
使用python html错误爬行web数据
使用python html错误爬行web数据
提问于 2016-06-30 10:15:17
我想使用python爬行数据,我又试了一次,但是它没有工作,我找不到代码的错误,我编写了如下代码:
import re
import requests
from bs4 import BeautifulSoup
url='http://news.naver.com/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_week&oid=277&aid=0003773756&date=20160622&type=1&rankingSectionId=102&rankingSeq=1'
html=requests.get(url)
#print(html.text)
a=html.text
bs=BeautifulSoup(a,'html.parser')
print(bs)
print(bs.find('span',attrs={"class" : "u_cbox_contents"}))我想抓取新闻中的回复数据。
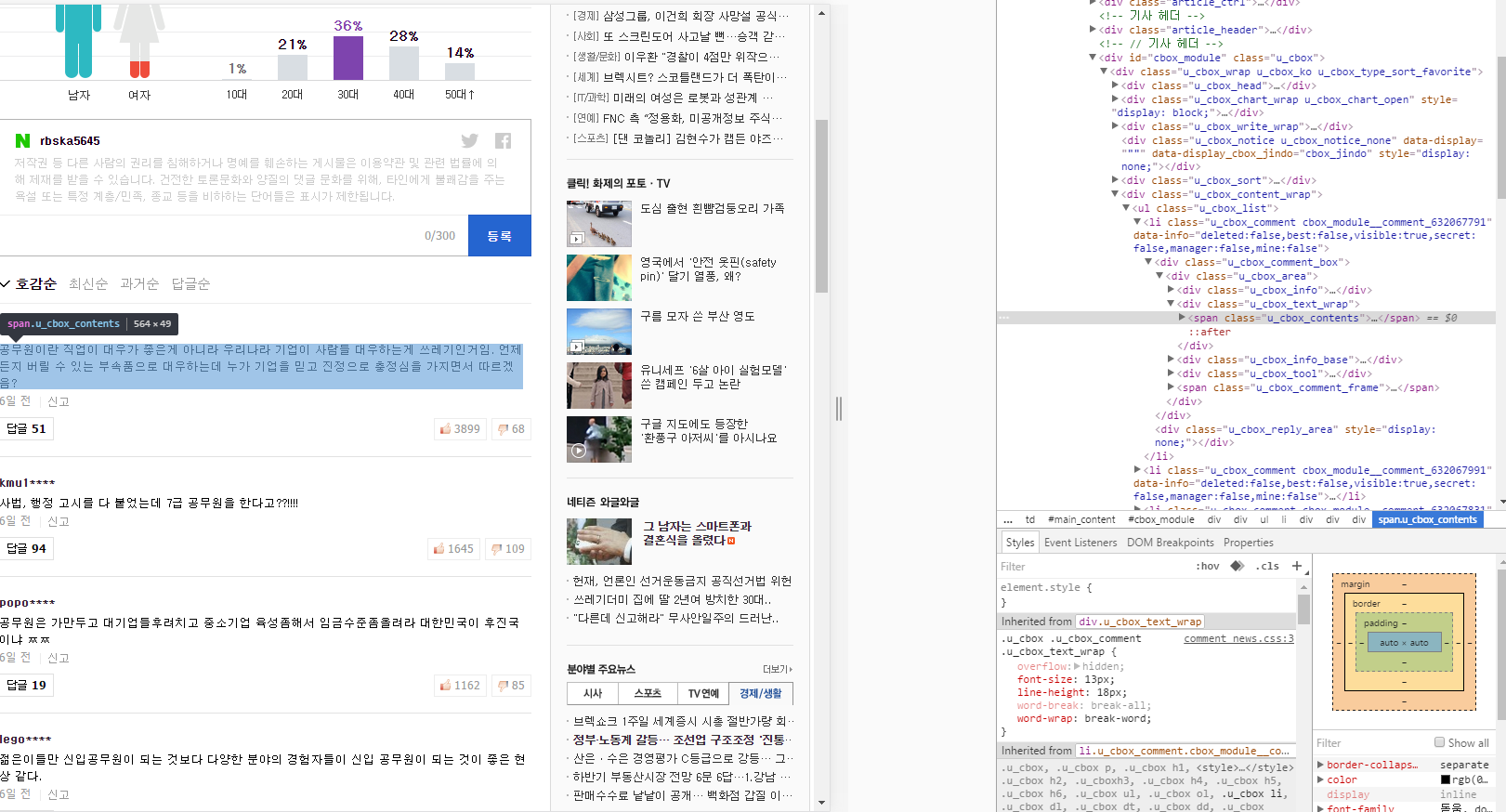
如你所见,我试着烧掉它:
斯潘,class="u_cbox_contents“在bs中
但蟒蛇只说“没有”
无
因此,我使用函数打印( bs )检查bs。
我检查bs变量的内容
但是没有跨度,class="u_cbox_contents“
为什么会发生这种事?
我真的不知道为什么
请帮帮我
谢谢你的阅读。
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-06-30 10:26:07
请求将获取URL的内容,但不会执行任何JavaScript。
我对cURL执行了相同的提取操作,并且在HTML代码中找不到任何u_cbox_contents的出现。最有可能的是,它是使用JavaScript注入的,这解释了为什么BeautifulSoup找不到它。
如果您需要页面的代码,因为它将在“普通”浏览器中呈现,您可以尝试硒。还请看一下这,所以有问题。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/38120180
复制相关文章
相似问题
腾讯云开发者
