【AGI-Eval趣味测试 】用 7 道超绕算术陷阱题,测测你和 AI 谁更会算
原创
【AGI-Eval趣味测试 】用 7 道超绕算术陷阱题,测测你和 AI 谁更会算
原创
AGI-Eval评测社区
发布于 2025-04-14 15:32:29
发布于 2025-04-14 15:32:29
在大模型飞速发展的今天,你以为 AI 是数学天才?那可不一定!最近刷到很多有趣的测试题,今天,我们就来用 7 道超绕的算术陷阱题考考 AI,据说这些题目连 AI 在初次 “审题” 时都得小心翼翼,稍不留意就会掉入思维的 “陷阱”,来个大翻车。 快来试试,测测你和 AI 谁更会“算”!👇
此次主要测试了7道题,测试目标为AI在数学陷阱题目上的表现。测试对象为推理系头部模型deepseek-r1、gpt-4o,对话系头部模型d豆包1.5 pro、Qwen-2.5。
prompt 1:我有六个鸡蛋,煮了两个,煎了两个,吃了两个,还剩几个?
模型1:gpt-4o

没有意识到题目中的“陷阱”,将煮鸡蛋、煎鸡蛋算作已经消失的鸡蛋,认为还剩0个鸡蛋,没有人类的思维模式。
模型2:deepseek-r1

录屏2025-03-20 14.08.18.mov
25.75MB
意识到了题目中的“陷阱”,认为煮鸡蛋和煎鸡蛋数量都未减少,只有吃的鸡蛋算是消耗,认为还剩余4个鸡蛋。并在思考过程中考虑了吃的鸡蛋为煎鸡蛋或者煮鸡蛋的情况。
模型3:豆包1.5 pro
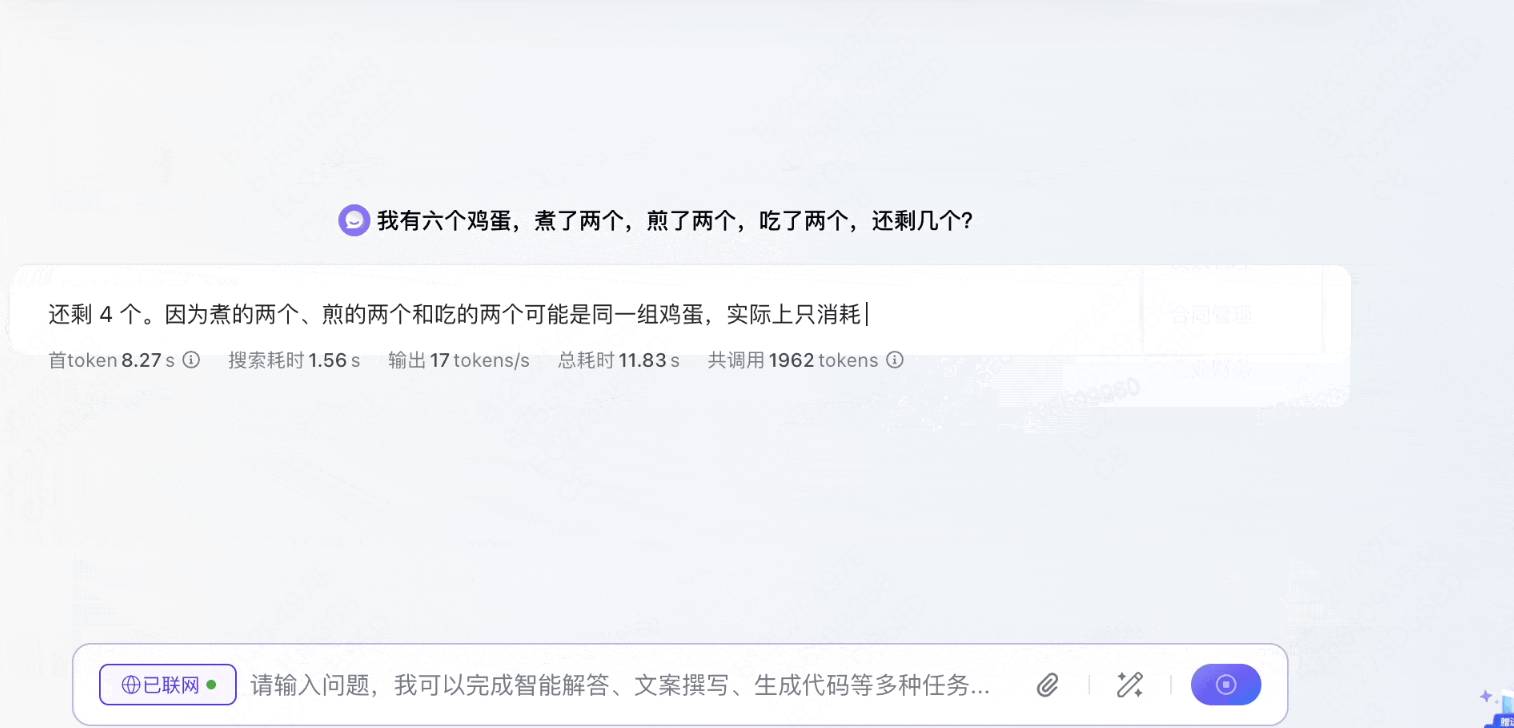
录屏2025-03-20 14.34.12.mov
8.29MB
认为煮的两个、煎的两个和吃的两个可能是同一组鸡蛋,实际上只消耗了 2 个鸡蛋,还剩下 4 个鸡蛋。
模型4: Qwen-2.5
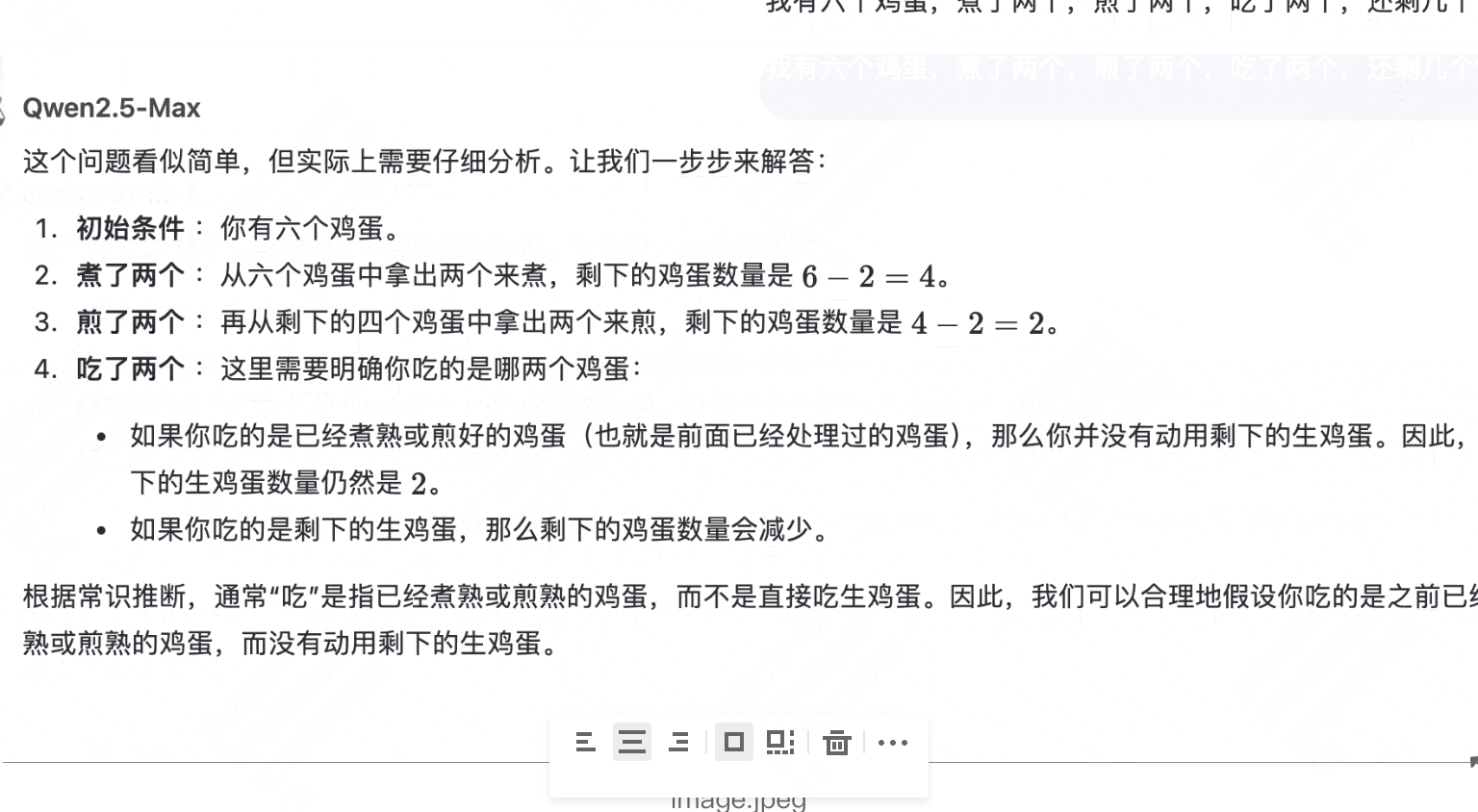
录屏2025-03-20 14.27.19.mov
2.90MB
该模型学会区分了生鸡蛋与熟鸡蛋,认为“吃”是指已经煮熟或煎熟的鸡蛋,而不是直接吃生鸡蛋,故认为还剩下2个生鸡蛋,但并未考虑还剩下两个熟鸡蛋。
在该测试中,deepseek-r1和豆包1.5 pro都认为还剩四个鸡蛋,表现不错。Qwen-2.5认为还剩2个生鸡蛋,考虑了“人吃熟鸡蛋”这一常识,但并未说出还剩几个鸡蛋。gpt-4o的表现让人失望,认为还剩0个鸡蛋。
deepseek-r1=豆包1.5 pro>Qwen-2.5>gpt-4o
prompt 2:“strawberry”中有几个r?
模型1:gpt-4o
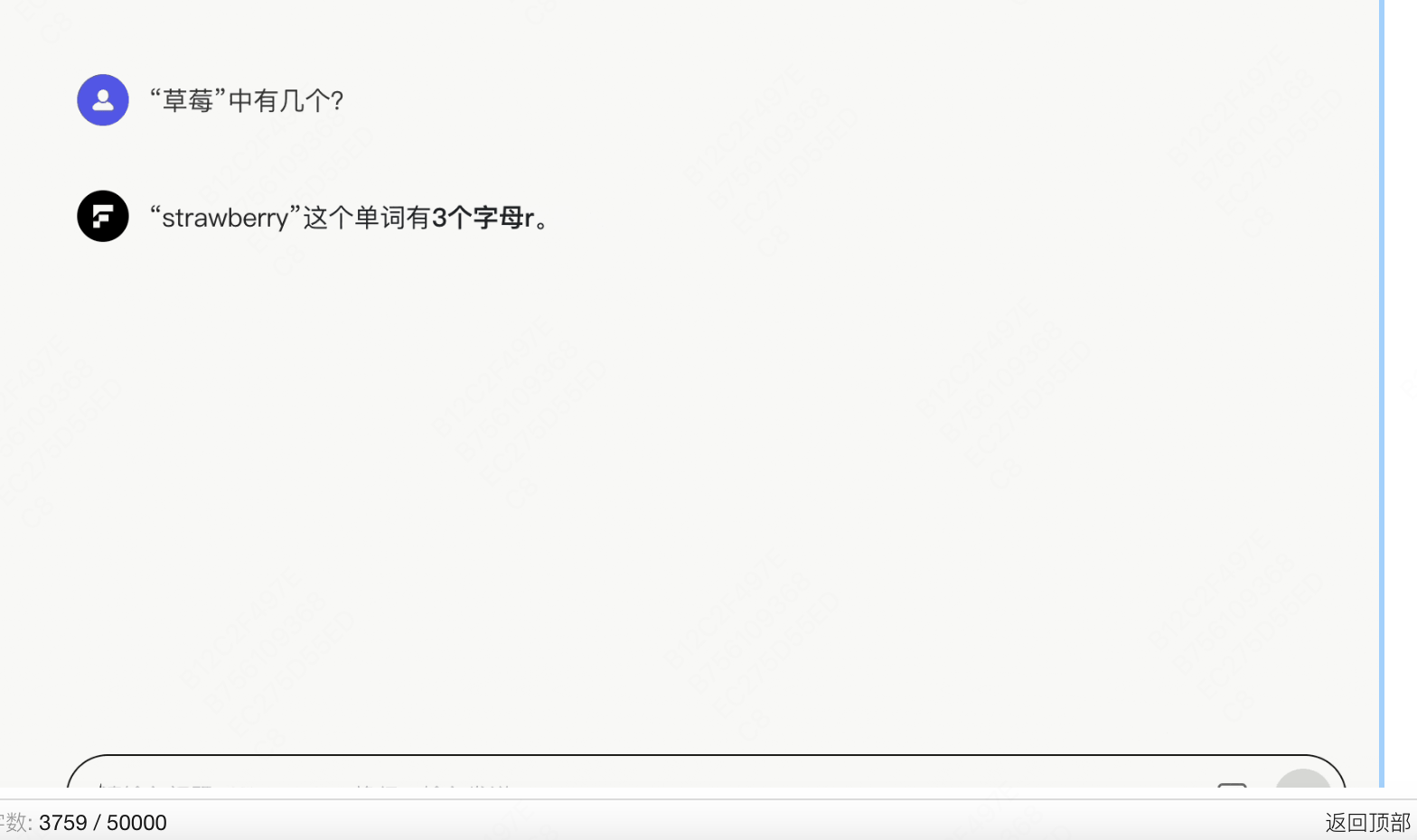
录屏2025-03-20 14.39.36.mov
450.94KB
迅速得出“strawberry”中有三个字母r
模型2:deepseek-r1

录屏2025-03-20 14.41.18.mov
6.28MB
在思考过程中,逐一分析每个字母是不是“R”,最终得出有3个的正确结论。
模型3:豆包1.5pro
录屏2025-03-20 14.43.01.mov
4.41MB
经过短暂思考后,得出有3个的正确结论。
模型4: Qwen-2.5
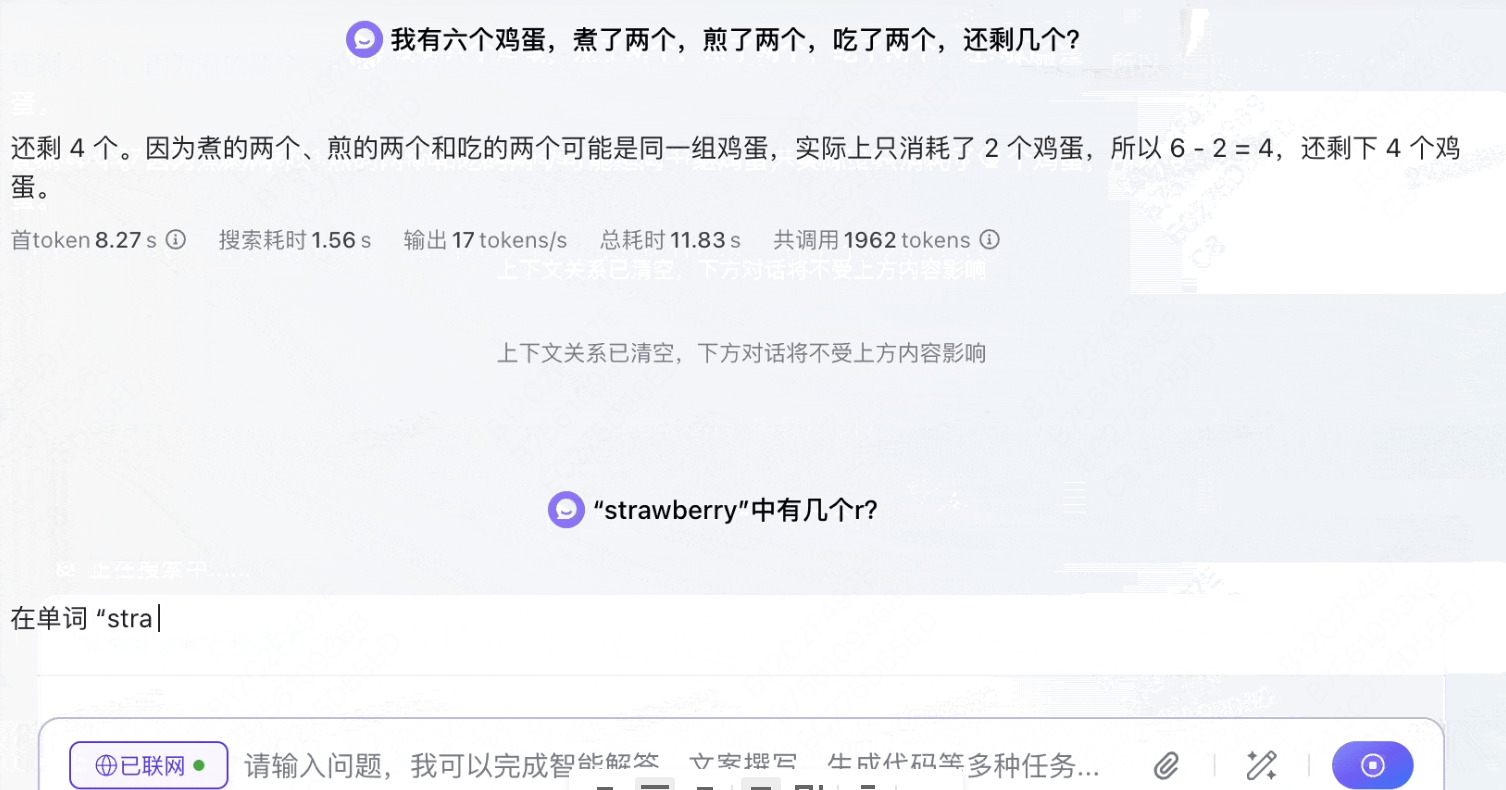
录屏2025-03-20 14.44.58.mov
1.39MB
经过短暂思考后,得出有3个的正确结论。
因为工作原理的原因,大模型擅长【理解含义】而不是【统计数量】,如果在大模型训练阶段并未针对【逐个字母数数】这个能力有专门的训练的话,会出现数错的情况,“strawberry中有几个字母r?”曾是测试模型能力的经典问题,在最新的模型中,这个问题被解决。
deepseek-r1=豆包1.5 pro=Qwen-2.5=gpt-4o
prompt 3:树上有30只鸟,我开枪打中一只,枪里没有子弹,此时树上还有多少只鸟
模型1:gpt-4o

录屏2025-03-20 14.50.27.mov
1.82MB
认为开枪后的声音会惊醒多所有的鸟,树上将没有任何鸟。
模型2:deepseek-r1

录屏2025-03-20 14.51.08.mov
26.74MB
认为这道题目属于脑筋急转弯,也意识到了题目中的“矛盾”所在:枪里没有子弹和打中一只鸟相互矛盾,考虑到“鸟儿是否会飞走”取决于扣动扳机时是否有声音,最终认为鸟儿对声音敏感,扣动扳机的声音也会惊醒鸟,树上将有0只鸟。
模型3:豆包1.5 pro
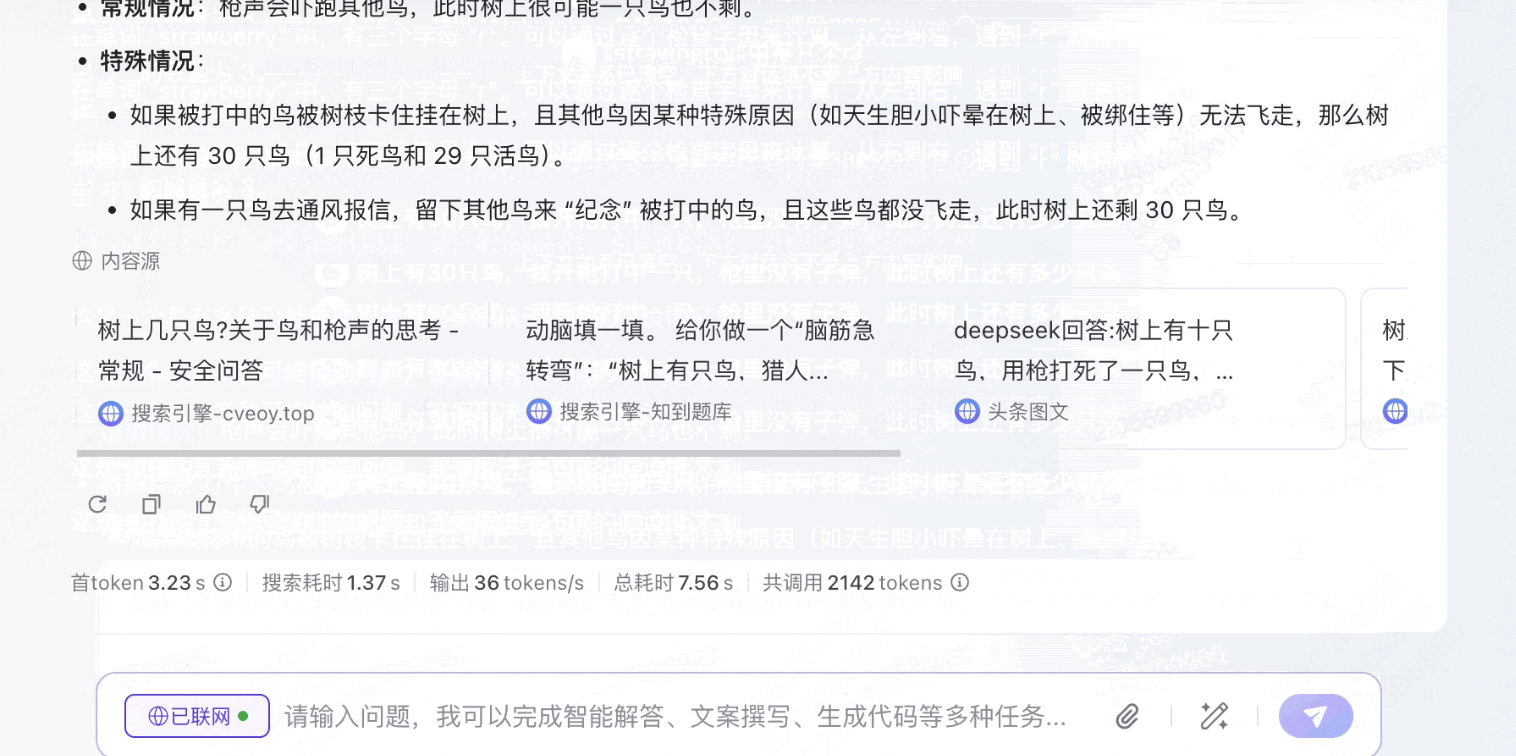
录屏2025-03-20 14.52.46.mov
5.83MB
并未意识到了题目中的“矛盾”所在。分多种情况进行讨论,但讨论的可能情况让人啼笑皆非:
情况一:枪声会吓跑其他鸟,此时树上很可能一只鸟也不剩。
情况二:被打中的鸟被树枝卡住挂在树上,且其他鸟因某种特殊原因(如天生胆小吓晕在树上、被绑住等)无法飞走,那么树上还有 30 只鸟(1 只死鸟和 29 只活鸟)。
情况三:如果有一只鸟去通风报信,留下其他鸟来 “纪念” 被打中的鸟,且这些鸟都没飞走,此时树上还剩 30 只鸟。
模型4:Qwen-2.5

录屏2025-03-20 14.56.34.mov
1.35MB
意识到了这是一个脑筋急转弯问题,树上将一只鸟也不剩。
在该测试中,deepseek-r1、Qwen-2.5、gpt-4o都意识到是个脑筋急转弯问题,树上一只鸟也不剩。豆包1.5 pro虽然分多种情况进行讨论,但“被打中的鸟被树枝卡住挂在树上,鸟天生胆小吓晕在树上、鸟被绑住、一只鸟去通风报信,留下其他鸟来 “纪念” 被打中的鸟”这种情况几乎不可能发生,把简单的问题复杂化。
deepseek-r1=Qwen-2.5=gpt-4o>豆包1.5 pro
prompt 4:在纸上画一个正方形,将正方形对折三次,最后得到的形状是什么?
模型1:gpt-4o:
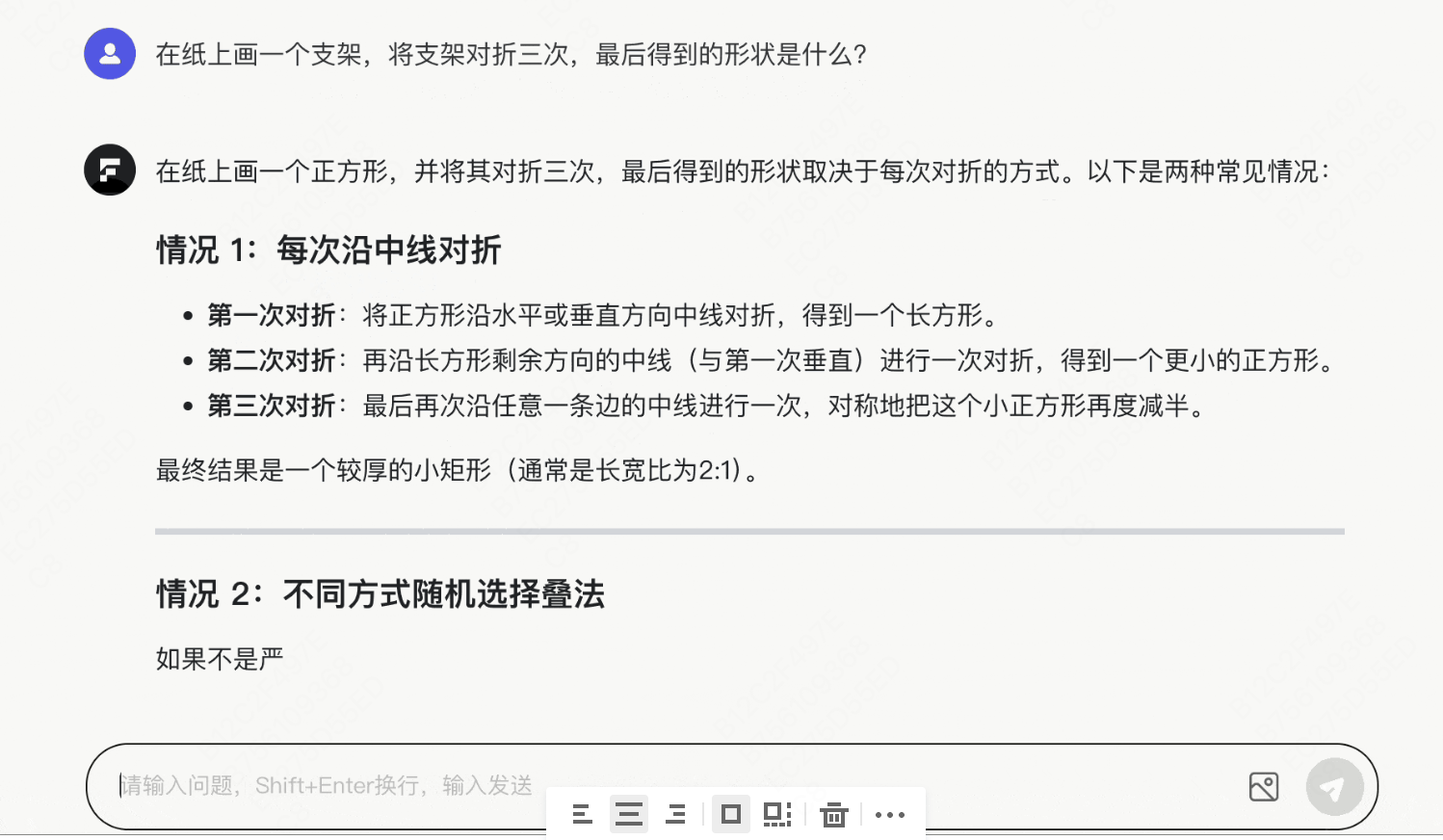
录屏2025-03-20 15.07.30.mov
4.19MB
将“在纸上画正方形”理解成为“在纸上画支架”,考虑多种折叠的方式,认为最后得到的形状为长方形或随机形状,未考虑折叠成为三角形。
模型2:deepseek-r1

录屏2025-03-20 15.09.51.mov
27.21MB
考虑了多种对折方式,最终思考中断,没有得出确定的结论。
模型3:豆包1.5 pro
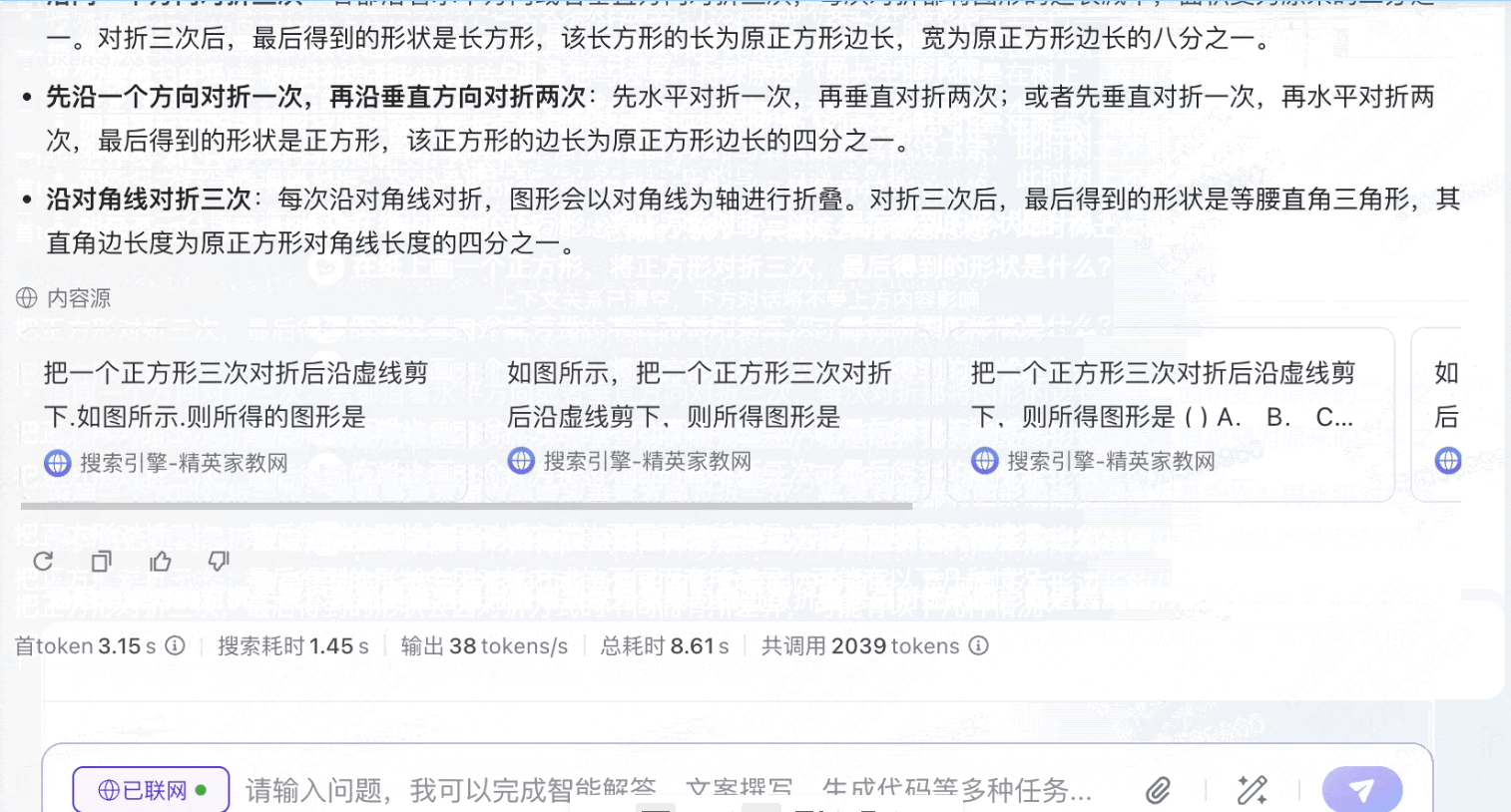
录屏2025-03-20 15.12.12.mov
7.20MB
考虑到了多种对折方式,得出为长方形或三角形的结论,并将不同长宽比的长方形做了分类,认为最终形状取决于折叠方式。
模型4:Qwen-2.5
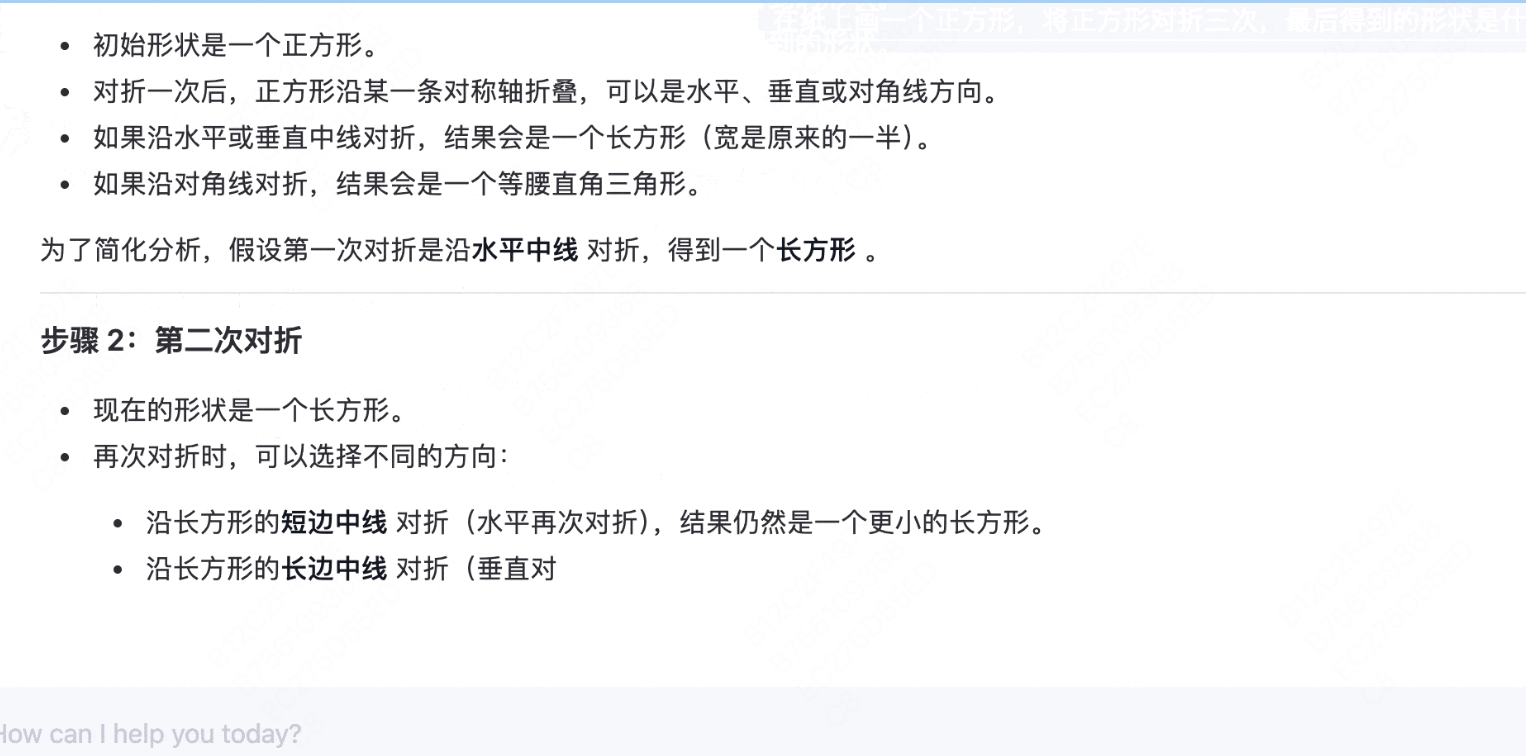
录屏2025-03-20 15.13.39.mov
7.24MB
考虑到了多种对折方式,得出为长方形或三角形的结论,认为如果没有特殊情况,更有可能是长方形。
在该测试中,豆包1.5 pro、Qwen-2.5都认为可能是长方形,也可能是三角形。gpt-4o虽然也分情况讨论,但忽略了三角形的结果。deepseek-r1思考中断。
豆包1.5 pro=Qwen-2.5>gpt-4o>deepseek-r1
prompt 5:小鲸鱼对妈妈说,妈妈,我长到你这么大,你就28岁了,妈妈对小鲸鱼说,我像你这么大时,你才只有1岁,请问妈妈今年多少岁?
模型1:gpt-4o

录屏2025-03-20 15.31.08.mov
11.03MB
列出错误的方程后,最终思考终止,没有生成最终答案。
模型2:deepseek-r1:

录屏2025-03-20 15.32.30.mov
12.67MB
通过设定变量、建立方程、求解方程、验证结果得出了鲸鱼妈妈19岁的正确答案。
模型3:豆包1.5pro
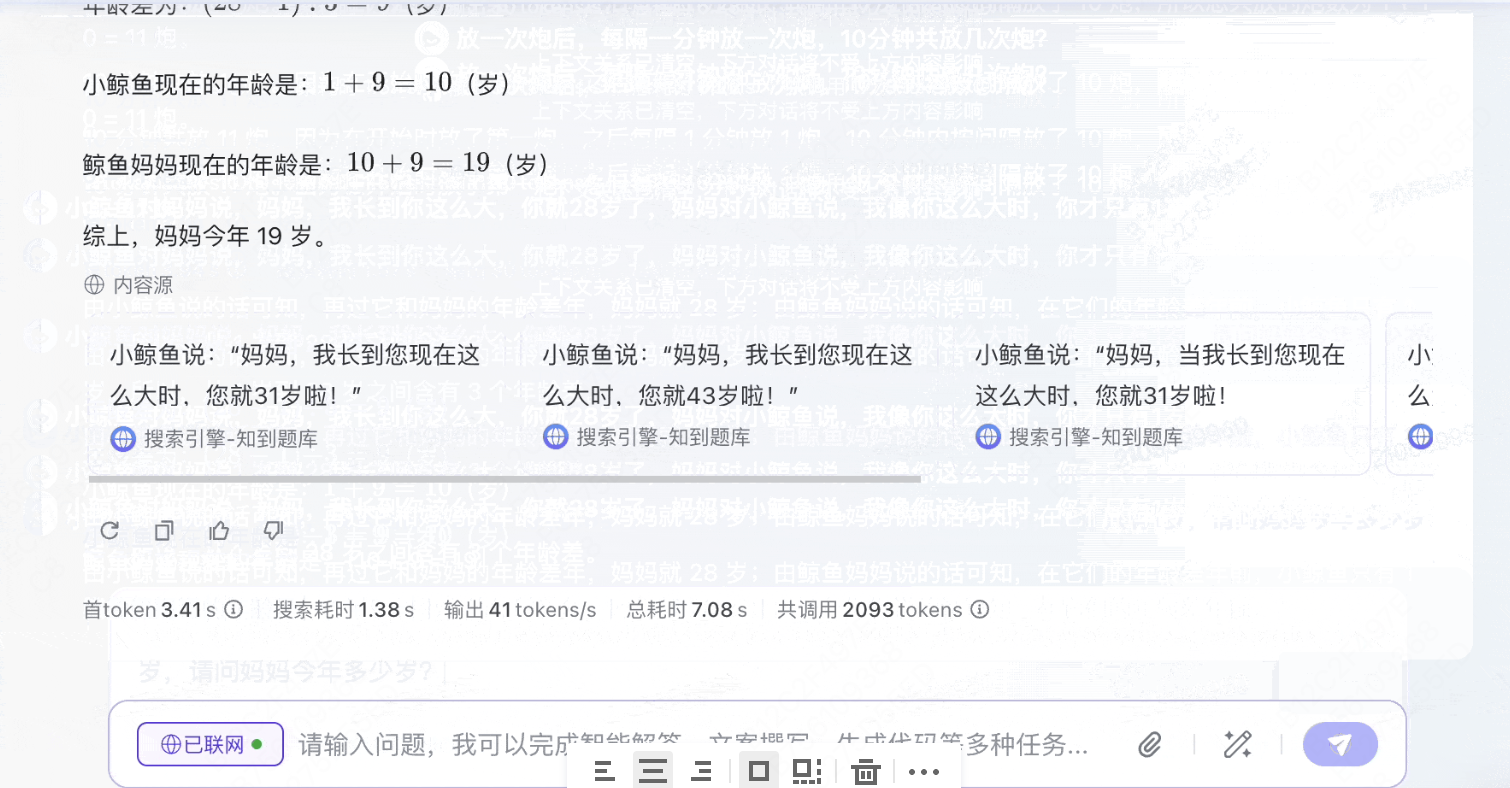
录屏2025-03-20 15.40.43.mov
6.78MB
并没有用解方程的形式,通过更加清楚简单的数学运算,得出了鲸鱼妈妈19岁。
模型4:Qwen-2.5

录屏2025-03-20 15.17.31.mov
6.85MB
通过设定变量、建立方程、求解方程、验证结果得出了鲸鱼妈妈19岁、小鲸鱼10岁的正确答案。
豆包1.5 pro、Qwen-2.5、deepseek-r1都计算正确,gpt-4o没有生成最后的答案。
豆包1.5 pro=Qwen-2.5=deepseek-r1>gpt-4o
prompt 6:15的阶乘结尾有几个0
模型1:gpt-4o:

录屏2025-03-20 15.33.51.mov
2.51MB
经过短暂推导,得出结尾有3个0,回答正确。
模型2:deepseek-r1:

录屏2025-03-20 15.34.25.mov
20.70MB
经过推导,得出结尾有3个0,回答正确
模型3:豆包1.5pro
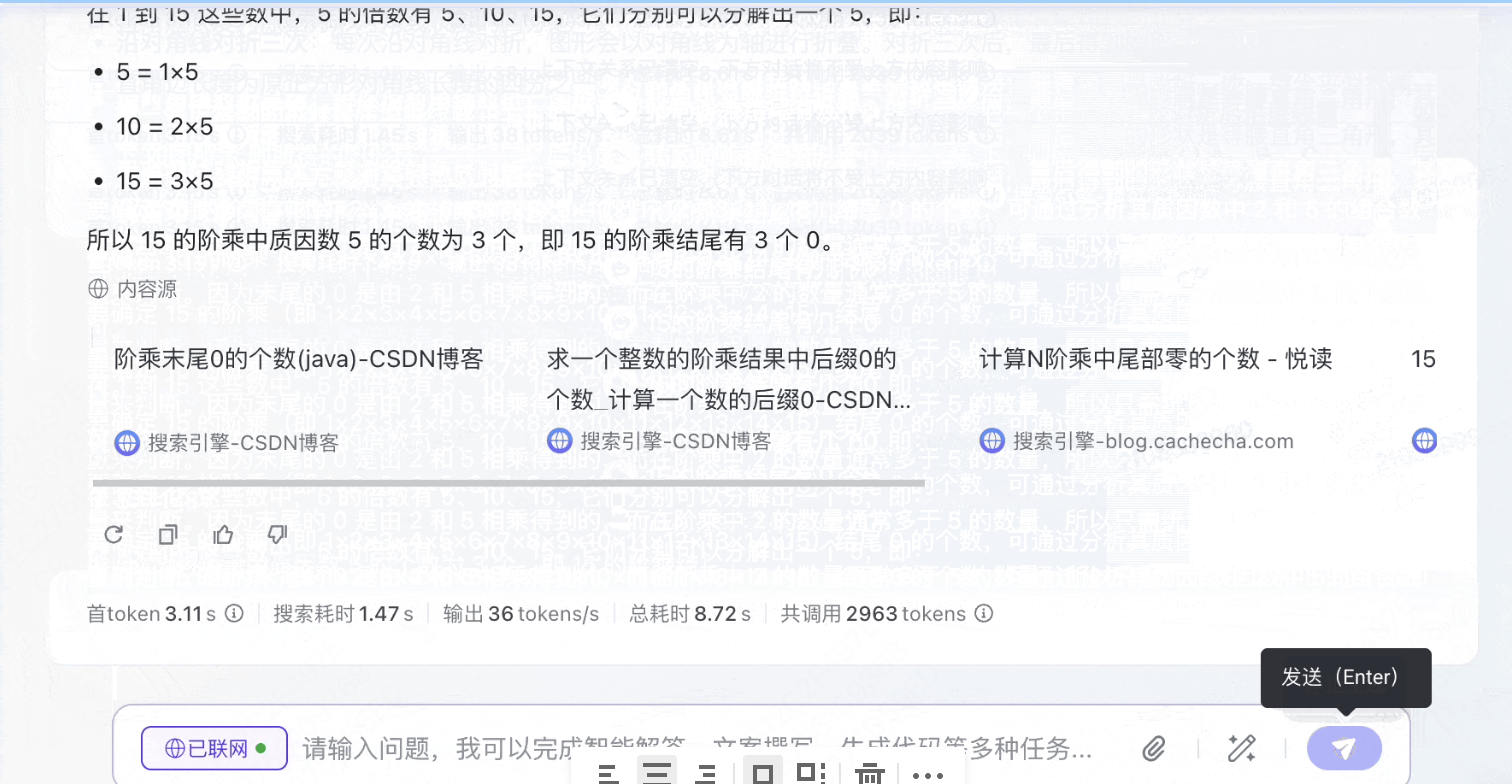
录屏2025-03-20 15.38.33.mov
6.97MB
经过推导,得出结尾有3个0,回答正确
模型4:Qwen-2.5

录屏2025-03-20 15.26.30.mov
4.13MB
经过短暂思考,得出有3个0的正确答案。
所测试模型全部得出正确答案。
豆包1.5 pro=Qwen-2.5=deepseek-r1=gpt-4o
prompt 7:放一次炮后,每隔一分钟放一次炮,10分钟共放几次炮?
模型1:gpt-4o:

录屏2025-03-20 15.36.38.mov
1.29MB
得出共放11次炮的正确结论。
模型2:deepseek-r1:

录屏2025-03-20 15.37.12.mov
19.27MB
意识到了第一次放炮是在0分的时刻,得出得出共放11次炮的正确结论。
模型3:豆包1.5pro
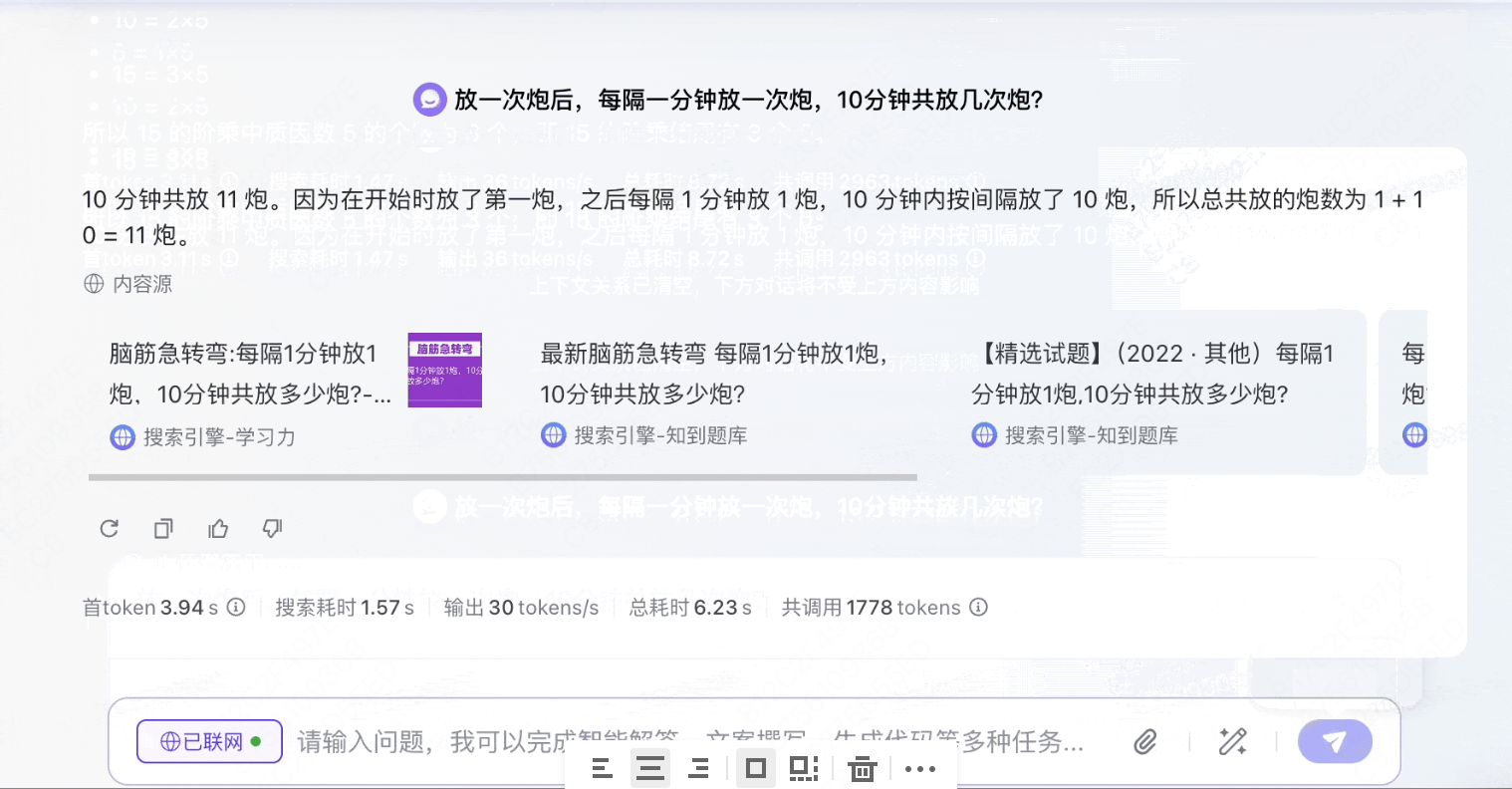
录屏2025-03-20 15.39.37.mov
4.33MB
得出共放11次炮的正确结论。
模型4:Qwen-2.5

录屏2025-03-20 15.29.59.mov
2.13MB
得出共放11次炮的正确结论。
所测试模型全部得出正确答案。
豆包1.5 pro=Qwen-2.5=deepseek-r1>gpt-4o
以上是我们本期测评的全部内容,欢迎关注我们,下期为你带来更多大模型最新资讯!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号