
iText :无法从页面检索/Resources
我使用iText 5.0.1来操作现有的PDF。当使用鲁普斯分析现有的PDF时,我可以看到第一页包含一个/Resources:
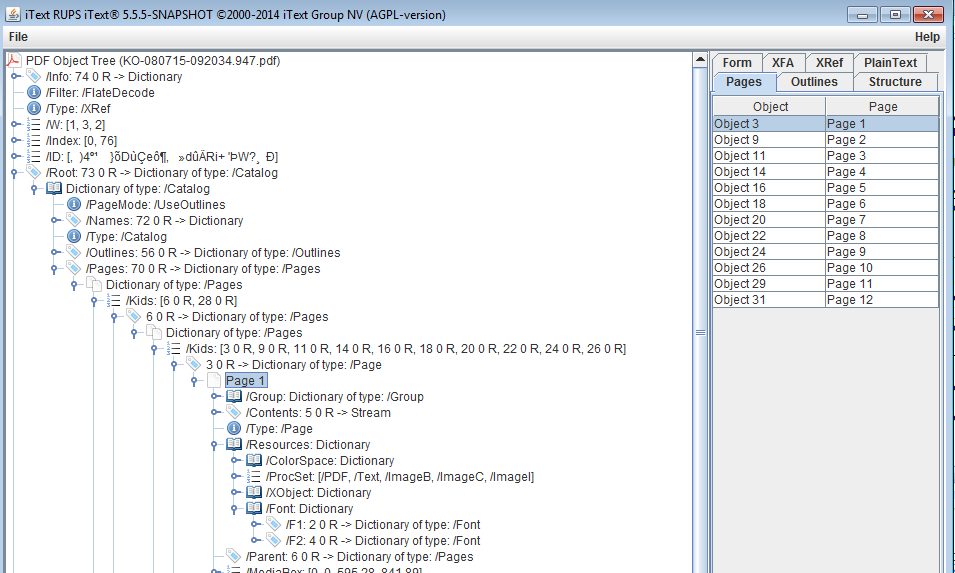
但是,当使用下面的例子操作PDF时,我会得到一个NPE,因为pageDictionary.get(PdfName.RESOURCES)返回null。
下面是我的pageDictionnary对象在调试时包含的内容:
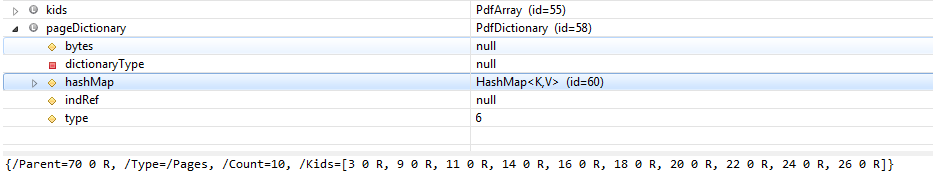
不幸的是,由于保密性,我现在不能发布PDF,但是有谁知道我为什么要得到这个NPE吗?还是有人知道如何进一步调查?(我远不是iText和PDF结构方面的专家.然后慢慢地失去想法)
非常感谢!
回答 1
Stack Overflow用户
发布于 2015-07-08 21:37:54
您使用的示例代码假设页面对象是Pages目录键所指向的字典的直接子对象:
PdfDictionary pages = (PdfDictionary) PdfReader.getPdfObject(reader.getCatalog().get(PdfName.PAGES));
PdfArray kids = (PdfArray) PdfReader.getPdfObject(pages.get(PdfName.KIDS));
PdfDictionary pageDictionary = (PdfDictionary) PdfReader.getPdfObject((PdfObject) kids.getArrayList().get(pageNum - 1));这种假设通常是可以的,因为许多PDF生产者生成简单的页面树,但通常页面树可以是一棵深度大于1的树,即它的叶子,页面节点,可能在结构中更深,根页面的子类字典等等。
在PDF的情况下,第1页(对象3)的页面字典是Pages字典对象6的子类,而后者又是根Pages字典对象70的子类。
因此,该代码假定中间Pages字典对象6已经是页面对象。
不过,这并不是该示例代码的唯一问题。例如,它还假定Resources字典附加到页面对象本身。这不一定是真的,它还可以附加到任何父页面对象,包括页面树根:
resources 字典(必需;可继承)包含页面所需的任何资源的字典(参见7.8.3,“资源字典”)。如果页面不需要任何资源,则此条目的值应为空字典。完全省略该项表示资源将从页树中的祖先节点继承。。 (表30 -页面对象中的条目-在当前的PDF规范ISO 32000-1中)
因此,您通常使用的示例是无用的,因为它不符合PDF规范。
也就是说,您的示例是在使用iText 5.0.1时,最新版本的iText为1.02b时的示例。你为什么不找一个最新的样本?这是一个奇迹,经过4个主要版本,它甚至可以调整,以方便编译!
在当前的iText版本中,您可以使用PdfReader方法getPageN(final int pageNum)或getPageNRelease(final int pageNum)获得给定页面的字典。
但是,您不应该期望当前的PdfReader方法getPageResources(final int pageNum)返回给定页面的资源,因为它(就像示例代码一样)只查看参考资料字典的Page字典
您使用iText 5.0.1有特定的原因吗?这个版本已经相当老了,并且从那时起就已经应用了许多bug修复和特性。
https://stackoverflow.com/questions/31288535
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号