
腾讯云向量数据库
腾讯云向量数据库应用示例有哪些?
大规模知识库
企业的私域数据存储在向量数据库中可构建外部知识库,帮助企业更好地管理和利用自己的数据资源。
推荐系统
向量数据库会基于用户特征进行向量存储与检索,并返回与用户可能感兴趣的物品作为推荐结果。
问答系统
向量数据库会基于问题信息进行向量存储与检索,并返回最相关的问题与对应的答案。
文本/图像检索
向量数据库对输入的图像和文本信息进行向量存储与检索,会找到最匹配输入信息的文本或图像结果。
腾讯云向量数据库支持哪些索引类型?
FLAT 索引
向量会以浮点型的方式进行存储,不做任何压缩处理。搜索向量会遍历所有向量与目标向量进行比较。
HNSW 索引
全称为 Hierarchical Navigable Small World, 是基于图的索引,适合对搜索效率要求较高的场景。
IVF 系列
全称为 Inverted File,IVF 系列索引的核心思想是:将高维空间划分为多个聚类,并为每个聚类构建一个倒排文件。适用于高维向量数据的快速检索。(即将支持)
腾讯云向量数据库有什么产品优势?
高性能
向量数据库单索引支持10亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
高可用
向量数据库提供多副本高可用特性,提高容灾能力,确保数据库在面临节点故障和负载变化等挑战时仍能正常运行。
大规模
向量数据库架构支持水平扩展,单实例可支持百万级 QPS,轻松满足 AI 场景下的向量存储与检索需求。
低成本
只需在管理控制台按照指引,简单操作几个步骤,即可快速创建向量数据库实例,全流程平台托管,无需进行任何安装、部署和运维操作,有效减少机器成本、运维成本和人力成本开销。
简单易用
支持丰富的向量检索能力,用户通过 HTTP API 接口即可快速操作数据库,开发效率高。同时控制台提供了完善的数据管理和监控能力,操作简单便捷。
稳定可靠
向量数据库源自腾讯集团自研的向量检索引擎 OLAMA,近40个业务线上稳定运行,日均处理的搜索请求高达千亿次,服务连续性、稳定性有保障。
腾讯云向量数据库是如何设计的?
部署架构
腾讯云向量数据库采用分布式部署架构,每个节点相互通信和协调,实现数据存储与检索。客户端请求通过 Load balance 分发到各节点上。
逻辑架构
实例是腾讯云中独立运行的数据库环境,是用户购买向量数据库服务的基本单位。腾讯云向量数据库数据存储的一个实例集群中包括 Database、Collection、Document 三个逻辑层级。其中,一个实例可以包含很多个 Database,一个 Database 可以包含多个 Collection,一个 Collection 可以包含多个 Document。
数据安全
腾讯云向量数据库的多副本设计、多可用区分布节点、API 密钥认证,并运行于私有网络环境,通过安全组控制访问来源,CAM 账户授权等多方面保护向量数据的完整性和隐私。
鉴权方式
腾讯云向量数据库使用账号(account)和 API 密钥(api_key)的组合进行鉴权,以验证用户身份并授权其访问。
连接方式
腾讯云向量数据库支持通过 HTTP 协议进行数据写入和查询等操作。
检索方法
腾讯云向量数据库支持通过标量检索、向量检索、标量向量混合检索的方法。
标量检索
是基于标量字段的检索。标量是指一个单独的数值,例如文本字段、数值字段或日期字段等,区别于向量等多维数据结构。
向量检索
是基于向量相似度进行的检索,通过计算向量之间的相似度来找到与查询向量最相似的文档或记录。
混合检索
是将标量检索和向量检索结合起来的一种方式,旨在综合利用标量属性和向量特征进行更精确和全面的检索。
腾讯云向量数据库支持哪些相似度计算方法?
在 VectorDB 中,相似度度量用于衡量向量之间的相似度。选择良好的距离度量有助于显着提高分类和聚类性能。根据输入数据形式,选择特定的相似性度量以获得最佳性能。
相似性计算方法 | 方法说明 |
|---|---|
内积(IP) | 全称为 Inner Product,是一种计算向量之间相似度的度量算法,它计算两个向量之间的点积(内积),所得值越大越与搜索值相似。 |
欧式距离(L2) | 全称为 Euclidean distance,指欧几里得距离,它计算向量之间的直线距离,所得的值越小,越与搜索值相似。L2在低维空间中表现良好,但是在高维空间中,由于维度灾难的影响,L2的效果会逐渐变差。 |
余弦相似度(COSINE) | 余弦相似度(Cosine Similarity)算法,是一种常用的文本相似度计算方法。它通过计算两个向量在多维空间中的夹角余弦值来衡量它们的相似程度。 |
腾讯云向量数据库的应用场景有哪些?
大模型知识库
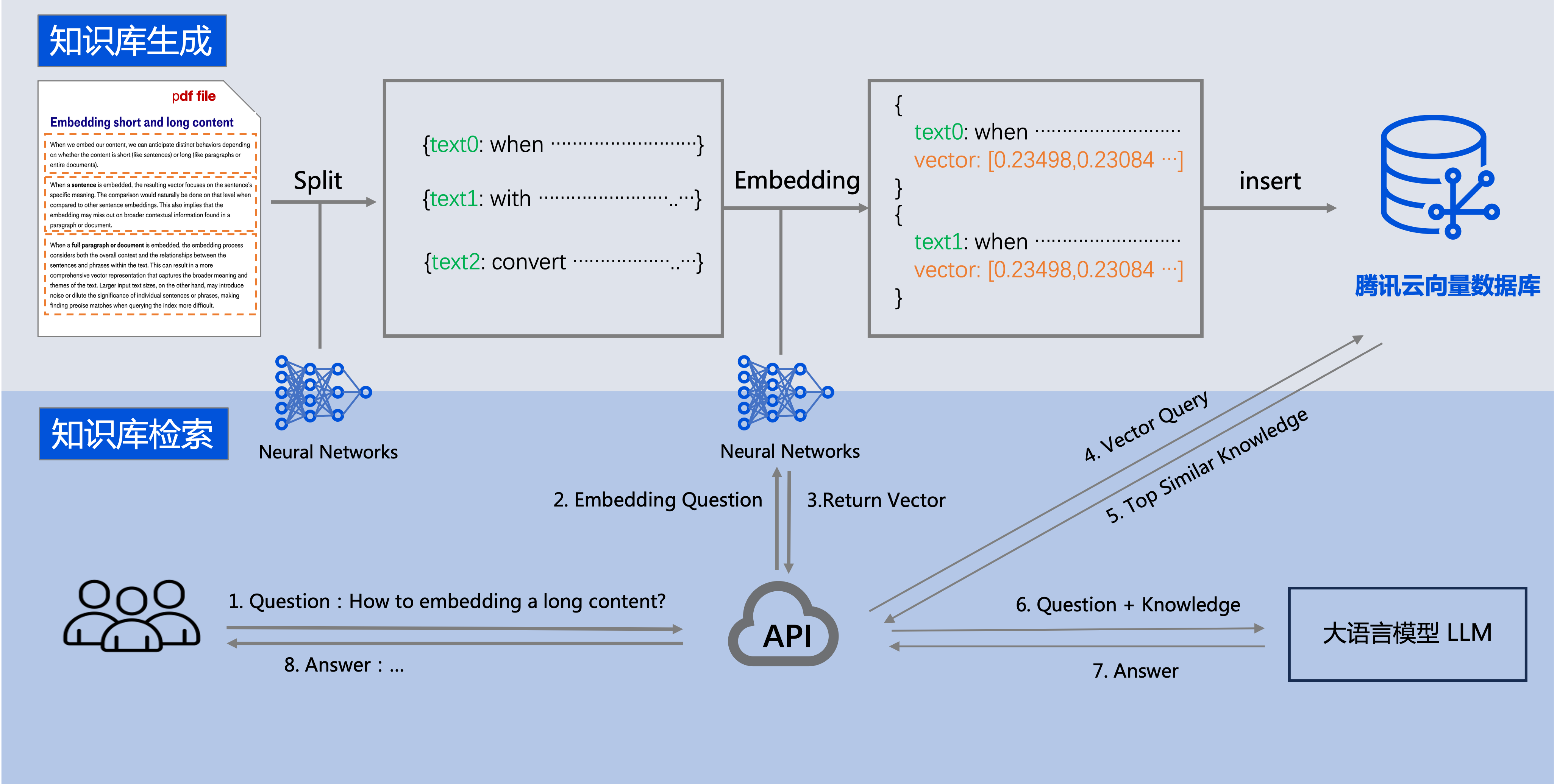
腾讯云向量数据库可以和大语言模型 LLM 配合使用。企业的私域数据在经过文本分割、向量化后,可以存储在腾讯云向量数据库中,构建起企业专属的外部知识库,从而在后续的检索任务中,为大模型提供提示信息,辅助大模型生成更加准确的答案。
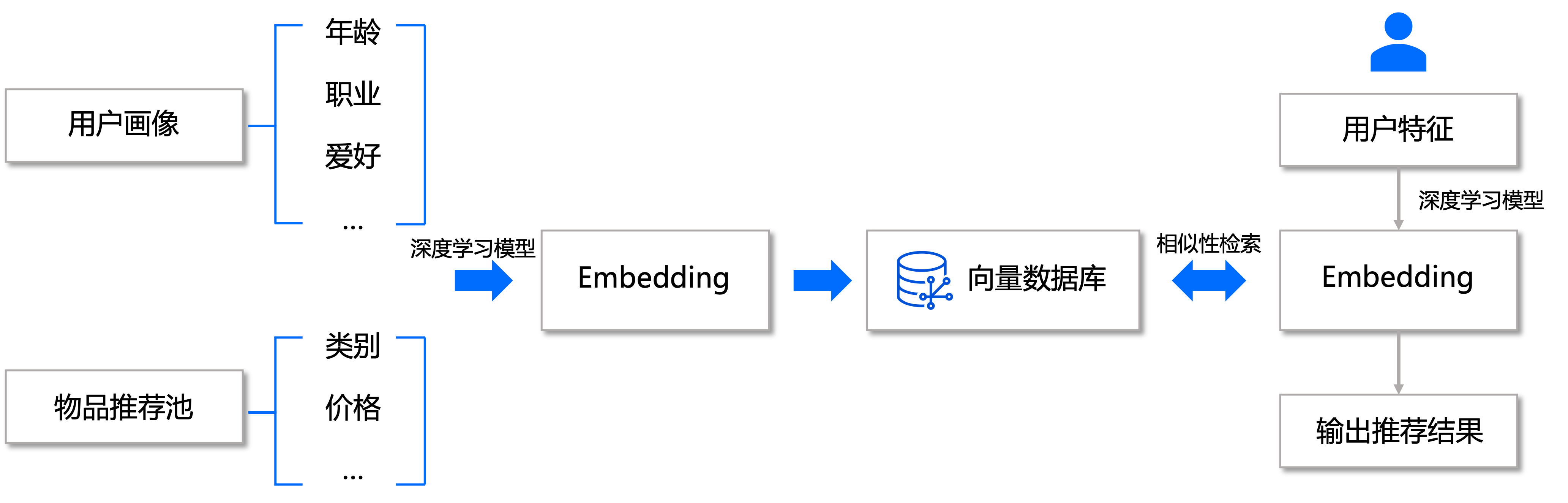
推荐系统
推荐系统的目标是根据用户的历史行为和偏好,向用户推荐可能感兴趣的物品。在这种场景下,将用户行为特征向量化存储在向量数据库。当发起推荐请求时,系统会基于用户特征进行相似度计算,然后返回与用户可能感兴趣的物品作为推荐结果。
问答系统
智能问答系统是一种能够回答用户提出问题的智能应用,通常使用 NLP 服务和深度学习等技术实现。在问答系统中,问题和答案通常被转换为向量表示,并存储在向量数据库中。当用户提出问题时,问答系统可以通过计算向量之间的相似度,检索最相关的问题信息并返回对应的答案信息。因此,使用向量数据库来存储和检索相关的向量数据,可以提高问答系统的检索效率和准确性。
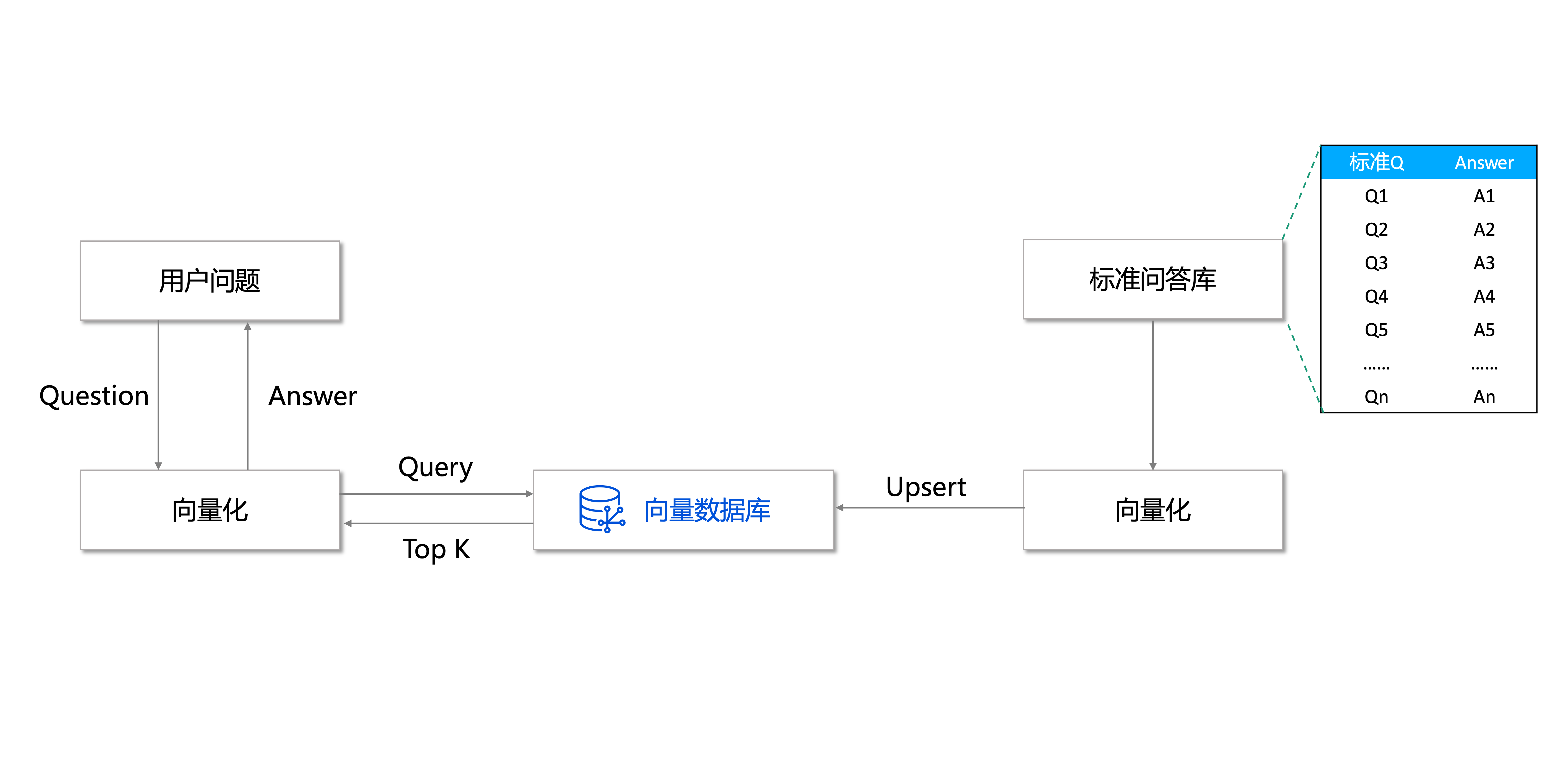
问答系统的应用场景非常广泛,例如智能客服、智能助手、智能家居等。在这些场景中,用户可以通过自然语言提问获取相关信息,例如查询产品信息、控制家居设备等。通过使用向量数据库来存储和检索相关的向量数据,问答系统可以更快速、准确地响应用户的请求,提高用户体验。
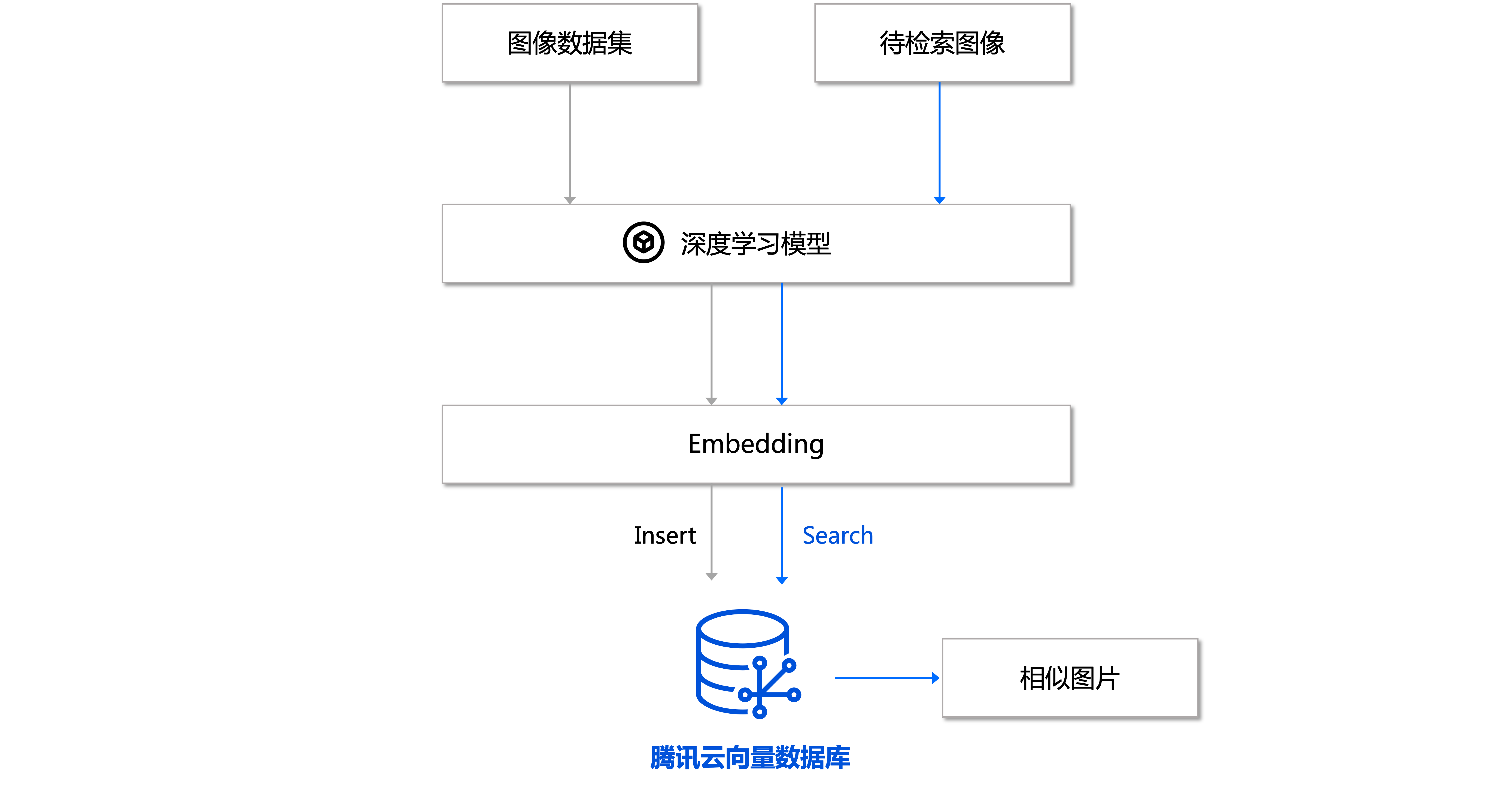
文本/图像检索
文本/图像检索任务是指在大规模文本/图像数据库中搜索出与指定图像最相似的结果,在检索时使用到的文本/图像特征可以存储在向量数据库中,通过高性能的索引存储实现高效的相似度计算,进而返回和检索内容相匹配的文本/图像结果。下图以图像检索为例介绍任务流程。
- 腾讯云向量数据库正式发布!
- 腾讯云向量数据库优势性
- 腾讯云向量数据库产品概要
- 腾讯云向量数据库SDK正式开源
- 腾讯云向量数据库SDK正式开源
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号