腾讯云TI平台极速部署DeepSeek
原创
腾讯云TI平台极速部署DeepSeek
原创
叫我阿柒啊
发布于 2025-02-06 01:37:29
发布于 2025-02-06 01:37:29
前言
DeepSeek的出现,改变了原有的LLM模式,让我们自己就可以部署类似于ChatGPT的LLM。我们可以部署在本地的电脑上,从此解决了网络、对话次数限制等问题。但是如果想要部署一个DeepSeek的云服务,随时随地可以使用DeepSeek的话,就可以考虑使用腾讯云的HAI或者TI平台。

腾讯云TI平台是为 AI 工程师打造的一站式机器学习平台,可以快速帮助用户实现模型训练、模型评估以及模型部署等工作。DeepSeek作为大模型的后起之秀,腾讯云TI平台同样提供了一键式部署DeepSeek的能力。
腾讯云TI平台
首次登录腾讯云TI平台时,需要创建服务角色,跟着流程指引完成授权之后,进入到TI平台的大模型广场。
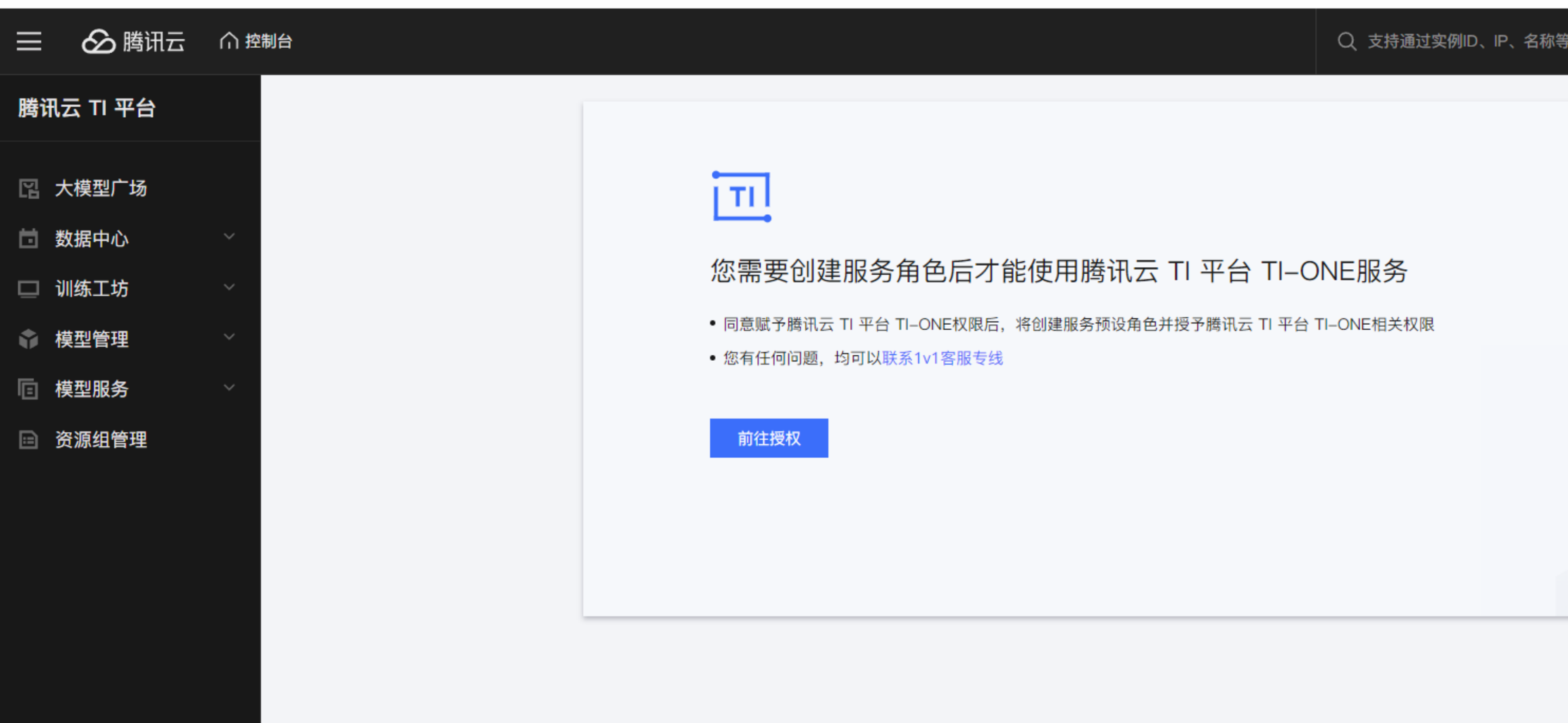
大模型广场
大模型广场 是 腾讯云 TI 平台 的内置大模型库,预置多种预训练大模型及指令微调大模型,覆盖各类下游任务,如多轮对话、逻辑推理、内容创作等。在大模型广场中,我们可以看到DeepSeek系列模型。
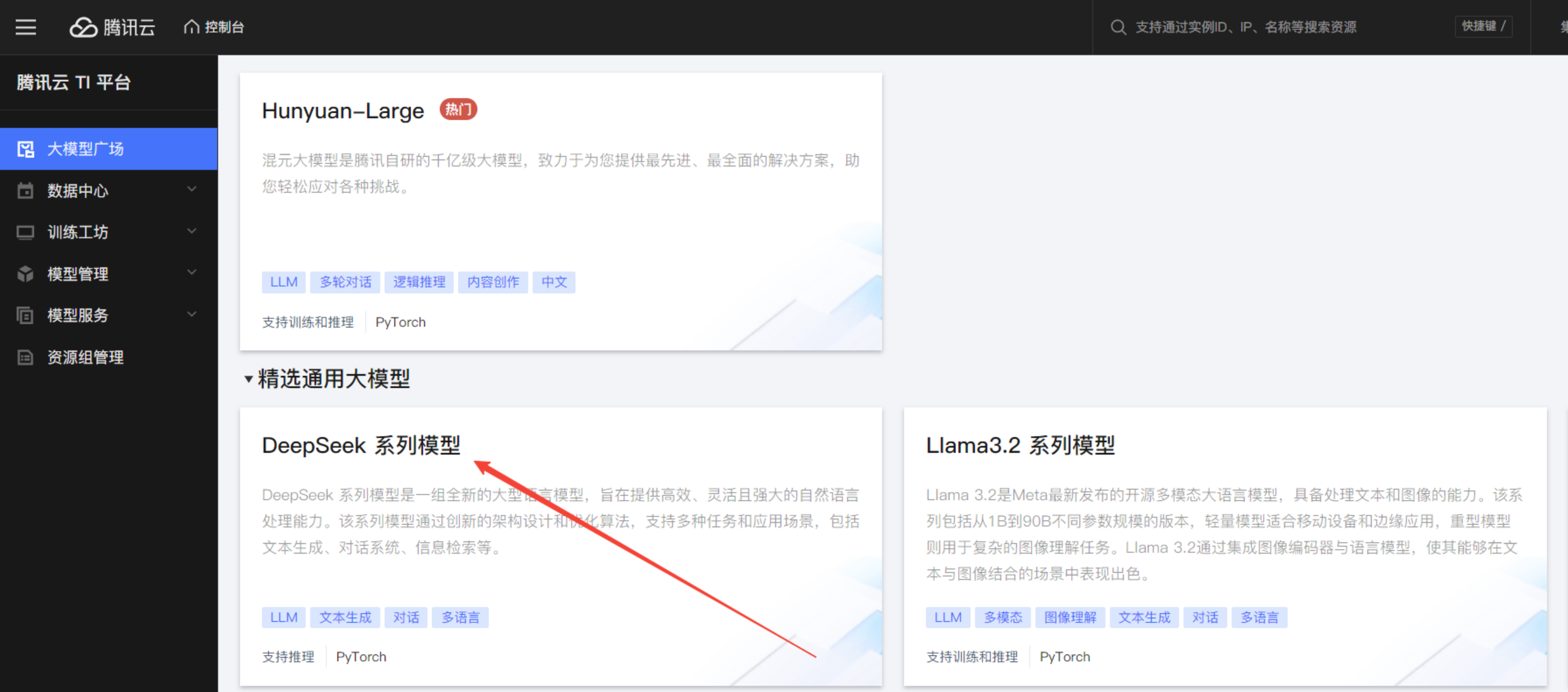
点击DeepSeek进入到详情页面,在详情页面可以看到模型介绍、模型体验。

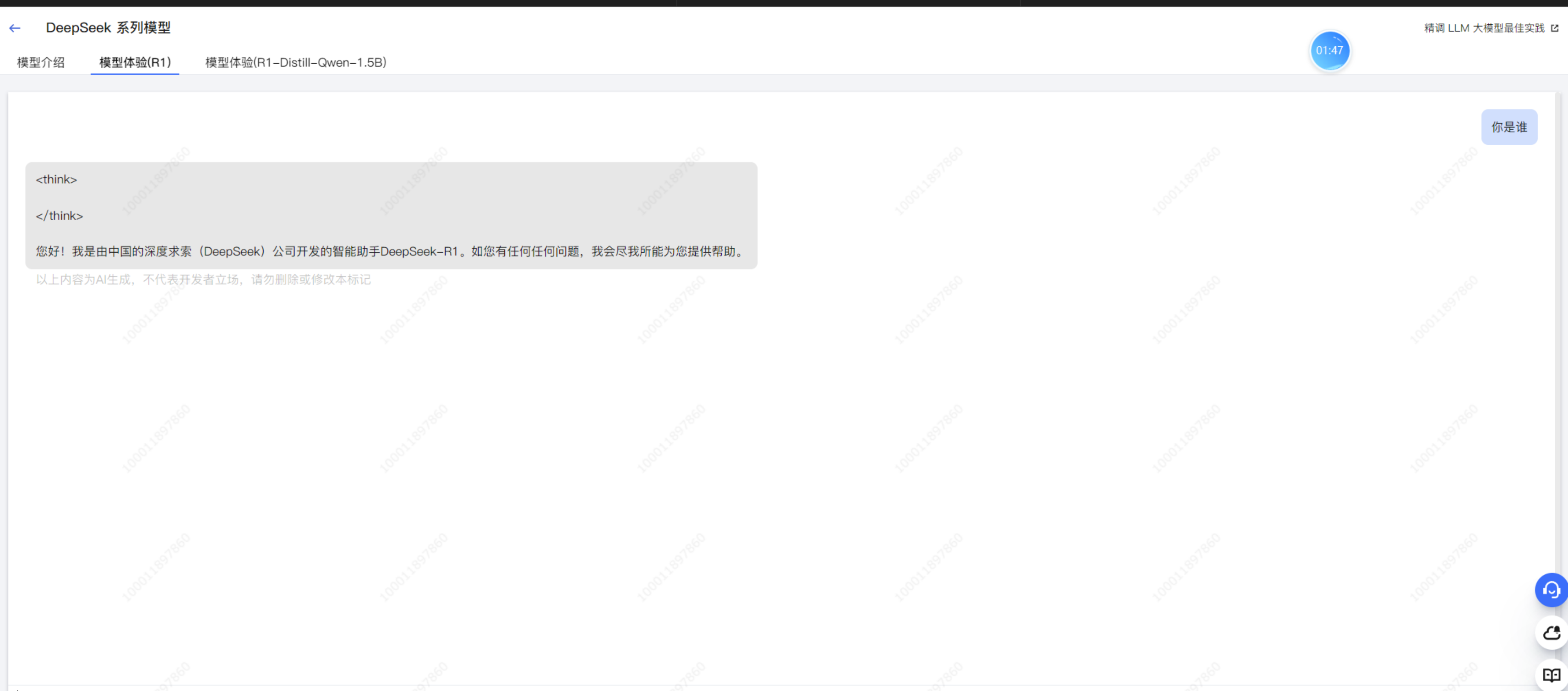
在模型体验中可以体验与DeepSeek模型的对话。
创建在线服务
在DeepSeek的模型页面,点击新建在线服务,进入到服务创建页面。填入服务名称之后,选择机器来源用来部署DeepSeek。
1. 选择主机资源
一种方式是从已有的腾讯云CVM中选择安装DeepSeek,这样DeepSeek模型运行和推理时,就会使用CVM云服务器的资源。另一种直接是通过TIONE平台购买资源(显卡、内存、CPU)完成部署。
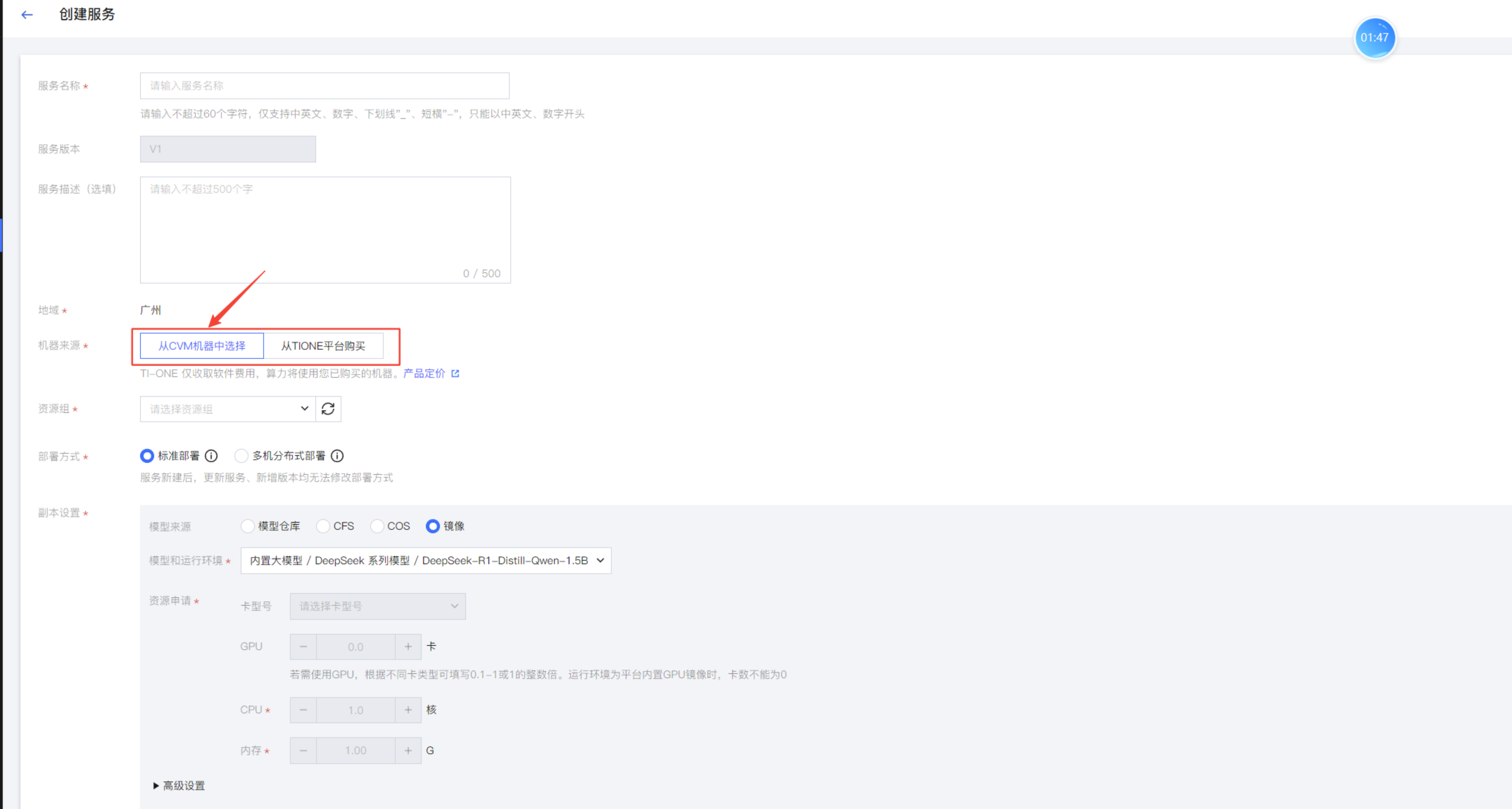
使用自有的CVM可能面临着资源不足的风险,通常带有显卡的CVM价格比较昂贵,而且当资源不足时也无法更改显卡内存或者内存的大小。而TIONE平台可以按量计费,可以实现快速的扩容和缩容。
2. 模型选择
接下来就是选择DeepSeek模型。
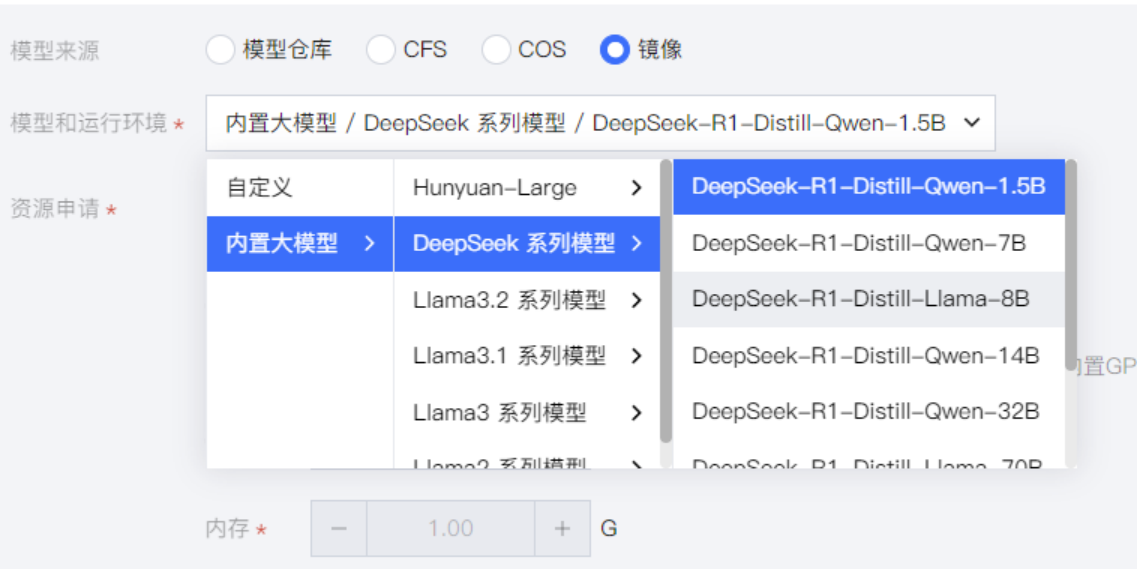
在内置大模型中,我们可以看到不同的名称的DeepSeek大模型,对于不同模型的区别如下所示:
模型名称 | 基础模型 | 参数规模 | 特点 | 计算需求 |
|---|---|---|---|---|
DeepSeek-R1-Distill-Qwen-1.5B | Qwen | 1.5B | 轻量级,适合移动端和本地推理 | 低(PC 可运行) |
DeepSeek-R1-Distill-Qwen-7B | Qwen | 7B | 适合本地推理和轻量级服务器部署 | 中等(24GB+ VRAM) |
DeepSeek-R1-Distill-Llama-8B | LLaMA | 8B | LLaMA 版本,英文能力更强 | 中等 |
DeepSeek-R1-Distill-Qwen-14B | Qwen | 14B | 中文能力更强,适用于专业应用 | 较高(A100 级别 GPU) |
DeepSeek-R1-Distill-Qwen-32B | Qwen | 32B | 适用于企业级 AI 任务 | 高(多 GPU / 云端) |
DeepSeek-R1-Distill-Llama-70B | LLaMA | 70B | 强大推理能力,适合高端 AI 计算 | 极高(H100 / TPU 级别) |
DeepSeek-V3-671B | 自研 | 671B | DeepSeek 最高参数量模型,超大规模通用 AI | 超高(云端 A100 集群) |
DeepSeek-R1-671B | 自研 | 671B | DeepSeek-R1 的完整超大模型 | 超高(企业级/科研级) |
- Qwen 系列(通义千问):基于阿里巴巴的 Qwen(通义千问)系列,适合中文任务,拥有较强的知识推理能力和上下文理解能力。
- LLaMA 系列:基于 Meta 的 LLaMA(LLaMA 2/3),更加通用,适合多语言任务,在英文任务上表现较好。
- DeepSeek 自研模型(R1/V3):DeepSeek 自主训练的大规模 Transformer 模型,R1 主要用于推理,而 V3 可能结合更多创新结构。
3. 选择算力规格
因为只有轻量应用服务器,没有CVM,所以我这里就从TIONE平台购买算力,这里我选择的按量计费。
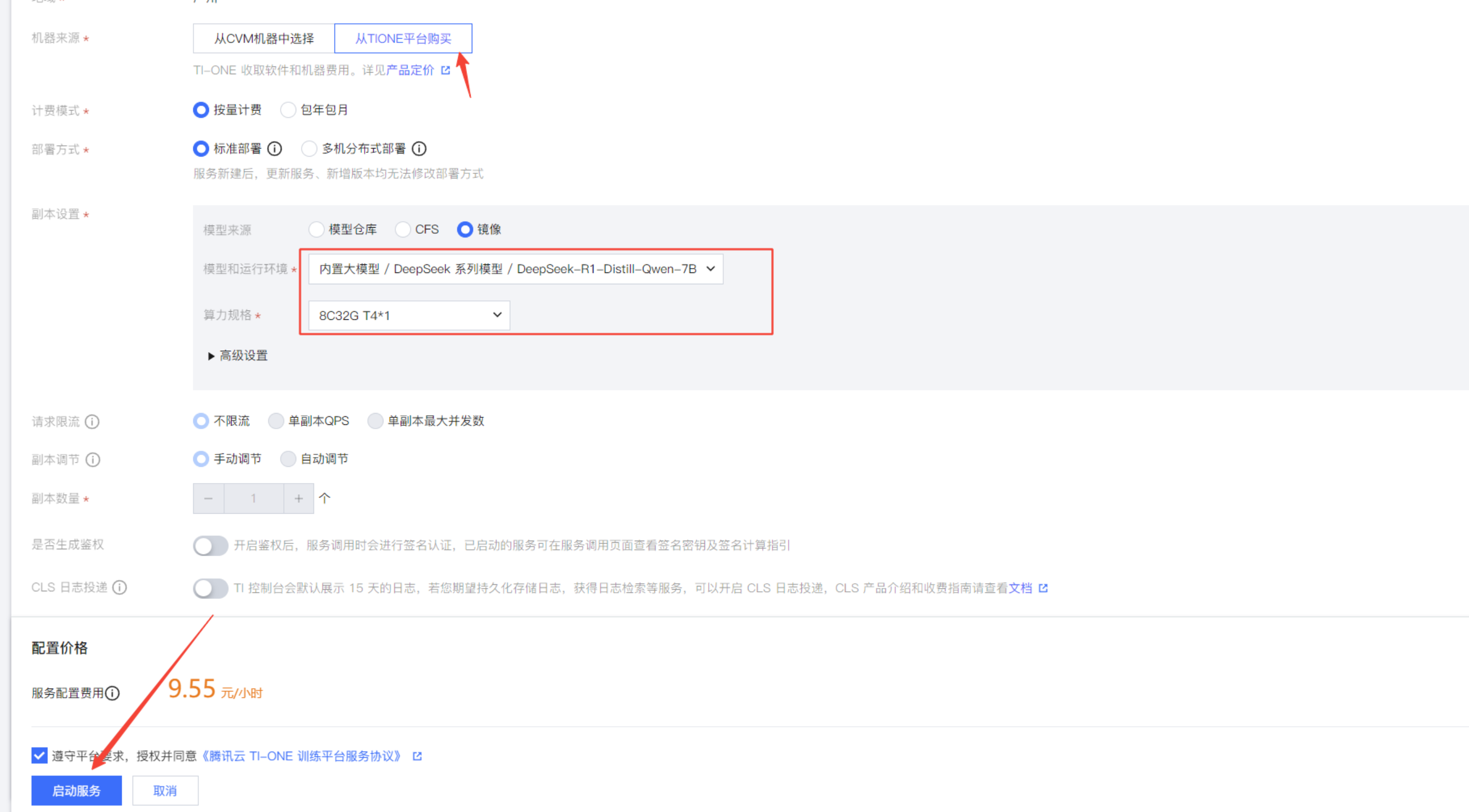
根据选择的DeepSeek模型,选择相对应的算力规格,点击启动服务。
4. 启动服务
启动之后进入在线服务列表。

在等待服务就绪之后,我们就可以点击服务查看详情。

点击调用API,可以查看DeepSeek的服务调用地址。
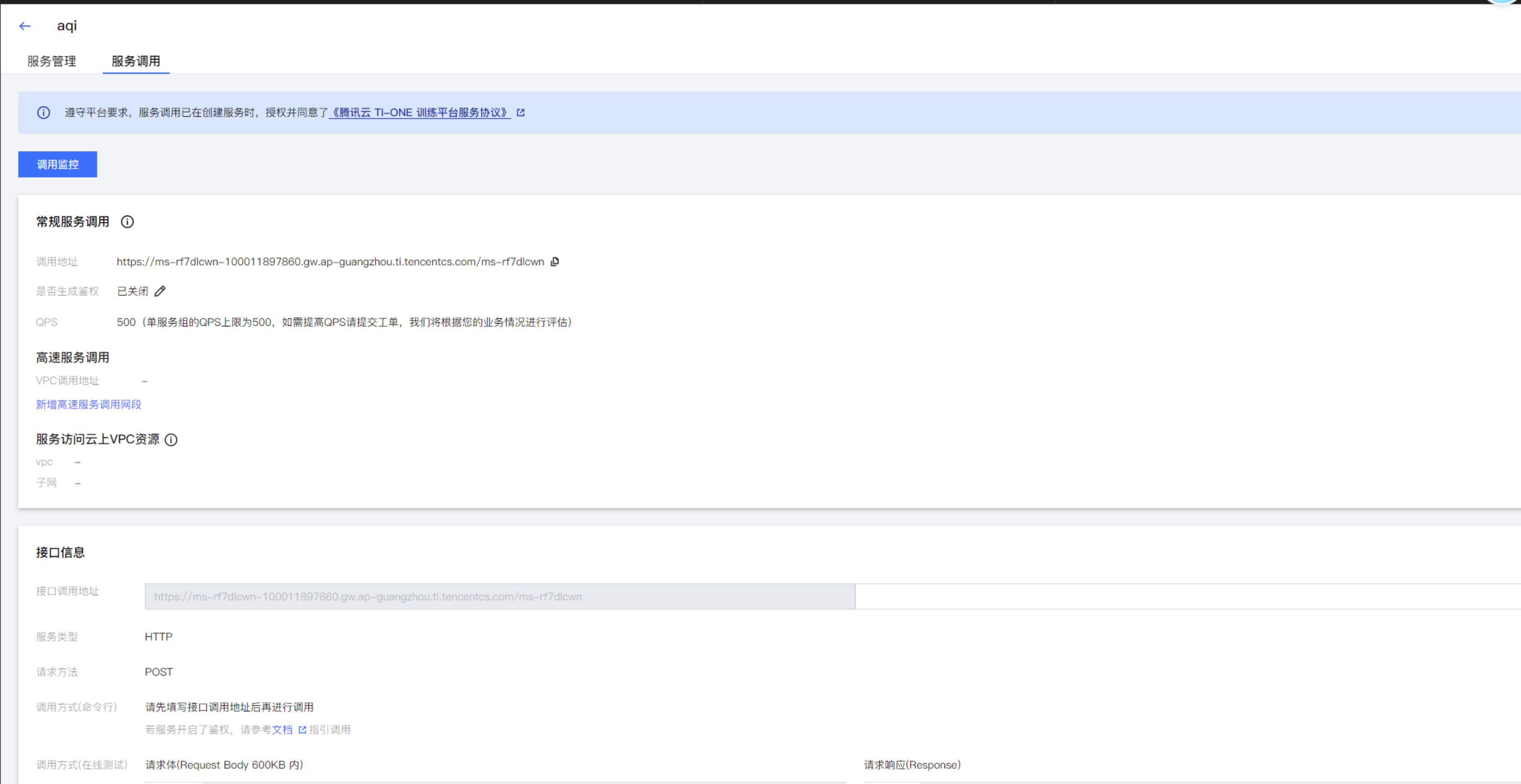
同时可以点击实例进入详情页面,我们可以看到安装了DeepSeek大模型实例的信息。
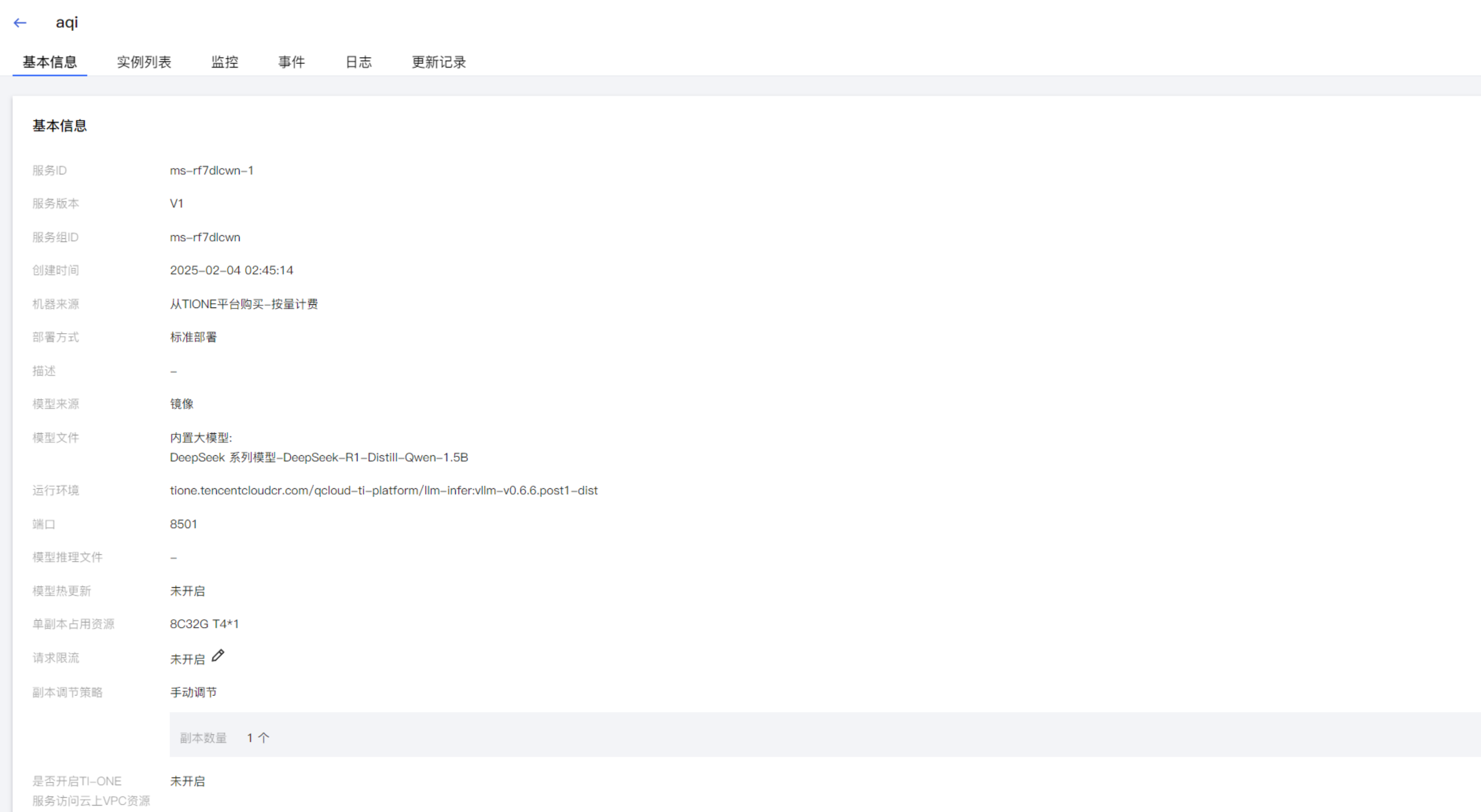
这样,我们就完成了DeepSeek在腾讯云TI平台的部署。
结语
可以看到通过腾讯云的TI平台,我们不需要自己部署DeepSeek大模型运行环境,也不需要自己购买服务器,通过资源打包、按量计费的模式,通过简单的界面化配置,完成了DeepSeek的部署。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号