
Jvm本机代码编译的疯狂--即使在编译代码之后,我似乎也遭受了一段时间的奇怪的性能损失。为什么?
问题
当用Java对一个简单的QuickSort实现进行基准测试时,我在我正在绘制的n vs time图形中遇到了意想不到的凸起:
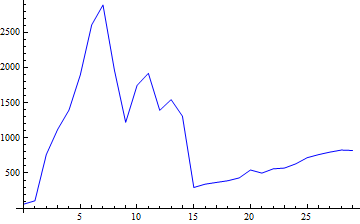
我知道,在某些方法被大量使用之后,HotSpot将尝试将代码编译为原生代码,因此我使用-XX:+PrintCompilation运行JVM。经过多次试验,它似乎总是以同样的方式编译算法的方法:
@ iteration 6 -> sorting.QuickSort::swap (15 bytes)
@ iteration 7 -> sorting.QuickSort::partition (66 bytes)
@ iteration 7 -> sorting.QuickSort::quickSort (29 bytes)我重复上面的图形与这个添加的信息,只是为了让事情变得更清楚:
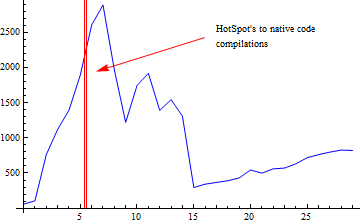
在这一点上,我们都必须扪心自问:为什么在编译代码之后,我们还会遇到这些丑陋的驼峰呢?也许这和算法本身有什么关系?当然可以,幸运的是,我们有一个快速的方法来解决这个问题,用-XX:CompileThreshold=0
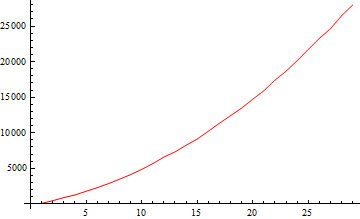
令人扫兴!这一定是JVM在后台做的事情。但是什么呢?我从理论上说,虽然正在编译代码,但可能需要一段时间才能真正开始使用编译过的代码。也许在这里和那里添加几个Thread.sleep()可以帮助我们解决这个问题吗?
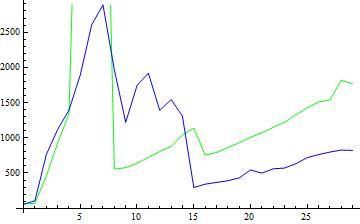
唉哟!绿色函数是快速排序的代码,每次运行之间有一个1000‘s的内部代码(详见附录),而蓝色函数是我们的旧函数(仅供参考)。
首先,给HotSpot留出时间似乎只会使事情变得更糟!也许其他因素,比如缓存问题,似乎只会让情况变得更糟?
免责声明:我正在运行1000次试验,每一点显示的图形,并使用System.nanoTime()来测量结果。
编辑
在这个阶段,你们中的一些人可能会想知道sleep()的使用会如何扭曲结果。我再次运行了“红色情节”(没有本机编译),现在在中间睡觉:
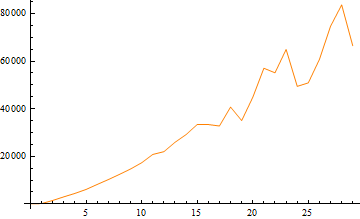
可怕!
附录
这里我展示了我正在使用的QuickSort代码,以防万一:
public class QuickSort {
public <T extends Comparable<T>> void sort(int[] table) {
quickSort(table, 0, table.length - 1);
}
private static <T extends Comparable<T>> void quickSort(int[] table,
int first, int last) {
if (first < last) { // There is data to be sorted.
// Partition the table.
int pivotIndex = partition(table, first, last);
// Sort the left half.
quickSort(table, first, pivotIndex - 1);
// Sort the right half.
quickSort(table, pivotIndex + 1, last);
}
}
/**
* @author http://en.wikipedia.org/wiki/Quick_Sort
*/
private static <T extends Comparable<T>> int partition(int[] table,
int first, int last) {
int pivotIndex = (first + last) / 2;
int pivotValue = table[pivotIndex];
swap(table, pivotIndex, last);
int storeIndex = first;
for (int i = first; i < last; i++) {
if (table[i]-(pivotValue) <= 0) {
swap(table, i, storeIndex);
storeIndex++;
}
}
swap(table, storeIndex, last);
return storeIndex;
}
private static <T> void swap(int[] a, int i, int j) {
int h = a[i];
a[i] = a[j];
a[j] = h;
}
}此外,我用来运行我的基准测试的代码:
public static void main(String[] args) throws InterruptedException, IOException {
QuickSort quickSort = new QuickSort();
int TRIALS = 1000;
File file = new File(Long.toString(System.currentTimeMillis()));
System.out.println("Saving @ \"" + file.getAbsolutePath() + "\"");
for (int x = 0; x < 30; ++x) {
// if (x > 4 && x < 17)
// Thread.sleep(1000);
int[] values = new int[x];
long start = System.nanoTime();
for (int i = 0; i < TRIALS; ++i)
quickSort.sort(values);
double duration = (System.nanoTime() - start) / TRIALS;
String line = x + "\t" + duration;
System.out.println(line);
FileUtils.writeStringToFile(file, line + "\r\n", true);
}
}回答 1
Stack Overflow用户
发布于 2012-04-05 22:08:06
看来我自己解决了这个问题。
我认为编译后的代码可能需要一段时间才能启动的想法是正确的。问题在于我实际实现基准代码的方式存在缺陷:
if (x > 4 && x < 17)
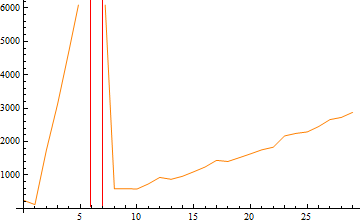
Thread.sleep(1000);在这里,我假设,由于唯一受影响的区域是4到17之间,我可以继续,只需对这些值做一个睡眠。但事实并非如此。以下情节可能具有启发性:
这里我是比较原始的无编译功能(红色)和另一个无编译功能,但与睡眠之间的区别。正如您可能看到的那样,它们以不同的数量级工作,这意味着将代码的结果与不睡觉的结果混合在一起将产生不可靠的结果,正如我所做的那样。
最初的问题至今仍未解决。是什么使驼峰在编译发生后也会出现?让我们试着找出这一点,把1s睡眠放在所有要点上:
会产生预期的结果。奇怪的驼峰正在发生,本地代码仍然没有出现。
将睡眠50 the与睡眠1000 the函数进行比较,将再次产生预期的结果:
(灰色的似乎仍有一点延迟)
https://stackoverflow.com/questions/10036280
复制相似问题
腾讯云开发者
