
将原始文本数据格式化为使用熊猫的列
将原始文本数据格式化为使用熊猫的列
提问于 2021-03-30 10:17:11
我正在使用熊猫构建一个平面文件,它包含了年龄、性别、行为等项目的属性。我所拥有的只是一个平面文件,它由每个项目的唯一键组成,还有一个文本列,其中的属性列表不指定他们正在谈论的属性,与下表相似。

然后属性在一个文件中是这样的。它说明了物品的性质,是否可供男性、女性和年龄等人食用。
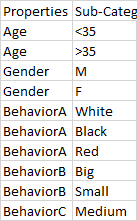
table1和table2中的文本
我期待作出最后的数据框架如下。

有人能让我知道简单的方法吗。
提前谢谢你!
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-03-30 10:54:09
您可以通过创建一个主字典来查找值和创建dataframe来做到这一点。
以下是几个步骤:
- 是带有属性和子类别的平面文件.创建一个以子类别为键,属性为值的主查找字典.这允许我们查找子类别并找到属性值.
。
- 读取文件中的每一行。然后用逗号把它们分开。然后取每个值并查找我们在步骤1.
中创建的主查找字典。
- 确保我们捕获每一行的索引(ItemA,ItemB)。
- 创建具有索引键和属性的数据字典。
- 使用数据字典创建数据框架。然后转置,得到键作为索引.
这是密码。
master_dict = {'<35':'Age','>35':'Age','M':'Gender','F':'Gender','White':'BehaviorA','Black':'BehaviorA',
'Red':'BehaviorA','Big':'BehaviorB','Small':'BehaviorB','Medium':'BehaviorC'}
file_data = '''\
Index,Properties
ItemA,F,Red,Small,Medium,<35
ItemB,>35,Black,Big,M'''
#initialize the pandas dataframe dictionary
data_dict = {}
#iterate through each row in the file
for i, line in enumerate(file_data.split('\n')):
#ignore header row (i == 0)
if i == 0:continue
#remove \n and leading spaces. split on comma
prop = line.strip().split(',')
#initialize dict for each item
d = {}
for ix, p in enumerate(prop):
#capture index values (ItemA, ItemB)
if ix == 0: key = p;continue
#for all others, get the column header and value
#column header is mapped to the value in the master dictionary; use that
else: d[master_dict[p]]=p
#create a row with the index value
data_dict[key] = d
#once all the rows have been added to the data dictionary, its ready for us to create a dataframe
import pandas as pd
#create a dataframe with the data dictionary. transpose will ensure keys are set as index
df = pd.DataFrame(data_dict).T
print (df)这方面的产出如下:
Gender BehaviorA BehaviorB BehaviorC Age
ItemA F Red Small Medium <35
ItemB M Black Big NaN >35页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66869037
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号