生信马拉松 Day8 GEO数据分析课程笔记
原创

今天又是干货满满的一天!
本日的主要内容是梳理GEO数据库分析的流程,一图总结如下:
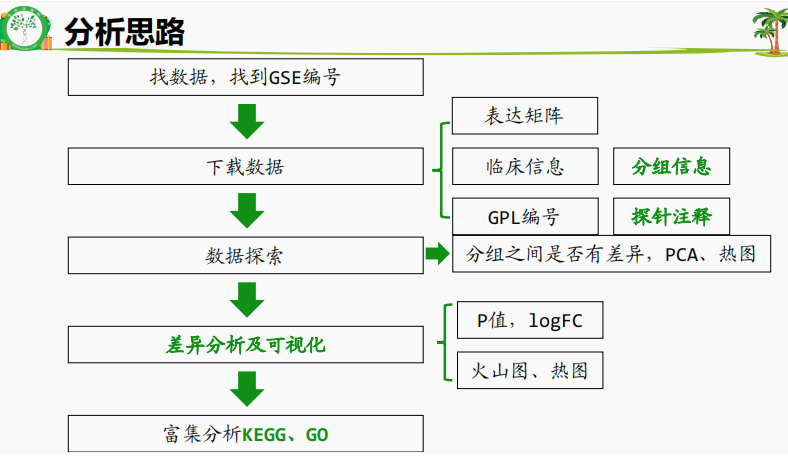
来自:生信技能树,生信马拉松,小洁老师
广义的基因有6w+个,包括lncRNA、miRNA等等,每年可能都有个别基因增增减减的情况,累计在一起,就存在基因库版本的差异,10年前查到的和今年的可能不一样,所以旧的数据仍然可以有新的解释,同一个数据集也可以在和其他数据集用不同的思路分析
我们的分析目的:寻找患者和对照组之间基因表达量差异
数据从哪来
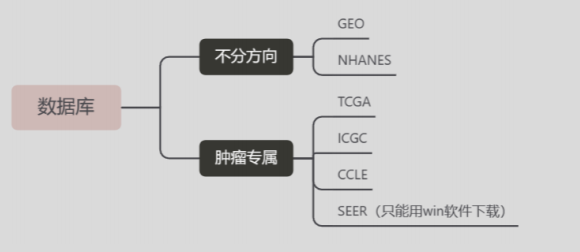
来自:生信技能树,生信马拉松,小洁老师
当数据分析能力到达一定程度,来源就只是来源,不影响分析的步骤
有什么类型的数据可挖掘
基因表达芯片、转录组、单细胞
共同特点:都是为了获取每个样本里基因的表达量多少(除了单细胞)
转录组相对高级,但是都照样用,原理和分析步骤略有差别
单细胞的分辨率更高,一列不再是样本而是细胞,因此用个人计算机处理可能存在算力不足的情况
当然生信不只是表达量数据,只是我们学习时往往从表达量开始
其他可以研究的内容包括但不限于:突变、表观
最后目标是筛选和我目标疾病相关的差异表达的基因
数据分析的步骤
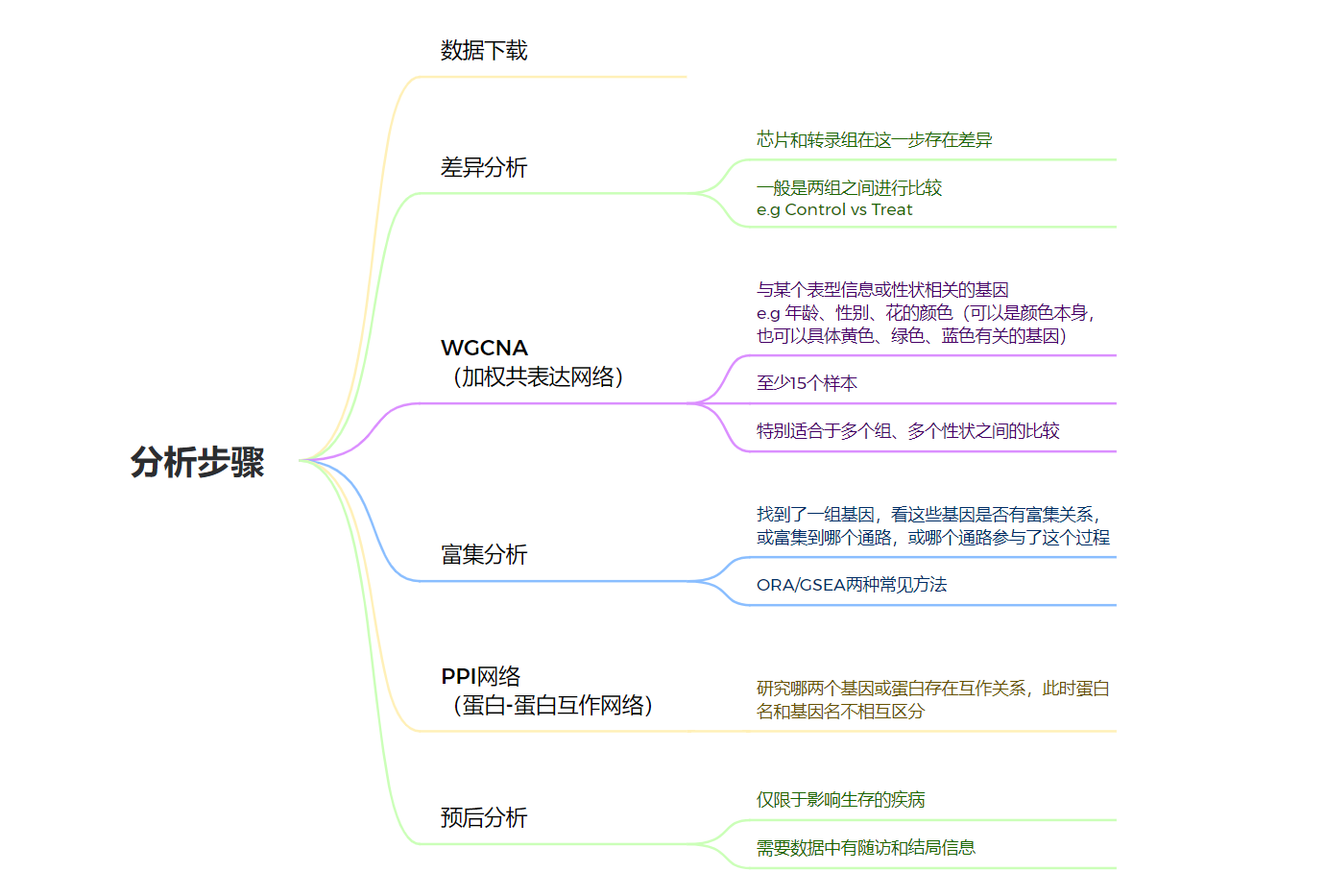
可以只做差异分析,也可以只做WGCNA,也可以都做取交集,主要是看得到的基因是否具有可解释性
常见图表
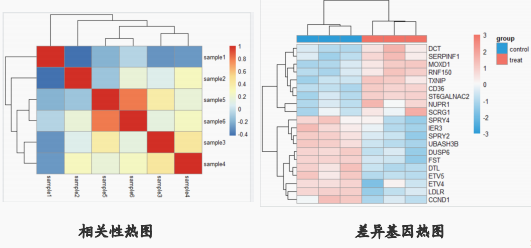
1.热图+聚类
输入数据是数值型矩阵/数据框
颜色的变化表示数值的大小
聚类默认是层次聚类,算法可以调整。算法不同可以让模棱两可内容结果发生差别,但不会让风马牛不相及的数据聚类在一起
相关性热图(相关系数在-1~1之间,你大我也大的关系,在0附近表示没有相关)
来自:生信技能树,生信马拉松,小洁老师
一般不画全部基因的热图,原因如下:
1.数据太大,画起来太费计算资源
2.没有必要,几万个基因里只有几十个到几千个表达存在差异,其余没有差异,如果全画,肉眼难以看到差别
2.散点图和箱线图
箱线图:输入数据是一个连续型向量和一个有重复值的离散型向量(分类型)
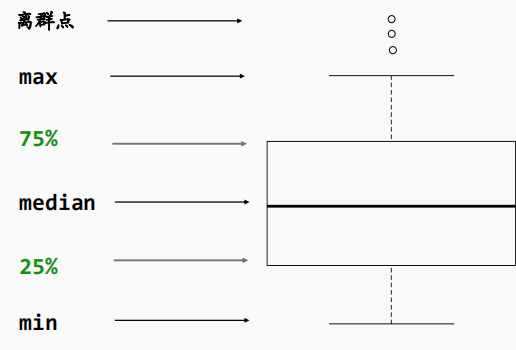
来自:生信技能树,生信马拉松,小洁老师
注意:箱线图的最大最小值有自己的计算方法,不是实际的最大最小值,最大最小值外可能存在离群值
箱线图适合展示一组数据的整体分布情况
5条线集中在一起,说明重复性好,数据集中
箱线图的实际用途:展示单个基因在两组之间的表达量差异
分组信息往往是单独提供的向量,注意需要分组信息和样本名一一对应
不一定需要先control、treat,但是分组一定要对应正确
3.多基因差异分析——火山图
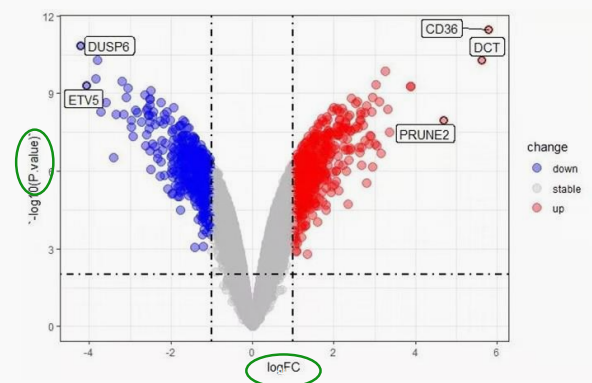
来自:生信技能树,生信马拉松,小洁老师
横坐标是logFC,纵坐标是-log10(P.value)
Foldchange(FC):处理组表达量平均值/对照组平均值
logFoldchange:FC取log2
芯片差异分析的起点是一个取过log的表达矩阵,如果拿到的是未log的矩阵,需要自行log

来自:生信技能树,生信马拉松,小洁老师
FC是对log后的数据取mean,mean(处理)-mean(对照),否则反了全错
logFC到达4和5已经是很大了,实际表达值差异已经是16倍和32倍
Inf是正无穷
一般logFC的范围在火山图是±10以内
取过log的数据,一般是在0~20以内,没取log的矩阵,会出现几千几百的数据
在火山图中,logFC>0,treat>control,基因表达量上升;logFC<0,treat<control,基因表达量下降
通常说的上调、下调基因是指表达量显著上升/下降的基因,也就是结合p值来看
每一次差异分析都需要界定阈值,是可以自己调的,阈值关系到差异基因大小
logFC的常见阈值:1/2/1.2/1.5/2.2/0.585=log2(1.5)
在基因数量特别少的时候,例如只用一条通路里的基因画火山图,可以不管logFC
p值常见取值:0.0001,0.001,0.01,0.1
p值越小,越有信心认为差异显著,-log10(P.value)越大
注意:研究的时候不会以对照组为主体,都是看treat组上调了还是下调了
4.主成分分析
PCA样本聚类图:每个点代表一个样本,没有量纲,距离越近相似程度越高
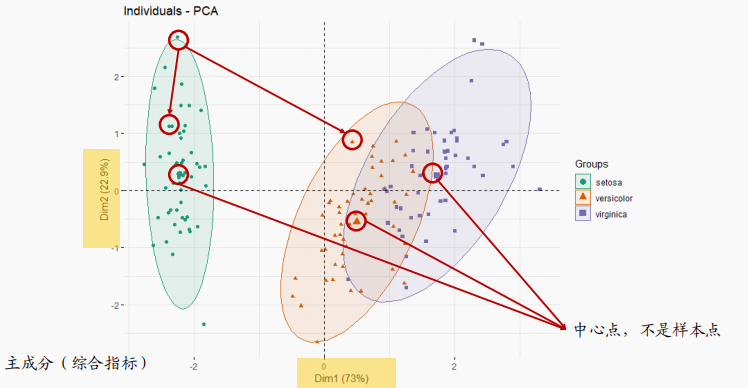
来自:生信技能树,生信马拉松,小洁老师
横纵坐标是主成分(也称为综合指标),每一个主成分由若干个基因组成
在数学中,要求前两个主成分对数据解释程度>90%,在生物学中这个数字不太重要,因为基因数量太多了一共几万个,PCA数据的结果很可能前3个加在一起也不够90%,所以一般不用管这个值
每个圆有一个比较大的中心点,是占位符,不是样本点,只有点没有圈也是正常的,此时代表样本量少
主成分分析,旨在利用降维的思想,把多指标转化为少数几个综合指标(即主成分)
实际用途:用于“预实验”,简单查看组间是否有差别
同一分组是否聚成一簇(组内重复好)
中心点之间是否有距离(组间差别大)
两个圈之间可以有重叠
GEO背景知识+表达芯片分析思路(首先学芯片的分析)
1.表达数据实验设计:通过基因表达量数据的差异分析和富集分析来解释生物学现象
有差异的材料——差异基因——找功能/找关联——解释差异,缩小基因范围
芯片有探针,转录组没有探针,探针的表达量代表基因的表达量,得到的是探针矩阵
探针是一组短的已知的核苷酸序列,探针对应的是什么基因是后续自己增加的
表达矩阵:行是探针id,少数时候是直接给基因,或者1,2,3,4,相应注释里也是1,2,3,4,列名为GSM样本编号
探针id最后需要转换为gene symbol
我们不关心单个样本,重要的是分组信息
数据分析需要的内容:
(1)数据范围:取过log,0~20之间,无异常值,如NA、Inf(这两个在GEO中不常见)负值(常见,需要处理),无异常样本(看箱线图确认)
(2)需要探针id注释:根据gpl编号查找;探针与基因之间的对应关系
(3)分组信息:同一个分组对应同一个关键词;顺序与表达矩阵的列一一对应;因子,对照组的levels在前
TIPS
如何在GEO中寻找自己感兴趣的数据?
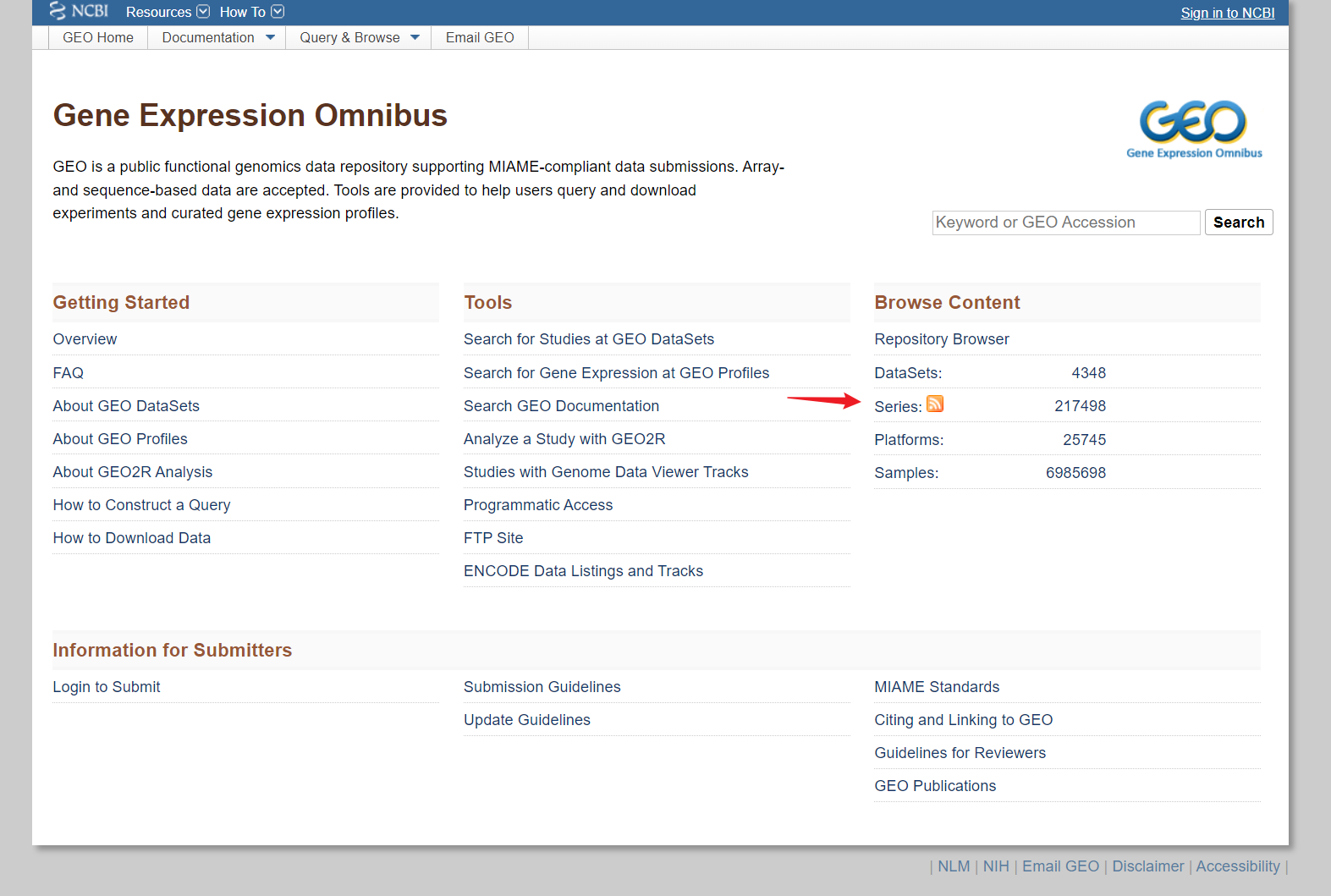
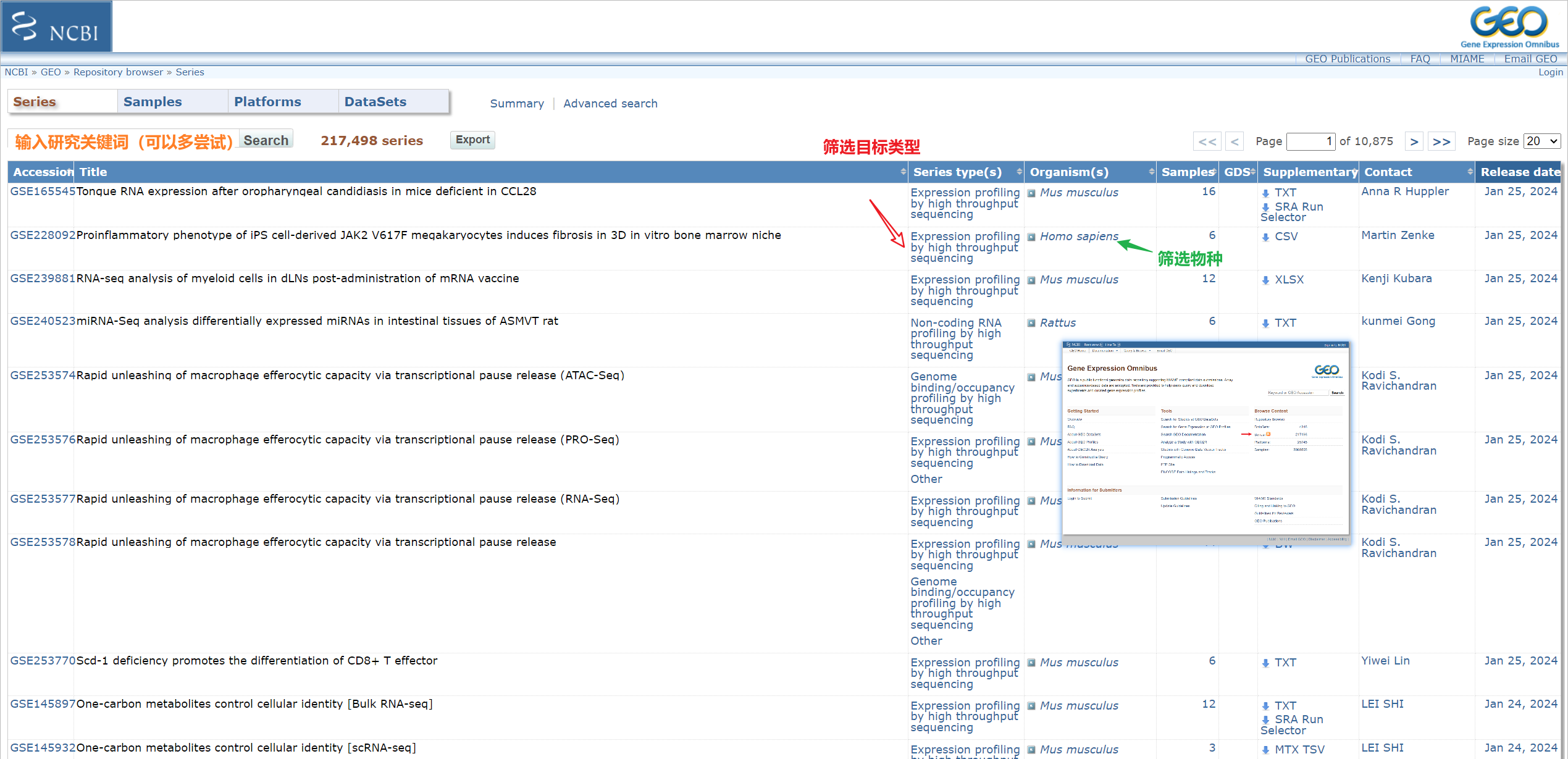
注意:不要选择少于6个样本的数据(每组至少3个,满足最小重复)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号