工业物联网实时分析技术研究:一体化时序数据库架构演进分析
原创
工业物联网实时分析技术研究:一体化时序数据库架构演进分析
原创
用户12507396
发布于 2026-05-23 17:47:44
发布于 2026-05-23 17:47:44
工业物联网实时分析技术研究:一体化时序数据库架构演进分析
【摘要】随着工业物联网传感器密度的持续提升,传统"组件堆叠式"数据架构在实时性、一致性和运维效率方面面临严峻挑战。本文通过分析工业现场数据处理的实际困境,探讨了存算一体、流批一体、多模融合等架构创新方向,并结合能源、制造、钢铁等行业的工程实践,论证了一体化时序数据库架构的技术可行性。研究表明,融合架构在写入吞吐、查询延迟、分析效率等维度较传统方案具有显著优势,为工业智能化转型提供了可行的技术路径。
【关键词】工业物联网;时序数据库;存算一体;流批一体;实时分析
一、研究背景与问题提出
工业物联网(Industrial Internet of Things, IIoT)作为智能制造的核心基础设施,其数据处理能力直接决定了生产系统的响应速度与决策质量。根据中国信息通信研究院发布的《工业互联网白皮书》,2025年我国工业互联网产业规模预计突破1.5万亿元,其中数据智能分析占比持续提升。然而,在产业快速发展的同时,底层数据架构的瓶颈日益凸显。
笔者在多个智能制造项目的调研中发现,工业现场普遍存在"数据沉睡"现象:传感器持续产生海量时序数据,但这些数据大多仅用于事后追溯,难以支撑实时决策。造成这一现象的根本原因,在于传统数据架构的设计理念与工业场景的实时性需求之间存在结构性矛盾。
1.1 传统架构的实时性瓶颈
现代工业设备的传感器密度已达到较高水平。以高端数控机床为例,其振动传感器采样频率可达10kHz;新能源汽车电池产线的单条产线测点数通常超过50万。这意味着系统需要处理每秒数千万甚至上亿条时序记录。
传统时序数据库通过水平扩展存储节点,在写入环节通常能够应对上述流量。但在查询环节,即使是一条简单的滑动平均值计算请求,响应时间也可能从数秒延长至数分钟。在工业现场,轴承异常振动、反应釜温度漂移等故障征兆的窗口期往往只有毫秒至秒级,查询延迟直接决定了预警系统的实际价值。
1.2 组件异构导致的语义断层
为应对复杂分析需求,企业通常采用"组件堆叠"方案:消息队列负责数据接入,流处理引擎负责实时计算,专用时序库负责存储,离线分析框架负责历史数据挖掘,Python集群负责AI推理。这种架构虽然功能完备,但存在三个结构性缺陷:
- 数据搬运开销:同一份数据在多个系统间流转,网络I/O成为性能瓶颈;
- 语义不一致:流处理与批处理使用不同的API和计算模型,同一业务逻辑需要重复实现;
- 运维复杂度高:每个组件独立部署、独立监控,运维团队需要掌握多种技术栈。
1.3 AI工程化落地的架构鸿沟
工业智能化的核心诉求是实现预测性维护、工艺优化等数据驱动应用。但在工程实践中,算法模型与生产系统之间存在显著的部署鸿沟:离线训练好的模型需要经过格式转换、接口封装、性能调优等工程化改造才能上线;模型迭代所需的生产数据难以高效回传至研发环境;特征工程逻辑在离线训练与在线推理之间无法复用。这些问题导致大量概念验证项目止步于试点阶段。
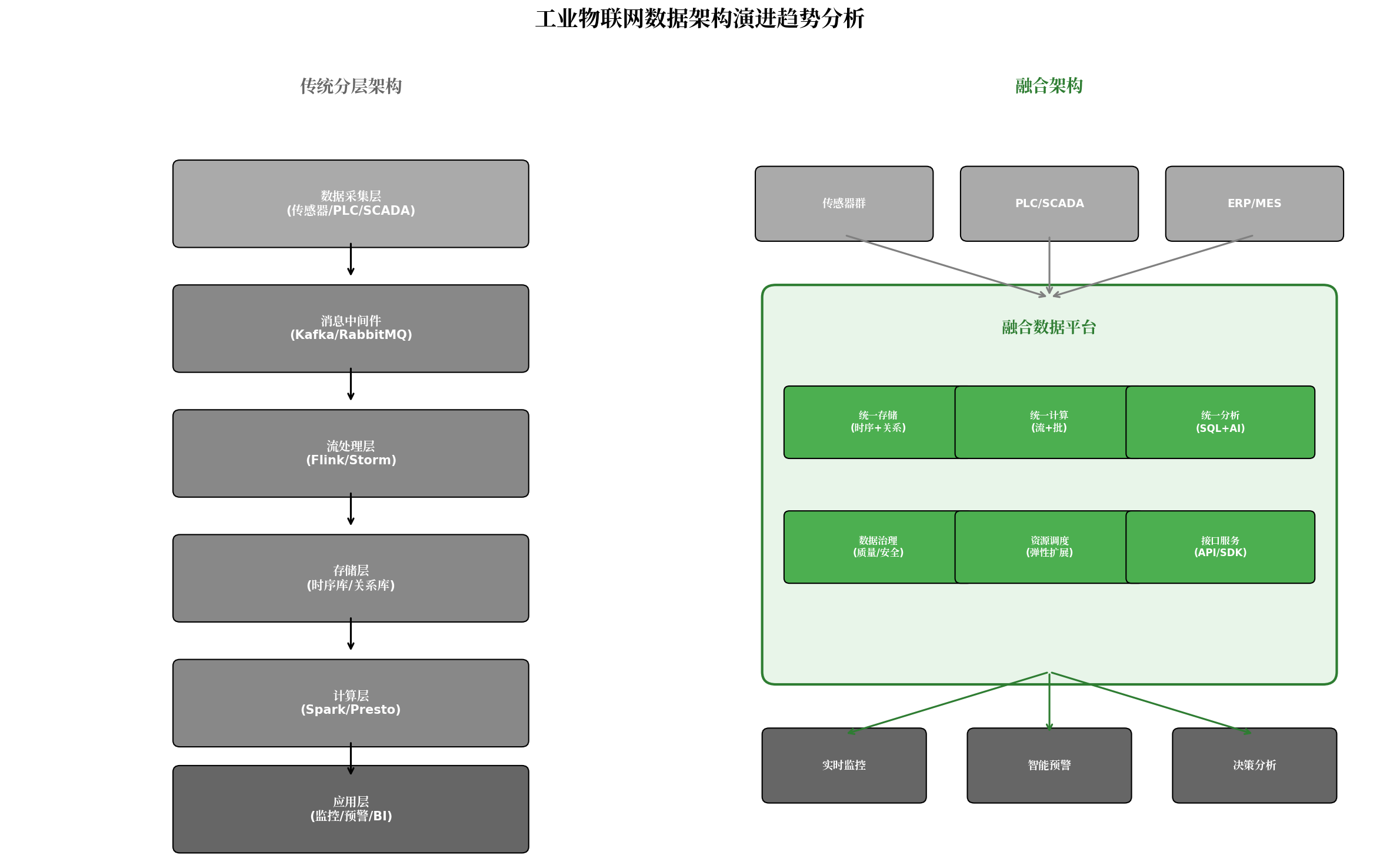
图1 工业数据架构演进趋势
二、一体化架构的技术原理
针对上述问题,学术界和工业界开始探索存储、计算、分析深度融合的新型架构。本章从技术原理层面,分析一体化架构的核心设计思路。
2.1 存算一体:数据本地化计算
传统架构的主要性能损耗来源于数据搬运。存算一体(Compute-Storage Fusion)架构的核心思想是打破存储与计算的物理分离,将计算任务调度至数据所在的存储节点执行,避免跨网络传输。
对比维度 | 传统分层架构 | 融合架构 |
|---|---|---|
数据移动方式 | 跨节点/跨系统搬运 | 存储节点本地计算 |
I/O延迟量级 | 毫秒级至秒级 | 微秒级 |
扩展模式 | 存储与计算独立扩缩容 | 节点级统一扩展 |
运维复杂度 | 多集群独立维护 | 单一系统统一管理 |
在电力物联网场景的压力测试中,融合架构面对百万级测点写入,实现了写入与查询的并发隔离,复杂算法延迟可从秒级压缩至毫秒级。这一结果表明,数据本地化计算是提升工业实时分析性能的有效路径。
2.2 流批一体:统一计算语义
流处理与批处理的分离是传统架构的另一核心痛点。流批一体(Stream-Batch Unification)架构允许使用同一套查询语言处理历史数据分析和实时流监控,消除了语义断层。
其技术价值体现在三个层面:
- 研发与生产一致性:历史数据上验证的算法逻辑可直接应用于实时流,无需改写;
- 计算结果一致性:滑动窗口、会话窗口等时序算子在批处理与流处理中保持相同语义;
- 延迟可控性:流计算引擎的端到端延迟可达亚毫秒级,满足高频监测需求。
某制造企业的实践表明,采用流批一体架构后,设备综合效率(OEE)的统计时效从次日汇总缩短至当班可见,显著提升了生产管理的响应速度。
2.3 多模融合:打破数据类型壁垒
工业数据具有显著的多样性:传感器产生时序数据,ERP/MES系统产生关系型数据,日志系统产生半结构化数据。传统方案将这些数据分散在不同系统中,跨库关联查询效率低下。
多模融合架构在同一平台内支持时序数据与关系型数据的联合查询,消除了跨库Join的性能损耗。例如,设备故障分析可以同时关联该设备的振动时序数据和维保记录,形成完整的分析视图。
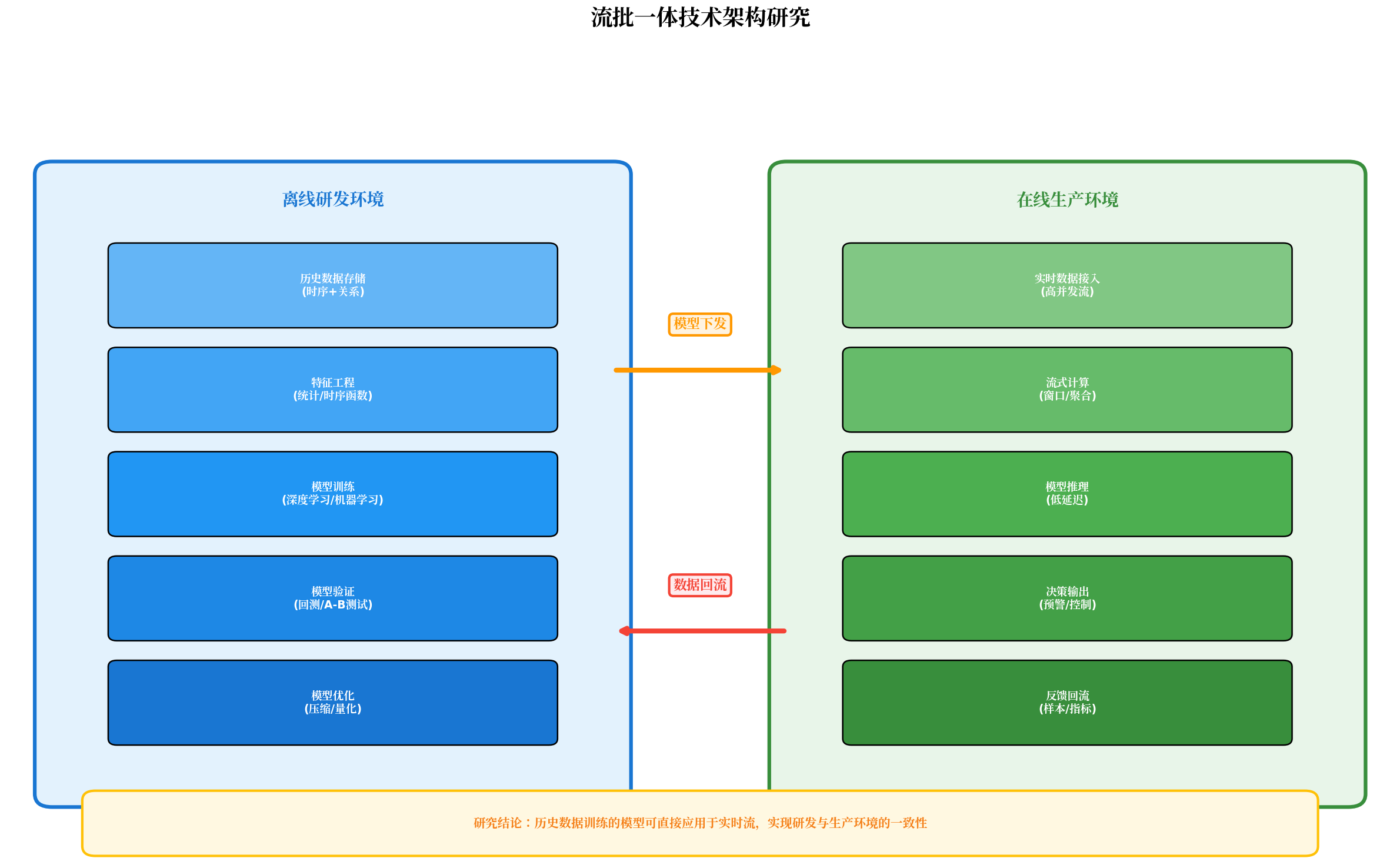
图2 流批一体技术架构
三、工程实践与效果分析
本章基于公开技术文献与行业调研资料,分析融合架构在典型工业场景中的应用效果。
3.1 能源行业:大规模测点监控
某大型能源集团下辖多座水电站和新能源场站,传感器测点规模达百万级,日新增数据量达数百亿行。改造前采用消息队列+流处理+开源时序库的分层架构,端到端预警延迟在分钟级。
采用融合架构后的主要改进包括:
- 写入性能:单集群支撑数百万测点/秒的并发写入;
- 查询响应:复杂多维度聚合查询从数十秒级压缩至毫秒级;
- 预警时效:设备异常检测延迟从分钟级降至秒级以内;
- 运维效率:多套独立系统合并为单一集群,运维复杂度显著降低。
该类场景对数据库的写入吞吐和查询并发能力提出了极高要求。融合架构通过存算一体设计,在大型水电企业的实践中验证了多源数据关联分析的可行性,为能源行业的实时决策提供了技术参考。
3.2 高端制造:实时质量检测
某精密零部件制造商部署了机器视觉质检系统。离线测试阶段模型准确率较高,但上线后由于数据链路延迟,检测节拍与产线速度不匹配,导致实际漏检率上升。
技术改进方案包括:将图像特征向量接入融合平台的流计算引擎;利用内置张量运算在数据流入时完成模型推理;推理结果在毫秒级反馈给控制系统触发分拣动作。
改进后检测节拍与产线速度实现匹配,模型上线后的准确率与实验室环境保持一致。这一案例表明,流批一体架构能够有效缩短算法研发到生产部署的周期。
3.3 钢铁行业:工艺参数优化
某钢铁集团的高炉工艺参数调整长期依赖人工经验,单次优化周期长达数月。基于融合架构构建机理模型与数据模型融合的实时优化系统后,工艺调整周期从数月级压缩至小时级。
该类场景对数据库的内置分析能力要求较高。融合架构通过丰富的内置函数库和时序连接算法,支持高频振动数据与低频工艺数据的关联分析,为工业多频数据融合提供了技术路径。
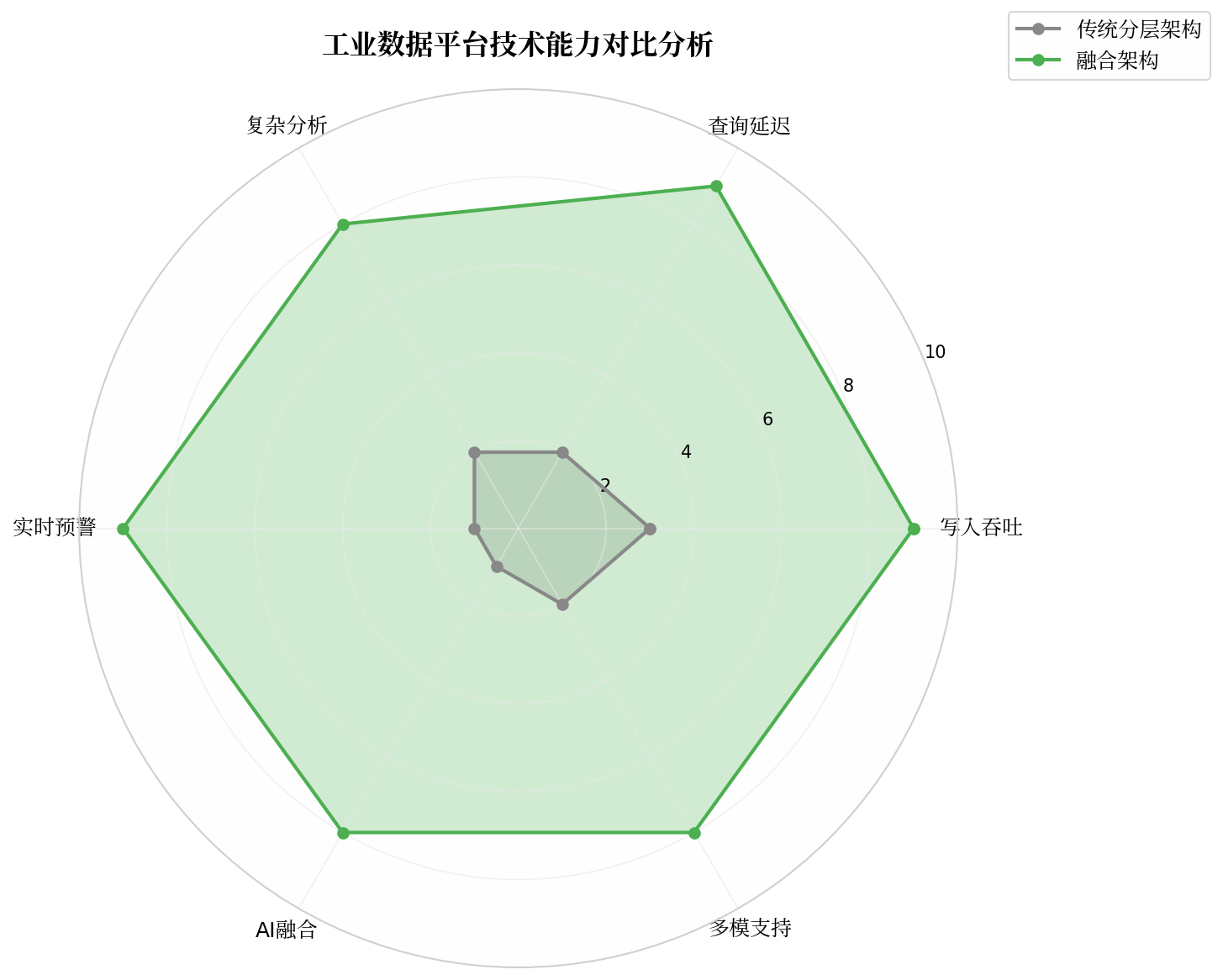
图3 工业数据平台技术能力对比
四、应用场景分析
融合架构已在多个垂直领域形成规模化应用,不同行业对技术能力的侧重点存在差异。
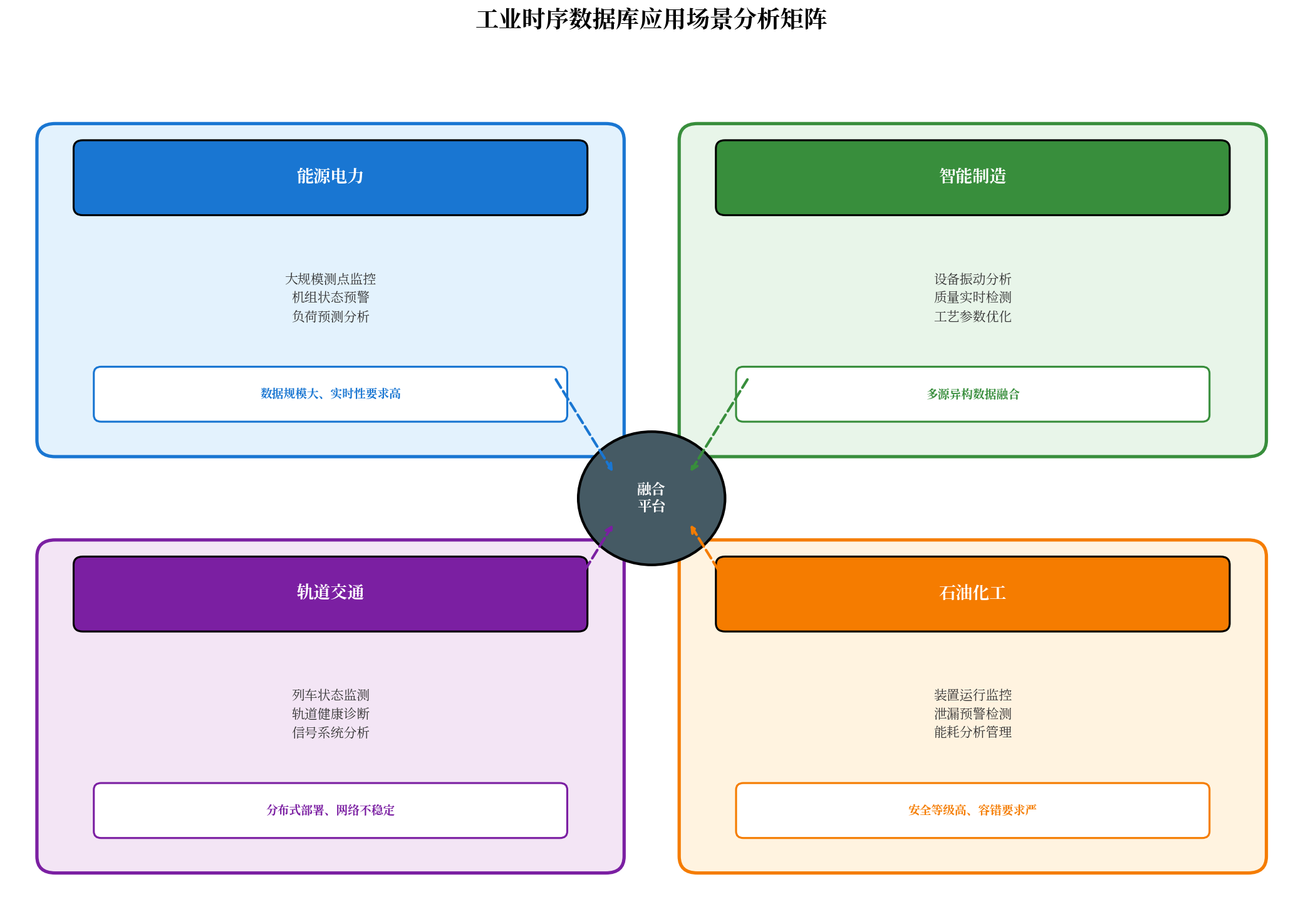
图4 工业时序数据库应用场景分析矩阵
行业领域 | 典型应用场景 | 核心技术挑战 |
|---|---|---|
能源电力 | 大规模测点监控、机组状态预警、负荷预测 | 数据规模大、实时性要求高 |
智能制造 | 设备振动分析、质量实时检测、工艺参数优化 | 多源异构数据融合 |
石油化工 | 装置运行监控、泄漏预警检测、能耗分析 | 安全等级高、容错要求严 |
轨道交通 | 列车状态监测、轨道健康诊断、信号系统分析 | 分布式部署、网络不稳定 |
五、关键技术分析
融合架构的性能优势来源于多项底层技术的协同优化。
5.1 存储引擎优化
采用日志结构合并树(LSM-Tree)的改良结构,写入操作先在内存中排序,再异步批量持久化至磁盘,避免随机写入带来的性能损耗。该设计在高频传感器数据场景中表现出良好的写入稳定性。
5.2 数据压缩技术
针对时序数据的时间连续性和数值渐变特征,采用差分编码等自适应压缩算法,在保证查询性能的前提下降低存储成本。
5.3 向量化执行
用向量化处理替代逐行处理,充分利用现代CPU的SIMD指令集,提升批量数据处理的效率。
5.4 时序连接算法
工业现场不同传感器的采样频率差异显著,时序连接算法能够有效对齐异构频率数据,支持高频振动数据与低频温度数据的关联分析。
5.5 复杂事件处理
将连续阈值超限等复杂告警逻辑抽象为可配置规则,支持在线更新,无需中断服务即可调整告警策略。
六、技术选型建议
基于行业实践,建议采用渐进式建设路径:
第一阶段:单点验证
选择关键产线或核心设备作为试点,部署融合架构节点,验证实时采集与基础分析能力。
第二阶段:产线扩展
将验证经验扩展至整条产线,统一数据模型,部署流计算能力,建立模型迭代机制。
第三阶段:工厂级平台
构建覆盖全厂的统一平台,引入多模数据融合能力,完善安全与治理体系。
第四阶段:生态协同
将平台能力扩展至供应链与产业链,建立跨域数据协同机制。
设计原则方面,建议遵循"存算一体、流批融合、分层智能"的理念:实时性要求高的任务在边缘侧完成;需要全局视角的任务在云端执行;高频原始数据本地存储,聚合数据云端归档;建立离线训练到在线推理的闭环迭代机制。
七、结论与展望
本文通过分析工业物联网数据处理的现实困境,探讨了融合架构的技术原理与工程实践。研究表明,存算一体设计能够有效降低数据搬运开销,流批一体架构能够统一离线研发与在线生产的计算语义,多模融合能力能够打破工业数据类型壁垒。
在能源、制造、钢铁等行业的实践中,融合架构在写入吞吐、查询延迟、分析效率等维度较传统方案展现出明显优势。对于工业物联网领域的技术选型者而言,核心问题已不再是是否需要实时分析能力,而是如何选择能够同时满足实时性与分析深度的技术架构。
展望未来,随着工业传感器密度的持续提升和AI应用需求的不断增长,融合架构有望成为工业数据基础设施的主流演进方向。后续研究可进一步关注边缘计算与中心协同、联邦学习在跨企业场景中的应用、以及时序数据与知识图谱的深度融合等方向。
参考文献
[1] 中国信息通信研究院. 工业互联网白皮书(2023年)[R]. 北京: 中国信息通信研究院, 2023.
[2] 工业互联网产业联盟. 工业大数据白皮书[R]. 北京: 工业互联网产业联盟, 2022.
[3] 刘韵洁, 张晨. 工业互联网体系架构研究[J]. 通信学报, 2021, 42(5): 1-15.
[4] Stonebraker M, Cetintemel U. "One Size Fits All": An Idea Whose Time Has Come and Gone[C]. ICDE, 2005.
[5] 周傲英, 钱卫宁. 数据库发展趋势与挑战[J]. 计算机学报, 2022, 45(1): 1-25.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号