总览
TI-ONE 大模型训推平台提供性能评测模板功能,用户可以在 模型服务 > 模型评测 > 配置管理 中创建评测集、性能评测模板,同时支持创建基线标准,可在评测中选择基线进行对比。
本实践对 Qwen3-4B 模型进行多并发压测,包括“短文本1K”、“中文本3.5K” 两个文本长度评测配置。实践总体步骤如下:
在实践过程中如果产生疑问可参考以下文档:
创建并管理评测集、评测模板、基线标准相关教程可参见 配置管理。
进行性能评测时,创建性能评测任务相关教程可参见 性能评测。
评测集格式要求可参见 评测集格式要求。
前置准备
1. 准备评测数据集
本教程需要通过数据处理准备两个评测数据集、两个预热数据集共四个数据集,介绍如下:
短文本评测数据 eval_1k.jsonl:模拟短文本场景(约900 ~ 1100 tokens)压测,共200条
短文本预热数据 eval_1k_warmup.jsonl:短文本压测前预热,共20条
中文本评测数据 eval_3_5k.jsonl:模拟中等长度文本场景(约3200 ~ 3800 tokens)压测,共150条
中文本预热数据 eval_3_5k_warmup.jsonl:中文本压测前预热,共20 条
1.1 创建开发机
镜像可选择“内置通用镜像 > py3.10-cpu”,也可根据需求选择其他版本内置镜像
机器来源可选自有的资源组 或者 通过从 TIONE 平台购买,选择 2C4G 及以上资源即可

单击确定完成创建,可在列表查看创建的开发机,单击打开可进入开发机。

1.2 下载原始数据及分词器
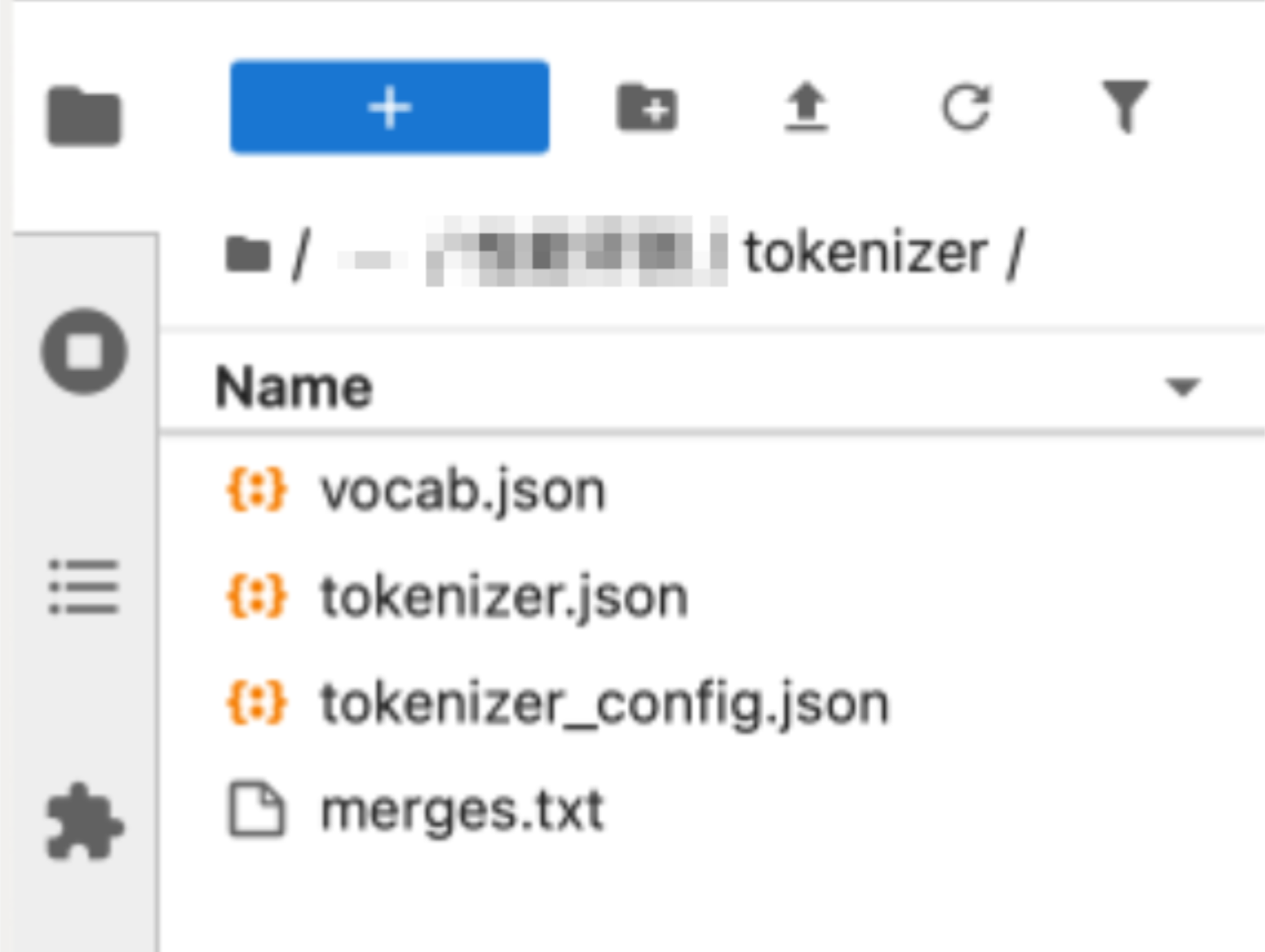
在开发机中新建”tokenizer“文件夹,点击下载 分词器文件 vocab.json、tokenizer.json、tokenizer_config.json、merges.txt 并上传至文件夹。
1.3 进行数据处理
新建 Notebook,运行以下代码。
import jsonfrom transformers import AutoTokenizerTOKENIZER_PATH = "./tokenizer"tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)# ── 正式评测集配置 ──────────────────────────────────────────TARGETS = {"eval_1k": {"min": 900, "max": 1100, "count": 200, "results": []},"eval_3_5k": {"min": 3200, "max": 3800, "count": 150, "results": []},}# ── 预热评测集配置 ──────────────────────────────────────────WARMUP_COUNT = {"eval_1k": 20,"eval_3_5k": 20,}# ── 读取原始数据 ────────────────────────────────────────────print("开始读取 Belle_open_source_0.5M.json ...")items = []with open('评测数据集/Belle_open_source_0.5M.json', 'r', encoding='utf-8', errors='ignore') as f:for i, line in enumerate(f):line = line.strip()if not line:continuetry:item = json.loads(line)except json.JSONDecodeError:continueinstruction = item.get('instruction', '').strip()inp = item.get('input', '').strip()# 压测只需要 prompt,不要 outputuser_text = (instruction + '\\n' + inp).strip() if inp else instructionif not user_text:continuetoken_count = len(tokenizer.encode(user_text))items.append((user_text, token_count))if i % 50000 == 0:print(f" 已读取 {i} 条...")print(f"共读取 {len(items)} 条,开始按档位拼接筛选...")# ── 生成正式评测集 ──────────────────────────────────────────# 预热从短到长,正式压测也建议从短到长for key in ["eval_1k", "eval_3_5k", "eval_16k"]:cfg = TARGETS[key]i = 0while i < len(items) and len(cfg["results"]) < cfg["count"]:combined_text = items[i][0]combined_tokens = items[i][1]j = i + 1while combined_tokens < cfg["min"] and j < len(items):combined_text += "\\n" + items[j][0]combined_tokens += items[j][1]j += 1if cfg["min"] <= combined_tokens <= cfg["max"]:cfg["results"].append({"messages": [{"role": "user", "content": combined_text.strip()}]})i = jprint(f" {key}:{len(cfg['results'])} 条")# ── 保存正式评测集 ──────────────────────────────────────────for key, cfg in TARGETS.items():path = f'评测数据集/{key}.jsonl'with open(path, 'w', encoding='utf-8') as f:for item in cfg["results"]:f.write(json.dumps(item, ensure_ascii=False) + '\\n')print(f"已保存正式评测集:{path}({len(cfg['results'])} 条)")# ── 生成并保存预热评测集 ────────────────────────────────────print("\\n开始生成预热评测集...")for key, n in WARMUP_COUNT.items():src_path = f'评测数据集/{key}.jsonl'warmup_path = f'评测数据集/{key}_warmup.jsonl'samples = []with open(src_path, 'r', encoding='utf-8') as f:for i, line in enumerate(f):if i >= n:breaksamples.append(json.loads(line))with open(warmup_path, 'w', encoding='utf-8') as f:for item in samples:f.write(json.dumps(item, ensure_ascii=False) + '\\n')print(f"已保存预热评测集:{warmup_path}({len(samples)} 条)")print("全部完成")
运行结果如下:

生成以下4个文件,记录文件路径

2. 准备待评测模型
详细步骤
步骤一:创建用户自定义评测集
1. 登录 TI-ONE 控制台,在左侧导航栏中选择 模型服务 > 模型评测。
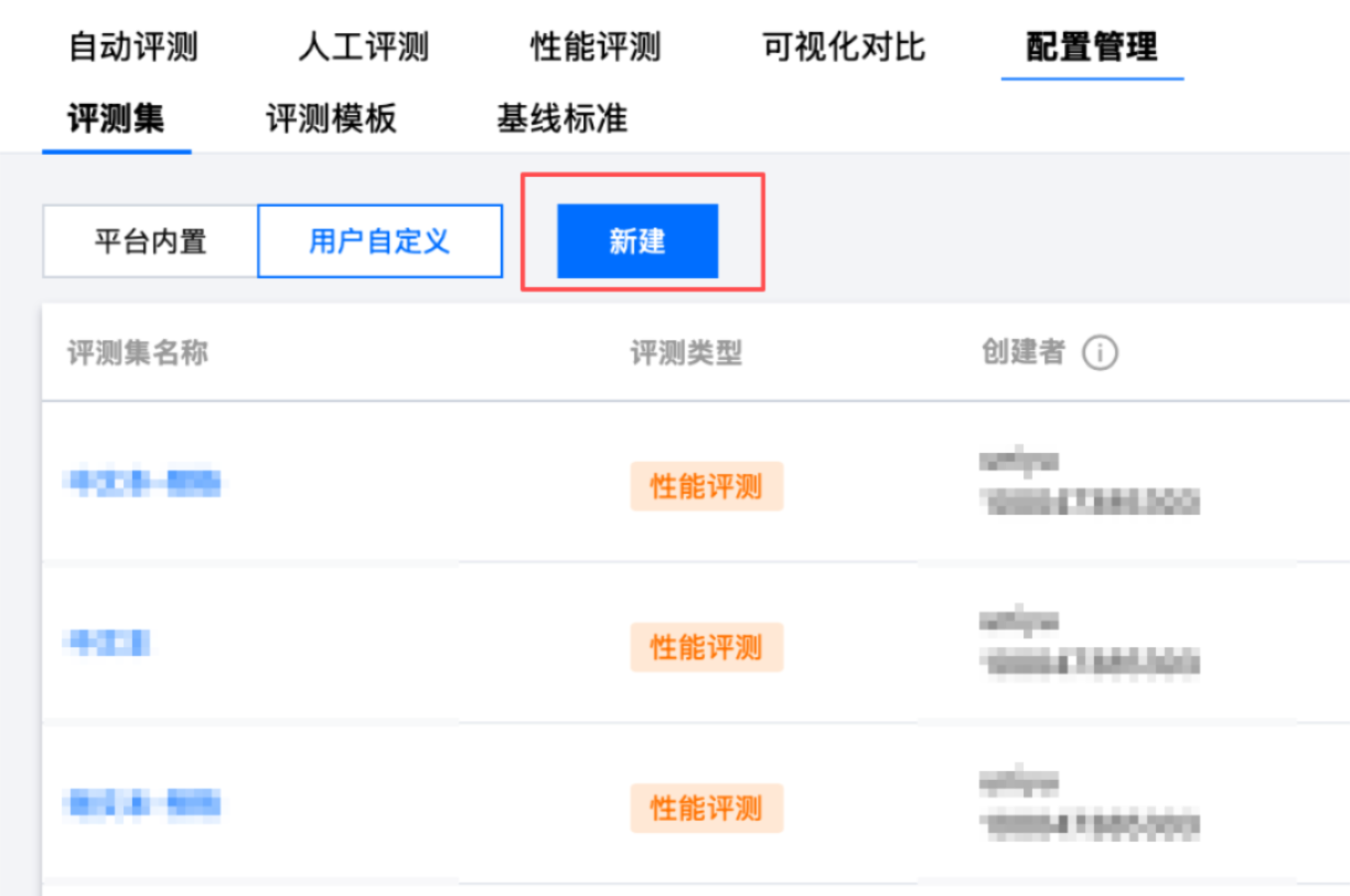
2. 单击 配置管理 Tab 页,选择评测集 > 用户自定义,单击新建。
3. 按照表格填写如下数据,创建短文本4. 数据集:
字段 | 说明 | 填写示例 |
评测类型 | 选择“性能评测” |  |
数据来源 | 选择“从 CFS 中选择评测集” | |
CFS 文件系统、评测集路径 | 填写短文本数据存储的 CFS 路径 | |
评测集名称 | 可填“短文本” | |
推理超参设置 | 可维持默认设置 | |
评测指标 | 可不选 | |
负责人 | 可选自己,也可根据实际情况选择 | |
按照表格填写如下数据,创建短文本评测配置的预热数据集:
字段 | 说明 | 填写示例 |
评测类型 | 选择“性能评测” |  |
数据来源 | 选择“从 CFS 中选择评测集” | |
CFS 文件系统、评测集路径 | 填写短文本预热数据存储的 CFS 路径 | |
评测集名称 | 可填“短文本-预热” | |
推理超参设置 | 可维持默认设置 | |
评测指标 | 可不选 | |
负责人 | 可选自己,也可根据实际情况选择 | |
按照表格填写如下数据,创建中文本数据集:
字段 | 说明 | 填写示例 |
评测类型 | 选择“性能评测” |  |
数据来源 | 选择“从 CFS 中选择评测集” | |
CFS 文件系统、评测集路径 | 填写中文本数据存储的 CFS 路径 | |
评测集名称 | 可填“中文本” | |
推理超参设置 | 可维持默认设置 | |
评测指标 | 可不选 | |
负责人 | 可选自己,也可根据实际情况选择 | |
按照表格填写如下数据,创建中文本评测配置的预热数据集:
字段 | 说明 | 填写示例 |
评测类型 | 选择“性能评测” |  |
数据来源 | 选择“从 CFS 中选择评测集” | |
CFS 文件系统、评测集路径 | 填写中文本预热数据存储的 CFS 路径 | |
评测集名称 | 可填“中文本-预热” | |
推理超参设置 | 可维持默认设置 | |
评测指标 | 可不选 | |
负责人 | 可选自己,也可根据实际情况选择 | |
4. 单击确定,可在评测集列表中查看新建的评测集信息。

步骤二:创建基线标准
1. 单击 配置管理 Tab 页,选择基线标准,单击新建。
2. 按照表格填写如下数据:
字段 | 说明 | 填写示例 |
基线标准名称 | 可填“Qwen3_4B-基准” | 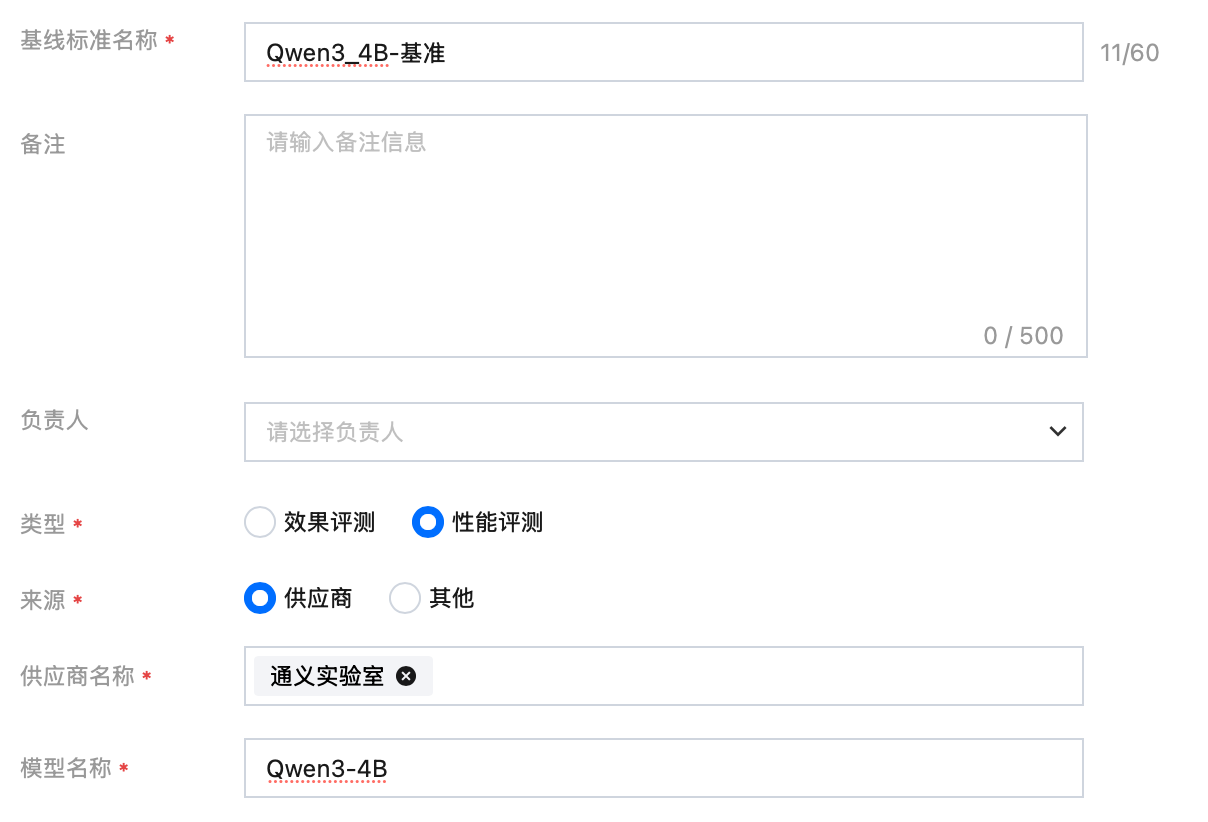 |
负责人 | 可选自己,也可根据实际情况选择 | |
类型 | 选择“性能评测” | |
来源 | 选择“供应商” | |
供应商名称 | 选择“通义实验室” | |
模型名称 | 填写“Qwen3-4B” | |
选择评测集 | 选择步骤一中创建的短文本、中文本两个数据集 | 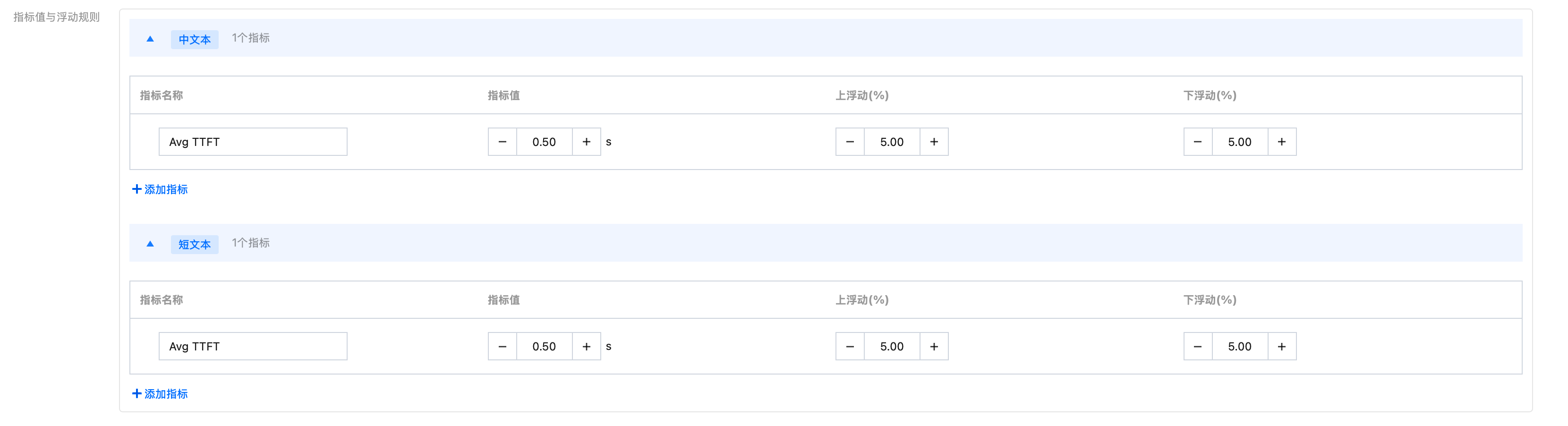 |
指标值与浮动规则 | 为数据集增加两个指标: Avg TTFT:设置指标值0.50(s),上下浮动5.00% Avg TPOT:设置指标值0.20(s),上下浮动5.00% | |
3. 单击确定,可在基线标准列表中查看新建的基线标准信息。

步骤三:创建性能评测模板
1. 单击 配置管理 Tab 页,选择评测模板,单击新建。
2. 按照表格填写基本信息:
字段 | 说明 | 填写示例 |
评测类型 | 选择“性能评测” | 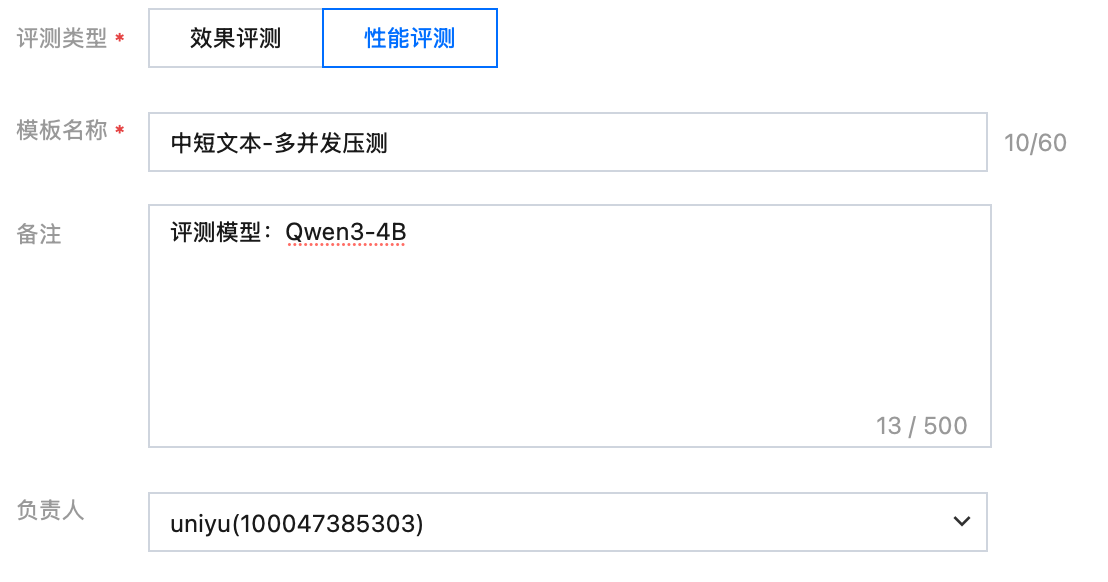 |
模板名称 | 可填“Qwen3_4B-多并发压测” | |
负责人 | 可选自己,也可根据实际情况选择 | |
按照表格填写评测配置1:
字段 | 说明 | 填写示例 |
配置名称 | 短文本1K | 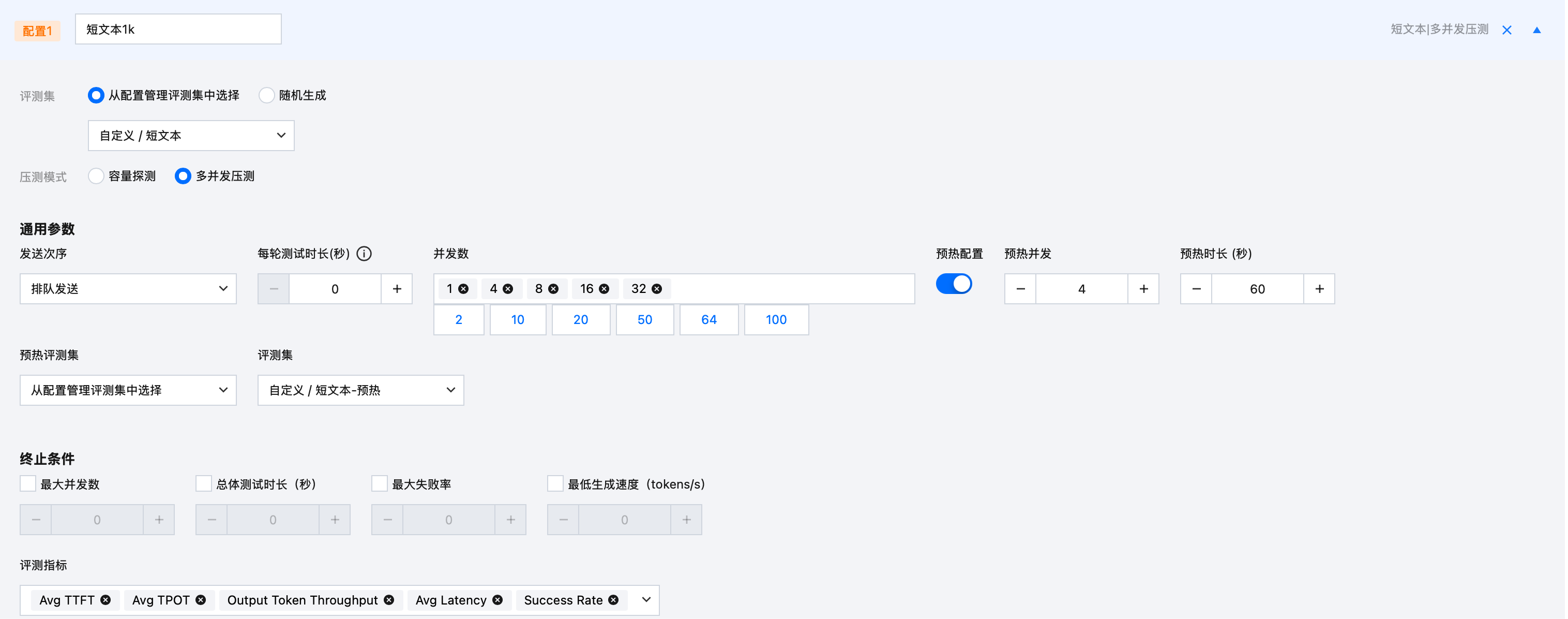 |
评测集 | 从配置管理评测集中选择“短文本” | |
通用参数 | 预热评测集:从配置管理评测集中选择“短文本-预热” 其他参数可以维持默认 | |
按照表格填写评测配置2:
字段 | 说明 | 填写示例 |
配置名称 | 中文本3.5K | 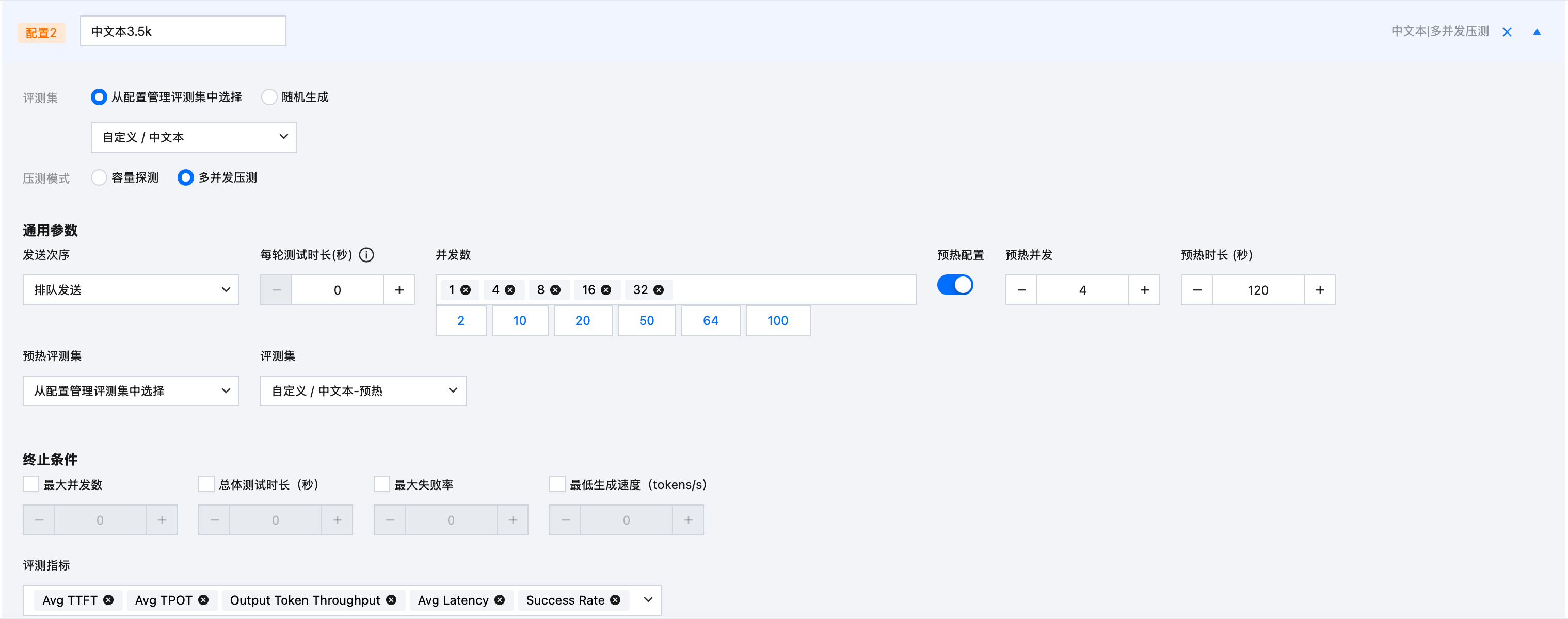 |
评测集 | 从配置管理评测集中选择“中文本” | |
通用参数 | 预热评测集:从配置管理评测集中选择“中文本-预热” 其他参数可以维持默认 | |
按照表格填写资源配置:
字段 | 说明 | 填写示例 |
机器来源、资源组 | 根据实际情况填写,可选自有的资源组或者通过从 TIONE 平台购买 | 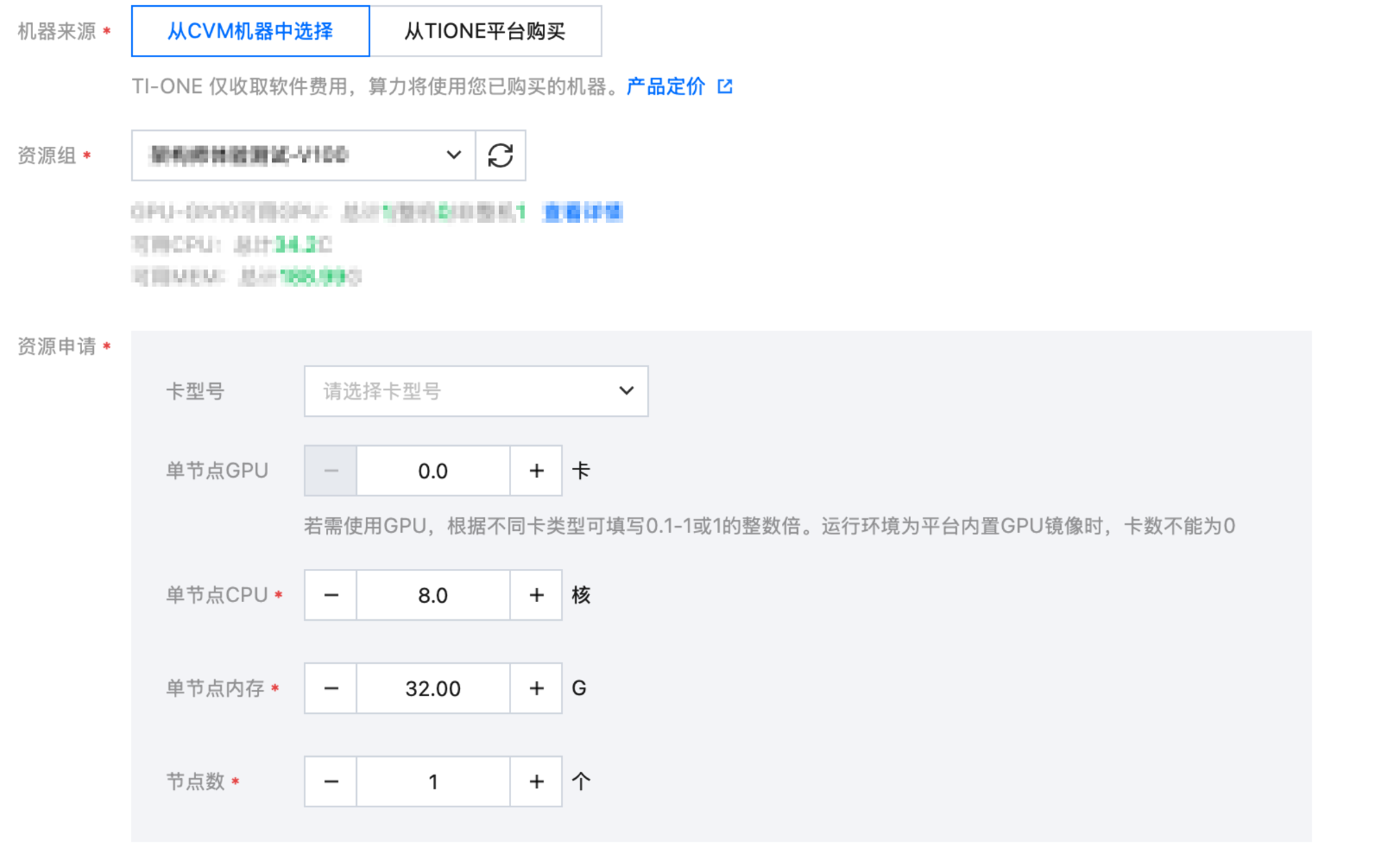 |
资源申请 | GPU 资源可填0 CPU 资源可填8C32G | |
3. 单击确定,可查看创建的评测模板信息:

步骤四:基于模板创建性能评测任务
1. 单击 性能评测 Tab 页,单击新建任务。
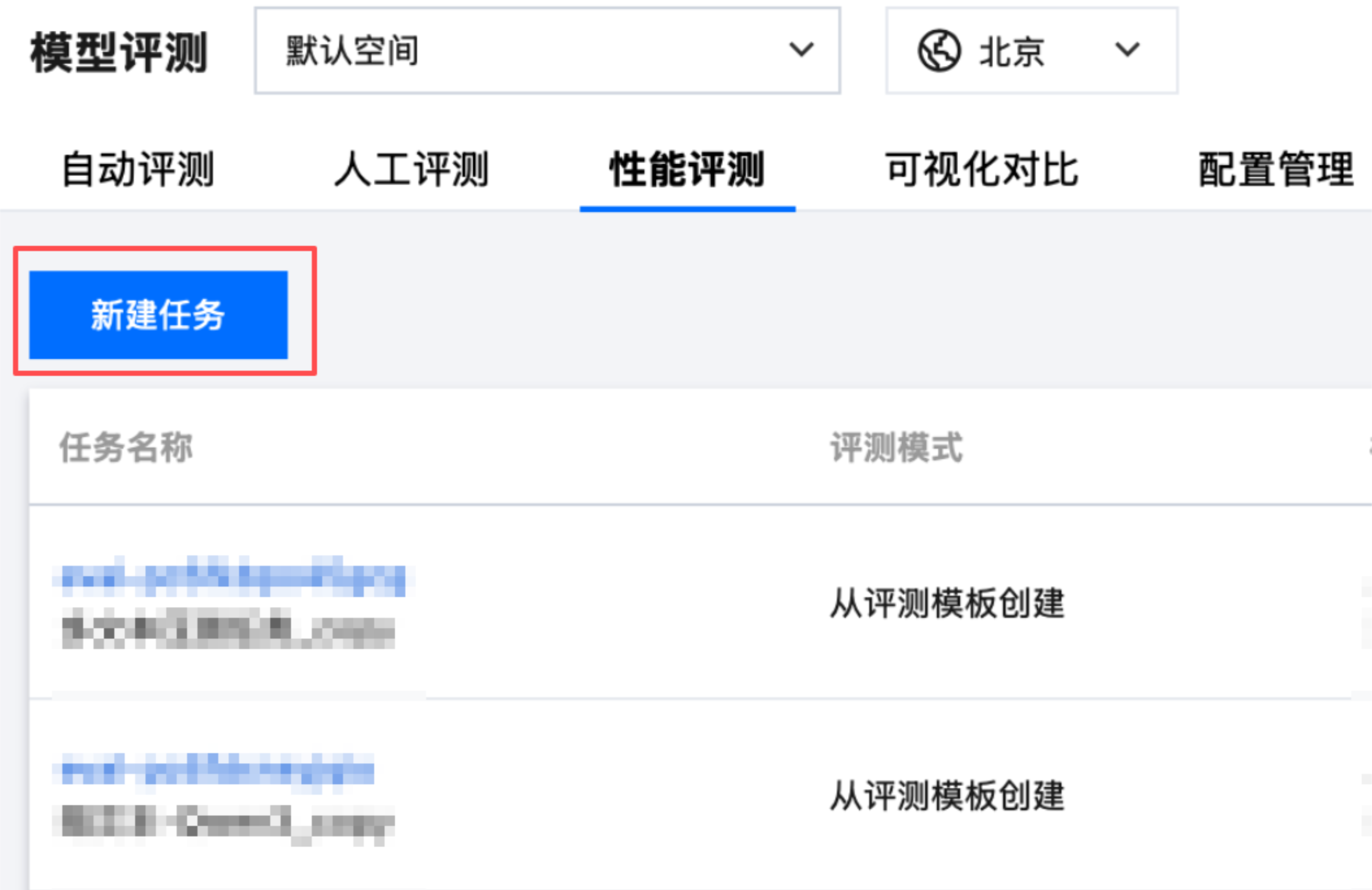
2. 按照表格填写基本信息:
字段 | 说明 | 填写示例 |
任务名称 | 可填“多文本压测任务” | 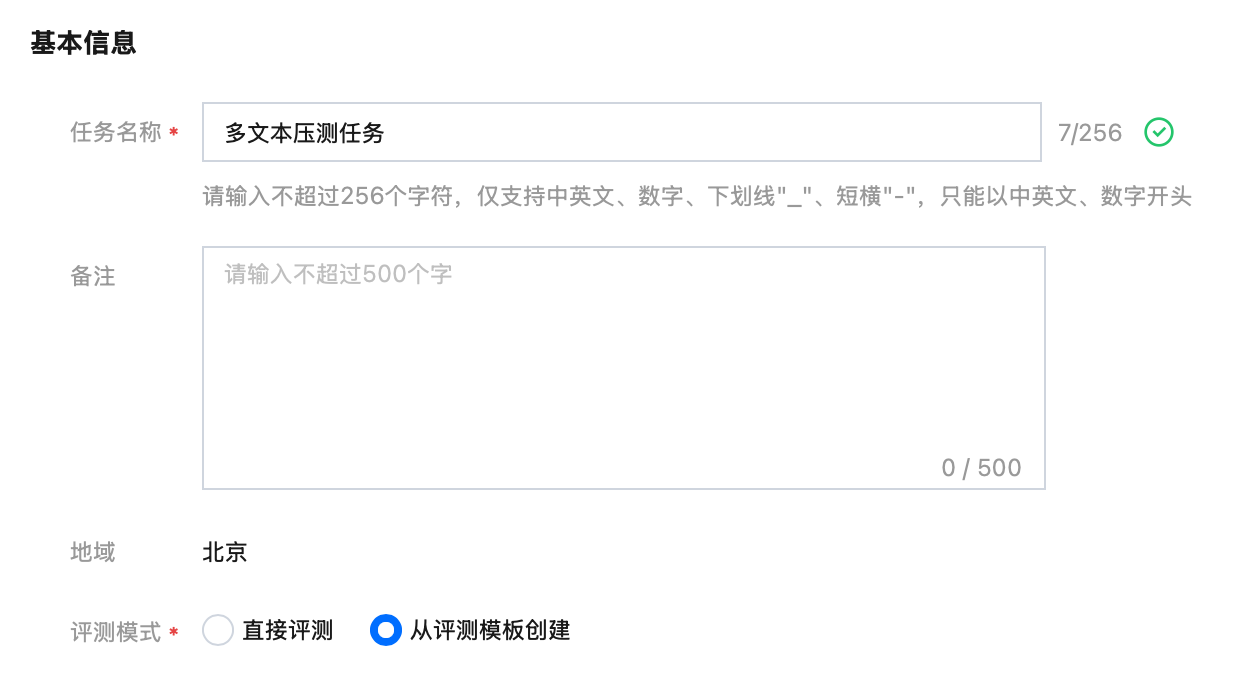 |
备注 | 如有需求可填写 | |
评测模式 | 选择“从评测模板创建” | |
按照表格填写评测配置:
字段 | 说明 | 填写示例 |
评测模板 | 选择步骤三创建的“中短文本-多并发压测”模板 |  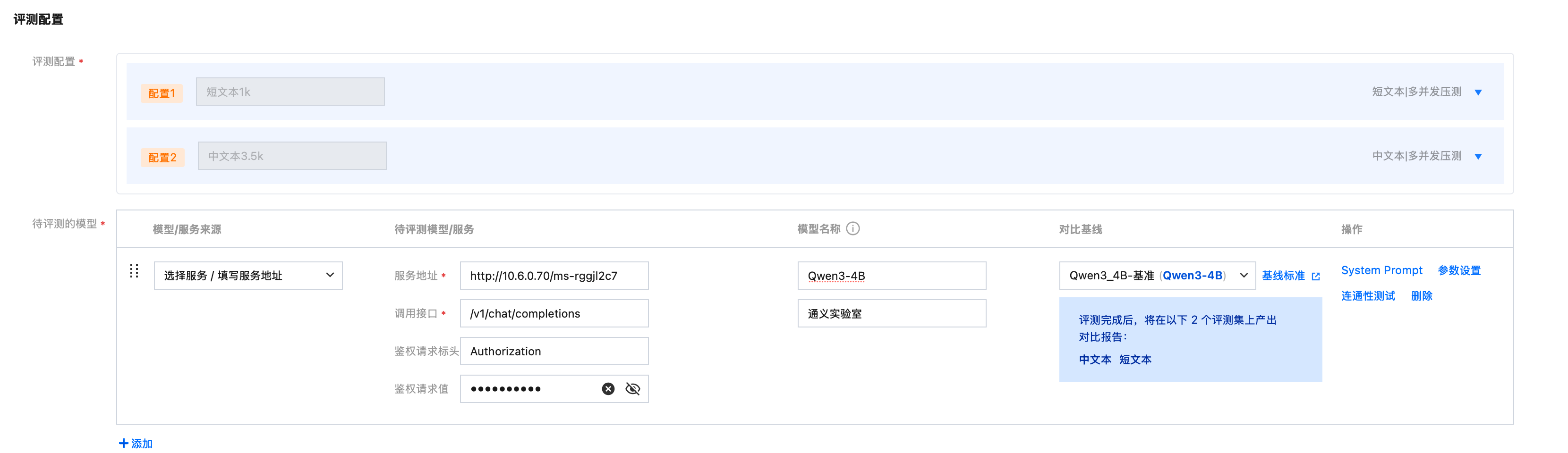 |
评测配置 | 配置将从模板自动导入,无需更改 | |
待评测的模型 | 填写前置准备中部署的 Qwen3-4B 模型地址: 模型/服务来源:可从在线服务选择,也可自行填写服务地址 模型名称及供应商:填写“Qwen3-4B”、“通义实验室” 对比基线:选择步骤二创建的“Qwen3-4B_基线” | |
3. 单击提交任务,可在任务列表查看所创建评测任务的基本信息及评测进度:

步骤五:查看评测结果
1. 单击任务 ID,进入任务详情页。

2. 进入详情页后可查看基本信息、整体评测结果和日志。

单击日志可查看任务日志。
任务完成后,单击整体评测结果,可查看评测结果。

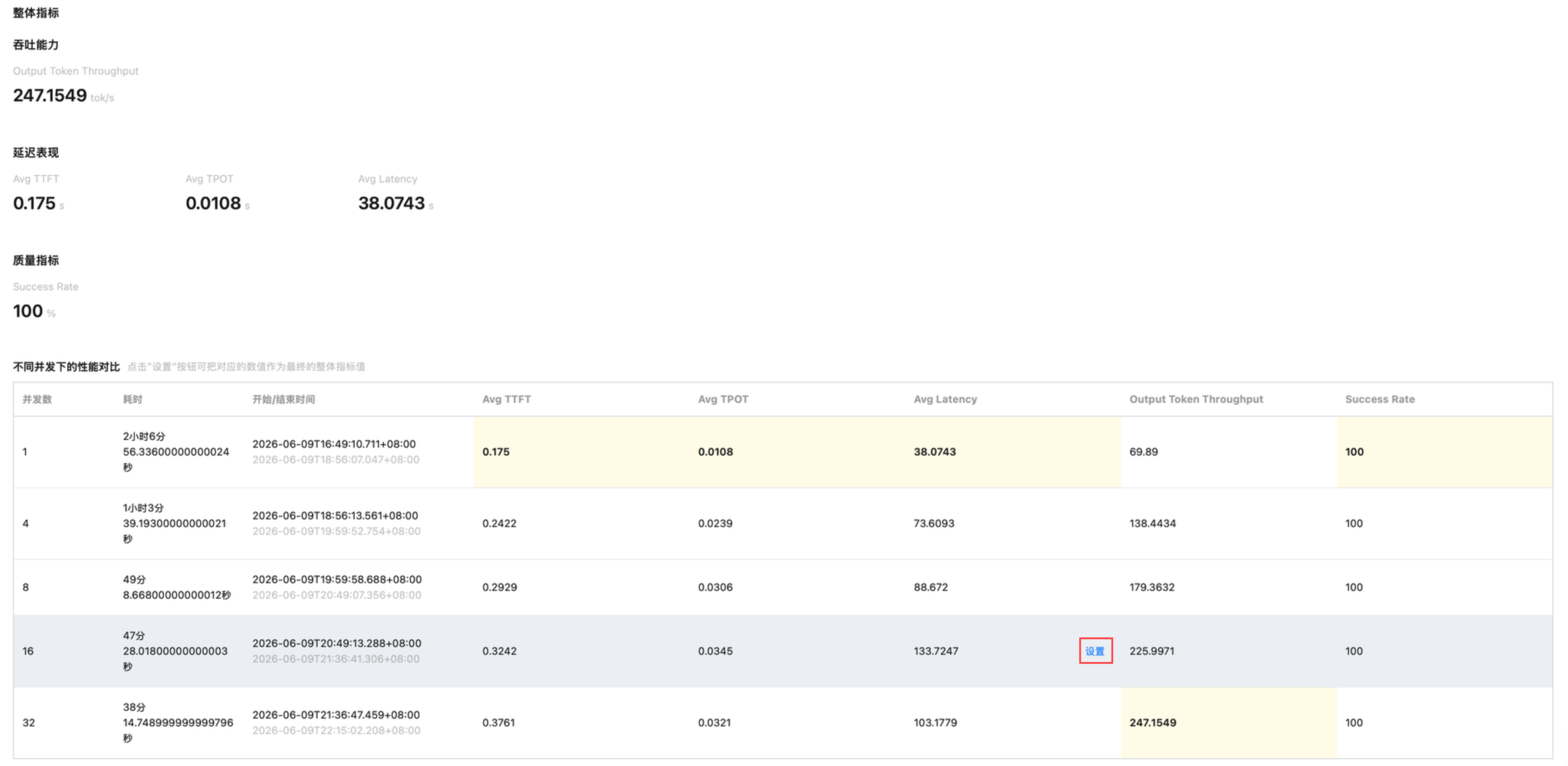
查看整体评测进度,支持下载评测结果。

待评测模型选择“Qwen3-4B”,可查看“短文本1K”、“中文本3.5K”两个配置的基线对比报告。
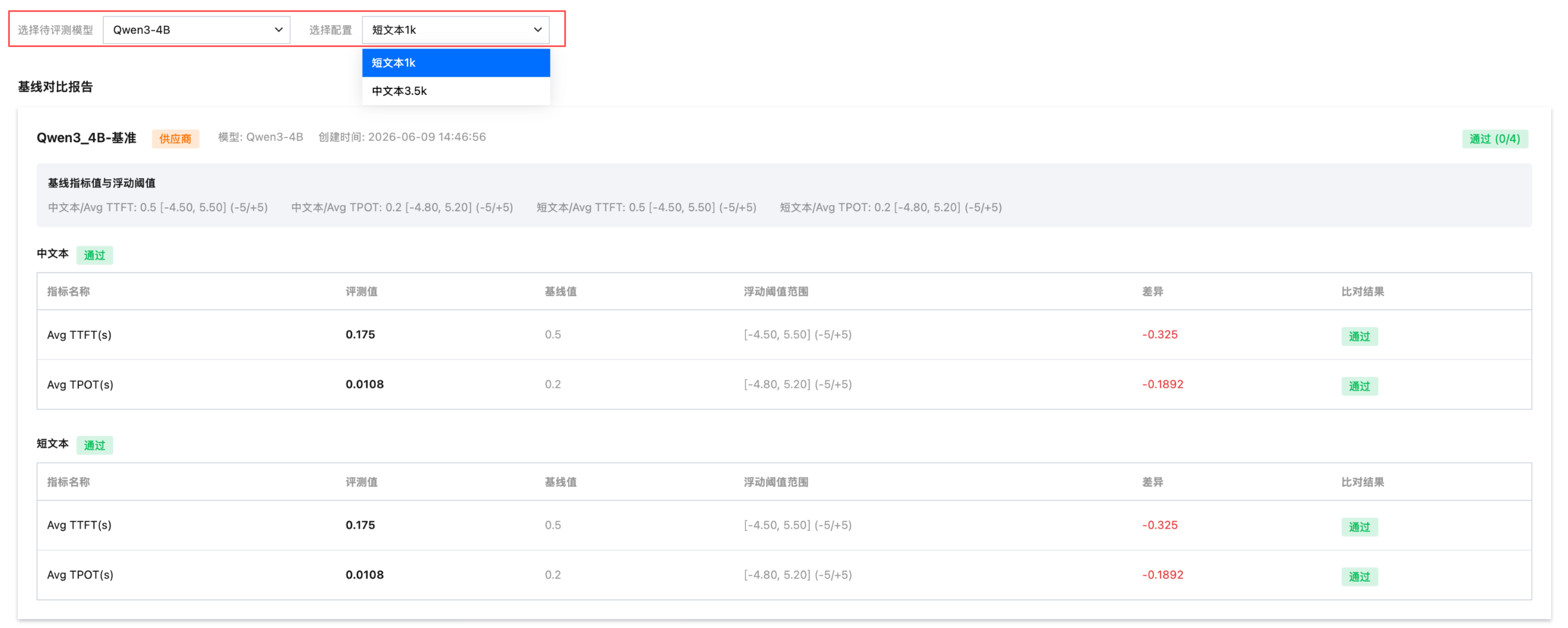
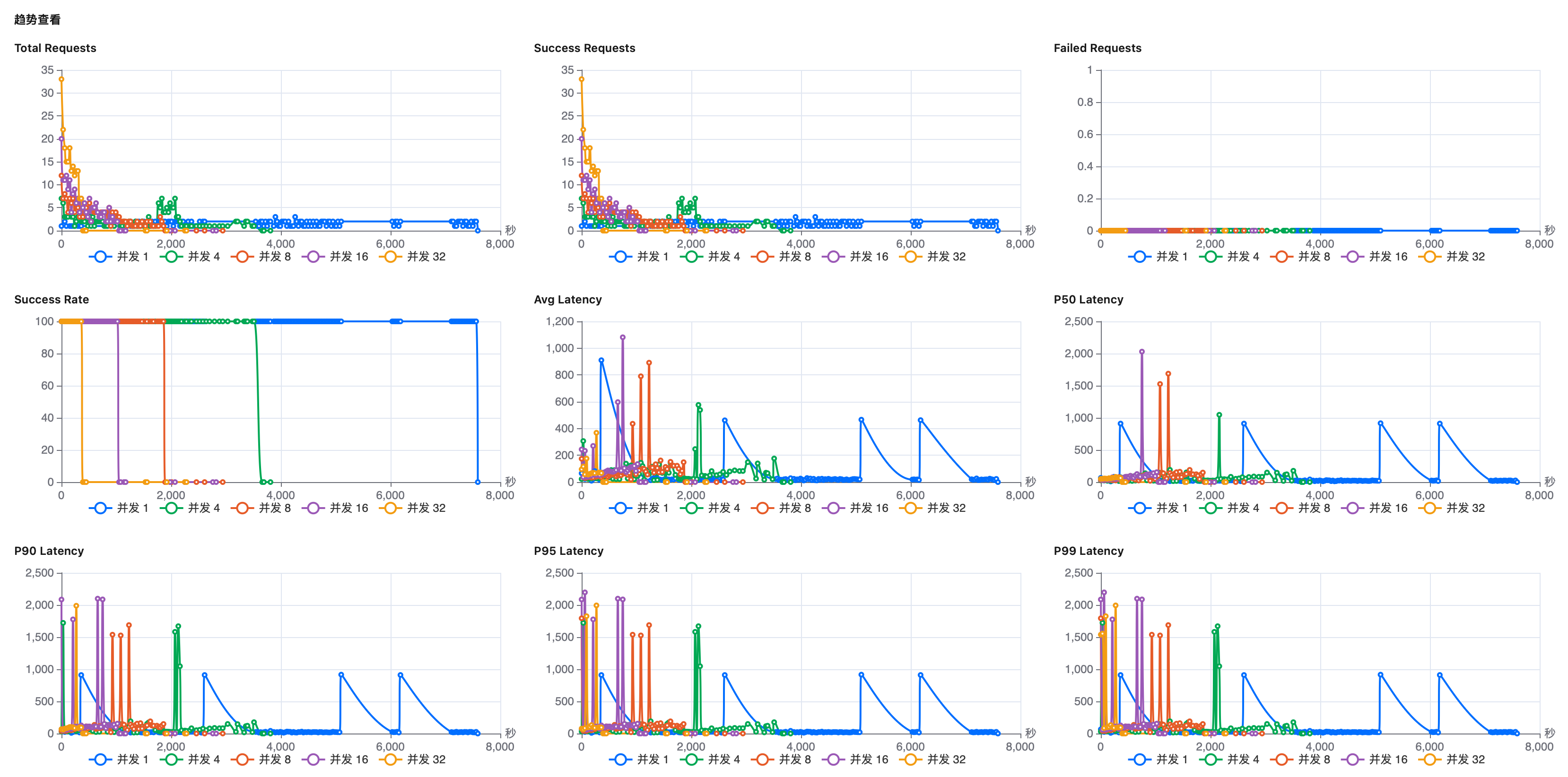
查看整体指标和趋势图,鼠标悬浮在指标数值,单击设置可把对应的数值作为最终的整体指标值。
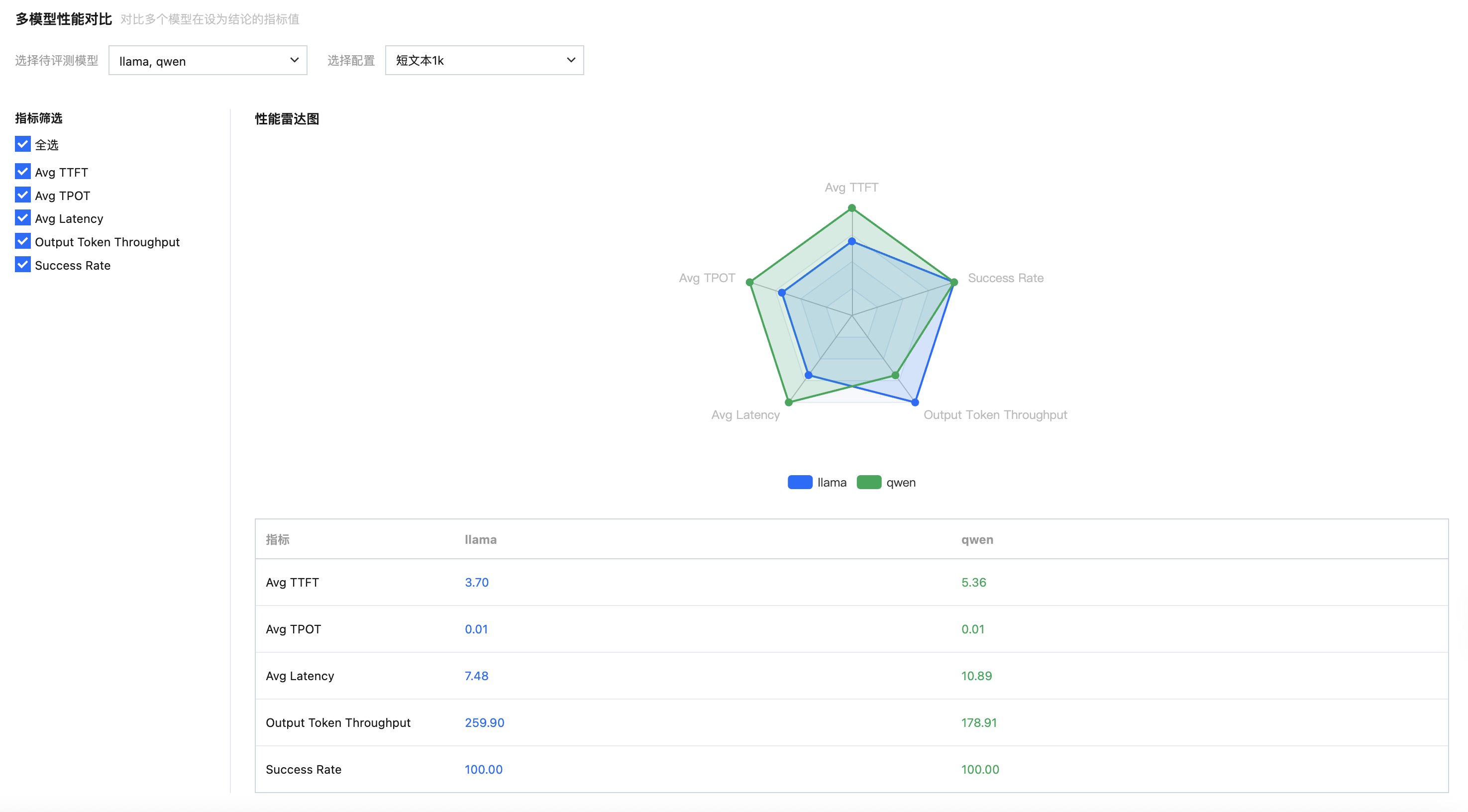
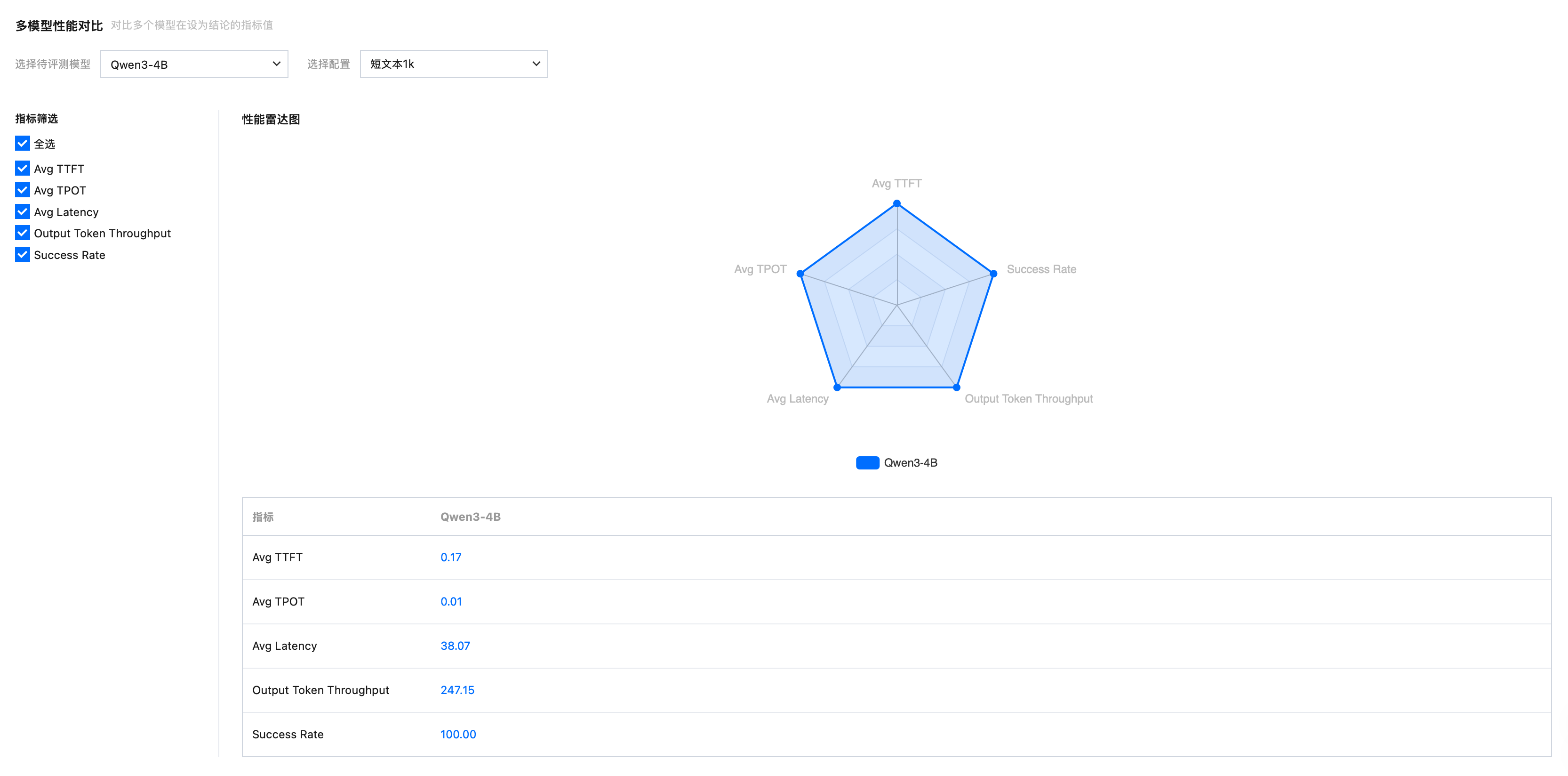
查看多模型性能对比,可选择指标并查看性能雷达图。
若想添加其他模型进行对比,可在性能评测列表找到当前任务,单击增加模型补充评测其他模型。
多模型对比图示例如下: