大模型在蓝鲸运维体系应用——大模型在可观测的增强
原创

前言
可观测性是指对于一个软件系统的运行状态和行为是否可以被监测和分析。它涉及日志记录、性能指标收集、错误追踪等技术手段,用于帮助开发人员诊断和解决软件系统中的问题。
随着 5G、云计算和微服务等技术的深入融合与广泛应用,IT 系统架构正经历着从传统的单体架构向分布式架构乃至云原生架构的转型,这一过程使得企业所面临的 IT 运维环境变得愈发复杂。在这样的背景下,企业需要运维的系统不仅数量多,而且网络架构复杂、基础设施多样。可观测性建设是帮助工程师掌握复杂分布式系统运行状态、感知系统异常、故障定位、根因分析持续改善系统设计的必要手段。
但是在可观测性建设过程中也面临不少挑战:
1、全栈观测对象的数据接入能力
随着云原生、分布式技术的普及以及国产化的要求,越来越多的组件和对象开始涌现,对各种观测对象数据接入能力提出了更高的要求,要求具备灵活的扩展能力,快速低门槛地接入不同对象的数据采集。
2、复杂应用架构下有效的故障感知
以微服务、云原生架构为代表的现代应用架构,其多服务、容器化及云原生技术的特性,极大地增加了观测对象识别、观测能力覆盖及有效告警识别的挑战。在这种背景下,故障感知的方式发生了显著变化。传统的基于资源、状态、结果和趋势的黑盒感知能力已不足以满足现代应用架构的需求,需要扩展至应用层,实现面向单笔请求、单个用户的精确业务流量白盒观测能力。
3、多业务多技术领域高效的故障定位
在复杂业务领域及软件架构下,故障往往涉及多个业务系统、多个技术领域,故障责任边界不清、上下文传递低效、人员技能缺失是实现故障高效定位的难点。
4、打通观测处置联动加速故障处置
可观测体系建设识别问题、定位问题仅是业务连续性保障的第一步,类似人的眼睛接受外界信号后,经过大脑分析感知,做出应答处置进行问题闭环。因此,基于观测工具感知到的异常事件如何进行有效分析,如何打通后端运维处置工具触发有效故障分派及运维操作行为,加速故障闭环,是运维体系生态建设的关键壁垒。
5、故障根因追踪持续稳定改善
在故障突发时,工程师首要工作是定位故障边界、识别故障影响范围、快速故障恢复。因此,在进行重启或回滚操作后,错误代码逻辑或不合理配置等引发的故障根因仍然存在,如何回溯故障现场、分析故障、依赖关系确定问题根因并修复,从而持续改善稳定性是可观测建设的核心价值和建设难点。
随着大模型技术的出现,这一切挑战似乎又有了新的解题方向。
可观测领域的大模型应用场景探索
大模型技术在数据处理方面拥有非常明显的优势,正如本系列上一篇所述(☜点击回看):
语言理解:大模型通过训练可以理解和解释自然语言文本,能够回答问题、提供解释、理解指令和上下文含义等,并根据上下文语境进行进一步的计算分析。
知识总结:大模型可以提取文本知识的关键信息,进行统计分析,使得用户能够快速获取数据中的关键信息并进行分析。
文本生成:大模型可以根据上下⽂⽣成各种类型的文本,如正则表达式、采集脚本、清洗脚本等自动生成。
在这些优势的加持下,大模型技术在可观测领域的应用也有着非常不错的前景。而嘉为蓝鲸在大模型的应用方面,利用内部观测数据以及内部沉淀知识库对大模型进行训练,并结合在线大模型相结合的方式,在数据采集、数据清洗、数据统计、告警分析和处置等多个场景进行探索和落地。
场景一:数据采集
在可观测场景中,经常会有新的数据需要采集,可以通过 Exporter、脚本、SQL 等方式进行采集,从零开始进行代码编写往往需要耗费不少的时间,而大模型的代码编写能力刚好可以辅助进行代码编写,极大降低代码编写的成本。
编写 Exporter 插件:
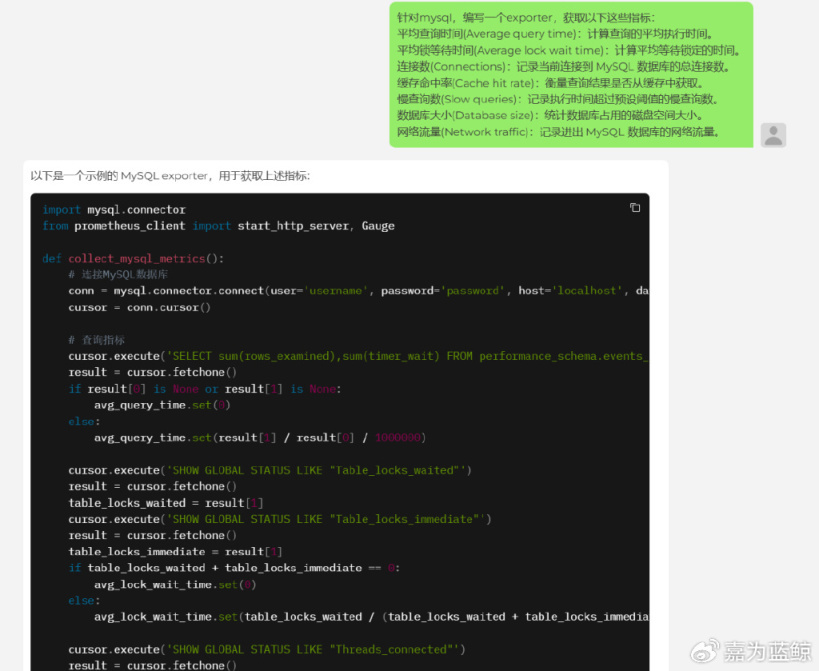
编写 Shell 脚本:
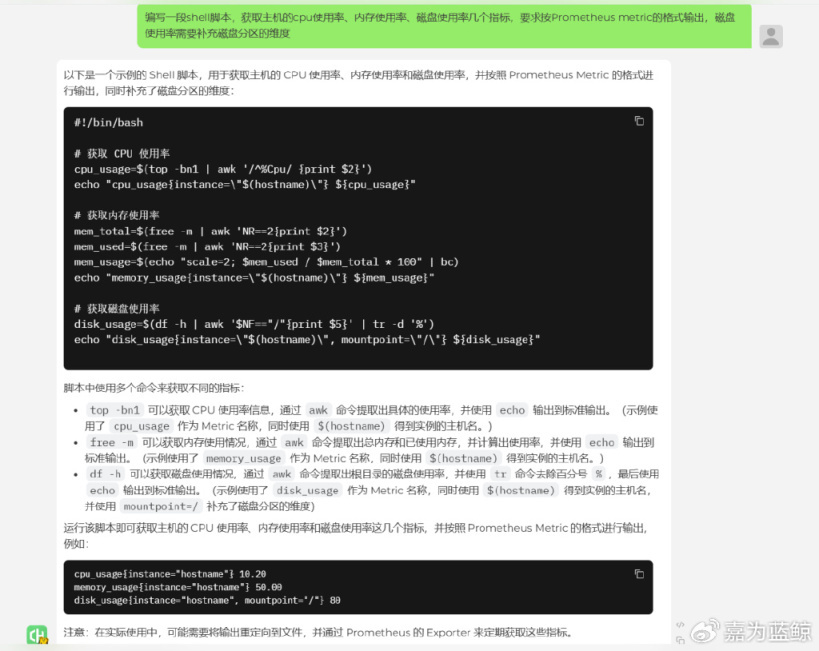
场景二:数据清洗
在可观测场景中,日志作为非结构化内容,为了提取有效信息,经常需要进行结构化处理,清洗出结构化字段,便于进一步分析,而大模型则可以快速编写正则进行日志清洗,而经过嘉为蓝鲸训练的大模型,可直接在日志产品的正则提取功能中使用。
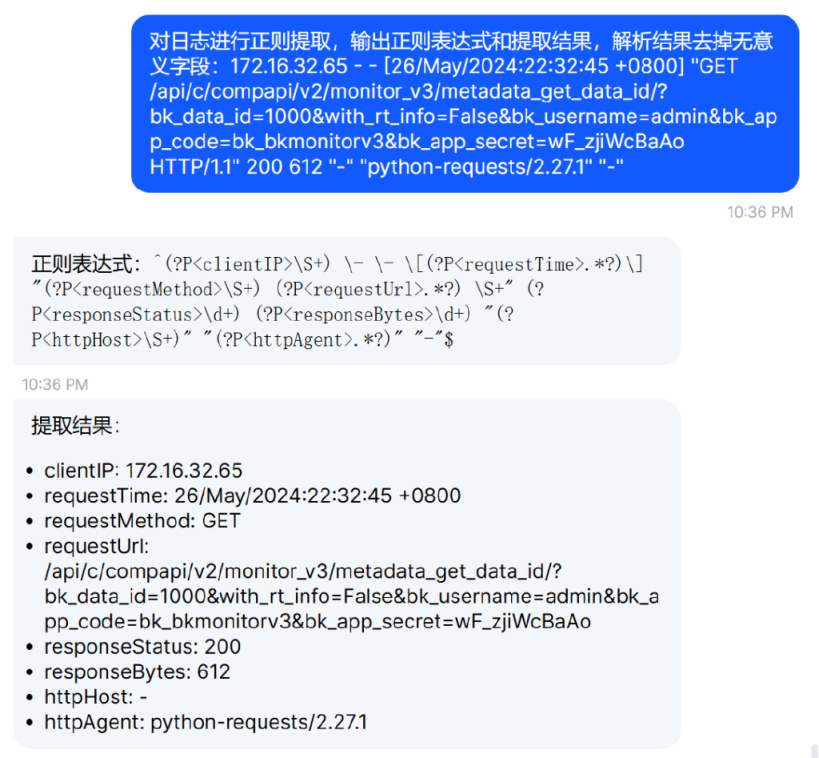
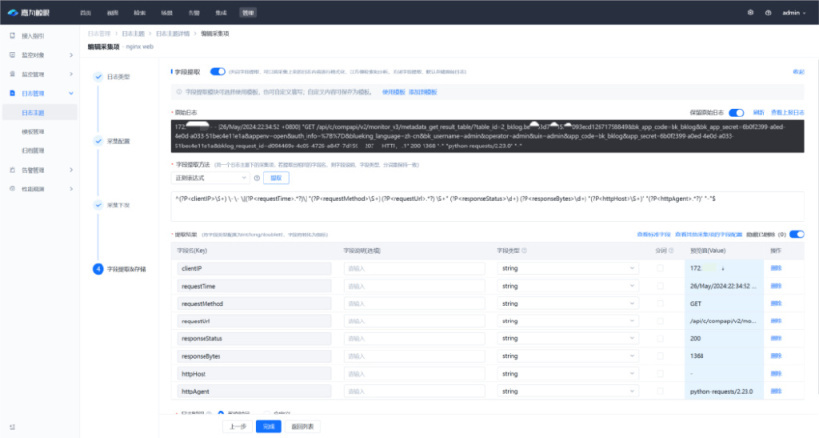
诸如此类的场景还有告警丰富提取规则编写,告警正则匹配规则编写,都可以使用大模型的正则清洗能力进行辅助。
场景三:数据统计
在可观测场景中,经常会有一些报表统计或者快速统计信息进行数据分析的场景,经过检验,可实现对指标、日志、告警等不同类型数据进行统计分析。
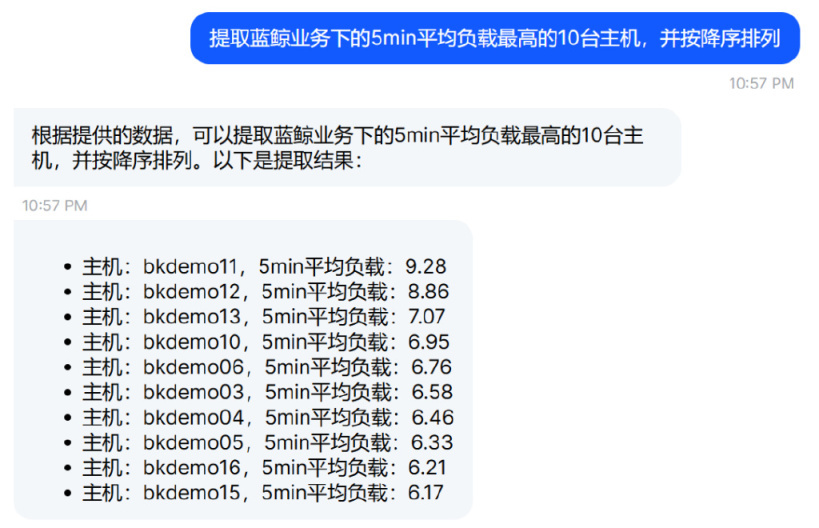
指标数据统计:各种指标数据排序统计分析,例如可快速获取 XX 业务的负载最高的 10 台主机。
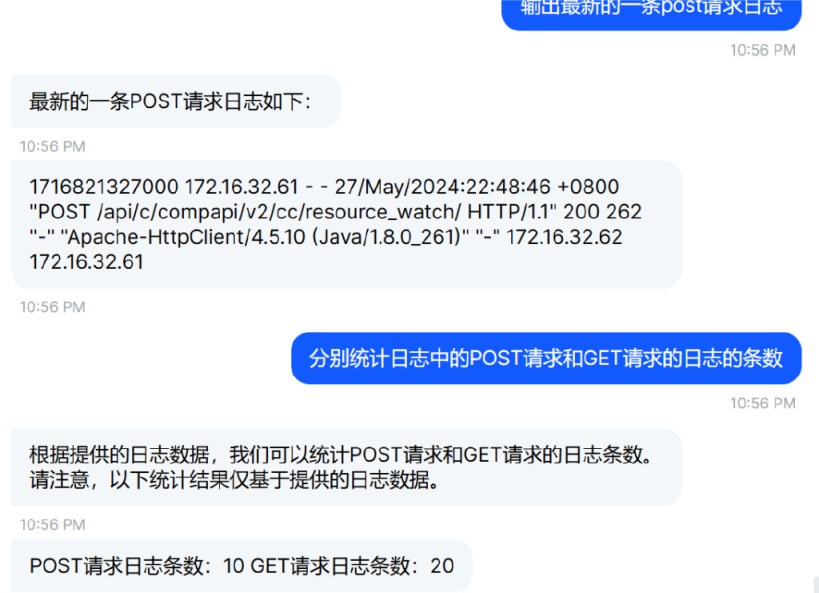
日志数据统计:例如对日志数据快速提取关键信息,对日志进行分类统计等场景
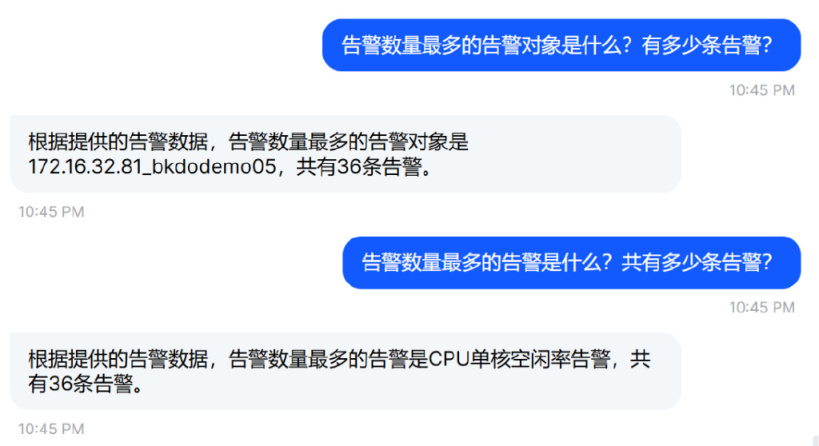
告警数据统计:对告警对象、告警数量等信息进行快速统计
场景四:告警分析和处置
在可观测场景中,最常见最麻烦的便是各种告警的处理,对人的要求非常高,门槛相对较高,主要体现在:
缺乏分步骤指引:故障处理的过程对于步骤的依赖性比较高,需要根据实际情况和上一步处理结果进行下一步操作,目前缺少适用的分步骤引导工具
手动获取故障信息不全面,一般故障处理需要监控信息、日志信息等数据,手动查找会遗漏
反复切换操作复杂:处理过程中,需要切换不同的平台执行脚本进行查询和修复,操作繁琐
而在大模型的辅助下,这些问题都将迎刃而解:可自动获取告警、资产、日志等相关信息,综合分析,并结合知识库的内容沉淀,自动进行引导进行故障分析和处理,甚至更进一步还能辅助编写处置脚本,降低告警处置门槛和成本。
展示告警关联数据详情,获取该告警对象的告警内容详细、告警数据库详情、关联服务器信息、关联日志信息等。
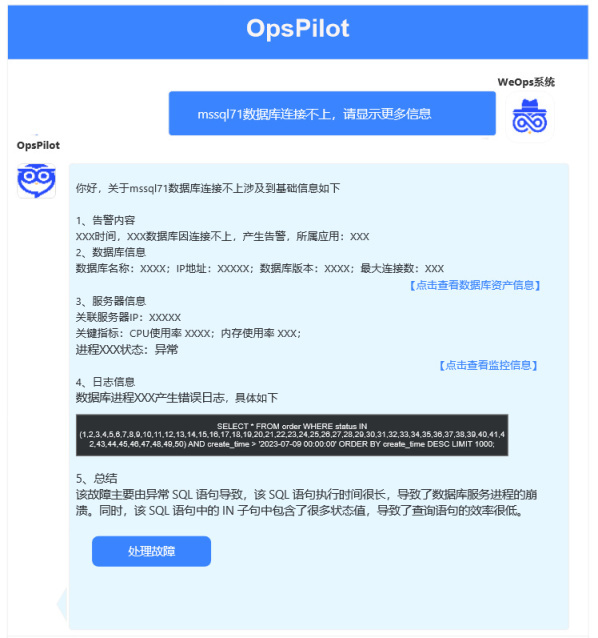
展示告警对象关联监控情况、查看告警的影响范围。
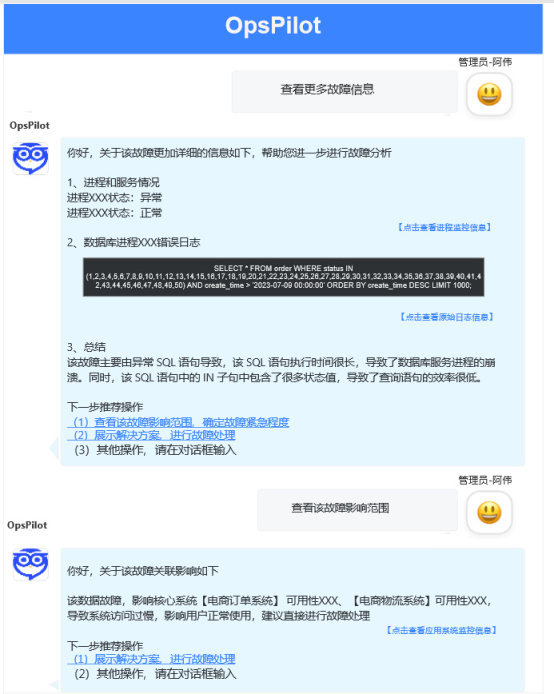
处置方案引导和执行,结合预置的解决方案和执行脚本,自动进行操作处置。
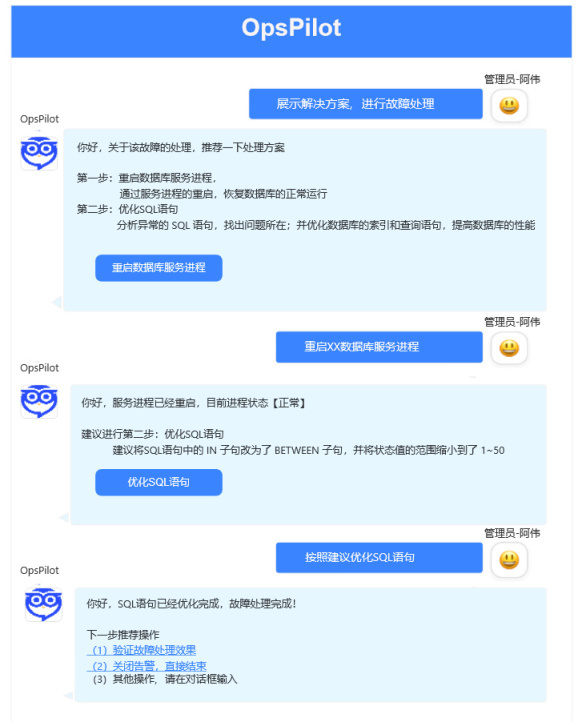
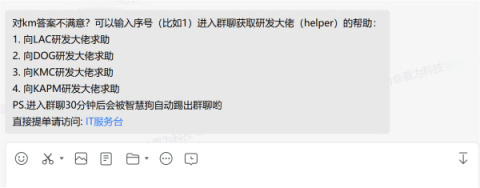
在嘉为蓝鲸内部结合内部知识库,已经实现对于故障问题进行知识库解决方案的自动推荐,并提供一键建群和提单功能,已真正带来业务价值,极大提高问题响应和解决效率。

未来展望
通过上述可观测+大模型的联合场景,已经充分体现了大模型魅力,可能在不久的将来,大模型不仅仅是一个观测辅助工具,而是能够自主分析定位问题,自主解决问题;甚至能够通过观测数据预测未来可能发生的问题,提前消除隐患预防问题的发生,真正实现观测从全面发现问题到快速处理问题再到提前预防问题的蜕变。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号