内容更新----CNV推断之inferCNVpy
原创
内容更新----CNV推断之inferCNVpy
原创
追风少年i
发布于 2025-04-26 15:39:57
发布于 2025-04-26 15:39:57
代码可运行
运行总次数:0
代码可运行
作者,Evil Genius
课程已经临近了,本次系列课程跟2024年一样,单细胞空间部分采用全python流程,而inferCNV对应的python流程就是inferCNVpy。
官网在https://infercnvpy.readthedocs.io/en/latest/。
其中有个小的疑问,那就是官网有如下信息
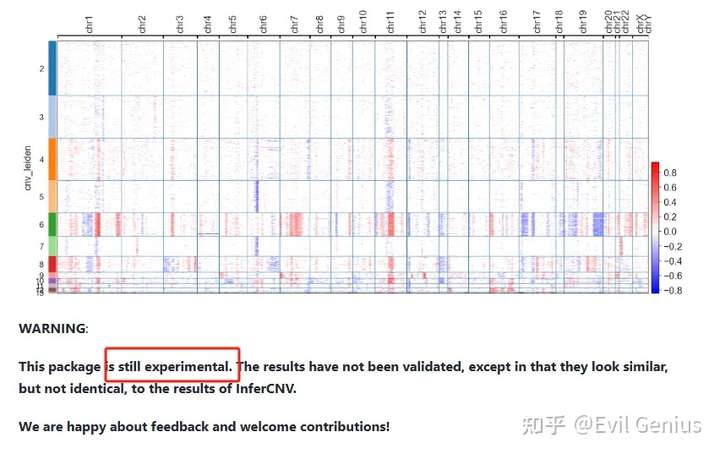
但是我们可不可以用呢?
让高分文献告诉我们答案,我虽然无法看完所有的单细胞空间文献,但也看的算多的,目前收集到2篇高分文献采用了inferCNVpy,当然应该不止2篇。
第一篇

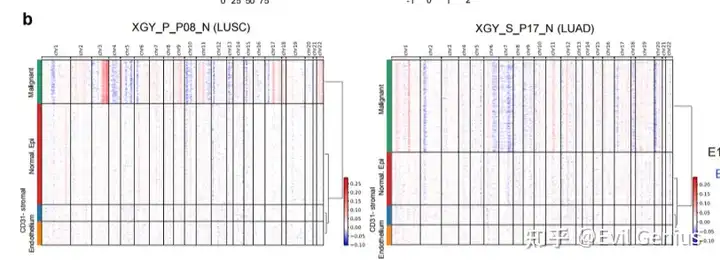

第二篇

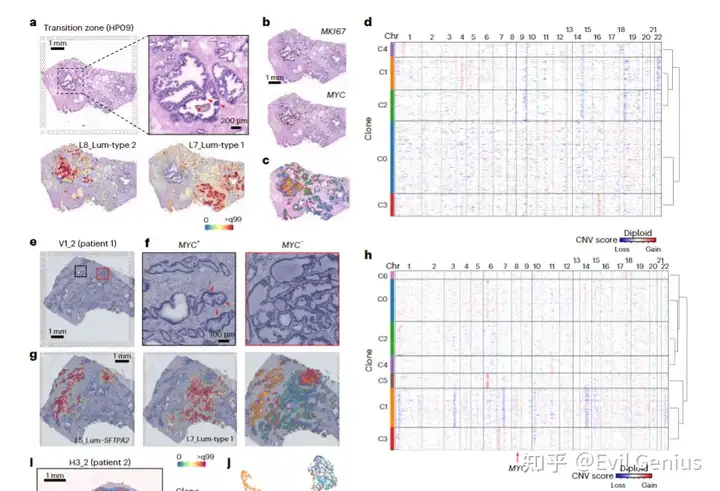

那么我想可以说明,inferCNVpy完全是可用的,我们来把脚本进行一下完全的封装。
其中最关键的需要基因坐标信息
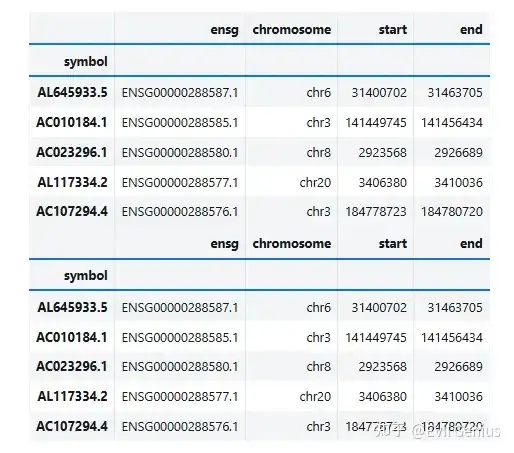
我们的脚本也要写的越来越规范化了,上课要用的。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
####zhaoyunfei
####20240321
import argparse
import os
import infercnvpy as cnv
import scanpy as sc
from matplotlib import pyplot as plt
# 创建参数解析器
parser = argparse.ArgumentParser(
description="运行inferCNVpy分析单细胞CNV",
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
# 添加参数
parser.add_argument("-i", "--input_file", required=True, help="输入h5ad文件路径")
parser.add_argument("-c", "--cell_type_col", required=True, help="细胞类型所在列名")
parser.add_argument("-r", "--reference_types", required=True, nargs="+", help="参考细胞类型列表")
parser.add_argument("-o", "--output_dir", default="infercnv_results", help="输出目录")
parser.add_argument("-w", "--window_size", type=int, default=100, help="基因组窗口大小")
parser.add_argument("--resolution", type=float, default=1.0, help="聚类分辨率(值越大聚类越多)")
# 解析参数
args = parser.parse_args()
# 创建输出目录
os.makedirs(args.output_dir, exist_ok=True)
# 读取数据
print(f"读取输入文件: {args.input_file}")
adata = sc.read_h5ad(args.input_file)
# 验证细胞类型列
if args.cell_type_col not in adata.obs.columns:
raise ValueError(f"列 '{args.cell_type_col}' 不存在于 adata.obs")
# 验证参考细胞类型
missing_refs = [rt for rt in args.reference_types if rt not in adata.obs[args.cell_type_col].unique()]
if missing_refs:
raise ValueError(f"参考类型 {missing_refs} 不存在于列 '{args.cell_type_col}'")
# 运行inferCNV
print("正在运行inferCNV分析...")
cnv.tl.infercnv(
adata,
reference_key=args.cell_type_col,
reference_cat=args.reference_types,
window_size=args.window_size,
step=args.window_size,
out_dir=args.output_dir
)
# 计算CNV分数
cnv.tl.cnv_score(adata)
# CNV聚类
print(f"使用分辨率 {args.resolution} 进行CNV聚类...")
cnv.tl.pca(adata)
cnv.pp.neighbors(adata)
cnv.tl.leiden(adata, key_added="cnv_leiden", resolution=args.resolution)
# 输出聚类信息
n_clusters = adata.obs["cnv_leiden"].nunique()
print(f"在分辨率 {args.resolution} 下获得 {n_clusters} 个CNV聚类")
# 可视化
print("生成可视化图表...")
sc.pl.umap(adata, color=["cnv_leiden", args.cell_type_col],
save="_cnv_clusters.png", show=False, wspace=0.5)
cnv.pl.chromosome_heatmap(adata, groupby="cnv_leiden",
save="_cnv_heatmap.png", show=False)
# 保存聚类结果
cluster_file = os.path.join(args.output_dir, "cnv_clusters.tsv")
adata.obs[["cnv_leiden"]].to_csv(cluster_file, sep="\t")
print(f"聚类结果已保存至 {cluster_file}")
# 保存完整结果
output_file = os.path.join(args.output_dir, "infercnv_results.h5ad")
adata.write(output_file)
print(f"完整结果已保存至 {output_file}")
print("CNV分析完成!")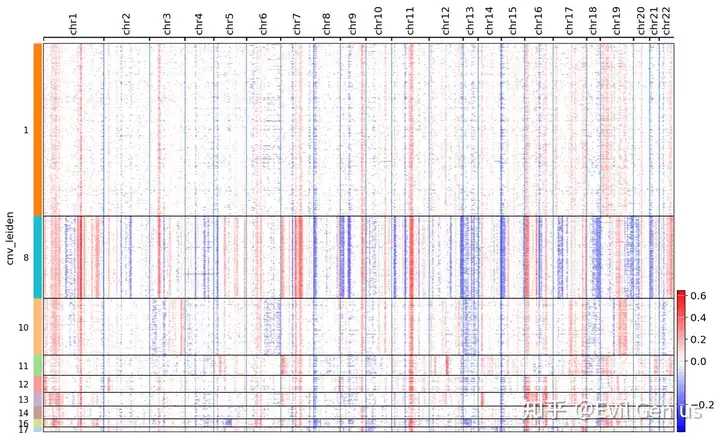
生活很好,有你更好
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
