
使用包含"not“一词的Gensim短语来进行情感分析
我正在做一个情感分析项目,在这个项目中,我分析了大量的文件,我并没有把“不”这个词作为临时词删除,这样我就可以用它来判断一个文本是否同意或不同意某件事。例如,在讨论COVID疫苗时,“无效”和“有效”是有区别的。
然而,我的短语并没有用“not”这个词来识别任何生词。我推测这是因为这个标记存在于如此大的数字中(特别是因为我扩展了收缩,所以“不是”“->”不是“),所以评分函数只是简单地用"not”太低来打分所有的值。这是因为标准短语评分功能是:
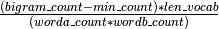
(其中min_count是一个超参数)
因此,由于数据库中有数千次"not“存在,所以worda_count将是非常大的,导致一个大分母并大大降低分数。
有没有办法解决这个问题,这样“不”的大写就会被有效地打分吗?
我可以从我的头顶上想出几个选择:
- 编写了我自己的评分函数,它实际上有两个评分公式:标准评分公式,如果第一个单词为“not”,则使用不同的评分公式。--
- I可以在
connector_words列表中包含"not“,但是gensim.models.phrases.Phraser明确指出这些连接器词不能位于短语的开头或结尾。
回答 1
Stack Overflow用户
发布于 2022-03-18 08:31:09
正如您所发现的,Gensim中的Phrases功能非常粗糙:它只结合了基于意义的单词--不经意的统计分析。它更可能有助于推广某些名词短语('new_york')或成语,而不是一般的句法倒转意义(如添加的'not')。所以你是否想使用它,我不确定。
您可以尝试最简单的事情:预处理始终将'not'附加到以下单词。也许能帮上忙!
您还可以尝试一些昂贵的语法感知预处理--使用词性的部分来标记单词,并进一步识别特定'not'修改的其他单词/单词。这可能会让你有条件地将'not'连接到后面的单词--甚至可能是非连词--也许这将为下游的情绪分析提供一种提升。
https://stackoverflow.com/questions/71515751
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号