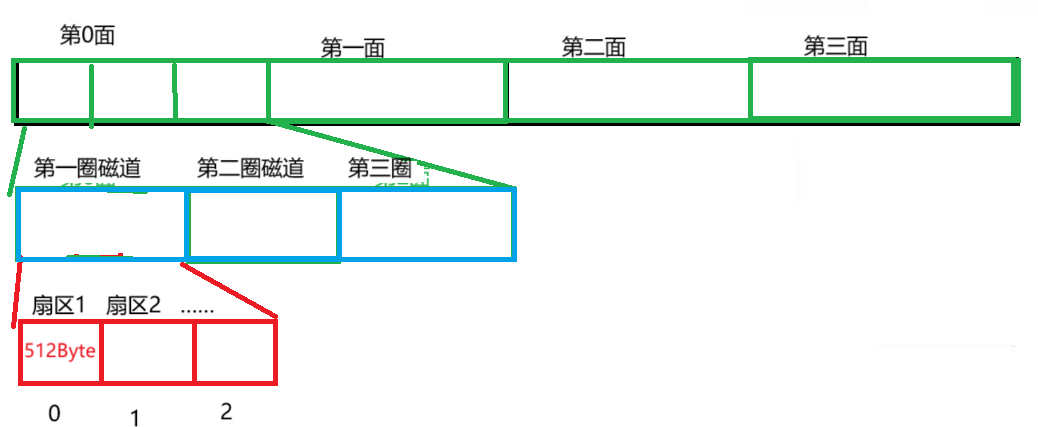
通过如上述抽象操作,重点是我们便可以从对磁盘的管理转化成对数组进行管理!
2)定位扇区——线性
将磁盘线性化后,显然只要知道了扇区的下标就可以定位一个扇区,这种下标称为LAB地址。
假如有一块磁盘共有4面,一面10圈磁道,一圈磁道100个扇区。已知每个扇区512Byte。
那么4 *10 *100 *512 == 该磁盘的总容量( Byte),4 *10 *100 ==线性化后的下标范围
假设这里有个LBA地址123号位置:
那么有123 /(10*100)= 0 ——位于0号磁盘;(用下标除以一面有的逻辑地址)
123 / 100 = 1 —— 位于1号磁道;
123 % 100 = 23 —— 23号扇区
那么综上述步骤,我们可以得出123号地址在该磁盘的第0面,第1号磁道的第23号扇区。
为什么OS要将磁盘抽象成线性结构呢,直接用CHS定位法不行吗
操作系统将磁盘线性化出于两个因素:
①便于管理磁盘,方便编址划分;
②让OS的代码与硬件解耦!
自计算机诞生以来,储存技术和存储材料也是不断更新换代,OS通过对硬件线性的抽象可免于受到来自硬件变化的影响。
倘若未来又出现个什么新型存储容器,操作系统只需略微变更一点代码便可使用新存储容器,无需重新设计一套IO方案。
二、文件系统
既然OS能找到扇区了,那自然可以对扇区进行数据IO了,但整个磁盘小的也有几十G,大的几个T,而一个扇区大小才512Byte,空间太大,数组太大难以管理。
操作系统采用了分而治之的思想,如将100G的磁盘分成几个区,再把每个区又分成几个组,只要把这个基本单元-存储组给管理好再把方法复制粘贴到其他组,那就算完成了对整个磁盘的管理。

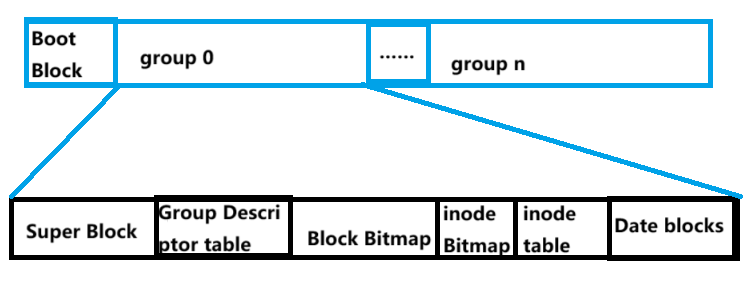
在介绍存储组之前,我们认识一个新的“结构体”——inode
什么是inode
1.概念
在Linux文件系统中,inode(index node)是操作系统用于管理文件系统对象的元数据容器。
在Linux一切皆文件的设计思想下,每个文件(包括目录)都对应唯一的 inode,这些存储在磁盘的 inode 表中(即下文的inode table)。当文件系统格式化时,会预先分配固定数量的 inode(可通过 df -i 查看剩余数量)。
2.作用
当用户访问某个文件时,OS会将磁盘中的 inode 加载到内存中,形成 inode 结构体(虚拟文件系统层),用于统一管理不同文件的差异。
3.inode中有什么
inode存储着文件的各种属性信息,如文件大小、文件拥有者 所属组等
// 简化的内核 inode 结构体定义(linux/fs.h)
struct inode {
umode_t i_mode; // 文件类型和权限(如 0755)
uid_t i_uid; // 所有者用户ID
gid_t i_gid; // 所有者组ID
loff_t i_size; // 文件大小(字节)
struct timespec i_atime; // 最后访问时间
struct timespec i_mtime; // 最后修改时间
struct timespec i_ctime; // inode变更时间
unsigned long i_ino; // inode编号(唯一标识)
struct block_device *i_bdev; // 块设备指针(针对设备文件)
// 数据块指针相关(不同文件系统实现不同):
union {
struct ext4_inode_info ext4_i; // ext4 文件系统的扩展数据
struct xfs_inode xfs_i; // XFS 文件系统的扩展数据
// ... 其他文件系统的特定结构
};
// 其他重要成员:
unsigned int i_nlink; // 硬链接计数
dev_t i_rdev; // 设备号(字符/块设备)
struct inode_operations *i_op; // inode操作函数指针(如mkdir/unlink)
struct super_block *i_sb; // 所属超级块
};注意:
inode虽然存储着文件的各种属性,当唯独没有该文件的文件名。
文件内容:文件内容存储在数据块(即下面介绍的date blocks)中,inode 仅通过指针记录数据块位置。
下面依次介绍上面图中的各个组或者区。
1.特殊分区Boot Block
Boot Block 即启动块:

2.存储组
Super Block 超级块对象

inode Table

inode 是文件系统管理的最小元数据单元,inode table 是这些单元的全局存储池。
即inode存储在inode table中。
Data blocks

inode Bitmap

Block Bitmap

Group Descriptor Table

3.文件查找
struct inode { int id; mode_t mode; uid; gid; size; …… int blocks[15]; }
首先我们需要认识inode中两个重要的成员变量:
①编号id
这个id是文件系统内唯一标识一个inode的整数的编号。
每个文件或目录的属性(如权限、时间戳、数据块指针等)存储在对应的inode中,并通过inodeID进行索引。

②int blocks[15]
在blocks数组中记录着该文件的数据对应在Date block中的地址。各个操作系统中blocks数组的大小不同,这里以Linux中的文件操作系统为例。

假设现在操作系统有着某文件inode中的id,若想要找到某文件应该怎么做?
属性
操作系统首先是通过inode Bitmap查看该inode是否存在(是否被使用),若存在则再通过inode Table找到inode并再次核对id是否正确,若上述两项都无误,那该inode中记录的文件属性即目标文件的文件属性。
内容
紧接着在上述属性的步骤后,操作系统通过inode的成员变量int blocks【15】中记录的映射关系前往Date block中寻找。
四、一些问题
1.通过文件名就能打开文件的原因
啊,上面叽里呱啦说了一大堆,可是我们在Linux下使用文件时也不是用的什么id啊inode啊,我们用的是路径+文件名了,系统就打开这个文件了啊。
在Linux中目录也是文件,读者有没有想过目录这种特殊文件他的属性和内容是什么呢?
属性都还好说,无非是目录的权限、大小之类的,可目录的内容呢?
目录的内容,即目录这个文件在磁盘中的Date block中存储的的是:该目录中的文件的文件名,以及该文件对应的inode地址等信息。所以,我们在Linux中打开某文件时,本质是通过该文件所处的目录实现的。
打开一个文件的流程:
通过目录路径解析得目录的id——>
通过此id找到目录的inode——>
通过目录inode中blocks【】数组,访问该目录下的文件的文件名和该文件的inode——>
再通过用户提供的文件名比对该目录下是否有该文件,若有则通过该文件的inode找到并访问该文件内容,若无则报错。

2.目录权限解析

3.如何创建一个新文件
①通过创建文件的路径确定磁盘分区;②在该分区中通过inode Bitmap找到一个未使用的inode; ③将新建文件的属性填进去;④若有内容再在bolcks中找到对应的数据块,再将对应block Bitmap中比特位初始化;⑤上述就绪后,再返回inode信息和文件名给当前目录。
4.如何删除一个文件,被删除的文件后能恢复吗

总结
本文首先花费大量篇幅介绍硬件磁盘,这是理解抽象的文件系统所必要的。之后通过阐述文件系统是如何通过分而治之的思想,管理存储空间庞大的磁盘。最后解释了在Linux中通过文件名+路径就可以打开一个文件的原因,以及目录权限的解析和删除文件的方式。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号