
基于枕的低秩逼近
我试图将low-rank-approximation用于潜在语义索引。我认为做低秩近似可以减少矩阵的维数,但它与我得到的结果相矛盾。
假设我有我的字典,有40000字和2000份文件。那么我的逐个文件表是40000 x 2000。根据维基百科的说法,我必须做矩阵的SVD,然后再应用。
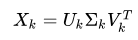
这是我用于SVD和低秩逼近的代码(矩阵是稀疏的):
import scipy
import numpy as np
u, s, vt = scipy.sparse.linalg.svds(search_matrix, k=20)
search_matrix = u @ np.diag(s) @ vt
print('u: ', u.shape) # (40000, 20)
print('s: ', s.shape) # (20, )
print('vt: ', vt.shape) # (20, 2000)结果矩阵是:(40000 X20)*(20x20)* (20,2000) =40000 x2000,这正是我开始时所做的。
所以..。低秩近似是如何精确地降低矩阵的维数的?
此外,我将对这个近似矩阵进行查询,以查找用户向量与每个文档之间的相关性(朴素搜索引擎)。用户向量从维度40000x1开始(包单词)。根据相同的维基百科页面,这是我应该做的:
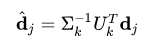
守则:
user_vec = np.diag((1 / s)) @ u.T @ user_vec它产生一个矩阵20x1,这正是我所期望的!((20x20)*(20x40000)*(40000x1)=(20x1))。但是现在,它的维数与我想要乘以的search_matrix不匹配。
所以..。我做错了什么?为什么?
资料来源:
回答 1
Stack Overflow用户
发布于 2019-10-17 12:30:37
关于低秩近似:
我们的目标是要有一个矩阵,您可以用较少的内存来存储它,并且可以使用它进行更快的计算。
但是您希望它具有与原始矩阵相同的行为(特别是相同的维度)。
这就是为什么你使用矩阵的乘积。它们给了你一个很小的等级,但不改变矩阵的尺寸。
https://stackoverflow.com/questions/56198440
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号