
想要一个根据条件给出列的最大值的groupby
想要一个根据条件给出列的最大值的groupby
提问于 2021-10-22 16:56:07
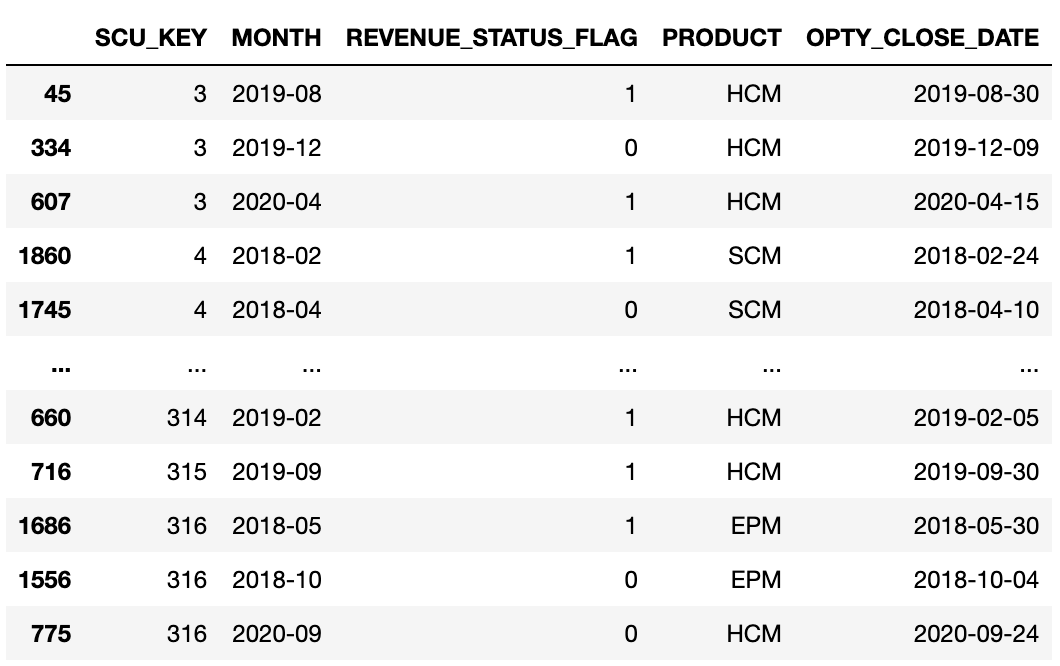
我试图得到'OPTY_CLOSE_DATE‘的最大值,按'SCU_KEY’分组为每个产品。结果将填充到一个名为'END_DATE‘的新列上。尽管可能有一段代码可以为每个产品获得这个数字,而不必执行3组代码,但我们可以只关注于产品“HCM”的代码,因为只有3个产品(但是如果您能够完成捕获每个产品的代码,则可以得到额外的点数)。如果需要指定,其他产品现在可以使用NaN填充。没有得到正确的结果,所以让我知道如何才能做到正确。数据帧的图像附后。THe正确的结果将显示前三行的“END_DATE”(SCU_KEY = 3)将是“2020-04-15”。SCU_KEY 314将有'2019-02-05';SCU_KEY 315将有'2019-02-05';SCU_KEY 316将只有'2020-09-24‘,而之前的2个值将是NaN,因为产品是EPM而不是HCM。为了实现这一点,我的代码如下所示:
df_5['END_DATE'] = df_5[df_5['PRODUCT'] =='HCM'].groupby('SCU_KEY')['OPTY_CLOSE_DATE'].max()
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-10-22 18:26:24
使用“转换”和“按感兴趣的两列分组”。
data = np.array([
[3,3,3,4,4,314,315,316,316,316],
['HCM','HCM','HCM','SCM','SCM','HCM','HCM','EPM','EPM','HCM'],
['2019-08-30','2019-12-09','2020-04-15','2019-02-24','2018-04-10',
'2019-02-05','2019-09-30','2018-05-30','2018-10-04','2020-09-24']
])
df = pd.DataFrame(data = data.T, columns = ['scu_key', 'product', 'opty_close_date'])
df['opty_close_date'] = pd.to_datetime(df['opty_close_date'])
# if you want to preserve the df as is and just add a max date column
df['max_date'] = (
df.groupby(['scu_key','product'])['opty_close_date'].transform('max')
)输出:
scu_key product opty_close_date max_date
0 3 HCM 2019-08-30 2020-04-15
1 3 HCM 2019-12-09 2020-04-15
2 3 HCM 2020-04-15 2020-04-15
3 4 SCM 2019-02-24 2019-02-24
4 4 SCM 2018-04-10 2019-02-24
5 314 HCM 2019-02-05 2019-02-05
6 315 HCM 2019-09-30 2019-09-30
7 316 EPM 2018-05-30 2018-10-04
8 316 EPM 2018-10-04 2018-10-04
9 316 HCM 2020-09-24 2020-09-24页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69680593
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号