总览
TI-ONE 大模型训推平台提供效果评测模板创建功能,用户可以在 模型服务 > 模型评测 > 配置管理 中创建评测集、效果评测模板,同时支持创建基线标准,可在评测中选择基线进行对比。TI-ONE 大模型训推平台提供了丰富的内置评测集,覆盖复杂推理综合能力、知识问答、代码生成、语言理解生成、数学等场景。
本实践使用 MBPP 和 HumanEval 两个内置评测集,对 Qwen3-4B 模型的代码生成能力进行评测。实践总体步骤如下:
在实践过程中如果产生疑问可参考以下文档:
创建并管理评测模板、基线标准相关教程可参见 配置管理。
进行自动评测时,创建自动评测任务相关教程可参见 自动评测。
评测集格式要求可参见 评测集格式要求。
前置准备
详细步骤
步骤一:创建基线标准
1. 登录 TI-ONE 控制台,在左侧导航栏中选择模型服务 > 模型评测。
2. 单击 配置管理 Tab 页,选择基线标准,单击新建。
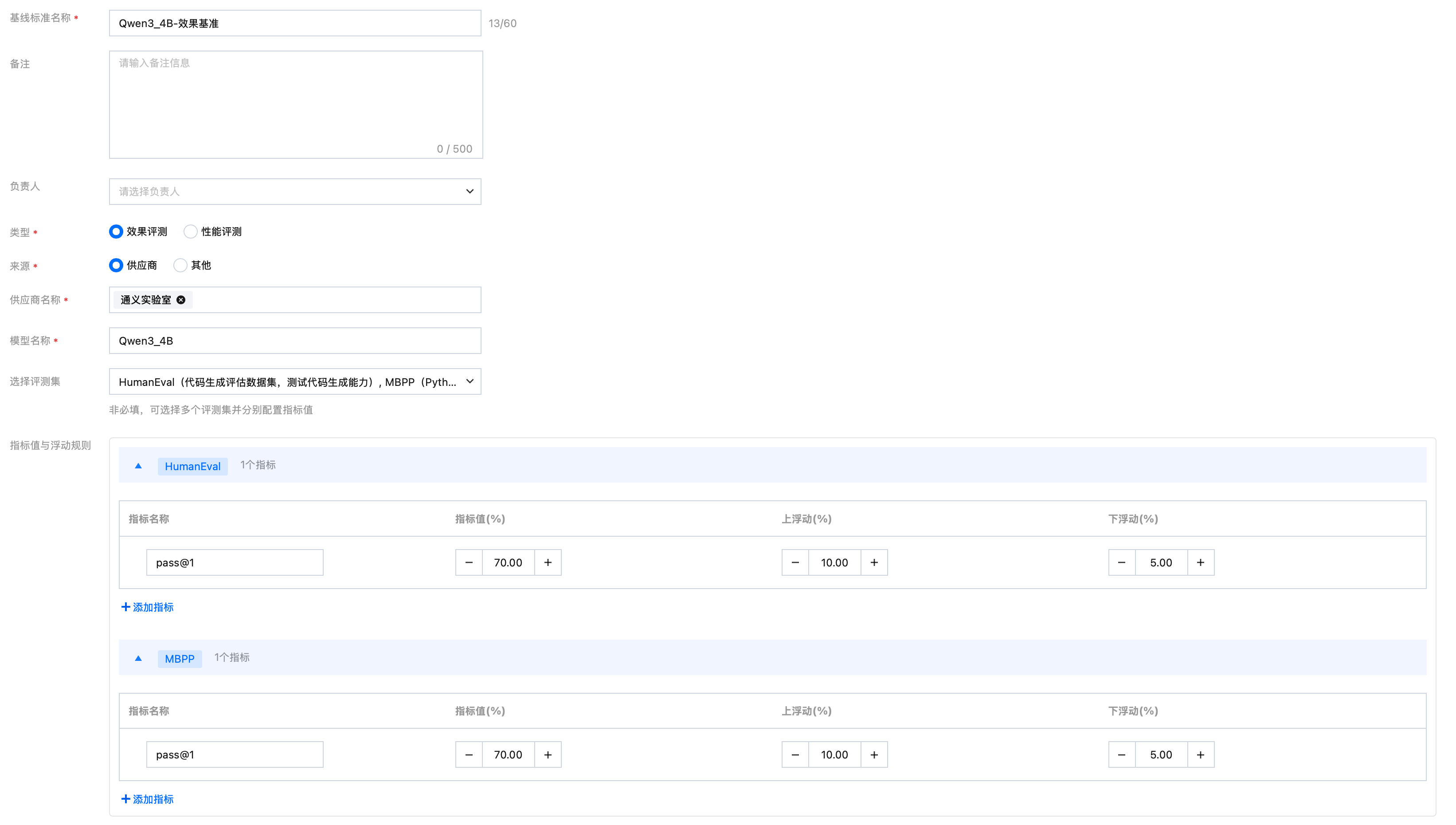
3. 按照表格填写如下数据:
字段 | 说明 |
基线标准名称 | 可填“Qwen3_4B-效果基准” |
负责人 | 可选自己,也可根据实际情况选择 |
类型 | 选择“效果评测” |
来源 | 选择“供应商” |
供应商名称 | 选择“通义实验室” |
模型名称 | 填写“Qwen3-4B” |
选择评测集 | 选择 MBPP、HumanEval 两个内置评测集  |
指标值与浮动规则 | 为两个数据集设置 pass@1 指标: 设置指标值 70%,上浮动 10.00%,下浮动 5.00% |
填写示例如下:
4. 单击确定,可在列表中查看新建的基线标准信息:

步骤二:创建效果评测模板
1. 单击 配置管理 Tab 页,选择评测模板,单击新建。
2. 按照表格填写如下信息:
字段 | 说明 |
评测类型 | 选择“效果评测” |
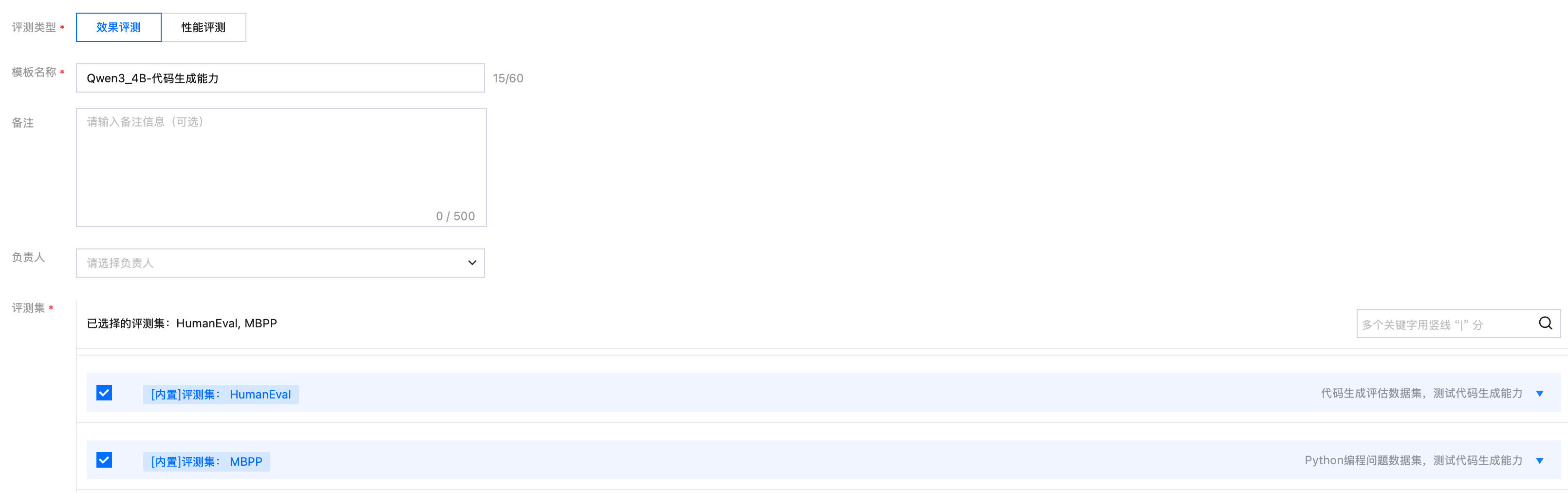
模板名称 | 填写“Qwen3_4B-代码生成能力” |
负责人 | 可选自己,也可根据实际情况选择 |
评测集 | 选择 MBPP、HumanEval 两个内置评测集 |
填写示例如下:
3. 按照表格填写资源配置:
字段 | 说明 |
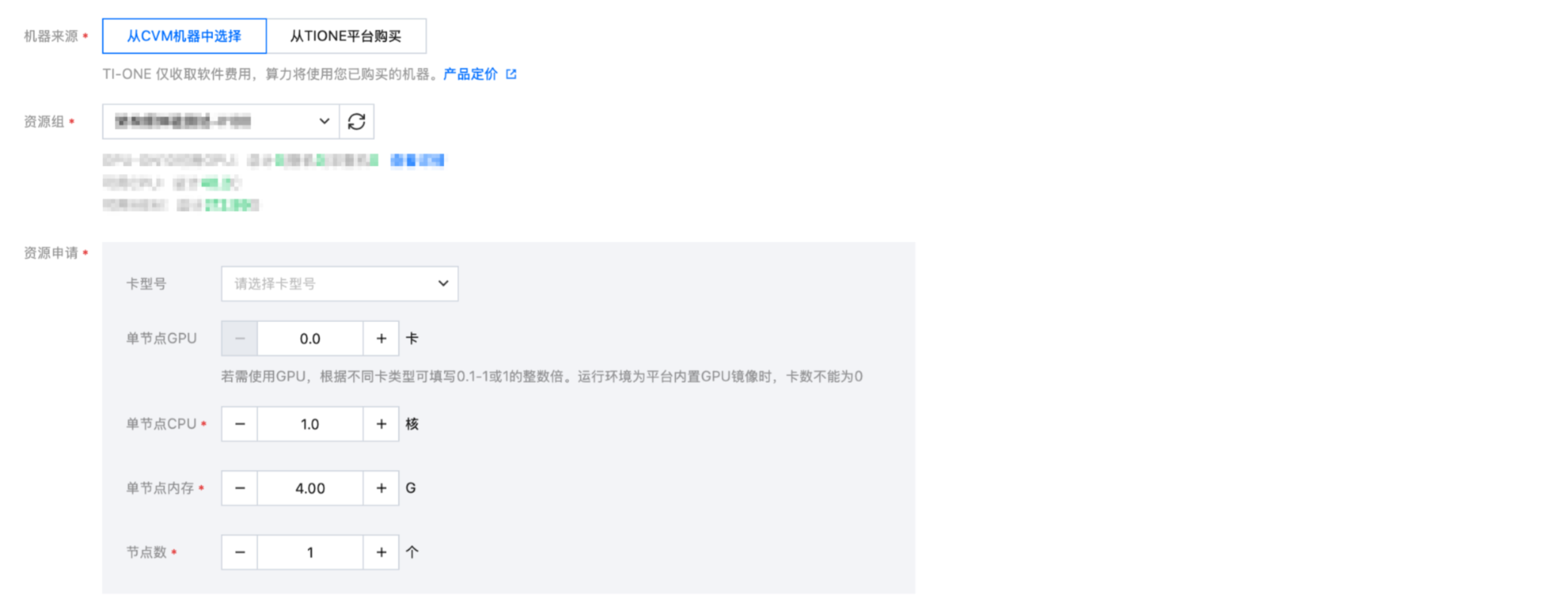
机器来源、资源组 | 根据实际情况填写 |
资源申请 | ● GPU 资源:评测的是部署好的在线服务,可填写0 ● CPU 资源:可填1C4G |
填写示例如下:
4. 单击确定,可在列表中查看创建的评测模板信息:

步骤三:基于模板创建自动评测任务
1. 单击 自动评测 Tab 页,单击新建任务。
2. 按照表格填写基本信息:
字段 | 说明 |
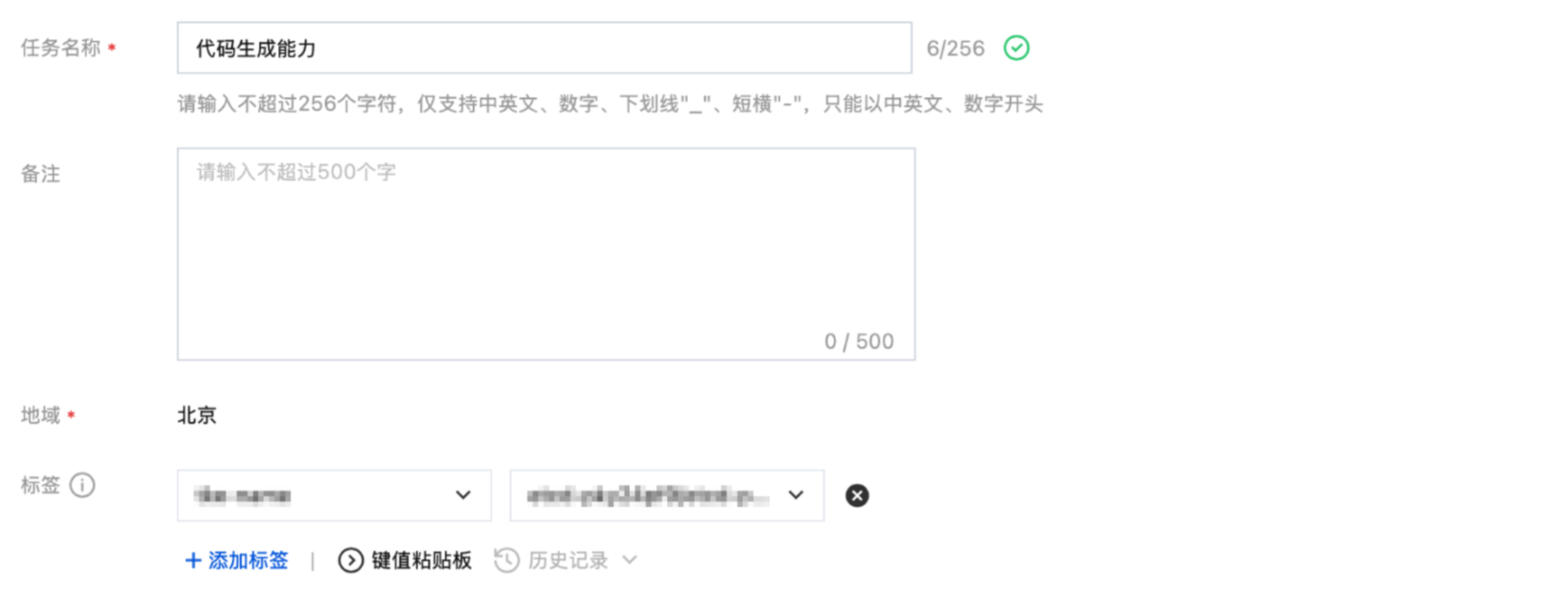
任务名称 | 可填“代码生成能力” |
备注 | 如有需求可填写 |
地域 | 地域字段取值根据您在服务列表页面所选择的地域自动带入 |
标签 | 用于评测任务间进行权限隔离,可根据需求选择 |
填写示例如下:
3. 按照表格填写评测信息和模型信息:
字段 | 说明 |
评测模式 | 选择“从评测模板创建” |
评测模板 | 选择步骤二中创建的“Qwen3_4B-代码生成能力”,评测数据集和资源配置将自动导入 |
待评测的模型 | 填写前置准备中部署的 Qwen3-4B 模型地址: ● 模型/服务来源:可从在线服务选择,也可自行填写服务地址 ● 模型名称及供应商:Qwen3-4B、通义实验室 ● 对比基线:选择步骤一创建的“Qwen3_4B-效果基准” ● 若已有推理结果可开启“复用已有结果” |
机器来源、资源组及资源申请 | 选择评测模板后将自动导入评测模板中设置的值,无需修改 |
填写示例如下:
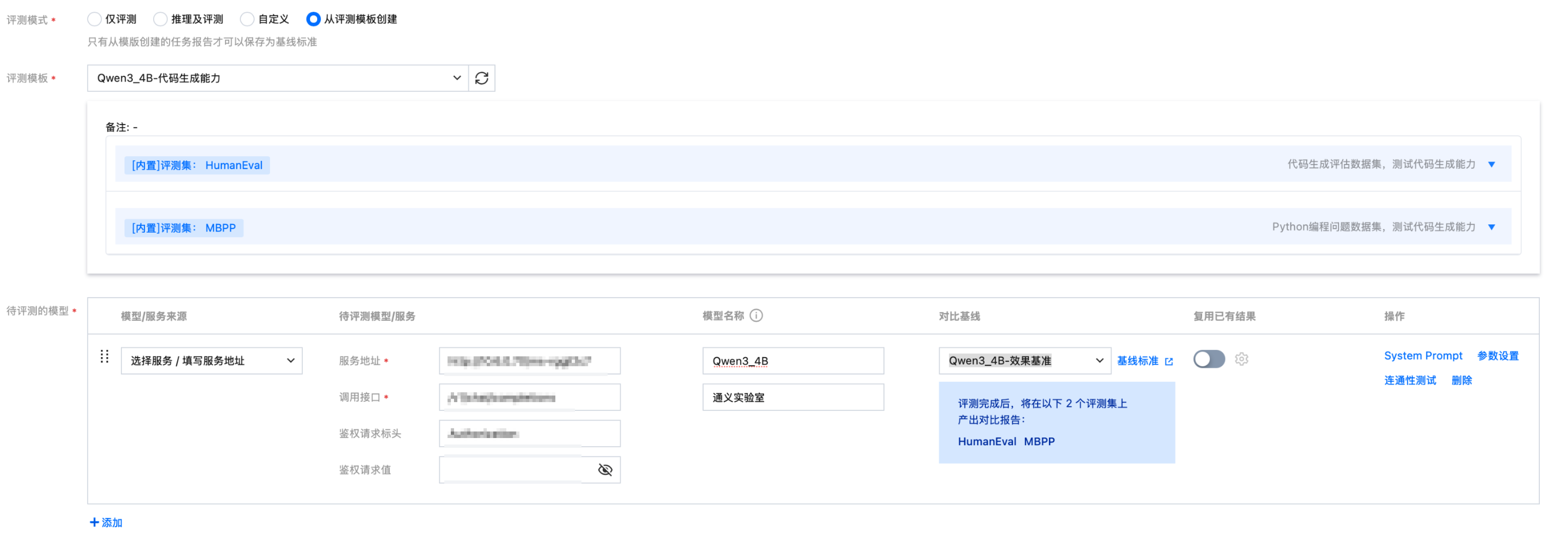
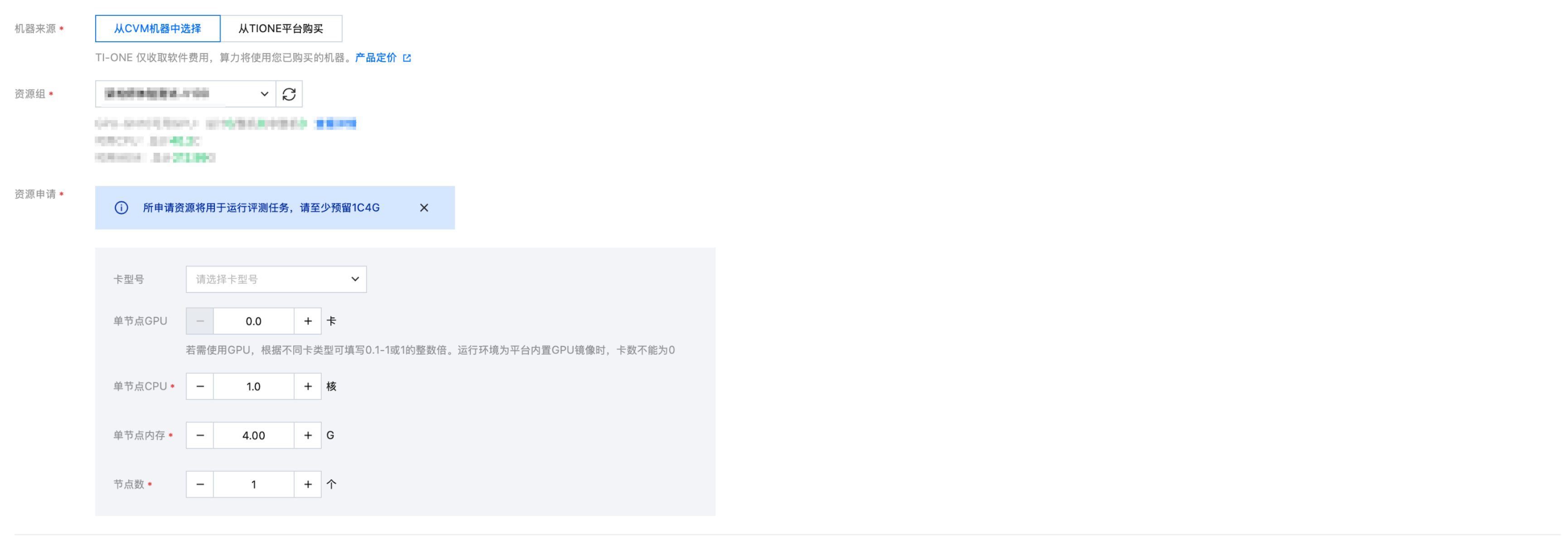
4. 单击提交任务,可在列表查看所创建评测任务的基本信息和各数据集评测进度:

5. 单击查看进度,可以查看评测进度详情:

步骤四:查看自动评测结果
1. 单击任务 ID,进入任务详情页。

2. 进入详情页后可查看基本信息、整体评测结果、单条评测结果和日志。
单击 日志,可查看评测任务日志。
任务完成后,单击整体评测结果,可查看评测结果。

查看整体评测进度,支持下载评测结果。

查看模型评测排名,支持调整数据集分数权重。

若想添加其他模型进行对比,可在自动评测列表找到当前任务,单击增加模型补充评测其他模型。

查看模型详细指标,可单击调整权重修改数据集分数权重。

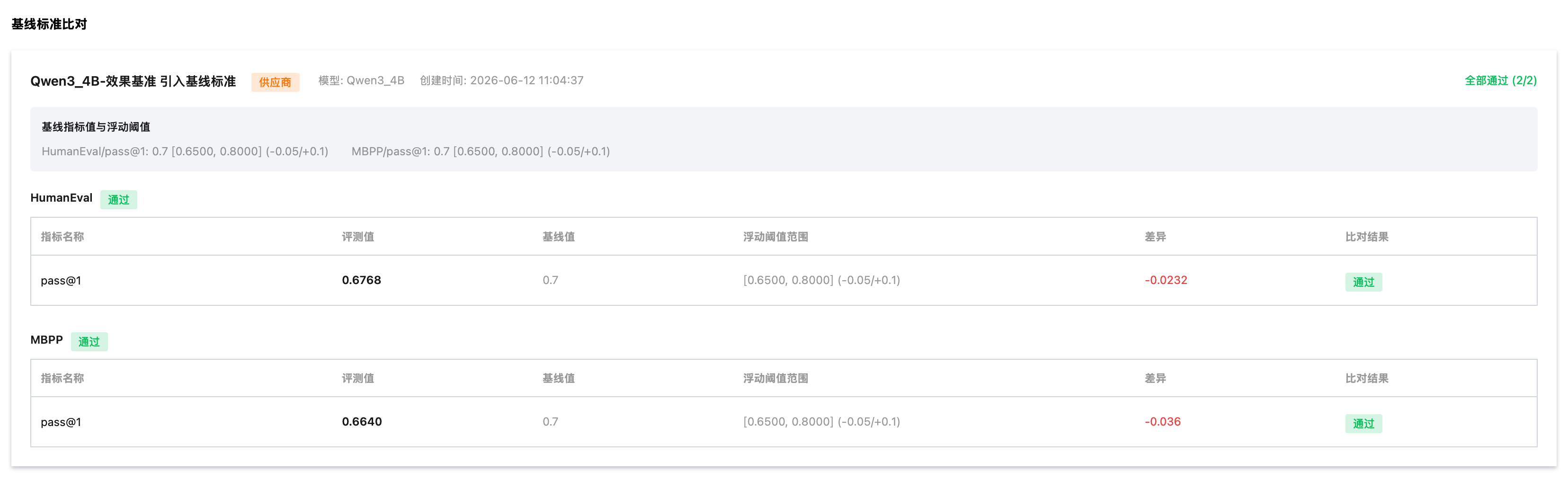
查看基线标准比对,可查看所评测模型是否通过基准对比。
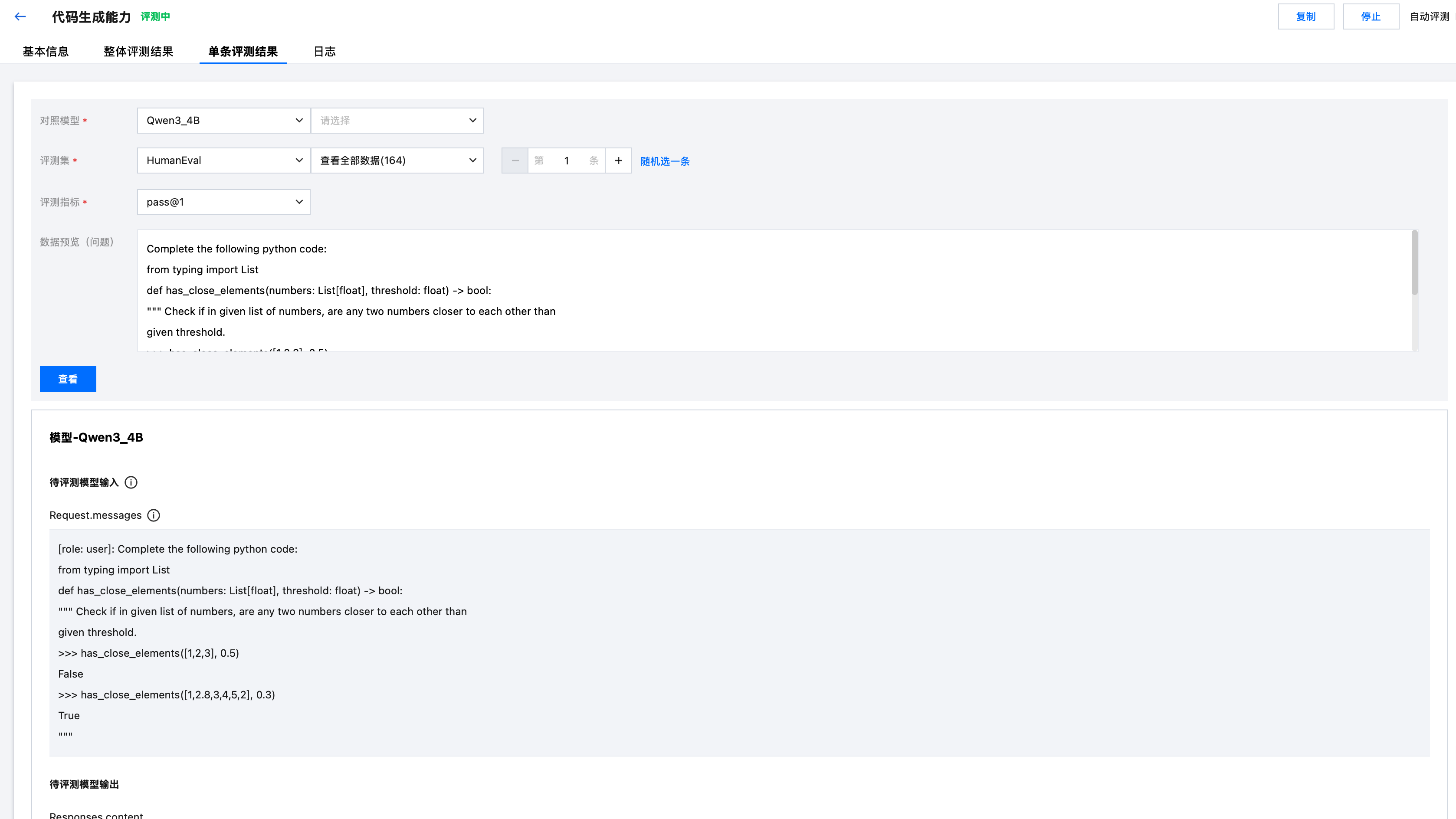
单击单条评测结果,可选择数据集,查看单条数据的评测结果。