
索引一组开始和结束索引的数组
我有两个数组:
timesteps = [1,3;5,7;9,10];
data = [1,2,3,4,5,6,7,8,9,10];timesteps数组中的值描述了我想要的data值。第一列开始,第二列结束。
这里我想要[1,2,3,5,6,7,9,10]。
所以这段代码对我来说很好,但是因为for循环很慢.在Matlab中是否有一个内线,这样我就可以摆脱反循环了吗?
newData=[];
for ind=1:size(timesteps,1)
newData=cat(2,newData,data(timesteps(ind,1):timesteps(ind,2)));
end编辑:通过Wolfie的解决方案,我得到了以下(非常好的)结果。(我只使用了一个小数据集,它通常是50倍大。)
(Mine) Elapsed time is 48.579997 seconds.
(Wolfies) Elapsed time is 0.058733 seconds.回答 3
Stack Overflow用户
发布于 2019-09-04 13:35:46
Irreducible's answer使用str2num和sprintf在数值和字符数据之间切换以创建索引.(在我的测试中),这不像您已经对小数组所做的那样循环执行,但是对于大型数组来说,随着内存分配处理得更好,这就更快了。
您可以通过预先分配输出并对其进行索引来提高性能,以避免循环中的级联。对于大型数组,这可能会带来很大的速度。
N = [0; cumsum( diff( timesteps, [], 2 ) + 1 )];
newData = NaN( 1, max(N) );
for ind = 1:size(timesteps,1)
newData(N(ind)+1:N(ind+1)) = data(timesteps(ind,1):timesteps(ind,2));
end下面的基准说明了这是如何持续更快。
- X轴:
data中的元素数 - Y轴:时间以秒为单位
- 假设:选择索引的随机子集,其中
index的行数比data少4倍。
标杆小区
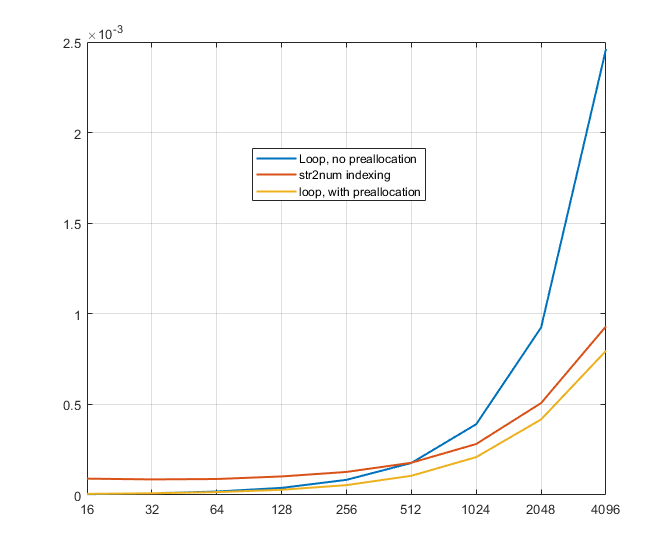
注意,这是变量,取决于所使用的索引。在下面的代码中,我会随机生成每次运行的索引,所以您可能会看到这个图有一点跳跃。
但是,带预分配的循环总是更快,而没有预分配的循环总是以指数方式爆炸。
基准代码
T = [];
p = 4:12;
for ii = p
n = 2^ii;
k = 2^(ii-2);
timesteps = reshape( sort( randperm( n, k*2 ) ).', 2, [] ).';
data = 1:n;
f_Playergod = @() f1(timesteps, data);
f_Irreducible = @() f2(timesteps, data);
f_Wolfie = @() f3(timesteps, data);
T = [T; [timeit( f_Playergod ), timeit( f_Irreducible ), timeit( f_Wolfie )]];
end
figure(1); clf;
plot( T, 'LineWidth', 1.5 );
legend( {'Loop, no preallocation', 'str2num indexing', 'loop, with preallocation'}, 'location', 'best' );
xticklabels( 2.^p ); grid on;
function newData = f1( timesteps, data )
newData=[];
for ind=1:size(timesteps,1)
newData=cat(2,newData,data(timesteps(ind,1):timesteps(ind,2)));
end
end
function newData = f2( timesteps, data )
newData = data( str2num(sprintf('%d:%d ',timesteps')) );
end
function newData = f3( timesteps, data )
N = [0; cumsum( diff( timesteps, [], 2 ) + 1 )];
newData = NaN( 1, max(N) );
for ind = 1:size(timesteps,1)
newData(N(ind)+1:N(ind+1)) = data(timesteps(ind,1):timesteps(ind,2));
end
endStack Overflow用户
发布于 2019-09-04 12:01:42
为了摆脱for循环,您可以执行以下操作:
timesteps = [1,3;5,7;9,10];
data = [1,2,3,4,5,6,7,8,9,10];
%create a index vector of the indices you want to extract
idx=str2num(sprintf('%d:%d ',timesteps'));
%done
res=data(idx)
res =
1 2 3 5 6 7 9 10然而,关于运行时,正如评论中所述,我还没有测试它,但我怀疑它是否会更快。这里唯一的优点是结果数组不必在每次迭代中更新.
Stack Overflow用户
发布于 2019-09-04 12:17:11
我通常会去做一个循环,但是你可以这样做
%take every 1st column element and 2nd column elemeent, use the range of numbers to index data
a=arrayfun(@(x,y) data(x:y),timesteps(:,1),timesteps(:,2),'UniformOutput',0)
%convert cell array to vector
a=[a{:}]我应该指出,这是比循环慢得多。
https://stackoverflow.com/questions/57787803
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号