父子进程的故事:解读Linux中的fork机制


前言
在Linux系统中,进程是操作系统最重要的执行单元,而父子进程的创建与管理更是系统资源分配和任务并行的关键。通过fork函数,Linux能够快速高效地复制一个进程,使得父子进程协同工作成为可能。理解父子进程的运行机制不仅有助于掌握系统编程的核心技能,更能为优化资源利用与提高程序性能提供理论基础。本文将带你从基础原理出发,解析Linux父子进程的运行特性、fork的核心机制及其在实际开发中的应用。
一、进程PID
PID 是用来唯一标识一个进程的属性,我们可以使用 ps 指令查看一个进程的部分属性。进程的属性信息是由操作系统来维护的,这些信息被存储在一个 task_struct 结构体中,属于操作系统内核中的数据。由于操作系统本身是不相信用户的,所以用户无法直接去访问 task_struct 对象中的成员,因此 ps 指令能够显示进程的属性信息,本质上是通过系统调用接口去实现的。
1.1 通过系统调用接口查看进程PID
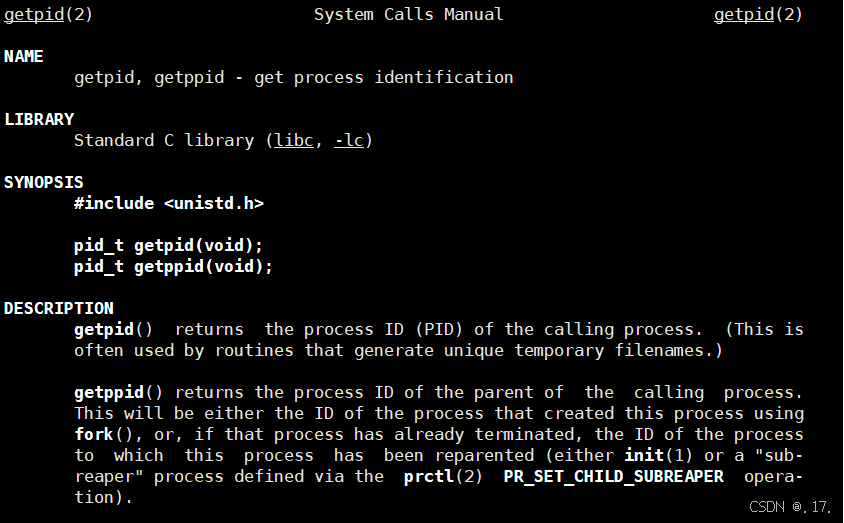
获取进程的 PID 需要用到系统调用接口 getpid() ,该函数会返回调用该函数的进程的 PID,返回值类型为 pid_t 。如下图我们使用 man getpid 指令去查看 getpid 的基础文档:
在这里插入图片描述
注意上图中还有一个 getppid 是什么呢?不难猜到,这应该是用来获取父进程 PID 的系统调用接口,接下来我们写段代码来具象化 PID 吧。
注意上图中还有一个 getppid 是什么呢?不难猜到,这应该是用来获取父进程 PID 的系统调用接口,接下来我们写段代码来具象化 PID 吧。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while(1)
{
printf("I am a process, my id is: %d, parent id is: %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}我们可以写一个脚本来实时获取上面这段代码执行起来后的进程信息。

在这里插入图片描述

在这里插入图片描述
可以看到,我一个将这段代码执行了两次,每一次的子进程 PID 都在发生变化,但是父进程的 PID 从未更改。
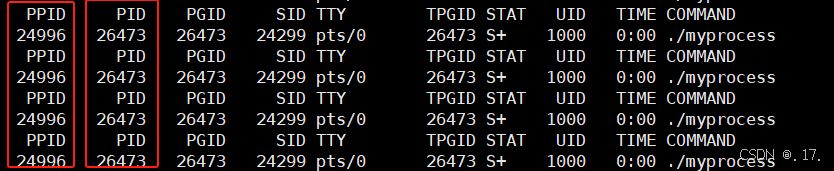
为了保证数据的准确性,我们再使用 ps 指令对比以下获取到的进程 PID 是否真的一样。
while :; do ps axj | head -1 ; ps axj |grep process | grep -v grep ; sleep 1 ; done
在这里插入图片描述
在这里插入图片描述
结论:我们用 getpid 和 getppid 得到的父子进程的 PID 和 ps 指令获取到的进程 PID 是一样的
二、通过系统调用创建进程-fork初识
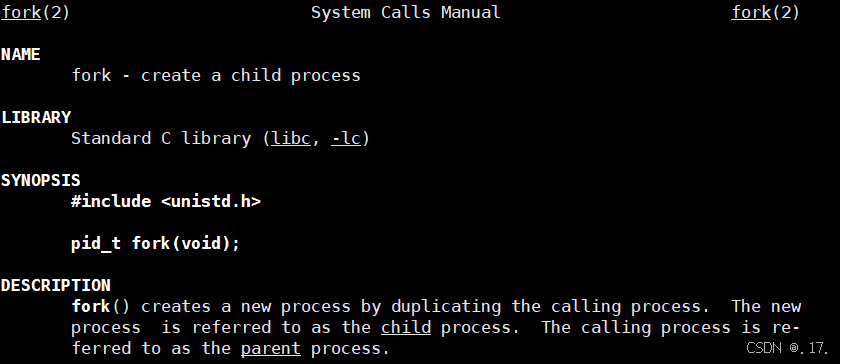
之前我们自己创建进程都是通过写一份源代码,然后去编译运行,最终得到一个进程,今天给大家介绍另一种通过系统调用接口 fork 去创建进程的方式。一样的,我们使用 man fork 去查看一下 fork 的相关文档:
在这里插入图片描述
大致意思就是:fork 函数会以调用该函数的进程作为父进程去创建一个子进程.

在这里插入图片描述
创建成功时,会在父进程中返回子进程的 PID ,在子进程中返回 0 。否则就在父进程中返回 -1 ,子进程创建失败。
2.1 调用fork函数后的现象
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("before:only one line\n");
fork();
printf("after:only one line\n");
return 0;
}
在这里插入图片描述
如上图所示,fork 后面的代码执行了两次!这是什么原因呢?我们再写一段代码跑跑。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
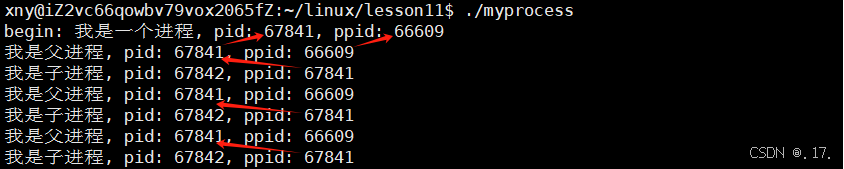
printf("begin:我是一个进程,pid:%d, ppid:%d\n",getpid(), getppid());
pid_t id = fork();
if(id > 0)
{
while(1)
{
printf("我是父进程,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else if(id == 0)
{
while(1)
{
printf("我是子进程,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else
{
perror("子进程创建失败!\n");
}
return 0;
}
在这里插入图片描述
通过结果我们可以得出,在上面的一份代码中 id 大于0和 id 等于0同时存在, if 和 else if 同时满足,并且有两个死循环在同时跑。这个现象说明此时一定存在两个进程,即原来的 myprocess 进程和在 myprocess 进程中创建的子进程,因为在一个进程中 if 和 else if 是不可能同时满足的。这也符合 fork 函数创建子进程的目的,fork 函数创建子进程后,会从原来的一个执行流变成两个执行流。
2.2 为什么fork要给子进程返回0,给父进程返回子进程 pid?
1. fork 返回值的设计目的
fork 是 UNIX 系统中用于创建新进程的核心系统调用。调用一次 fork,系统会“分裂”出两个进程:父进程和子进程。它的返回值有以下特点:
- 在父进程中:
fork返回新创建的子进程的PID,使得父进程可以通过该PID来管理和操作子进程(如使用wait或kill等操作)。 - 在子进程中:
fork返回0,标识自己是子进程,无需再通过PID区分。
这种设计的核心目的正如您提到的,用于区分不同执行流,即便父子共享同一套代码,也可以根据返回值选择性地执行不同代码。
2. 现实类比的深入解读
- 父亲喊“儿子”:如果不区分,所有子进程都会响应,导致混乱。通过分配唯一的
PID,每个子进程可以被单独识别。 - 子进程喊“爸爸”:由于每个子进程只能有一个父进程,所以子进程通过调用
getppid()即可找到其唯一的父进程。
3. 为什么子进程返回值为 0
- 简单区分:子进程无需知道自己的
PID来执行自己的任务,而只需通过返回值0知道自己是子进程。 - 效率和逻辑一致性:如果子进程也返回自己的
PID,会引入额外的复杂性,而且父进程需要一个单独机制区分这些值。
2.3 一个函数是如何做到返回两次的?如何理解?
在调用 fork 函数之前就只有一个进程,我们先来回顾一下什么是进程?进程 = 内核数据结构 + 代码和数据,其中的内核数据结构就是进程对应的 PCB 对象。
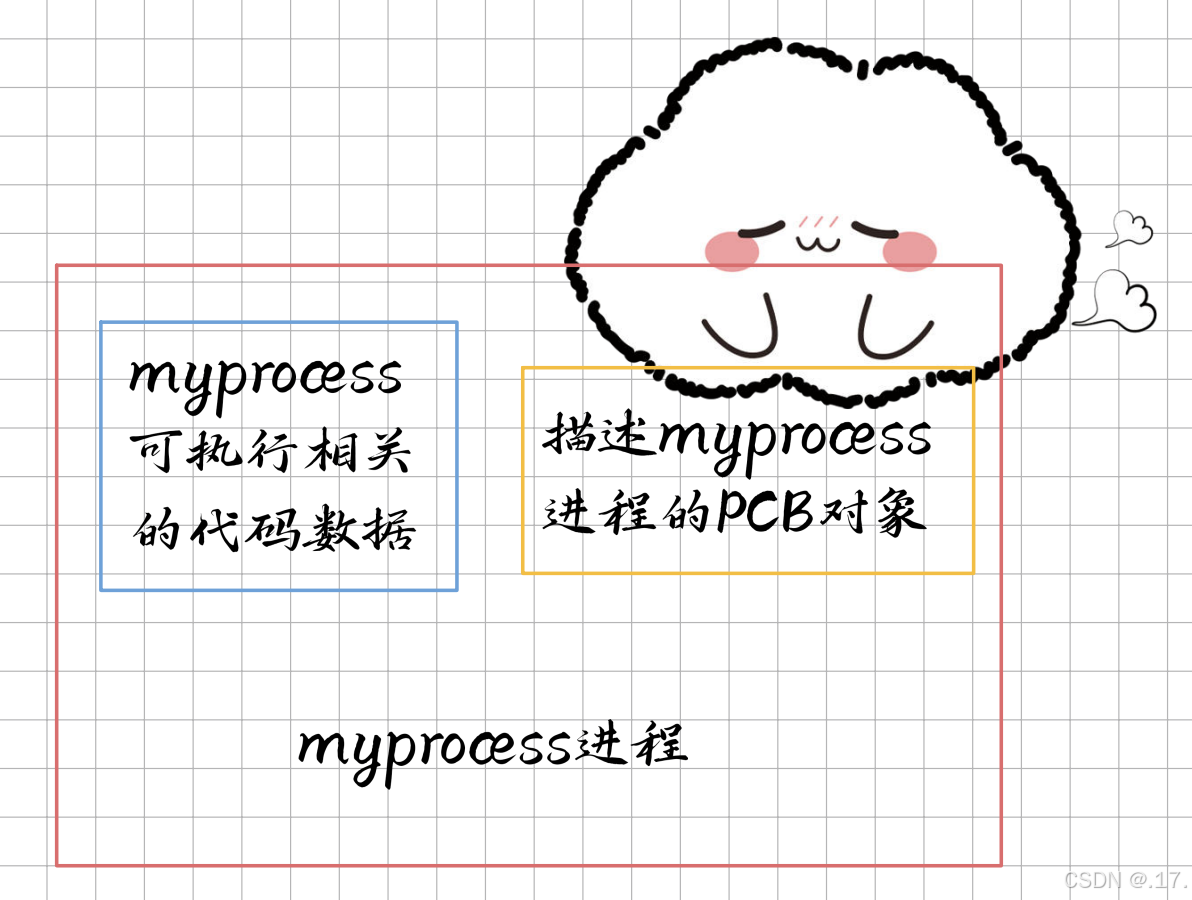
在这里插入图片描述
进程的 PCB 对象会找到相应的代码和数据,然后 CPU 就要去调度这个进程,也就是找到该进程的代码和数据去执行。调用 fork 函数创建子进程,本质上是操作系统多了一个进程,因此 fork 函数创建出来的子进程,它要先创建自己的 PCB 对象,子进程的 PCB 对象大部分都是以父进程的 PCB 对象为模板创建的,即从父进程的 PCB 对象中拷贝过来,再对部分属性稍作修改,子进程的 PCB 对象就有了。但是它没有自己的代码和数据,所以只能用父进程的,所以 fork 函数之后,父子进程的代码共享,这就解释了为什么上面 fork 函数之后的代码输出了两次,其实就是父子进程各自执行了一次。
创建子进程的目的就是为了帮助父进程做不同的事情,但是父子进程共享一份代码,所以我们应该在代码中对它们加以区分。fork 函数就帮我们完成了这个需求,它会在父子进程中返回不同的值,用户只需要根据返回值的不同让父子进程执行不同的代码。
fork 函数的实现过程:
pid_t fork():
- 创建子进程
- 创建子进程的PCB
- 填充PCB对应的内容
- 让子进程和父进程指向同样的代码
- 此时父子进程都有独立的task_struct对象,可以被CPU调度运行了
- return ret;
由于父子进程会共享一份代码,所以在 fork 函数执行 return 语句之前,子进程的 PCB 对象就已经被创建出来了,CPU 已经可以去同时调度父子进程。由于 fork 函数中的 return 语句也是被共享的,所以 fork 函数有两个返回值。
2.4 一个变量怎么会有不同的内容?
1. fork 的返回值如何写入不同的变量空间
当调用 fork 时,父进程与子进程会各自接收一个返回值,并且写入同名变量 id。但这并不意味着他们共享同一块内存,而是因为:
- 独立的进程地址空间
每个进程都有自己独立的虚拟地址空间。在
fork之后,父进程与子进程的地址空间是彼此独立的。尽管子进程初始时看起来与父进程完全相同,但实际上它们的数据是分离的。 - 写时拷贝(COW)机制
操作系统为提高效率并节省资源,采用了写时拷贝技术。在
fork之后:- 父子进程共享同一份内存数据,直到有一方尝试修改这些数据。
- 当某个进程试图修改数据时,操作系统会为该进程分配新的物理内存空间,并将被修改的数据复制到新分配的空间中。
2. fork 中变量 id 的本质
在代码中,变量 id 是存储 fork 返回值的地方。以下几点解释了为什么同名变量可以存储不同的值:
- 父子独立运行
fork返回后,父子进程的执行路径分开。父进程的id变量存储的是子进程的 PID,而子进程的id变量存储的是0。 - 不同的内存空间
由于父子进程的地址空间独立,
id实际上存在于两块不同的内存区域,即父进程的id和子进程的id是完全独立的变量。 - 赋值过程
fork的返回值通过操作系统写入到父子进程各自的id变量中:- 父进程在
return时向id写入子进程的 PID。 - 子进程在
return时向id写入0。
- 父进程在
结语
Linux父子进程的运行机制展示了操作系统设计的高效性与灵活性。从fork的返回值设计到写时拷贝(COW)的优化方案,这一切都体现了Linux在性能与资源利用上的巧妙平衡。通过深入理解父子进程的特性,不仅能够提升系统编程的能力,还能为并发和并行程序设计提供坚实的理论支持。希望本文能为你的学习和实践带来启发,在Linux系统的探索中迈向更高的层次。

在这里插入图片描述
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,17的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是17前进的动力!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号