大模型应用:RAG与向量数据库结合Ollama调用模型深度融合全解析.27
原创
大模型应用:RAG与向量数据库结合Ollama调用模型深度融合全解析.27
原创
未闻花名
发布于 2026-02-24 08:24:37
发布于 2026-02-24 08:24:37
一、引言
通过多篇博文我们也反复介绍说明了大模型知识滞后、生成幻觉成为制约智能问答、企业知识库等场景落地的核心痛点,检索增强生成(RAG)技术通过“外部知识检索 + LLM 生成” 的模式,为解决这些问题提供了关键思路,而向量数据库则是 RAG 发挥价值的核心底座。今天我们从一个新的视角,以本地员工手册智能问答系统为内容载体,从基础概念到实践,系统拆解 RAG 与向量数据库的深度融合逻辑,同时引入 Ollama 这一轻量级本地大模型运行工具,增加实用性和便捷性。
Ollama 作为开源的本地大模型运行框架,能够一键部署、自定义配置通义千问、Llama3 等主流模型,无需依赖云端算力,既保障了数据隐私,又降低了技术落地成本。今天我们从文档智能分块、向量入库、RAG 问答链搭建到调试优化,通过 FAISS 构建轻量级向量库,解决非结构化文本的语义检索问题;借助 Ollama 实现本地 LLM 的灵活调用,结合调试输出直观呈现检索、生成全流程的关键细节。

二、基础概念回顾
1. RAG(检索增强生成)
RAG 全称为 Retrieval-Augmented Generation,是一种将外部知识库检索与大模型生成相结合的技术框架。简单来说,它就像带参考书考试的学生,生成答案前先从外部知识源中查找相关信息,再结合自身能力组织语言输出。
- 核心解决的问题:大模型存在知识滞后,受限于训练数据截止时间、易产生幻觉编造虚假信息、领域知识不足、微调成本高等痛点,RAG 通过实时调用外部知识,无需重新训练模型即可弥补这些缺陷。
- 核心流程:可概括为“检索 - 增强 - 生成”三步。先检索外部相关知识,再将知识作为上下文补充给大模型,最后由大模型生成准确回答。
2. 向量数据库
向量数据库是专门用于存储、管理和高效检索高维向量数据的数据库系统。计算机无法直接理解文本、图像等非结构化数据,而向量数据库能通过嵌入模型将这些数据转化为类似 “数字指纹” 的高维向量,再通过相似度算法实现快速检索。
- 核心优势:区别于传统数据库的关键词匹配,向量数据库支持语义级搜索。例如 “苹果手机” 和 “iPhone” 虽关键词不同,但语义相近,其向量距离会很小,可被精准匹配到。
- 核心技术:依赖嵌入模型(如 BGE、Sentence-BERT)完成数据向量化,依靠余弦相似度等算法计算向量相似度,通过 HNSW、IVF 等索引算法实现亿级向量的毫秒级检索。
3. Ollama介绍
Ollama 是一款开源、轻量级的本地大模型运行与管理工具,核心定位是让普通开发者和中小企业能够以极低的成本、零门槛在本地环境部署和使用主流大模型。它并非自研大模型,而是搭建了一套简洁的模型运行框架,将模型下载、环境配置、参数调优、服务启动等复杂流程封装为简单的命令行操作,大幅降低了大模型本地化落地的技术门槛。
Ollama 的价值体现:
- 1. 部署极简,无需手动配置 CUDA、依赖库等复杂环境,通过一行命令即可拉取并启动通义千问、Llama3、Phi-3 等数十种主流大模型,即使是非技术人员也能快速上手;
- 2. 灵活性高,支持自定义模型参数,比如调整温度值控制生成随机性、扩展上下文窗口提升长文本处理能力,还能通过编写 Modelfile 文件组合、微调模型,适配不同业务场景需求;
- 3. 隐私性强,所有模型推理过程均在本地完成,无需将数据上传至云端,完美适配企业内部知识库、敏感业务问答等对数据安全要求高的场景;
- 4. 轻量化运行,针对轻量级模型做了深度优化,即使在普通个人电脑或低配服务器上也能流畅运行,大幅降低了硬件成本,避免了依赖云端 API 的长期费用支出。
在实际应用中,Ollama 常与 RAG、向量数据库组合使用:
- 作为 RAG 系统的生成端,它能接收向量数据库检索到的精准上下文,快速生成贴合业务的回答,既发挥了 RAG “检索增强” 的精准性,又借助本地部署的优势保障了响应速度和数据安全。
- 无论是验证大模型应用逻辑,还是搭建私有化智能问答系统,Ollama 都能以“低成本、易操作、高安全”的特性,成为连接大模型与实际业务的高效桥梁。
4. 融合的核心意义
向量数据库是 RAG 系统的 “记忆中枢”:
- RAG 的检索环节若依赖传统数据库,会因语义理解能力不足导致检索精度低;
- 而向量数据库提供的高效语义检索能力,能让 RAG 快速从海量外部知识中定位核心信息。
二者融合后,既发挥了 RAG“灵活调用外部知识”的优势,又借助向量数据库解决了 RAG 检索效率和精度的核心问题,成为搭建实用智能问答、知识库系统的黄金组合。
三、融合的核心逻辑
RAG 与向量数据库的融合贯穿于整个 RAG 系统的离线建库和在线问答全流程,每个环节的优化都直接影响系统性能,具体可分为两大阶段。
1. 离线建库阶段
构建可检索的知识底座,该阶段的核心是将非结构化知识转化为向量数据库可存储、可检索的格式,为后续检索做准备,步骤如下:

- 1. 数据收集与预处理:整合 PDF、Word、网页文本等多源知识,剔除重复、无效内容(如格式错乱的字符、无意义的页眉页脚)。
- 2. 文本智能分块:长文本直接向量化易丢失语义,需拆分为语义完整的小块。例如按 “章节”“条款” 等锚点拆分法律文档,按段落拆分技术手册,同时设置 5%-20% 的文本重叠率,避免语义断裂。
- 3. 文本向量化:使用嵌入模型(如我们一直使用的本地开源的 all-MiniLM-L6-v2)将每个文本块转化为高维向量。同一系统需固定嵌入模型,确保查询向量与存储向量的格式一致。
- 4. 向量入库与索引构建:将向量及对应的原始文本、元数据(如文档类型、更新时间)存入向量数据库,并构建索引。例如用 HNSW 索引适配高并发检索场景,用 IVF 索引适配亿级数据场景。
2. 在线问答阶段
实时检索与智能生成,用户发起查询时,二者通过协同完成从查询到回答的全链路流程,步骤如下:

- 1. 查询向量化:用户输入自然语言查询(如 “公司年假政策是什么”),通过与离线建库阶段相同的嵌入模型,将查询转化为向量。
- 2. 相似向量检索:向量数据库接收查询向量后,通过相似度算法检索出 Top-K 个最相关的向量,对应到原始文本块。
- 3. 上下文增强:RAG 将检索到的文本块作为上下文,与用户原始查询整合为增强提示词。
- 4. 生成最终回答:将增强提示词输入 LLM,由 LLM 结合上下文生成兼顾准确性和可读性的回答,同时可标注信息来源,提升可信度。
3. 融合的关键点
- 混合检索策略:向量检索搭配关键词检索,例如检索 “某型号手机售后政策” 时,向量检索匹配语义,关键词检索锁定 “型号”“售后” 等核心词,降低检索噪声。
- 元数据过滤增强:为向量添加业务标签(如产品型号、更新时间),检索时可通过元数据快速筛选范围。例如筛选 “2025 年更新的家电售后文档”,大幅提升检索效率。
- 检索结果重排:用 CrossEncoder 等模型对向量数据库返回的 Top-K 结果二次排序,修正仅靠向量相似度导致的偏差,例如区分 “苹果手机售后” 和 “苹果水果供应链售后” 的差异。
四、Ollama部署与应用
1. 部署及应用
访问 Ollama 官方网站,根据自身系统选择对应安装包,下载 OllamaSetup.exe 安装文件; 双击安装包,按提示完成下一步安装(默认路径即可,无需额外配置),完成基础安装; 打开终端/命令提示符,执行 :
- ollama -v:输出版本号,即表示安装成功
- ollama ps:查看Ollama中正正运行的模型
- ollama run deepseek-r1:1.5b:运行指定模型
- ollama pull deepseek-r1:1.5b:当模型不存在时,运行指定命令下载模型,如下载deepseek-r1:1.5b 模型
本示例使用的比较小的模型deepseek-r1:1.5b部署,第一次通过ollama pull deepseek-r1:1.5b命令进行下载,下载完后通过ollama run deepseek-r1:1.5b运行即可;

Ollama的部署应用明细可参考《构建AI智能体:DeepSeek的Ollama部署FastAPI封装调用》
2. 扩展说明
2.1 多模型切换
# 支持动态切换模型(如qwen2:1.5b、llama3:8b)
def switch_llm(model_name):
return Ollama(model=model_name, temperature=0.1)
llm_1.5b = switch_llm("qwen2:1.5b")2.2 流式输出
# 流式回答(逐字输出)
from langchain_core.callbacks import StreamingStdOutCallbackHandler
llm_stream = Ollama(model="deepseek-r1:1.5b", callbacks=[StreamingStdOutCallbackHandler()])
llm_stream.invoke("请详细说明年假政策")五、示例:本地文档智能问答系统
1. 文档示例内容
员工年假政策:正式员工入职满1年不满3年,每年享有5天带薪年假;入职满3年不满10年,每年享有10天带薪年假;入职满10年及以上,每年享有15天带薪年假。 请假流程:员工请假需提前3天通过企业OA提交申请,经直属领导审批通过后方可生效。紧急情况无法提前申请的,需24小时内补提申请。 加班调休规则:工作日加班可按1:1比例申请调休,调休需在加班后3个月内使用完毕,逾期作废。 # 新增冗余内容(用于调试检索过滤效果) 办公用品申领:每月5号可提交申领表,限领笔、笔记本等基础用品。 团建活动规则:每季度部门可申请1次团建经费,上限5000元。
2. 完整示例过程
2.1 加载文档并智能分块
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from rich import print # 美化调试输出
# 加载本地文档
loader = TextLoader("knowledge.txt", encoding="utf-8")
documents = loader.load()
print(f"【调试】原始文档加载结果:\n{documents}\n")
# 文本分块:100字符/块,50字符重叠率
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ",", "、"] # 新增中文分隔符优化
)
chunks = text_splitter.split_documents(documents)
# 调试输出:分块数量+每个块内容
print(f"【调试】文本分块总数:{len(chunks)}")
for i, chunk in enumerate(chunks):
print(f"【调试】第{i+1}个分块内容:\n{chunk.page_content}\n---")输出结果:
【调试】原始文档加载结果: [Document(metadata={'source': 'knowledge.txt'}, page_content='员工年假政策:正式员工入职满1年不满3年,每年享有5天带薪年假;入职满3年不满10年,每年享有10天带薪年假;入职满10年及以 上,每年享有15天带薪年假。\n请假流程:员工请假需提前3天通过企业OA提交申请,经直属领导审批通过后方可生效。紧急情况无法提前申请的, 需24小时内补提申请。\n加班调休规则:工作日加班可按1:1比例申请调休,调休需在加班后3个月内使用完毕,逾期作废。\n# 新增冗余内容(用于调试检索过滤效果)\n办公用品申领:每月5号可提交申领表,限领笔、笔记本等基础用品。\n团建活动规则:每季度部门可申 请1次团建经费,上限5000元。')] 【调试】文本分块总数:4 【调试】第1个分块内容: 员工年假政策:正式员工入职满1年不满3年,每年享有5天带薪年假;入职满3年不满10年,每年享有10天带薪年假;入职满10年及以上,每年享有15天带薪年假。 --- 【调试】第2个分块内容: 请假流程:员工请假需提前3天通过企业OA提交申请,经直属领导审批通过后方可生效。紧急情况无法提前申请的,需24小时内补提申请。 --- 【调试】第3个分块内容: 加班调休规则:工作日加班可按1:1比例申请调休,调休需在加班后3个月内使用完毕,逾期作废。 # 新增冗余内容(用于调试检索过滤效果) 办公用品申领:每月5号可提交申领表,限领笔、笔记本等基础用品。 --- 【调试】第4个分块内容: 办公用品申领:每月5号可提交申领表,限领笔、笔记本等基础用品。 团建活动规则:每季度部门可申请1次团建经费,上限5000元。 ---
2.2 构建向量数据库并入库
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
import numpy as np
# 初始化嵌入模型(新增模型参数优化)
embeddings = HuggingFaceEmbeddings(
model_name="D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'device': 'cpu'}, # 指定CPU运行(无GPU时)
encode_kwargs={'normalize_embeddings': True} # 归一化向量,提升相似度计算精度
)
# 为分块添加元数据(扩展:便于后续过滤)
for i, chunk in enumerate(chunks):
chunk.metadata.update({
"chunk_id": i+1,
"content_type": "employee_rule",
"update_time": "2025-12-17"
})
# 文本块向量化并构建FAISS向量库
vectorstore = FAISS.from_documents(chunks, embeddings)
# 调试:查看向量维度+相似度计算示例
sample_chunk = chunks[0]
sample_vector = embeddings.embed_query(sample_chunk.page_content)
print(f"【调试】单个文本块向量维度:{len(sample_vector)}")
print(f"【调试】向量前10位数值:{np.round(sample_vector[:10], 4)}\n")
# 调试:测试相似性检索
query = "入职5年年假有多少天"
retrieved_docs = vectorstore.similarity_search(query, k=2)
print(f"【调试】测试检索结果(查询:{query}):")
retrieved_docs_with_scores = vectorstore.similarity_search_with_score(query, k=2)
for doc, score in retrieved_docs_with_scores:
print(f"- 匹配分块:{doc.page_content}(相似度:{score:.4f})")
# 保存向量库到本地
vectorstore.save_local("local_faiss_index")
print("\n【调试】向量库已保存到 local_faiss_index 目录") 输出结果:
【调试】单个文本块向量维度:384 【调试】向量前10位数值:[ 0.0227 0.0214 0.0536 0.0264 -0.0132 0.0831 -0.0024 -0.0287 -0.0151 0.0242] 【调试】测试检索结果(查询:入职5年年假有多少天): - 匹配分块:员工年假政策:正式员工入职满1年不满3年,每年享有5天带薪年假;入职满3年不满10年,每年享有10天带薪年假;入职满10年及以上, 每年享有15天带薪年假。(相似度:0.5489) - 匹配分块:请假流程:员工请假需提前3天通过企业OA提交申请,经直属领导审批通过后方可生效。紧急情况无法提前申请的,需24小时内补提申请 。(相似度:0.6494) 【调试】向量库已保存到 local_faiss_index 目录
2.3 搭建 RAG 问答链
from langchain_community.llms import Ollama
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.runnables import RunnableConfig
# 初始化Ollama LLM(扩展:自定义参数)
llm = Ollama(
model="deepseek-r1:1.5b", # 使用自定义模型(或qwen2:0.5b)
temperature=0.1, # 低温度=低随机性
num_ctx=4096, # 扩展上下文窗口
timeout=30 # 超时时间(避免模型响应过慢)
)
# 调试:测试LLM基础调用
test_prompt = "你是谁?请用一句话回答"
llm_response = llm.invoke(test_prompt)
print(f"【调试】LLM基础调用测试:\n提问:{test_prompt}\n回答:{llm_response}\n")
# 定义提示模板(增强:明确来源标注)
prompt = ChatPromptTemplate.from_template(
"请严格根据以下上下文内容回答用户问题,禁止编造任何信息。\n"
"上下文来源:员工手册(2025版)\n"
"上下文内容:{context}\n\n"
"用户问题:{input}\n"
"回答要求:1. 仅使用上下文信息;2. 简洁明了;3. 标注信息对应的规则类型。"
)
# 创建文档整合链
document_chain = create_stuff_documents_chain(llm, prompt)
# 加载本地向量库并转为检索器(扩展:添加元数据过滤)
retriever = FAISS.load_local(
"local_faiss_index",
embeddings,
allow_dangerous_deserialization=True
).as_retriever(
search_kwargs={
"k": 2, # 检索Top2
"filter": {"content_type": "employee_rule"} # 仅检索员工规则类内容
}
)
# 构建完整RAG问答链
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 调试:查看检索链结构
print(f"【调试】RAG链结构:\n{retrieval_chain.get_graph().draw_ascii()}\n")输出结果:
【调试】LLM基础调用测试: 提问:你是谁?请用一句话回答 回答:<think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。 </think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。 【调试】RAG链结构: +------------------------+ | Parallel<context>Input | +------------------------+ *** *** ** ** ** ** +--------+ ** | Lambda | * +--------+ * * * * * * * +----------------------+ +-------------+ | VectorStoreRetriever | | Passthrough | +----------------------+ +-------------+ ***************************省略*********************
完整的RAG链结构:
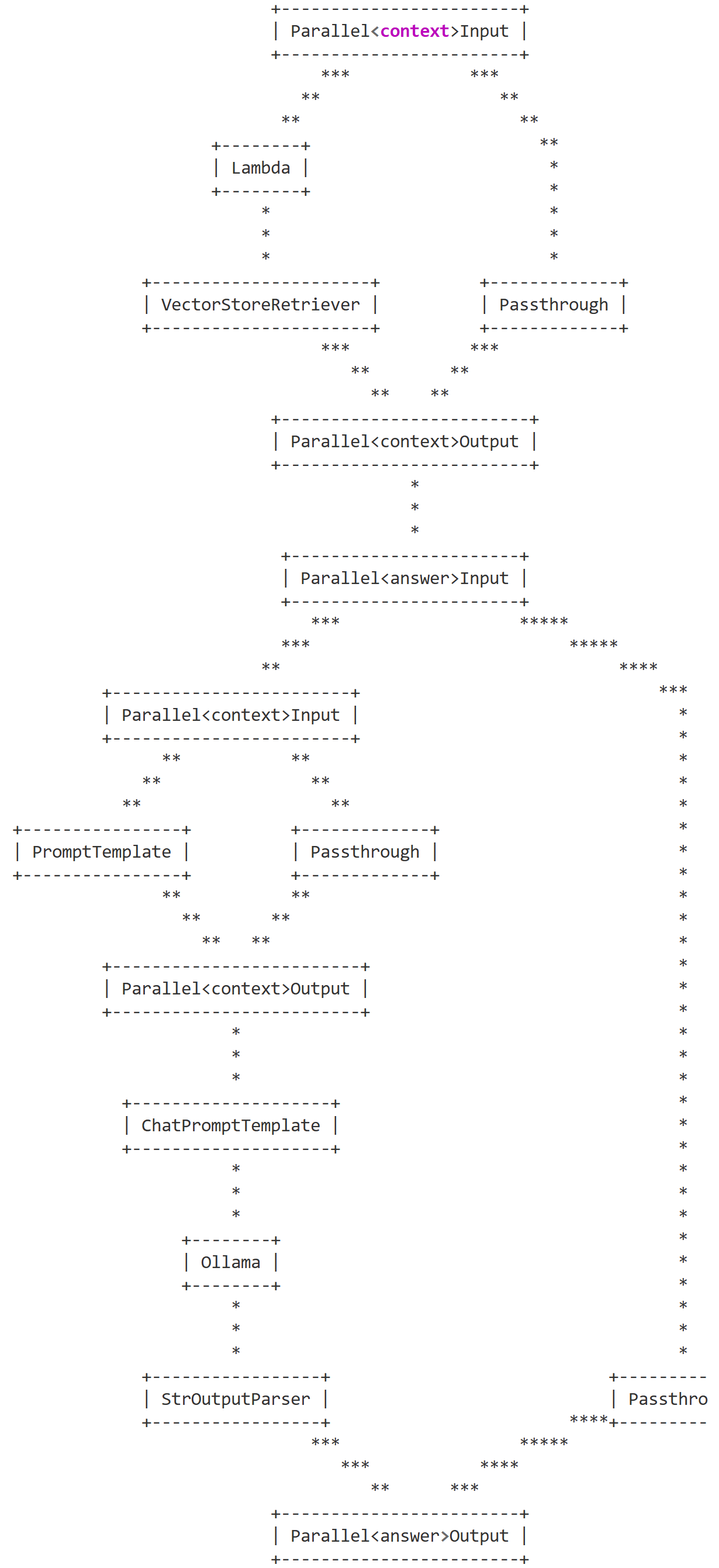
RAG 链结构总结:
该 RAG 链是一套并行化设计的检索增强生成架构,核心特点是通过多分支并行处理、分层式数据流转,兼顾检索精准性与成效率,整体可拆解为三大核心阶段,各环节分工明确且协同高效:
1. 并行检索阶段(上游)
以Parallel<context>Input为统一输入入口,拆分为两条并行分支:
- 核心检索分支:通过Lambda(匿名函数)处理用户查询(如清洗、标准化)后,传入VectorStoreRetriever(向量库检索器),完成核心语义检索,获取与问题匹配的知识库上下文;
- 透传分支:通过Passthrough(透传组件)直接保留原始查询,不做修改。 两条分支结果汇总至Parallel<context>Output,既保证检索到精准上下文,又保留原始查询的完整性,为后续生成提供双维度输入。
2. 提示构建阶段(中游)
检索结果与原始查询进入Parallel<answer>Input后,再次拆分并行分支处理:
- 上下文加工分支:检索到的上下文经PromptTemplate格式化(如添加 “基于以下上下文回答” 等指令);
- 查询透传分支:原始查询继续通过Passthrough保留。 两者汇总至Parallel<context>Output后,统一传入ChatPromptTemplate(对话提示模板),拼接成 “指令 + 上下文 + 原始查询” 的完整提示词,确保 Ollama 生成时既有明确规则约束,又有精准上下文支撑。
3. 生成输出阶段(下游)
完整提示词传入Ollama(本地大模型)完成回答生成,生成结果经StrOutputParser(字符串输出解析器)格式化后,与透传的原始查询再次汇总至Parallel<answer>Output,最终输出 “原始问题 + 精准回答” 的完整结果。
简单总结:
- 并行化设计:检索、提示构建环节均采用 “核心处理 + 透传” 并行分支,既保证关键步骤的加工效果,又保留原始数据,避免信息丢失;
- 分层清晰:检索、提示、生成三阶段边界明确,检索聚焦 “找对信息”,提示聚焦 “规范输入”,生成聚焦 “精准回答”,便于调试和优化;
- 轻量化落地:基于 Ollama 本地运行模型,结合向量检索,既保障数据隐私(全流程本地处理),又通过组件化设计降低架构复杂度,适合私有化部署场景。
2.4 实现交互问答
print("="*50)
print("本地智能问答助手已启动(输入'quit'退出,输入'debug'查看检索详情)")
print("="*50)
while True:
user_question = input("\n请提问:")
if user_question.lower() == "quit":
print("助手已关闭!")
break
if user_question.lower() == "debug":
print("\n【调试模式】当前检索器配置:")
print(f"- 检索数量k:{retriever.search_kwargs['k']}")
print(f"- 元数据过滤条件:{retriever.search_kwargs.get('filter', '无')}")
print(f"- 向量库文档总数:{len(vectorstore.index_to_docstore_id)}")
continue
# 调用问答链并记录耗时
import time
start_time = time.time()
result = retrieval_chain.invoke({"input": user_question})
end_time = time.time()
# 详细调试输出
print("\n" + "-"*30 + "调试信息" + "-"*30)
print(f"【调试】检索到的上下文:")
for i, doc in enumerate(result["context"]):
print(f" {i+1}. {doc.page_content}(元数据:{doc.metadata})")
print(f"【调试】回答生成耗时:{end_time - start_time:.2f}秒")
print("-"*66)
# 最终回答输出
print(f"\n回答:{result['answer']}")输出结果:
================================================== 本地智能问答助手已启动(输入'quit'退出,输入'debug'查看检索详情) ================================================== 请提问:入职5年的正式员工有多少天年假? ------------------------------调试信息------------------------------ 【调试】检索到的上下文: 1.员工年假政策:正式员工入职满1年不满3年,每年享有5天带薪年假;入职满3年不满10年,每年享有10天带薪年假;入职满10年及以上,每年享有15天带 薪年假。 (元数据:{'source': 'knowledge.txt', 'chunk_id': 1, 'content_type': 'employee_rule', 'update_time': '2025-12-17'}) 2.请假流程:员工请假需提前3天通过企业OA提交申请,经直属领导审批通过后方可生效。紧急情况无法提前申请的,需24小时内补提申请。 (元数据:{'source': 'knowledge.txt', 'chunk_id': 2, 'content_type': 'employee_rule', 'update_time': '2025-12-17'}) 【调试】回答生成耗时:18.78秒 ------------------------------------------------------------------ 回答:<think> 好的,我现在需要解决用户的问题:“入职5年的正式员工有多少天年假?”首先,我要仔细阅读提供的上下文内容,确保理解所有相关的政策和规定。 根据上下文来源,特别是“员工年假政策”,我了解到正式员工的年假安排是基于入职时间的不同阶段。具体来说: 1. **入职满1年不满3年**:每年享有5天带薪年假。 2. **入职满3年不满10年**:每年享有10天带薪年假。 3. **入职满10年及以上**:每年享有15天带薪年假。 现在,问题中的员工是入职了5年。根据第二条政策,入职满3年不满10年,所以他们的年假是10天。接下来,我需要确认是否有其他相关的规则或例外情况影响这个结果。 在“请假流程”部分提到,员工必须提前3天通过企业OA提交申请,并经直属领导审批才能生效。这里的信息可能会影响是否可以享受年假,但根据上下文内容,年假的发放是基于入职时间的,而不是请假的具体安排。因此,即使有请假的情况,年假的发放仍然按照入职满1年的标准来计算。 此外,紧急情况无法提前申请的员工需要24小时内补提申请,这可能影响他们的年假享受,但同样,根据政策,他们仍然可以享受相应的年假天数。 综上所述,入职5年的正式员工应享有10天带薪年假。因此,回答时应该明确指出这一点,并标注对应的规则类型。 </think> 根据“员工年假政策”,入职满3年不满10年,员工每年享有10天带薪年假。因此,入职5年的正式员工有10天年假。 **答案:10天** 请提问:加班调休有效期是多久? ------------------------------调试信息------------------------------ 【调试】检索到的上下文: 1. 加班调休规则:工作日加班可按1:1比例申请调休,调休需在加班后3个月内使用完毕,逾期作废。 # 新增冗余内容(用于调试检索过滤效果) 办公用品申领:每月5号可提交申领表,限领笔、笔记本等基础用品。(元数据:{'source': 'knowledge.txt', 'chunk_id': 3, 'content_type': 'employee_rule', 'update_time': '2025-12-17'}) 2.请假流程:员工请假需提前3天通过企业OA提交申请,经直属领导审批通过后方可生效。紧急情况无法提前申请的,需24小时内补提申请。(元数据:{'source': 'knowledge.txt', 'chunk_id': 2, 'content_type': 'employee_rule', 'update_time': '2025-12-17'}) 【调试】回答生成耗时:10.93秒 ------------------------------------------------------------------ 回答:<think> 好的,我现在需要解决用户的问题:“加班调休有效期是多久?”根据提供的上下文和规则,我得仔细分析。 首先,查看上下文来源:员工手册(2025版)。里面明确提到“工作日加班可按1:1比例申请调休,调休需在加班后3个月内使用完毕,逾期作废。” 这里提到了“3个月”,所以直接引用这个信息作为回答。 接下来,用户的问题是关于有效期的,而规则中也明确说明了调休的有效期是3个月。因此,回答应该直接引用这条规则,不需要添加额外的信息或冗余内容。 最后,确保回答简洁明了,并且标注对应规则类型,这里就是加班调休规则。 </think> 根据员工手册(2025版)中的规则,加班调休有效期为3个月。 请提问:debug 【调试模式】当前检索器配置: - 检索数量k:2 - 元数据过滤条件:{'content_type': 'employee_rule'} - 向量库文档总数:4 请提问:quit 助手已关闭!
2.5 检索效果评估
# 计算检索准确率(人工标注+自动化验证)
test_cases = [
("入职5年年假", ["10天带薪年假"]),
("加班调休有效期", ["3个月内使用完毕"])
]
def evaluate_retrieval(query, expected_answer):
result = retrieval_chain.invoke({"input": query})
return 1 if any(ans in result["answer"] for ans in expected_answer) else 0
# 计算整体准确率
accuracy = sum(evaluate_retrieval(q, e) for q, e in test_cases) / len(test_cases)
print(f"【调试】检索准确率:{accuracy*100}%")输出结果:
【调试】检索准确率:100.0%
六、总结
今天我们完整呈现了 RAG 与向量数据库的深度融合应用,核心价值在于将抽象的技术逻辑转化为可落地的实战示例,同时借助 Ollama 让本地大模型部署与 RAG 结合更具实用性。
向量数据库作为 RAG 的 “记忆中枢”,解决了非结构化文本的语义检索难题,而合理的文本分块、元数据过滤、相似度调试等优化手段,进一步提升了检索精度;Ollama轻量化部署、自定义模型参数的特性,让我们也能低成本搭建私有化 RAG 系统,兼顾数据安全与响应效率。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号