Skill-adapter:让SKILL快速部署到你的ai应用
原创
Skill-adapter:让SKILL快速部署到你的ai应用
原创
九年义务漏网鲨鱼
发布于 2026-03-23 13:42:05
发布于 2026-03-23 13:42:05
SKILL
随着 AI Coding 和智能体开发越来越普及,越来越多开发者开始把大模型接入真实应用中。但在这个过程中,一个很常见的问题也逐渐暴露出来:同类 prompt 在不同场景中反复编写、重复维护,导致能力难以复用,系统也越来越臃肿,以 open_deep_research( https://github.com/langchain-ai/open_deep_research) 为例,系统会通过不同 prompt 设计来定义研究、压缩、报告生成等不同角色与阶段能力
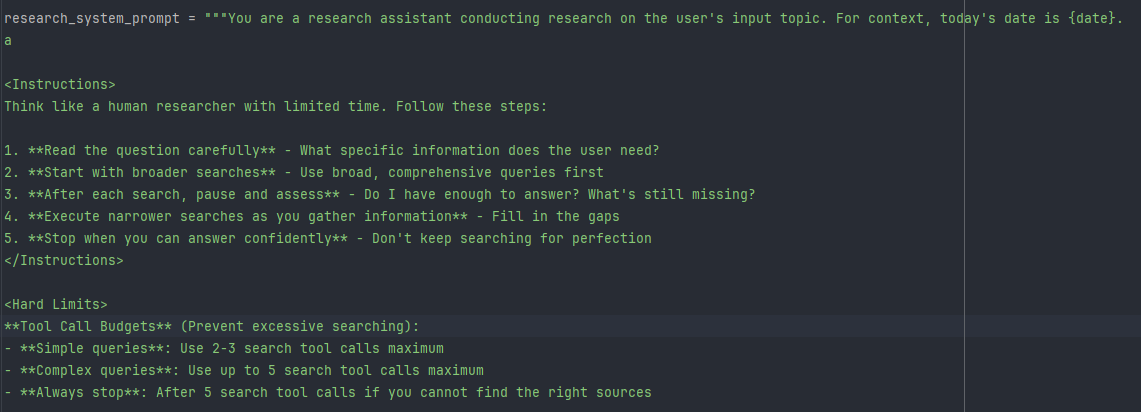
为了解决这种 prompt 冗余和能力分散的问题,Anthropic 在 2025 年 10 月公开发了 Introducing Agent Skills,把 skill 明确描述成一类可复用能力单元,并围绕 SKILL.md、目录结构、动态加载来推广这套机制,把原本散落在代码和 prompt 里的能力,整理成一个可描述、可检索、可复用、可注入的能力单元,从而让智能体系统从“堆 prompt”走向“按需调用能力”。但当你了解更多细节之后,skill其实就是prompt工程的新发展。
例如当前很火的pua, 该项目已经达到了10k ⭐
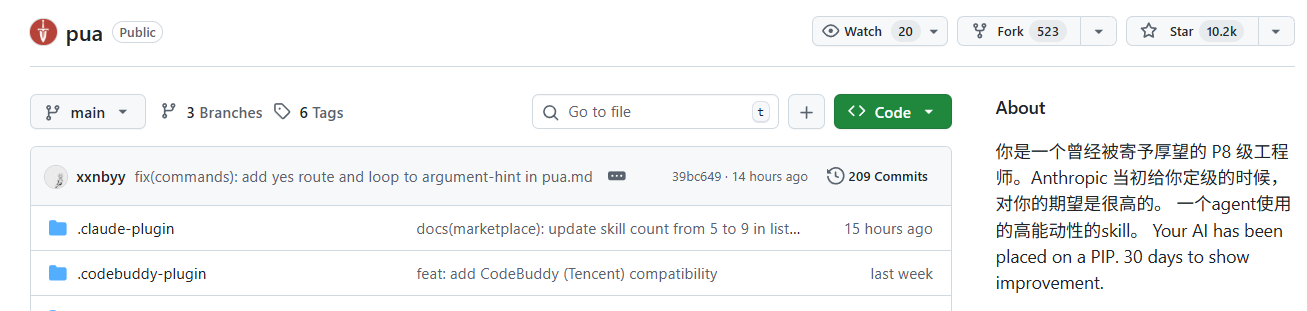
事实上他的实现就是一个好的prompting工程 (有兴趣的同学也可以去做一些开源的skill去丰富自己的简历)

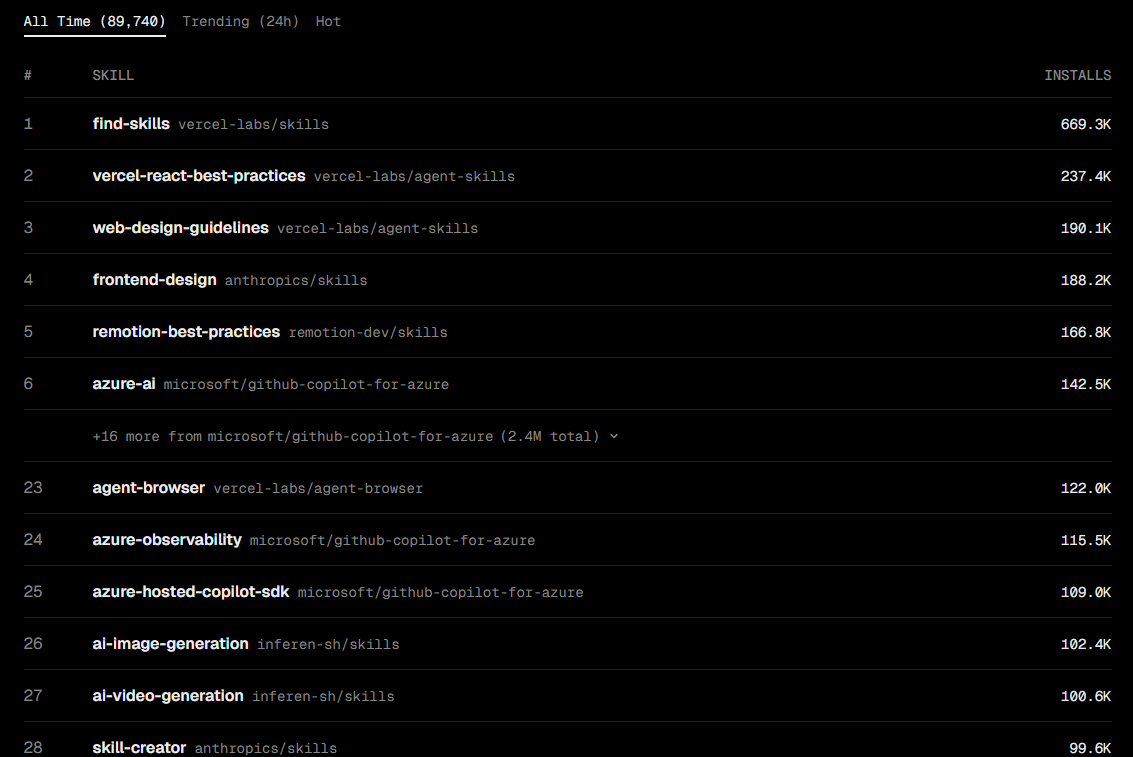
可复用的skill也迅速加快了人们对他的使用.除此之外,们还可以在不同的社区上找到不同SKILL
- Skills.sh https://skills.sh
- SkillsMP https://skillsmp.com/zh
- Skillhub https://skillhub-1388575217.cos.ap-guangzhou.myqcloud.com/install/skillhub.md
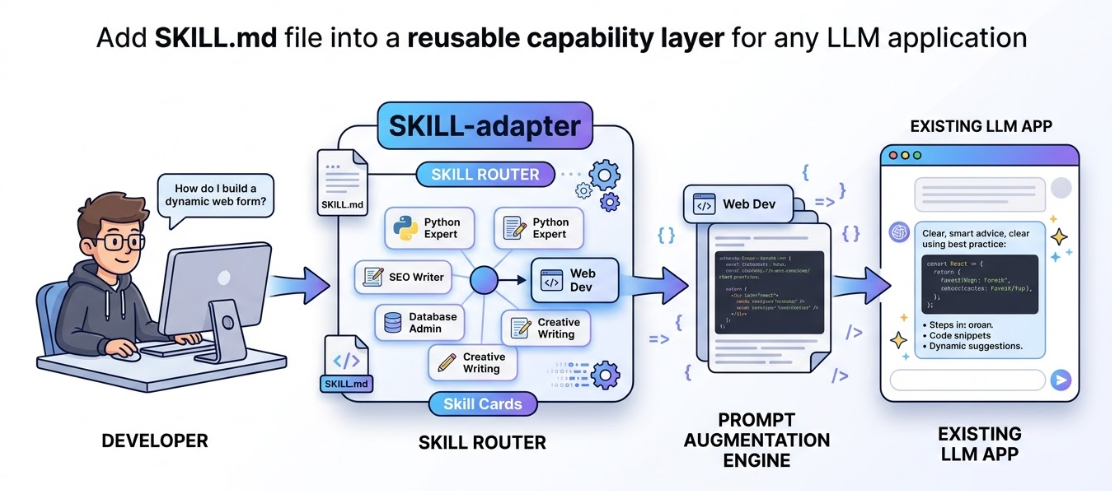
SKILL-adapter
这些 skill 很容易装进 Claude Code / Codex / OpenClaw 之类的 coding agent,但对很多自建 LLM 应用、业务 Agent、对话系统来说,并没有一个低侵入接入层。
为了解决这个问题,我开源了SKILL-adapter的轻量级适配层:不要求重写整套 Agent 框架,也不要求迁移现有后端,只需要在原有模型调用前多接一层 adapter layer,就能获得 Skill Routing、Prompt Augmentation 和平滑 fallback. 例如在一个对话场景中,如果我们希望有pua的skill注入,我们还需要去手动修改prompt,一旦有一个新的skill,就得重复、反复的修改,这不仅是一个繁杂的工作,而且对于无需使用的skill还会导致上下文爆炸。
仓库链接:https://github.com/Yirzzzz/SKILL-adapter,希望各位大佬帮忙小弟点点star
response = client.chat.completions.create(
model='Qwen/Qwen3-8B', # ModelScope Model-Id, required
messages=[
{
'role': 'user',
'content': '<pua.skill> + query'
}
],
stream=True,
extra_body=extra_body
)当我们有了SKILL-adapter之后呢,它通过用户 Query → Skill Routing → Skill 选择 → Prompt Augmentation → 现有 LLM 应用的流程,以低侵入的方式直接接入ai应用中
from skill_adapter import SkillRuntime
runtime = SkillRuntime(skill_dirs=["./skills"]) # 定义skills路径
prepared = runtime.prepare(
query="query",
payload={"messages": [{"role": "user", "content": "query"}]},
mode="messages",
debug=True,
)
response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
**prepared.payload,
stream=True,
extra_body=extra_body
)
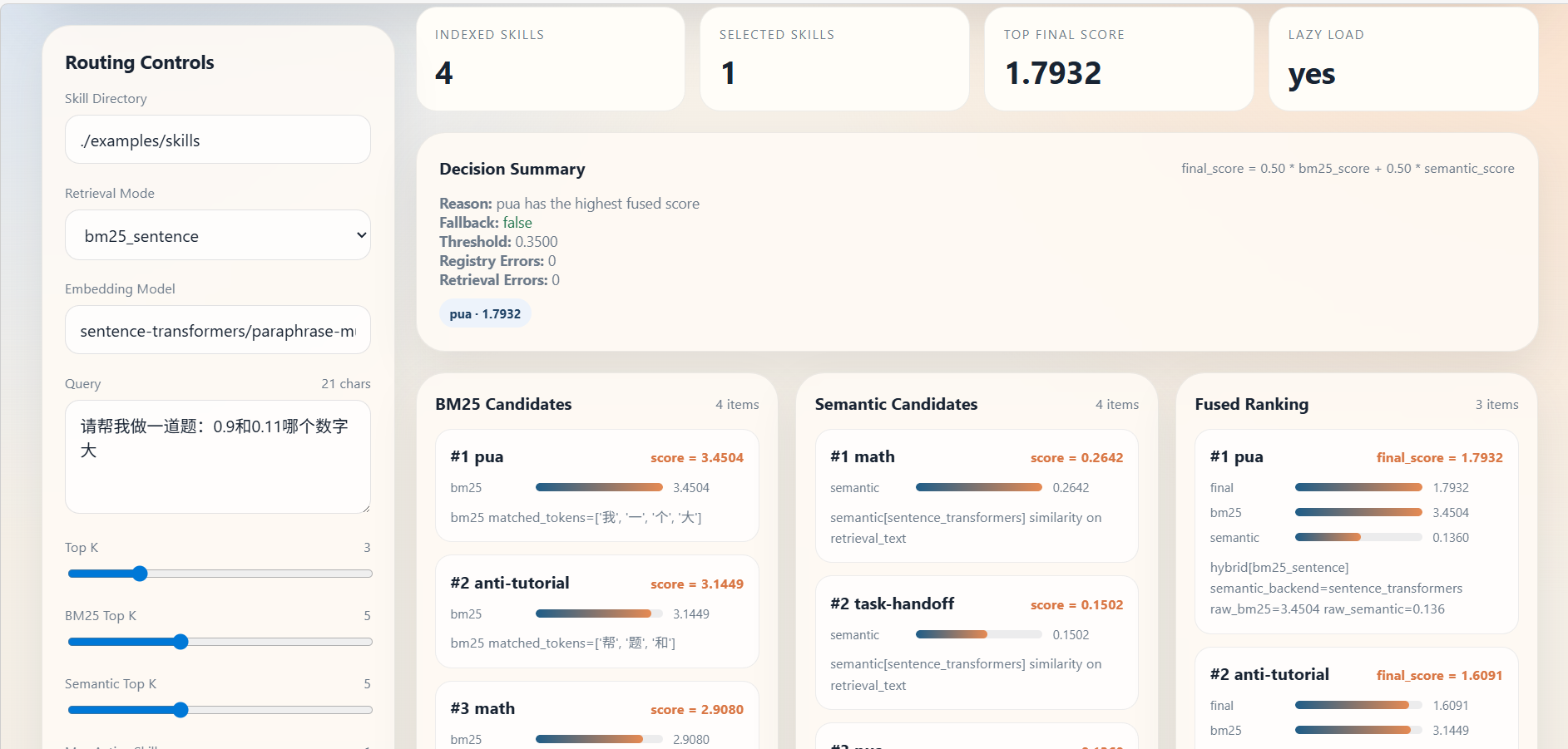
在该项目中,skill的检索召回能力至关重要,目前项目支持四种模式的召回:
bm25_sentence(default): BM25 + sentence-transformers hybrid. Fully implemented. Legacy baseline.bm25_bge_m3: BM25 + BGE-M3 dense hybrid. Fully implemented. Recommended baseline for phase-2 benchmark.bge_m3_rerank: BGE-M3 first-stage + reranker pipeline. Implemented (with dependency fallback).bm25_bge_m3_rerank: BM25 + BGE-M3 first-stage + reranker pipeline. Implemented (with dependency fallback).
用户可以根据自己实际的项目需求,配置召回的skill个数以及权重:
from skill_adapter import SkillConfig
config = SkillConfig(
skill_dirs=["./skills"], # skill 目录
top_k=5,
bm25_top_k=8,
semantic_top_k=8,
max_active_skills=1, #激活skill个数
activation_threshold=0.6,
bm25_weight=0.7,
semantic_weight=0.3,
embedding_model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
enable_semantic_retrieval=True,
enable_bm25_retrieval=True,
debug=True,
)除此之外,为了方便对比不同的召回模式,还提供了web服务供用户观察不同query对于skill召回结果
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号