Day09 生信马拉松-GEO数据挖掘 (中)
原创
Day09 生信马拉松-GEO数据挖掘 (中)
原创
大冬仔
修改于 2023-08-19 17:18:47
修改于 2023-08-19 17:18:47
文章所有内容均来自生信技能树“生信马拉松-数据挖掘班”授课内容个人整理,如需转载请注明出处。
1.如何进行实验分组
#######前期准备#######
rm(list = ls())
load(file = "step1output.Rdata")
# 1.Group----
library(stringr)
# 标准流程代码是二分组
# 生成Group向量的三种常规方法,三选一,选谁就把第几个逻辑值写成T,另外两个为F。如果三种办法都不适用,可以继续往后写else if
if(F){
# 第一种方法,直接查看data.frame用现成的可以用来分组的列--不一定可以找出
}else if(F){
# 第二种方法,眼睛数,自己生成--仅适用排列有序,每种分组都在一起
Group = rep(c("Disease","Normal"),each = 10)
}else if(T){
# ★★第三种方法,使用字符串处理的函数获取分组--适用范围最广,优先选择★★
k = str_detect(pd$title,"Normal");table(k)
Group = ifelse(k,"Normal","Disease")
}
# 需要把Group转换成因子,并设置参考水平,指定levels,对照组在前,处理组在后
Group = factor(Group,levels = c("Normal","Disease")) #第一个是对照组,第二个是处理组,不可标记反!!
Group2.如何进行芯片探针注释
2.1 探针注释的来源
①Biocoductor的注释包
②GPL的表格文件解析
③官网下载对应产品的注释表格
④自主注释
PS.不是所有GPL都能找到注释!!
2.2 探针注释的实操流程
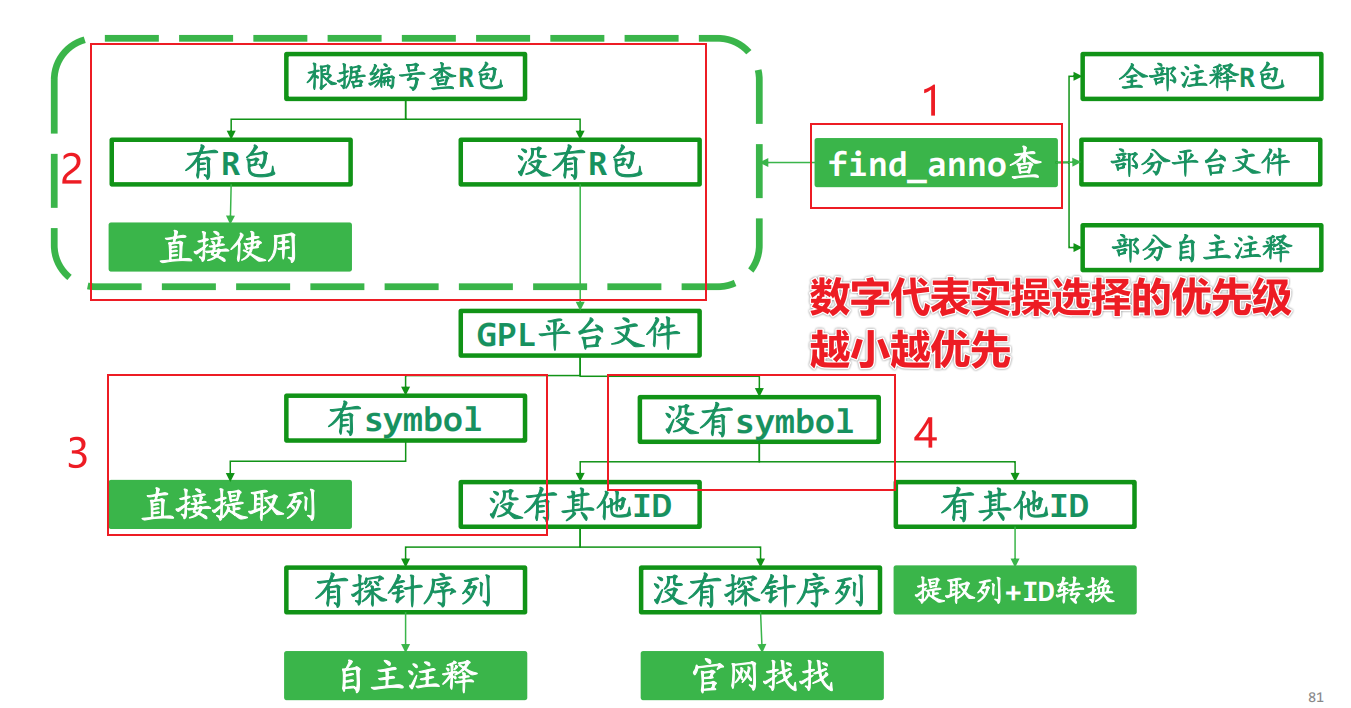
#捷径—首选选择该方法
if(T){
library(tinyarray)
find_anno(gpl_number) # 寻找注释的函数,此处的“gpl_number” 是在"step1output.Rdata"中生成的向量,无需替换,也可用'GPLxxxxx'
ids <- AnnoProbe::idmap('GPL17692')
# 如果AnnoProbe::idmap() 报错,对type进行标注—查看帮助文案
ids <- AnnoProbe::idmap('GPL17692',type = "soft")#是复制的
}
##如果捷径的方法可行则无需运行以下四种方法,从方法1开始逐个往后。##
#方法1 BioconductorR包(最常用)
if(T){
'GPL32737'
#http://www.bio-info-trainee.com/1399.html 查询GPL对应的R包
if(!require(hgu133plus2.db))BiocManager::install("hgu133plus2.db")
library(hgu133plus2.db)
ls("package:hgu133plus2.db")
ids <- toTable(hgu133plus2SYMBOL)
head(ids)
}
# 方法2 读取GPL网页的表格文件,按列取子集——需要解读表格才用的代码
##https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL570 先下载GPL对应的txt到本地文件
if(F){
#注:表格读取参数、文件列名不统一,活学活用,有的表格里没有symbol列,也有的GPL平台没有提供注释表格
b = read.delim("GPL570-55999.txt",
check.names = F,
comment.char = "#")
colnames(b)
ids2 = b[,c("ID","Gene Symbol")] #名字从colnames(b)输出结果中复制,防止输入错误
colnames(ids2) = c("probe_id","symbol") #修改行名
k1 = ids2$symbol!="";table(k1) #去除注释的空格
k2 = !str_detect(ids2$symbol,"///");table(k2) #去除非特异性探针格子
ids2 = ids2[ k1 & k2,]
# ids = ids2
}
# 方法3 官网下载注释文件并读取
# 方法4 自主注释
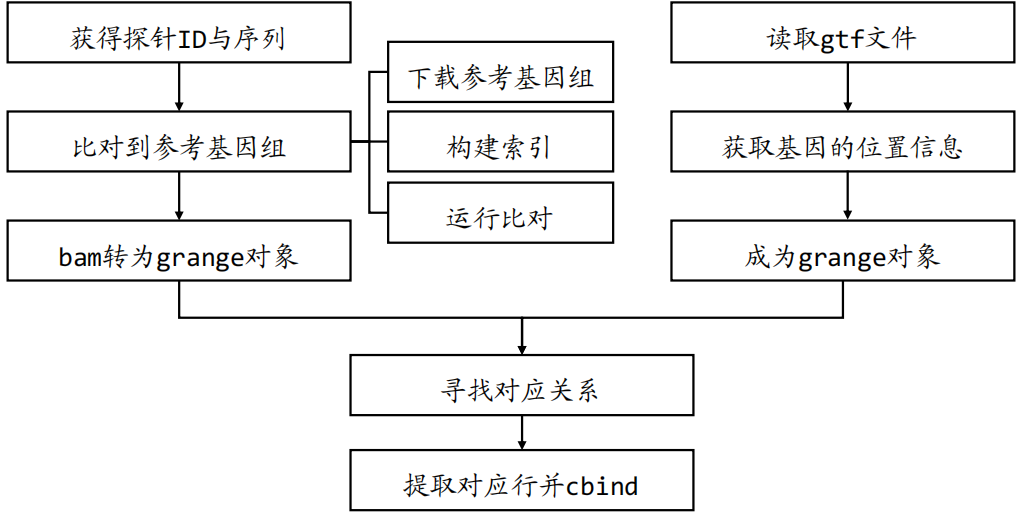
#https://mp.weixin.qq.com/s/mrtjpN8yDKUdCSvSUuUwcA
save(exp,Group,ids,file = "step2output.Rdata")自主注释流程--了解即可
3.PCA与heatmap的绘制
3.1 PCA图
######清空环境,加载需要的数据######
rm(list = ls())
load(file = "step2output.Rdata")#输入数据:exp和Group
#Principal Component Analysis(PCA的全称)
#http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/112-pca-principal-component-analysis-essentials
#PCA的不同呈现方式可在上面链接中查找,先用示例数据确保能运行,再根据实际需要进行调参
# PCA 图操作代码
dat=as.data.frame(t(exp)) #将matrix形式的exp转换为data.frame
library(FactoMineR)
library(factoextra)
dat.pca <- PCA(dat, graph = FALSE)
fviz_pca_ind(dat.pca,
geom.ind = "point", # show points only (nbut not "text")
col.ind = Group, # color by groups
palette = c("#00AFBB", "#E7B800"),
addEllipses = TRUE, # Concentration ellipses
legend.title = "Groups"
)3.2 heatmap
# 绘制top 1000 sd 热图----
cg = names(tail(sort(apply(exp,1,sd)),1000)) #嵌套型代码写法
#管道符代码写法
library(tidyr)
library(tibble)
library(dplyr)
cg = apply(exp,1,sd) %>%
sort() %>%
tail(1000) %>%
names()
n = exp[cg,]
# 直接画热图---色彩对比不鲜明
library(pheatmap)
annotation_col = data.frame(group=Group) #写列的注释信息
rownames(annotation_col) = colnames(n) #写行的注释信息
pheatmap(n,
show_colnames =F, #不显示行名
show_rownames = F, #不显示列名
annotation_col=annotation_col #根据分组映射颜色
)
# 按行标准化
pheatmap(n,
show_colnames =F,
show_rownames = F,
annotation_col=annotation_col,
scale = "row", #基因只在样本间对比,不跨行与其他基因对比
breaks = seq(-3,3,length.out = 100) #从-3到3生成100个颜色,让颜色对比更鲜明 “length.out = 100”为颜色范围
)
dev.off()拓展内容:归一化函数—
scale()scale函数是按列归一化,对于我们一般习惯基因名为行,样本名为列的数据框,就需要
t()转置
cor()函数求相关系数的时候也是按列计算,如果计算行之间的相关系数也需要对矩阵进行t()转置参考资料:scale函数对矩阵归一化是按行归一化,还是按列归一化?
以上内容均引用自生信技能树
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号