Spark纯净版 Hive on Spark配置
原创
Spark纯净版 Hive on Spark配置
原创
码农GT038527
发布于 2024-08-11 21:32:58
发布于 2024-08-11 21:32:58
介绍
Apache Spark 是一个开源的统一分析引擎,旨在快速处理大规模数据。它支持多种数据处理任务,包括批处理、流处理、机器学习和图形处理,具有高性能和易于使用的特点。
快速数据处理: Spark 利用内存计算,能够极大地提高处理速度,特别是在迭代计算和交互式查询中。
简化数据分析: 提供易于使用的 API,支持 Java、Scala、Python 和 R 等多种编程语言,使得数据分析变得更加简单。
支持多种数据源: Spark 可以处理我的多种数据格式,如 HDFS、S3、关系数据库、NoSQL 等。
先进的分析功能: 提供机器学习库(MLlib)、图计算库(GraphX)和实时流处理功能(Spark Streaming),能够满足多样化的分析需求。
例子:
想象一下你在家里准备一个大规模的聚会,涉及很多食物和饮料的准备。
- 厨房: 你的厨房是处理数据的地方。
- 食谱: 食谱就像是你用于数据分析的代码,指导你如何将原材料(数据)转化为准备好的菜肴(结果)。
- 厨师: 你负责做菜,使用不同的工具(如锅、烤箱等)来快速加工各种食物。
如果你不只是在准备一两道菜,而是要一次性烹饪多种菜肴,Spark 就像是一个高效的厨房助手。它能帮助你准备多个菜肴,同时又省时又省力。不同于传统的逐一烹饪方式,Spark 可以同时处理多种食材就如它在内存中快速处理大数据一样。因此,Spark 的作用就是通过提供快速而高效的计算方式,帮助我们在处理大量数据的同时,轻松获得所需的信息和结果。
前提准备
- 兼容性说明 注意:官网下载的Hive3.1.3和Spark3.3.1默认是不兼容的。因为Hive3.1.3支持的Spark版本是2.3.0,所以需要我们重新编译Hive3.1.3版本。
- 编译步骤 官网下载Hive3.1.3源码,修改pom文件中引用的Spark版本为3.3.1,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
- 在Hive所在节点部署Spark纯净版
Spark官网下载jar包地址:
http://spark.apache.org/downloads.html - 使用纯净版的原因:
spark提交任务到YARN上(RM , NM) RM负责接收,NM负责执行。而YARN上没有scala依赖来解析spark任务,需要从spark上载Scala依赖至HDFS,从HDFS下载至YARN(NM)上。而spark是基于MR(Hadoop),所以会一致上载Scala和Hadoop相关依赖,让YARN管理(自动上载和下载),导致和YARN上的Hadoop依赖相互冲突,所以使用spark纯净版可以解决这个冲突
# 上传并解压解压spark-3.3.1-bin-without-hadoop.tgz
tar -zxvf spark-3.3.1-bin-without-hadoop.tgz -C /opt/module/
# 重命名
mv /opt/module/spark-3.3.1-bin-without-hadoop /opt/module/spark
# 修改spark-env.sh配置文件
# 修改文件名。
mv /opt/module/spark/conf/spark-env.sh.template /opt/module/spark/conf/spark-env.sh
# 编辑文件
vim /opt/module/spark/conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
# 配置SPARK_HOME环境变量
vim /etc/profile
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=:$SPARK_HOME/bin$PATH
# source使其生效
source /etc/profile配置spark
# 在hive中创建spark配置文件
vim /opt/module/hive/conf/spark-defaults.conf
# 添加如下内容(在执行任务时,会根据如下参数执行)。
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
# 在HDFS创建如下路径,用于存储历史日志。
hadoop fs -mkdir /spark-history
# 向HDFS上传Spark纯净版jar包
# 说明1:采用Spark纯净版jar包,不包含hadoop和hive相关依赖,能避免依赖冲突。
# 说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
hadoop fs -mkdir /spark-jars
hadoop fs -put /opt/module/spark/jars/* /spark-jars修改hive-site.xml文件
vim /opt/module/hive/conf/hive-site.xml
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>启动Hive on Spark测试
#(1)启动hive客户端
hive
#(2)创建一张测试表
hive (default)> create table student(id int, name string);
#(3)通过insert测试效果
hive (default)> insert into table student values(1,'abc');成功标志
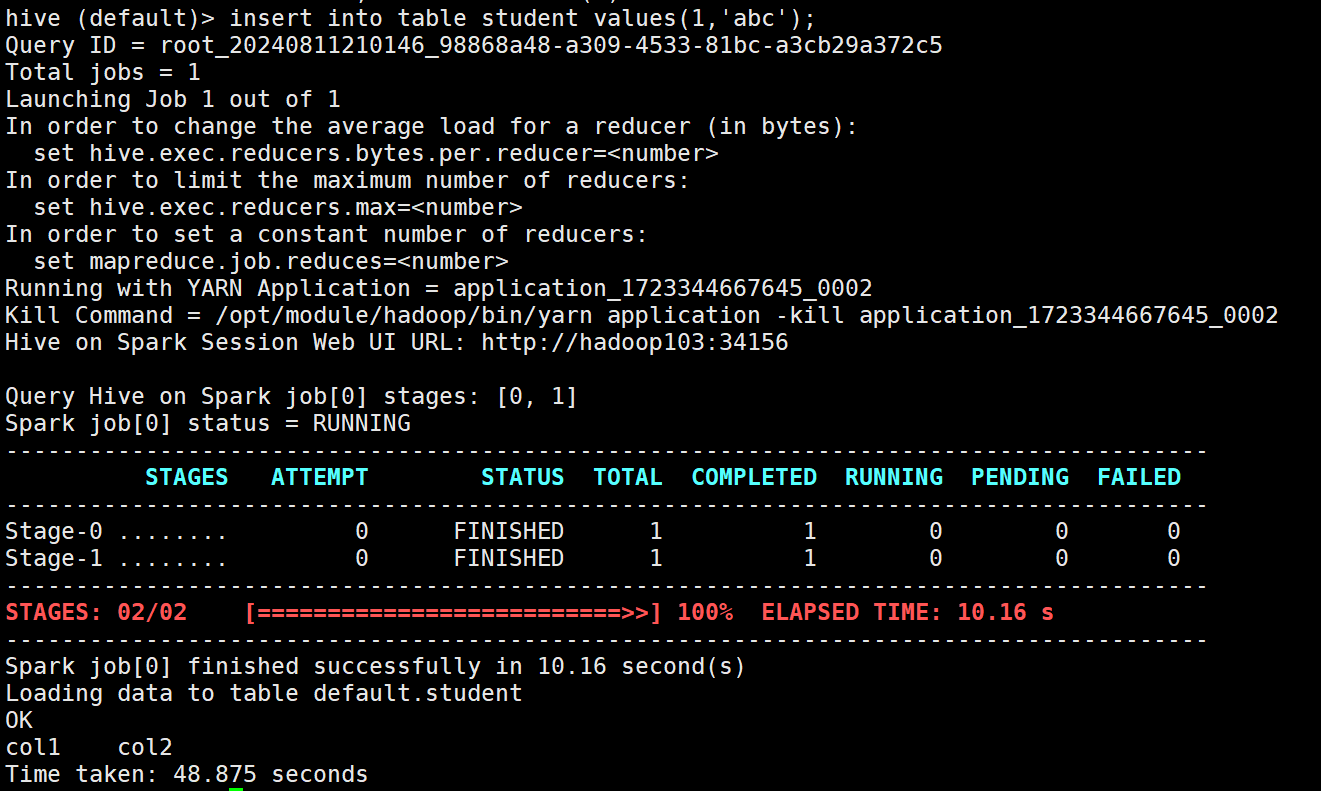
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号