GKE自动驾驶仪在部署后5-15分钟内返回502错误
我在运行最新版本的Kubernetes (1.18.15-gke.1501)的GKE集群上设置了一个(非常)简单的GKE部署,并附加了一个连接到简单ClusterIP服务的入口(外部HTTP(s)负载均衡器)。
每当我用新映像更新部署时,我都会经历大约5-15分钟的停机时间,其中负载均衡器返回502错误。似乎控制平面创建了新的,更新的吊舱,允许服务级别的健康检查通过(不是负载平衡器,它还没有创建NEG ),然后杀死旧的吊舱,同时设置新的NEG。然后,它不会删除旧的NEG,直到一个可变的时间后。
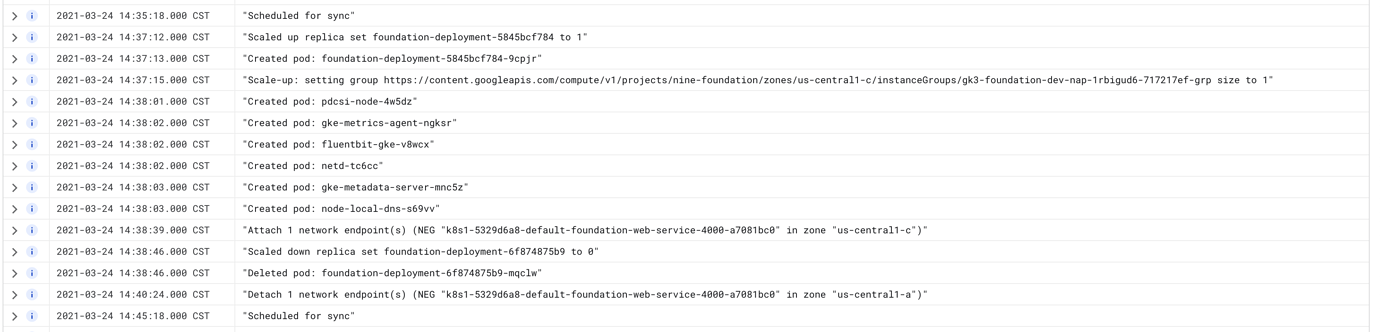
豆荚上的日志显示正在进行健康检查,但GKE仪表板显示的结果不一致。入口将显示为罚款,但服务将502。
我试过的东西
- 将吊舱数量从1增加到3,这对一些部署有所帮助,但在其他部署中,它增加了负载均衡器正确解析所需的时间。
- 尝试将
maxSurge设置为1,maxUnavailable设置为0。这根本没有改善停机时间。 - 在部署中将
lifecycle.preStop.exec.command: ["sleep", "60"]添加到容器。这是在这里的GKE文档中提出的。 - 多次重新创建入口、服务、部署和群集。
- 向服务中添加一个
BackendConfig,这会使它的消耗速度更慢。 - 在文档中添加一个准备好的门来修复这个问题,但出于某种原因却没有?
上述任何一项都没有对事情持续多久有所帮助,也没有产生任何明显的影响。
我真的,真的很困惑为什么这不起作用。感觉好像我错过了一些很明显的东西,但这也是一个简单的配置,你会认为它会.只是工作??有人知道这是怎么回事吗?
配置文件
部署配置:
apiVersion: apps/v1
kind: Deployment
metadata:
name: foundation-deployment
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 1
selector:
matchLabels:
app: foundation-web
template:
metadata:
labels:
app: foundation-web
spec:
readinessGates:
- conditionType: "cloud.google.com/load-balancer-neg-ready"
serviceAccountName: foundation-database-account
containers:
# Run Cloud SQL proxy so we can safely connect to Postgres on localhost.
- name: cloud-sql-proxy
image: gcr.io/cloudsql-docker/gce-proxy:1.17
resources:
requests:
cpu: "250m"
memory: 100Mi
limits:
cpu: "500m"
memory: 100Mi
command:
- "/cloud_sql_proxy"
- "-instances=nine-foundation:us-central1:foundation-staging=tcp:5432"
securityContext:
runAsNonRoot: true
# Main container config
- name: foundation-web
image: gcr.io/project-name/foundation_web:latest
imagePullPolicy: Always
lifecycle:
preStop:
exec:
command: ["sleep", "60"]
env:
# Env variables
resources:
requests:
memory: "500Mi"
cpu: "500m"
limits:
memory: "1000Mi"
cpu: "1"
livenessProbe:
httpGet:
path: /healthz
port: 4000
initialDelaySeconds: 10
periodSeconds: 10
readinessProbe:
httpGet:
path: /healthz
port: 4000
initialDelaySeconds: 10
periodSeconds: 10
ports:
- containerPort: 4000服务配置:
apiVersion: v1
kind: Service
metadata:
name: foundation-web-service
annotations:
cloud.google.com/neg: '{"ingress": true}'
cloud.google.com/backend-config: '{"ports": {"4000": "foundation-service-config"}}'
spec:
type: ClusterIP
selector:
app: foundation-web
ports:
- port: 4000
targetPort: 4000BackendConfig:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: foundation-service-config
spec:
# sessionAffinity:
# affinityType: "GENERATED_COOKIE"
# affinityCookieTtlSec: 120
connectionDraining:
drainingTimeoutSec: 60入口配置:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: foundation-web-ingress
labels:
name: foundation-web-ingress
spec:
backend:
serviceName: foundation-web-service
servicePort: 4000回答 1
Stack Overflow用户
发布于 2021-08-10 09:34:48
我认为这可能与云sql auth代理侧服务器没有正确终止有关,从而导致负载均衡器出现扭曲。
请注意,这是从GCP文档 (我已经做了关键部分斜体)
症状 502错误或拒绝连接。潜在的原因新端点通常会在将它们附加到负载均衡器后变得可访问,只要它们对健康检查作出响应。如果通信量无法到达端点,则可能会遇到502错误或拒绝连接。 502错误和拒绝连接也可能由不处理SIGTERM的容器引起。如果容器没有显式处理SIGTERM,它会立即终止并停止处理请求。负载均衡器继续向终止的容器发送传入通信量,从而导致错误。 容器本机负载均衡器只有一个后端端点。在滚动更新期间,旧端点在新端点被编程之前被取消编程。 后端Pod(s)在配置容器本机负载均衡器后首次部署到新区域。当区域中至少有一个端点时,负载平衡器基础结构被编程在一个区域中。当一个新的端点被添加到一个区域时,负载平衡器基础结构会被编程并导致服务中断。 分辨率 配置容器以处理SIGTERM,并在整个终止宽限期内继续响应请求(默认情况下为30秒)。配置Pods,使其在接收SIGTERM时开始失败健康检查。这指示负载均衡器停止向Pod发送流量,而端点解程序正在进行中。
默认情况下,代理不会很好地处理SIGTERM,并且不会在SIGTERM上优雅地退出(请参阅相关问题),但是它现在有一个很好的标志来处理这个问题,所以您可以使用如下
- name: cloud-sql-proxy
image: gcr.io/cloudsql-docker/gce-proxy:1.23.1
command:
- "/cloud_sql_proxy"
- "-instances={{ .Values.postgresConnectionName }}=tcp:5432"
- "-term_timeout=60s"
securityContext:
runAsNonRoot: true
resources:
requests:
memory: "2Gi"
cpu: "1"添加term_timeout标志主要是为我修复了它,但在部署过程中仍然偶尔看到502。将副本提高到3(我的集群是区域性的,所以我想覆盖所有的区域),这似乎很有帮助,因为我已经安装了term_timeout。
https://stackoverflow.com/questions/66810269
复制相似问题
腾讯云开发者
