PPO算法理解
原创
PPO算法理解
原创
喏喏心
修改于 2024-11-21 09:50:46
修改于 2024-11-21 09:50:46
好事发生
文章推荐:MFC/C++学习系列之简单记录7——句柄和AFX开头的函数的使用
文章链接:MFC/C++学习系列之简单记录7——句柄和AFX开头的函数的使用-腾讯云开发者社区-腾讯云
文章简介:本文介绍了在MFC使如何使用句柄和AFX开头的函数作用,代码解释详细且包含代码实现后效果,适合初学者已经需要使用句柄的朋友!
前言
PPO(Proximal Policy Optimization)算法在A2C基础上进行样本管理和梯度计算改进。
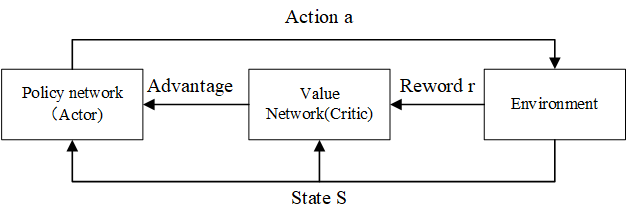
图0.强化学习算法原理图
核心改进点
1. 样本管理
- A2C 在每次更新时只使用新生成的样本,导致样本利用效率较低。
- PPO 引入了多个更新回合的机制,在不违背 On-policy 原则的前提下,允许对相同的样本进行多次梯度更新,提高数据利用率。
2. 梯度计算改进:引入剪切(Clipping)机制
- 在策略梯度方法中,策略的更新幅度如果过大,可能导致策略退化(偏离当前最优策略)。
- PPO 通过定义 目标函数,在策略更新时加入 剪切限制,保证策略的改进幅度不会太大。

图1.目标函数截图
目标函数的工作原理是:限制策略更新的范围,策略的更新比率超不超过预设的范围(即大于1+ϵ或小于1−ϵ),以防止策略发生剧烈变化。
代码实现
1. 支持离散动作空间的PPO网络结构
class Memory:
def __init__(self):
self.actions = []
self.states = []
self.logprobs = []
self.rewards = []
self.is_terminals = []
def clear_memory(self):
del self.actions[:]
del self.states[:]
del self.logprobs[:]
del self.rewards[:]
del self.is_terminals[:]
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim, n_latent_var):
super(ActorCritic, self).__init__()
# actor
self.action_layer = nn.Sequential(
nn.Linear(state_dim, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, action_dim),
nn.Softmax(dim=-1)
)
# critic
self.value_layer = nn.Sequential(
nn.Linear(state_dim, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, 1)
)
def forward(self):
raise NotImplementedError
def act(self, state, memory):
state = torch.from_numpy(state).float().to(device)
action_probs = self.action_layer(state)
dist = Categorical(action_probs)#按照给定的概率分布来进行采样
action = dist.sample()
memory.states.append(state)
memory.actions.append(action)
memory.logprobs.append(dist.log_prob(action))
return action.item()
def evaluate(self, state, action):
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action_logprobs = dist.log_prob(action)
dist_entropy = dist.entropy()
state_value = self.value_layer(state)
return action_logprobs, torch.squeeze(state_value), dist_entropy
class PPO:
def __init__(self, state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip):
self.lr = lr
self.betas = betas
self.gamma = gamma
self.eps_clip = eps_clip
self.K_epochs = K_epochs
self.policy = ActorCritic(state_dim, action_dim, n_latent_var).to(device)
self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr, betas=betas)
self.policy_old = ActorCritic(state_dim, action_dim, n_latent_var).to(device)
self.policy_old.load_state_dict(self.policy.state_dict())
self.MseLoss = nn.MSELoss()
def update(self, memory):
# Monte Carlo estimate of state rewards:
rewards = []
discounted_reward = 0
for reward, is_terminal in zip(reversed(memory.rewards), reversed(memory.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
rewards.insert(0, discounted_reward)
# Normalizing the rewards:
rewards = torch.tensor(rewards, dtype=torch.float32).to(device)
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5)
# convert list to tensor
old_states = torch.stack(memory.states).to(device).detach()
old_actions = torch.stack(memory.actions).to(device).detach()
old_logprobs = torch.stack(memory.logprobs).to(device).detach()
# Optimize policy for K epochs:更新多少次
for _ in range(self.K_epochs):
# Evaluating old actions and values :
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
# Finding the ratio (pi_theta / pi_theta__old):
ratios = torch.exp(logprobs - old_logprobs.detach())
# Finding Surrogate Loss: R(t)-b
advantages = rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy
# take gradient step
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
# Copy new weights into old policy:
self.policy_old.load_state_dict(self.policy.state_dict())PPO算法分为三个主要部分:Memory 类、ActorCritic 模型类,以及 PPO 主类。
(1)Memory 类:用于存储交互数据,包括动作、状态、对数概率、奖励以及是否终止的标志
- actions: 存储当前策略选择的动作。
- states: 存储每个时间步的状态。
- logprobs: 存储动作的对数概率,用于计算策略更新的目标函数。
- rewards: 存储环境反馈的奖励。
- is_terminals: 记录每个时间步是否为终止状态,用于奖励折扣计算。
(2) ActorCritic 类:PPO 算法的核心模型
模型包含 Actor 和 Critic 网络,用于分别计算策略分布和状态价值。
Actor 网络:
- 输出动作分布的概率值(Softmax)。
- 根据给定的状态,输出策略分布,供采样使用。
Critic 网络:
- 输出状态值 V(s),用作优势函数计算。
关键函数:
- act 方法:根据当前状态,采样动作并存储与环境交互相关的信息。
- evaluate方法:用于计算动作的对数概率、状态价值以及策略分布的熵,用于优化目标函数。
(3)PPO 类:实现策略的存储、更新和优化,是整个算法的主流程
- 初始化:包含policy和policy_old 两个模型实例,分别表示当前策略和旧策略。
- update :通过多轮优化更新策略网络。
- 折扣奖励计算:反向迭代计算奖励折扣
- 归一化奖励:对折扣奖励归一化,提升训练稳定性。
- 目标函数:通过概率比 rt(θ)和剪切限制实现策略优化。
2.main函数
def main():
############## Hyperparameters ##############
env_name = "LunarLander-v2" #月球登录器环境LunarLander-v2
# creating environment
#gym0.26 render_mode='human'可显示界面 不需要“render = True #True显示游戏窗口,False不显示”
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 4
render = True #True显示游戏窗口,False不显示
solved_reward = 100 # stop training if avg_reward > solved_reward 最大结束奖励
log_interval = 20 # print avg reward in the interval 打印间隔
max_episodes = 50000 # max training episodes 最大训练局数(游戏重新玩几局)
max_timesteps = 300 # max timesteps in one episode 每局最大步长
n_latent_var = 64 # number of variables in hidden layer 神经网络隐藏神经元数量
update_timestep = 2000 # update policy every n timesteps 多少步后更新学习参数
lr = 0.002 #学习率
betas = (0.9, 0.999) #Adam中更新权重参数
gamma = 0.99 # discount factor 折扣因子
K_epochs = 4 # update policy for K epochs 前轮数据学多少次
eps_clip = 0.2 # clip parameter for PPO 1+0.2 | 1-0.2
random_seed = None
#############################################
if random_seed:
torch.manual_seed(random_seed)
env.seed(random_seed)
memory = Memory()
ppo = PPO(state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip)
#print(lr,betas)
# logging variables
running_reward = 0
avg_length = 0
timestep = 0
# training loop
for i_episode in range(1, max_episodes+1):
state = env.reset()#初始化(重新玩)
for t in range(max_timesteps):
timestep += 1
# Running policy_old:
action = ppo.policy_old.act(state[0], memory)
#state, reward, done, _ = env.step(action)#执行action,得到(新的状态,奖励,是否终止,额外的调试信息) gym0.23
obs, reward, done, _, _ = env.step(action) #gym0.26 错误原因:获取的变量少了,应该是5个,现在只定义4个,所以报错。
# Saving reward and is_terminal:
memory.rewards.append(reward)
memory.is_terminals.append(done)
# update if its time
if timestep % update_timestep == 0:
ppo.update(memory)
memory.clear_memory()
timestep = 0
running_reward += reward
if render:
env.render()
if done:
break
avg_length += t
# stop training if avg_reward > solved_reward
if running_reward > (log_interval*solved_reward):
print("########## Solved! ##########")
torch.save(ppo.policy.state_dict(), './PPO_20241105_{}.pth'.format(env_name))
break
# logging
if i_episode % log_interval == 0:
avg_length = int(avg_length/log_interval)
running_reward = int((running_reward/log_interval))
print('Episode {} \t avg length: {} \t reward: {}'.format(i_episode, avg_length, running_reward))
running_reward = 0
avg_length = 0模型训练结果:
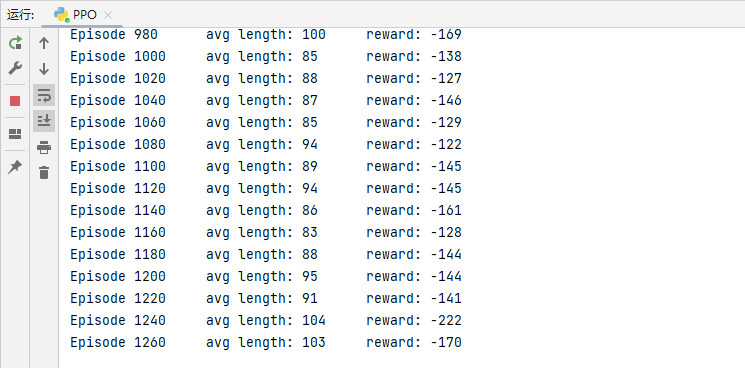
图2.训练过程截图
模型测试结果:
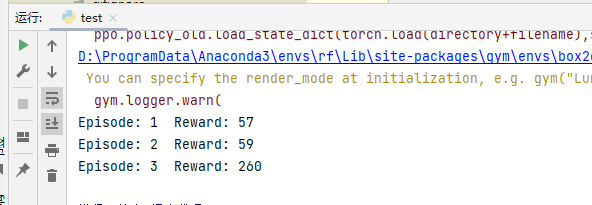
图3.测试过程截图
代码来自bi站学习下载,需要源码的朋友可以关注我或者评论,我会回复和发送源码,欢迎学习交流。
邀请人:升级打怪的菜鸟
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号