Spark性能优化调优
原创

1、SPARK-SQL优化三剑客:1内存2并发3CPU
1、内存: spark的dirver和executor内存及对应spark作业参数 涉及内存调优就三个参数:spark.driver.memory ,-executor-memory 和 spark.yarn.executor.memoryOverhead 2、并发:在 Spark 应用程序中,尽量避免不必要的 Shuffle 操作。例如,使用合适的转换操作(如 map、filter)来代替需要 Shuffle 的操作(如 reduceByKey)。 这样可以减少数据的传输和磁盘读写,提高并发性能及 SQL脚本 涉及并发优化就1个参数:spark.sql.shuffle.partitions 3、CPU:spark的executor的CPU核数和对应spark作业参数(不建议改) 涉及内存调优就1个参数:-executor-cores
1、发生GC,GC时间过长

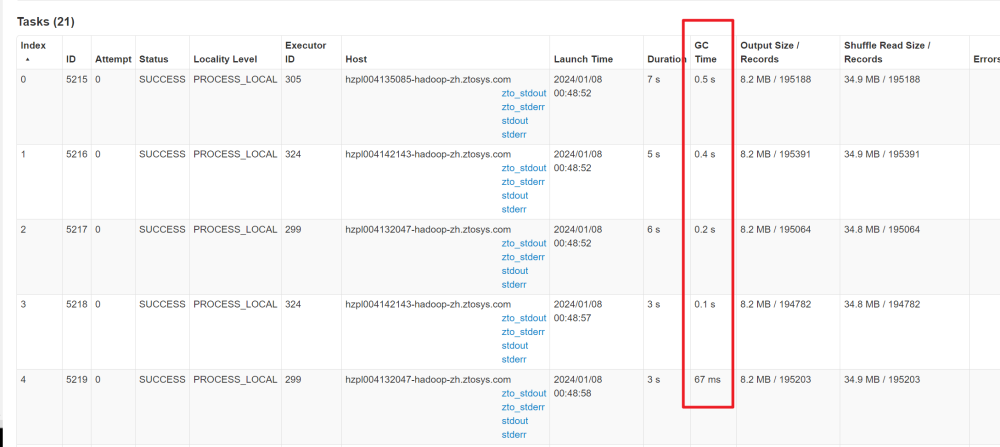
为了提高运行速度,盲目的将-executor-cores的数量调大,增加CPU核数,但是executor memory的大小不变,每个core的内存也就变小,导致内存不够产生GC,可以也将executor memory也调大些,或者将executor-cores数量调小
2、临时视图或者串行跑任务,任务速度调优
很多时候我们的SQL中会出现许多的临时视图的情况
create temporary view a as
select xxx;
create temporary view b as
select xxx;
insert overwrite table c as
select
xxx
from
a join weidu
union all
b join weidu
group by xxx;
如果数据量比较小,那么这样操作是没什么问题的,如果数据量比较大,那么就会因为a视图计算完之后,存储在内存中,到b视图计算的时候有可能会因为内存不够导致shuffle溢写,速度就会下降许多。
此处可以的优化,将这个任务拆分成三个任务,a和b并行跑,结束跑c的任务。这样的话可以提高整体的效率,相当于利用空间换时间。
因为在做一些调优,这个花费的时间比较长,join也是不可去避免的,只能去进行一个拆分并行计算的方法。
或者在a/b的操作的时候进行提前预聚合,也可以避免一些数据倾斜的问题
3、关联的时候将大表放到左边,小表放到右边
这个是小表join大表,大表缓存造成oom
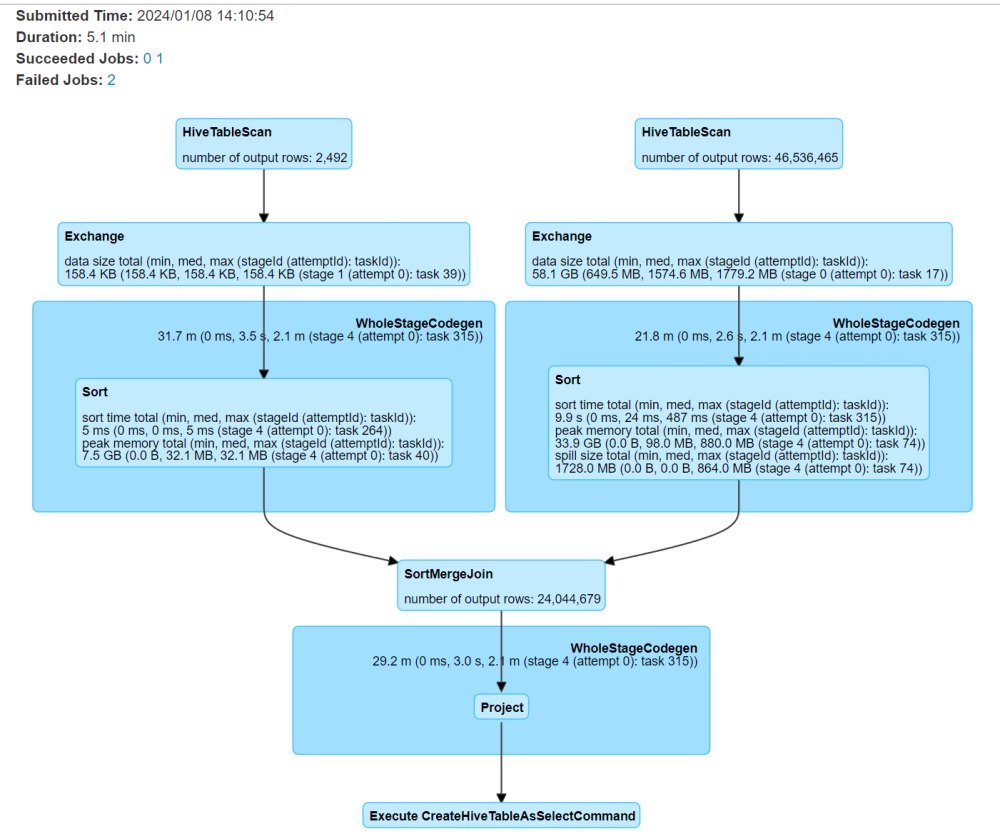

代码一样,看大表join小表
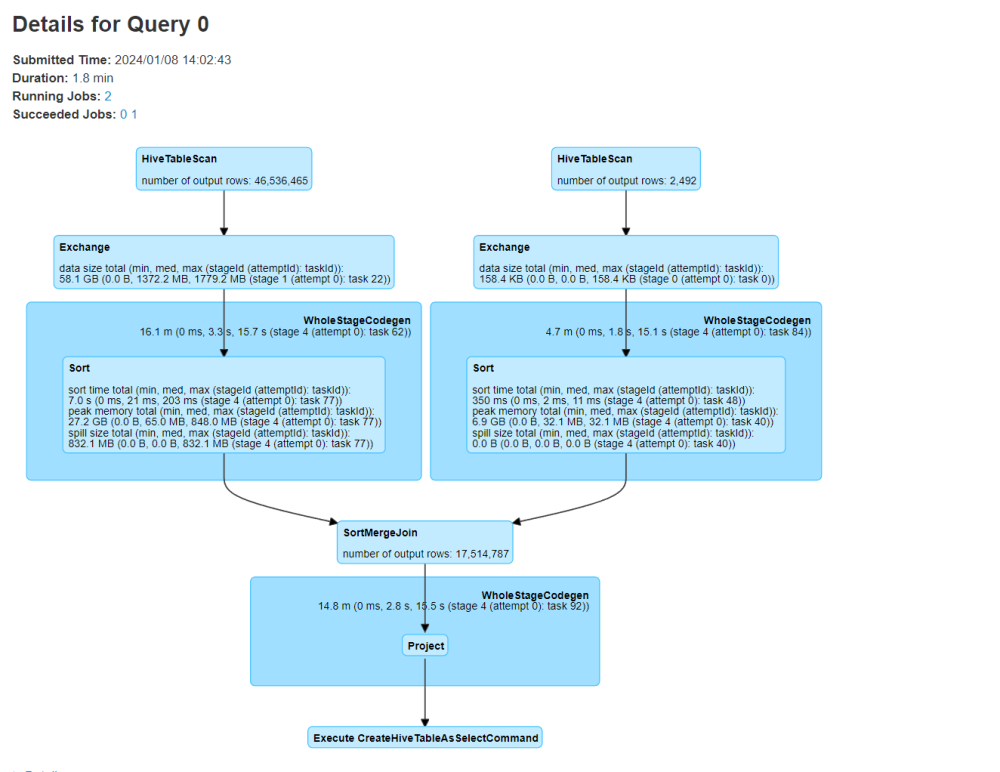
1、其实在对表关联的时候小表驱动大表的时候还是注意下大表是否是被缓存不然或许会起到反作用。这个是需要注意关联条件
2、广播join,将右边的小表缓存到内存中,避免shuffle的情况
4、Spark,lateral view explode。任务优化问题
select
xxx
from
( a,b on a.mid=b.mid ) a
lateral view explode x as xxx
先关联,产生shuffle数据,根据配置的partition分区,然后再进行炸开。假如默认有200个分区,那么之后进行操作的炸开也就只有200个文件去执行,数据量本身比较大,又按照分区的200去合并,会导致数据更大。
select
xxx
from
(
select
xxx
from a
lateral view explode x as xxx
) a join b
先去做炸开,然后去关联去重。炸开的时候是按照读取a表的文件数量,在炸开的时候任务执行很快,炸开之后进行关联,然后按照shuffle partition的数量分区
5、多个开窗在一起,任务执行stage单个串行执行
select
mid,
row_number() over(partition by expose order by expose),
row_number() over(partition by click order by click),
row_number() over(partition by order order by order),
row_number() over(partition by sale order by sale)
from
(
select
mid,
sum(expose) expose,
sum(click) click,
sum(order) order,
sum(sale) sale
from
(
select
'1' mid,
1 expose,
2 click,
3 order,
4 sale
) a
group by
mid
) t
这种执行下来会让流程很长,任务是串行的所以执行时间也会很长优化方案:
select
mid,
sum(expose_rn) as expose_rn,
sum(click_rn) as click_rn,
sum(order_rn) as order_rn,
sum(sale_rn) as sale_rn
from
(
select
mid,
row_number() over(partition by expose order by expose) as expose_rn,
0 as click_rn,
0 as order_rn,
0 as sale_rn
from
(
select mid, sum(expose) expose from ( select '1' mid, 1 expose ) a group by mid
) t
union all
select
mid,
0 as expose_rn,
row_number() over(partition by click order by click) as click_rn,
0 as order_rn,
0 as sale_rn
from
(
select mid, sum(click) click from ( select '1' mid, 1 click ) a group by mid
) t
union all
select
mid,
0 as expose_rn,
0 as click_rn,
row_number() over(partition by order order by order) as order_rn,
0 as sale_rn
from
(
select mid, sum(order) order from ( select '1' mid, 1 order ) a group by mid
) t
union all
select
mid,
0 as expose_rn,
0 as click_rn,
0 as order_rn,
row_number() over(partition by sale order by sale) as sale_rn
from
(
select mid, sum(sale) sale from ( select '1' mid, 1 sale ) a group by mid
) t
) a group by mid
其本质就是让一个task执行的变成多个task执行 这样会极大地缩短任务进程时间,可以很好地优化
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号