TSBS 实测 | 写入差17倍、查询差514倍!不同时序数据库性能差距究竟有多大?
原创
TSBS 实测 | 写入差17倍、查询差514倍!不同时序数据库性能差距究竟有多大?
原创
DolphinDB
发布于 2026-05-27 17:24:08
发布于 2026-05-27 17:24:08
对于许多物联网企业而言,时序数据库(TSDB)已经成为数据架构中的关键一环。随着设备数量从数百台增长到数万、甚至千万台,早期选定的数据库往往会遭遇性能瓶颈:数据入库越来越慢,磁盘空间迅速耗尽,一些稍微复杂的分析查询直接超时或报错。
这些问题与数据库的底层架构和处理能力密切相关。为了客观评估当前主流时序数据库在大规模 IoT 场景下的表现,我们基于标准的 TSBS(Time Series Benchmark Suite)测试框架,模拟了一家货运公司的车队数据,对 DolphinDB、InfluxDB、TimescaleDB 三款产品进行系统对比,供大家参考。
结果显示,在所有测试场景中,DolphinDB 的综合性能最优,且设备越多优势越明显。例如,在1000万台设备场景下,DolphinDB 的写入速度比 InfluxDB 快 17 倍、比 TimescaleDB 快 2 倍;面对相同查询任务,DolphinDB 的查询性能较其他两者实现了数量级提升,耗时缩短数百倍。
接下来,我们将详细拆解三款时序数据库在 IoT 场景下的真实表现。
一、测试场景
本次测试采用 TSBS 标准 IoT 场景的基础数据集,模拟一家货运公司多辆货车持续上报数据的真实业务环境,分别考察系统写入性能、磁盘空间占用以及 12 类典型查询的响应表现。整个基准测试共覆盖五个场景,各场景在数据规模与特征上有所差异,具体如下:
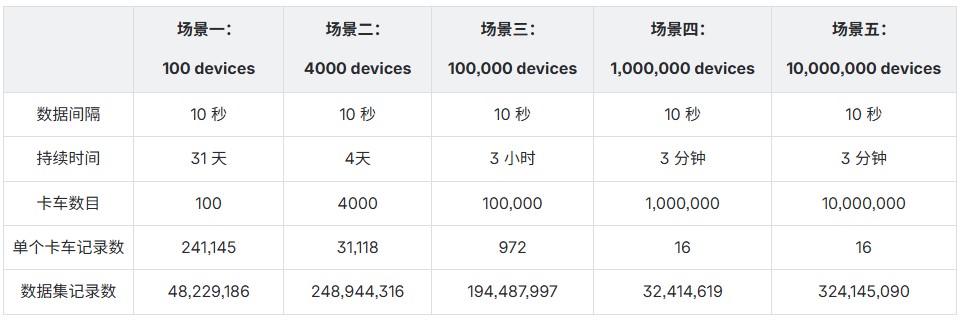
测试数据内容不仅包含每辆车的运行指标和诊断信息,还引入了更贴近实际的环境因素,例如乱序数据和批量摄取(针对离线一段时间后再上线的货车)。在数据组织上,测试同时记录货车的元信息作为查询集的一部分,将指标与诊断信息关联起来,使查询不仅停留在简单状态获取,还能够支持更复杂的分析需求。本次测试中的查询类型既覆盖实时状态监控,也包含基于历史数据的分析型查询,例如通过时间序列数据对车辆行为进行预测。
每个货车的诊断数据(diagnostics)记录包含 1 个(纳秒分辨率)时间戳和 3 个测量值,8 个标签值;货车的指标信息(readings)记录包含 1 个(纳秒分辨率)时间戳和 7 个测量值,8 个标签值。部分数据展示见图 1-1 和图 1-2。
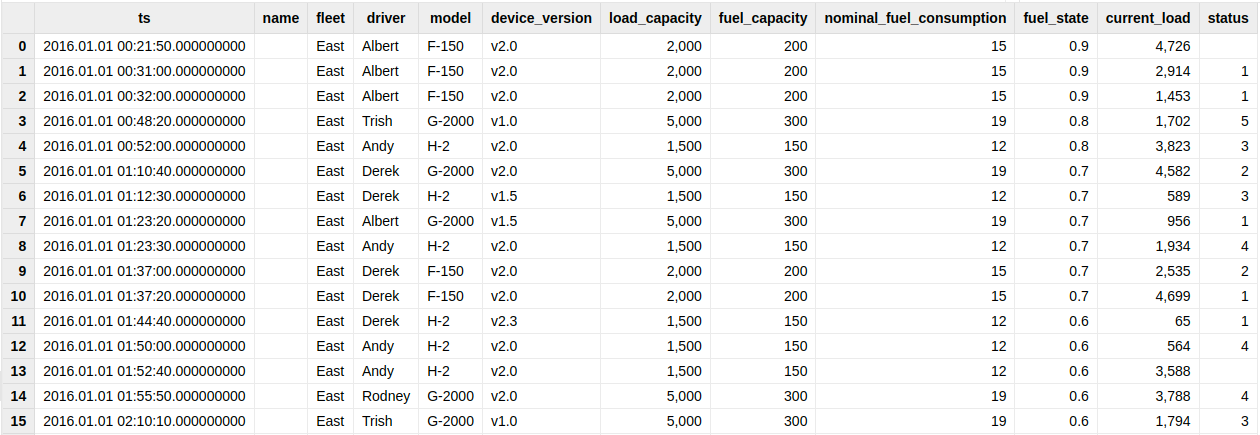
图 1-1 diagnostics 部分示例数据
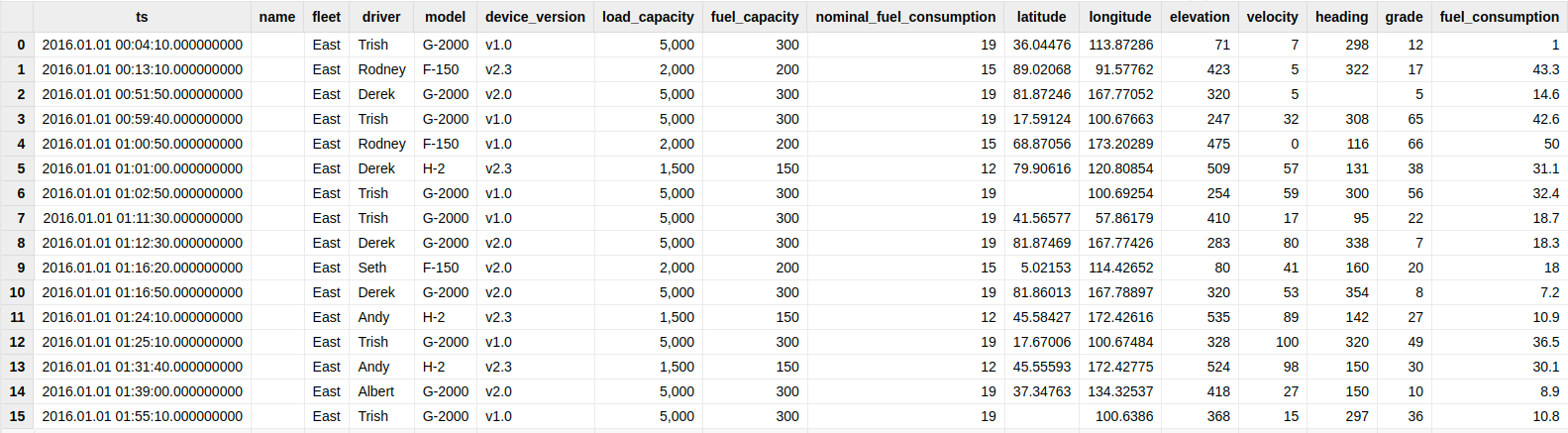
图 1-2 readings 部分示例数据
二、环境配置
三个数据库采用同一个服务器进行测试。
硬件配置
- CPU:Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
- CPU cores:64
- 内存:512G(32*16 DDR4 2400 MT/s)
- 硬盘:3.2 TB SSD
软件版本
- DolphinDB Server V3.00.5
- InfluxDB V1.8.10
- TimescaleDB V2.10.1
本次测试过程中,上述软件都采用单节点模式。
关键参数
分别设置各软件的关键参数以优化测试性能数据。
- DolphinDB
开启 TSDB 块缓存,调用 setTSDBBlockCacheSize(50) 函数设置为 50GB 。
- InfluxDB
cache-max-memory-size = "80g"
max-values-per-tag = 0
index-version = "tsi1"
compact-full-write-cold-duration = "30s"将写缓存上限设置为 80GB,降低频繁刷盘对写入性能的影响; 取消 tag 值数量限制,避免高基数设备场景受限; 采用面向高基数场景的 TSI 索引,降低内存压力; 将完整压缩触发时间设置为 30 秒,加快数据整理与查询优化。
- TimescaleDB
按不同场景配置不同的 CHUNK_TIME,参数的设置如下表所示。
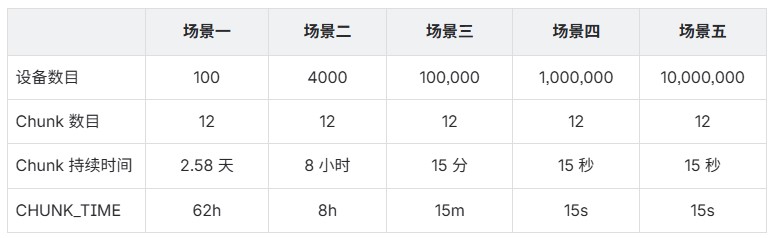
CHUNK_TIME:用于定义 TimescaleDB 中每个数据分块(chunk)覆盖的时间范围,即按多长时间切分一次时序数据。
三、写入性能对比
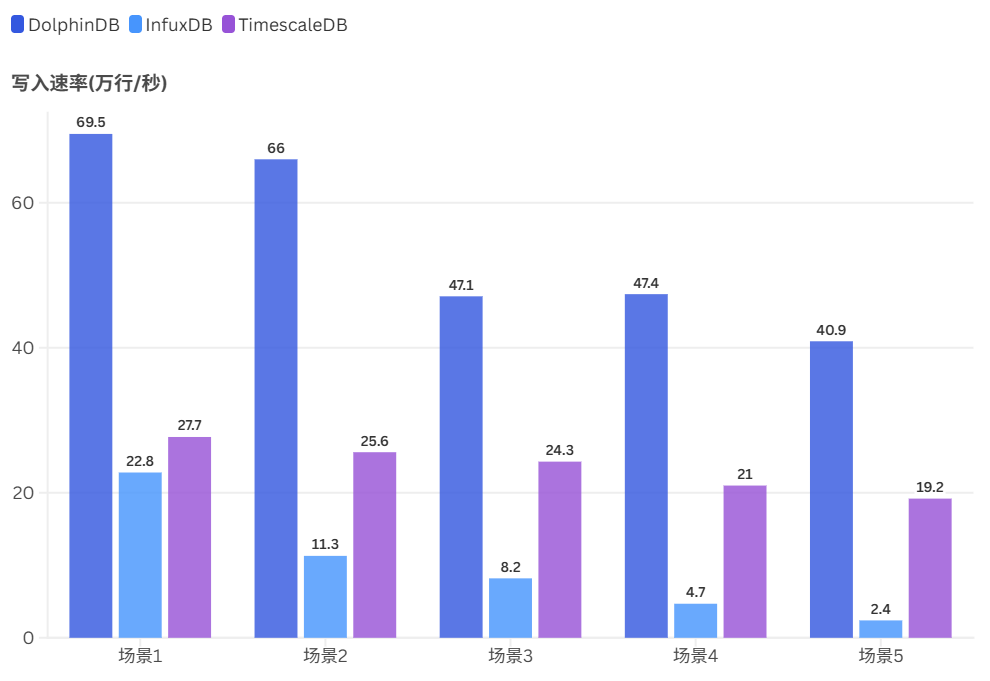
以下是5个场景中 DolphinDB、InfluxDB、TimescaleDB 的写入性能测试结果, 单位为万行/秒:
各场景磁盘占用量如下:
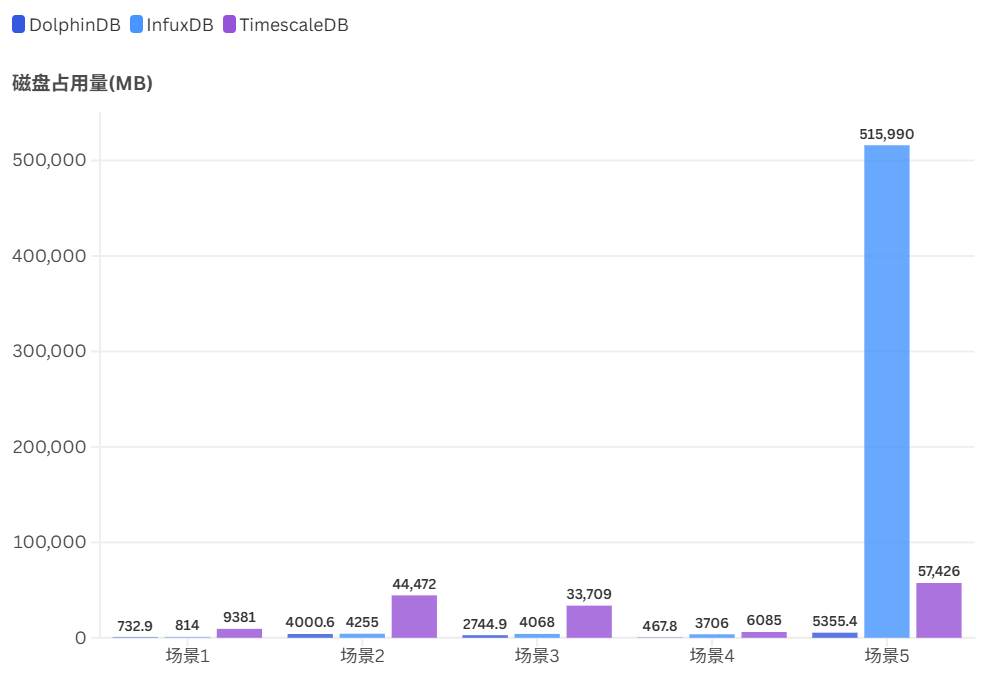
整体来看,DolphinDB 在各场景下均表现出更高的写入速率和压缩率,且在数据规模增大时优势更加明显。
随着设备规模增长,InfluxDB 与 TimescaleDB 的写入吞吐出现了明显衰减,而 DolphinDB 的下降幅度相对平缓。在 1000 万台设备的场景中,DolphinDB 的写入速度维持在 40.9万行/秒,InfluxDB 则下降至 2.4万行/秒,TimescaleDB 下降至 19.2万行/秒,差距扩大至 2.1倍~17倍。
DolphinDB 在 TSBS IoT 场景下展现出的高写入性能(最高可达 69.5万行/秒),得益于其存储引擎对 LSM-Tree 架构的深度优化。它通过将大量随机写入转换为高效的顺序写入,充分释放了磁盘带宽,有效避免了传统 B+ 树引擎在大规模写入场景下容易出现的性能瓶颈。
四、查询性能对比
我们从中选取三个典型场景展示 DolphinDB、InfluxDB、TimescaleDB 查询性能测试结果。
场景二:4000台设备测试
完整查询测试结果如下:
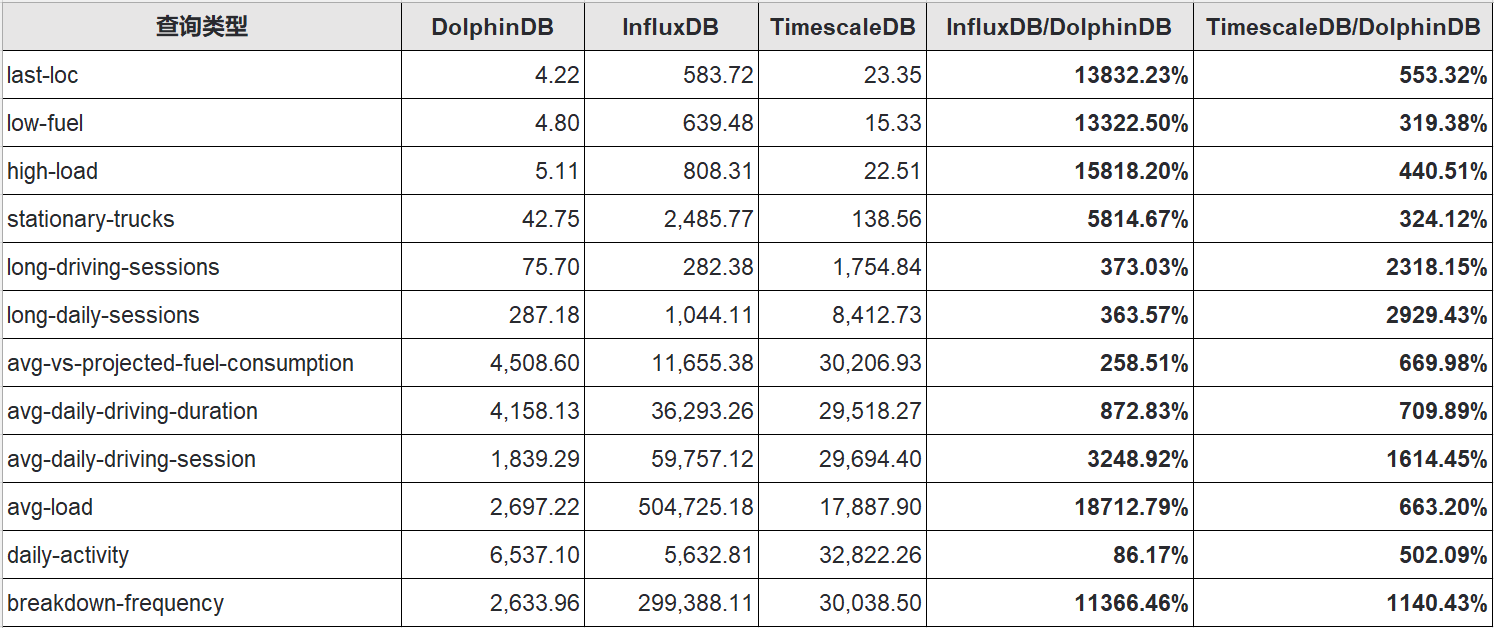
场景二查询性能对比表(单位: ms)
典型查询结果对比如下:
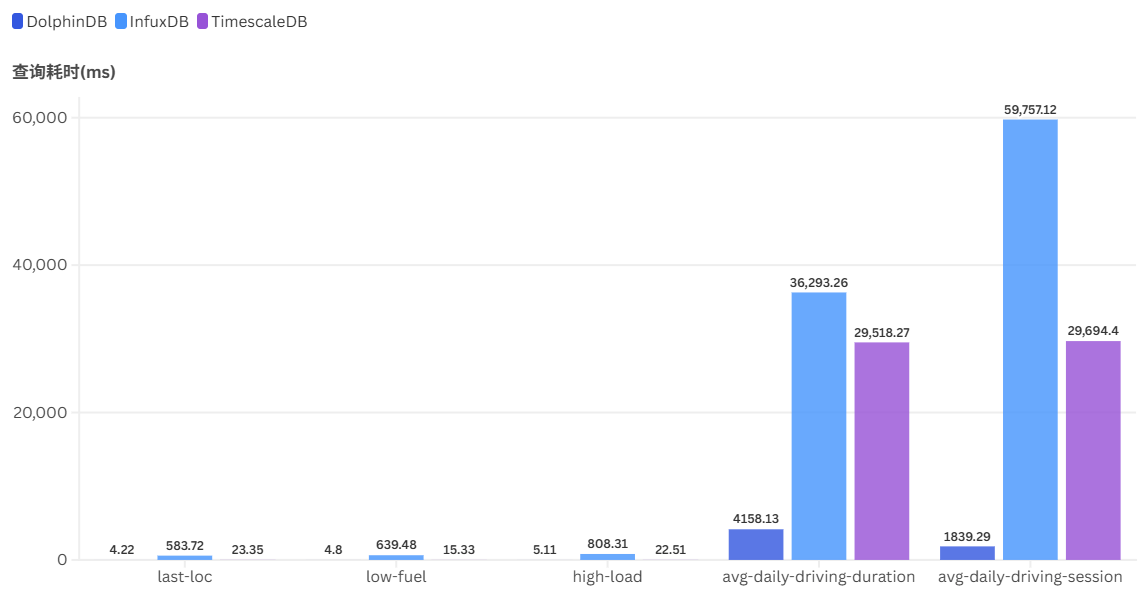
在场景二4000台设备的规模下,DolphinDB 在几乎所有查询项上的响应时间都更短、查询吞吐更高。在进行最新值查询时,得益于物联网点位管理引擎的最新值查询优化,DolphinDB 的响应时间能稳定保持在毫秒级。能够有效应对应用对应设备最新值查询的需求。
场景三:100,000台设备测试

场景三查询性能对比表(单位: ms)
在10万台设备的规模下,DolphinDB 展现了卓越的大规模设备管理能力,last-loc 这类高频点查性能仍能稳定在100毫秒以内,性能衰减速度远低于数据规模增长速度。
场景五:10,000,000台设备测试

场景五查询性能对比表(单位: ms)
在1000万台设备的规模下,DolphinDB 的性能优势进一步显现,与其他两者的查询性能差距扩大至900%,且最新值相关查询耗时在1秒左右,性能优异。
五、总结
在本次 TSBS IoT 场景测试中,DolphinDB 相较 InfluxDB、TimescaleDB,在写入吞吐、查询性能、数据压缩率等方面都表现出了极为突出的优势,特别是在十万、百万、千万级设备规模下,性能差距被逐步拉大。
目前,DolphinDB 已广泛应用于电力、高端制造、车联网、公用事业等各类物联网场景。无论是工业设备的健康管理,还是能源电力系统的实时监控,DolphinDB 都能凭借强大的存算能力,为企业提供稳定、高效的解决方案。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号