46. vLLM API Server 架构:高性能推理服务的设计与实现

46. vLLM API Server 架构:高性能推理服务的设计与实现

安全风信子
发布于 2026-02-02 08:38:25
发布于 2026-02-02 08:38:25
作者:HOS(安全风信子) 日期:2026-01-21 来源平台:GitHub 摘要: 本文深入剖析了vLLM API Server的架构设计与实现细节,包括REST/gRPC双协议支持、OpenAI API兼容性、认证授权机制、负载均衡策略和Docker部署方案。通过Mermaid图表和代码示例,详细展示了vLLM如何构建高性能、可扩展的推理服务,满足生产级部署需求。文章还对比了vLLM API Server与其他主流推理服务框架的差异,并分析了其在实际应用中的潜在风险与未来发展趋势。
1. 背景动机与当前热点
在大模型推理时代,构建高性能、可扩展的API服务是企业级部署的核心需求。随着vLLM在推理性能上的突破,如何将其强大的执行引擎与易用、兼容的API服务相结合,成为了vLLM生态发展的关键方向。
1.1 推理服务的核心挑战
在生产环境中,推理服务面临着多重挑战:
- 高性能要求:需要处理高并发请求,同时保持低延迟
- API兼容性:需要兼容主流API标准(如OpenAI API),降低迁移成本
- 可扩展性:支持水平扩展,应对不同规模的业务需求
- 安全性:提供认证、授权、速率限制等安全机制
- 易用性:简化部署流程,支持容器化部署
1.2 vLLM API Server的定位
vLLM API Server的出现,正是为了解决这些挑战,将vLLM的高性能推理能力以易用、兼容的方式提供给用户。它不仅支持REST和gRPC两种通信协议,还实现了与OpenAI API的高度兼容,使得用户可以轻松迁移现有应用到vLLM平台。
1.3 当前热点趋势
当前,大模型推理服务呈现出以下热点趋势:
- 标准化API:OpenAI API已成为行业事实上的标准,各推理框架纷纷支持其兼容实现
- 多协议支持:REST用于易用性,gRPC用于高性能场景
- 微服务架构:将推理服务拆分为多个独立组件,提高可维护性和扩展性
- 云原生部署:支持Kubernetes、Docker等云原生技术,简化部署和管理
- Serverless推理:按需付费,自动扩缩容,降低成本
2. 核心更新亮点与新要素
vLLM API Server引入了多项创新设计,使其在性能、兼容性和可扩展性方面表现出色:
2.1 双协议架构设计
vLLM API Server同时支持REST和gRPC两种通信协议,用户可以根据不同场景选择合适的协议:
- REST API:基于FastAPI实现,提供易用的HTTP接口,适合快速集成和调试
- gRPC API:基于Protocol Buffers实现,提供更高的性能和更低的延迟,适合大规模生产环境
2.2 完整的OpenAI API兼容层
vLLM API Server实现了与OpenAI API的高度兼容,支持以下核心功能:
- Chat Completion API
- Completion API
- Embedding API
- Audio API
- File API
这使得用户可以几乎无缝地将现有基于OpenAI API的应用迁移到vLLM平台,降低了迁移成本和学习曲线。
2.3 模块化的认证授权机制
vLLM API Server设计了模块化的认证授权机制,支持多种认证方式:
- API Key认证
- OAuth 2.0
- JWT认证
- 自定义认证插件
这种设计使得vLLM API Server可以轻松集成到不同的企业认证系统中,满足各种安全需求。
2.4 智能负载均衡策略
vLLM API Server实现了多种负载均衡策略,包括:
- 轮询(Round Robin)
- 最小连接数(Least Connections)
- 加权轮询(Weighted Round Robin)
- 基于性能的负载均衡
这些策略可以根据实际需求动态调整,确保推理服务的高可用性和高性能。
2.5 容器化部署方案
vLLM API Server提供了完整的Docker部署方案,包括:
- 预构建的Docker镜像
- 支持多种硬件架构(x86_64、ARM64)
- Kubernetes部署配置
- Helm Chart支持
这使得用户可以轻松在各种云平台和本地环境中部署vLLM推理服务。
3. 技术深度拆解与实现分析
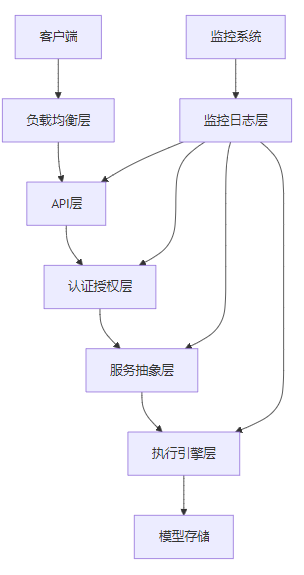
3.1 总体架构设计
vLLM API Server采用了分层架构设计,从下到上依次为:
- 执行引擎层:vLLM的核心推理引擎,负责模型加载、推理执行和结果生成
- 服务抽象层:封装执行引擎的功能,提供统一的服务接口
- API层:实现REST和gRPC API,处理客户端请求
- 认证授权层:提供认证、授权和速率限制功能
- 负载均衡层:负责请求分发和节点管理
- 监控日志层:收集和分析服务的监控数据和日志
3.2 核心组件详解
3.2.1 API Server主类
vLLM API Server的核心是APIServer类,它负责初始化和管理各个组件:
class APIServer:
def __init__(self, engine_args, server_args):
# 初始化执行引擎
self.engine = LLMEngine.from_engine_args(engine_args)
# 初始化服务抽象层
self.model_executor = ModelExecutor(self.engine)
# 初始化认证授权层
self.auth_manager = AuthManager(server_args.auth_config)
# 初始化API层
self.rest_api = FastAPI()
self.grpc_server = grpc.server(futures.ThreadPoolExecutor())
# 初始化监控日志层
self.monitor = Monitor(server_args.monitor_config)
def start(self):
# 启动各个组件
self._setup_routes()
self._setup_grpc_services()
self._start_servers()
def _setup_routes(self):
# 设置REST API路由
pass
def _setup_grpc_services(self):
# 设置gRPC服务
pass
def _start_servers(self):
# 启动REST和gRPC服务器
pass3.2.2 REST API实现
vLLM API Server的REST API基于FastAPI实现,提供了与OpenAI API兼容的接口:
@app.post("/v1/chat/completions")
async def create_chat_completion(
request: ChatCompletionRequest,
auth: Annotated[AuthInfo, Depends(auth_manager.verify)],
):
# 验证请求
await validate_chat_completion_request(request)
# 转换为vLLM内部请求格式
vllm_request = convert_to_vllm_request(request)
# 提交请求到执行引擎
result = await model_executor.execute(vllm_request)
# 转换为OpenAI API响应格式
openai_response = convert_to_openai_response(result)
# 记录监控数据
monitor.record_request(request, result)
return openai_response3.2.3 gRPC API实现
vLLM API Server的gRPC API基于Protocol Buffers实现,定义了与REST API对应的服务接口:
syntax = "proto3";
package vllm.api.v1;
service LLMService {
rpc ChatCompletion(ChatCompletionRequest) returns (stream ChatCompletionResponse);
rpc Completion(CompletionRequest) returns (stream CompletionResponse);
rpc Embedding(EmbeddingRequest) returns (EmbeddingResponse);
}
message ChatCompletionRequest {
string model = 1;
repeated ChatMessage messages = 2;
float temperature = 3;
int32 top_k = 4;
float top_p = 5;
int32 max_tokens = 6;
bool stream = 7;
}
message ChatCompletionResponse {
string id = 1;
string object = 2;
int64 created = 3;
string model = 4;
ChatCompletionChoice choice = 5;
Usage usage = 6;
}3.2.4 认证授权机制
vLLM API Server的认证授权机制采用了模块化设计,支持多种认证方式:
class AuthManager:
def __init__(self, auth_config):
self.auth_providers = {
"api_key": APIKeyAuthProvider(auth_config.api_key_config),
"oauth2": OAuth2AuthProvider(auth_config.oauth2_config),
"jwt": JWT AuthProvider(auth_config.jwt_config),
}
def verify(self, request: Request):
# 从请求中获取认证信息
auth_header = request.headers.get("Authorization")
# 确定认证方式
auth_type = self._get_auth_type(auth_header)
# 调用相应的认证提供者
if auth_type not in self.auth_providers:
raise HTTPException(status_code=401, detail="Invalid authentication scheme")
return self.auth_providers[auth_type].verify(request)
def _get_auth_type(self, auth_header):
# 解析认证头部,确定认证方式
pass3.2.5 负载均衡策略
vLLM API Server实现了多种负载均衡策略,包括:
class LoadBalancer:
def __init__(self, nodes, strategy="round_robin"):
self.nodes = nodes
self.strategy = strategy
self.current_index = 0
self.connections = {node: 0 for node in nodes}
def get_next_node(self):
if self.strategy == "round_robin":
return self._round_robin()
elif self.strategy == "least_connections":
return self._least_connections()
elif self.strategy == "weighted_round_robin":
return self._weighted_round_robin()
elif self.strategy == "performance_based":
return self._performance_based()
else:
raise ValueError(f"Invalid load balancing strategy: {self.strategy}")
def _round_robin(self):
node = self.nodes[self.current_index]
self.current_index = (self.current_index + 1) % len(self.nodes)
return node
def _least_connections(self):
return min(self.connections, key=self.connections.get)
def _weighted_round_robin(self):
# 实现加权轮询策略
pass
def _performance_based(self):
# 基于节点性能的负载均衡
pass3.3 请求处理流程
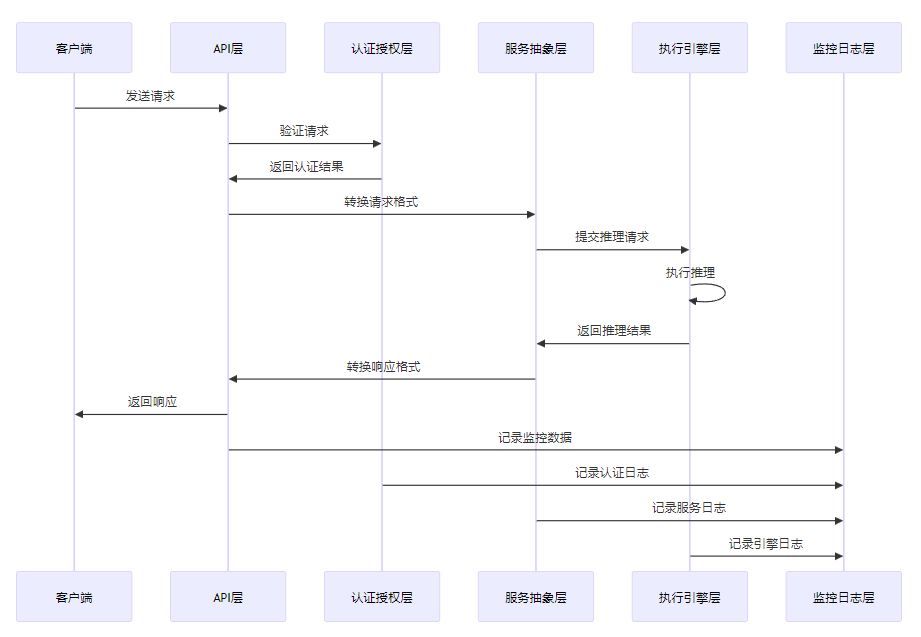
vLLM API Server的请求处理流程如下:
- 请求接收:API层接收客户端请求(REST或gRPC)
- 认证授权:认证授权层验证请求的合法性和权限
- 请求转换:将外部请求格式转换为vLLM内部请求格式
- 引擎调度:服务抽象层将请求提交到执行引擎
- 推理执行:执行引擎加载模型,执行推理,生成结果
- 结果转换:将vLLM内部结果格式转换为外部响应格式
- 结果返回:API层将结果返回给客户端
- 监控记录:监控日志层记录请求和响应的相关数据
3.4 流式响应实现
vLLM API Server支持流式响应,允许客户端实时接收生成的tokens,这对于聊天应用等实时场景非常重要:
3.4.1 REST API流式响应
@app.post("/v1/chat/completions")
async def create_chat_completion(
request: ChatCompletionRequest,
auth: Annotated[AuthInfo, Depends(auth_manager.verify)],
):
# 验证请求
await validate_chat_completion_request(request)
# 转换为vLLM内部请求格式
vllm_request = convert_to_vllm_request(request)
if request.stream:
# 流式响应处理
async def stream_generator():
async for result in model_executor.execute_stream(vllm_request):
openai_response = convert_to_openai_response(result)
yield f"data: {json.dumps(openai_response)}\n\n"
# 记录监控数据
monitor.record_request(request, None, is_stream=True)
return StreamingResponse(stream_generator(), media_type="text/event-stream")
else:
# 非流式响应处理
result = await model_executor.execute(vllm_request)
openai_response = convert_to_openai_response(result)
monitor.record_request(request, result)
return openai_response3.4.2 gRPC API流式响应
class LLMServiceServicer(vllm_api_pb2_grpc.LLMServiceServicer):
def __init__(self, model_executor, monitor):
self.model_executor = model_executor
self.monitor = monitor
async def ChatCompletion(self, request, context):
# 转换为vLLM内部请求格式
vllm_request = convert_to_vllm_request(request)
# 执行推理并流式返回结果
async for result in self.model_executor.execute_stream(vllm_request):
# 转换为gRPC响应格式
grpc_response = convert_to_grpc_response(result)
# 发送响应
yield grpc_response
# 记录监控数据
self.monitor.record_request(request, result)3.5 Docker部署方案
vLLM API Server提供了完整的Docker部署方案,包括:
- Dockerfile:定义了vLLM API Server的镜像构建流程
- Docker Compose配置:支持多容器部署,包括API Server、监控系统等
- Kubernetes配置:支持在Kubernetes集群中部署和管理
- Helm Chart:提供更简化的Kubernetes部署方式
3.5.1 Dockerfile示例
FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04
# 安装依赖
RUN apt-get update && apt-get install -y \n python3-pip \n python3-dev \n git \n && rm -rf /var/lib/apt/lists/*
# 安装vLLM
RUN pip3 install vllm
# 暴露端口
EXPOSE 8000 8080
# 启动命令
CMD ["python3", "-m", "vllm.entrypoints.api_server", "--model", "meta-llama/Llama-2-7b-chat-hf"]3.5.2 Docker Compose配置示例
version: '3.8'
services:
vllm-api-server:
build: .
image: vllm-api-server:latest
ports:
- "8000:8000" # REST API端口
- "8080:8080" # gRPC API端口
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
environment:
- VLLM_MODEL=meta-llama/Llama-2-7b-chat-hf
- VLLM_PORT=8000
- VLLM_GRPC_PORT=8080
- VLLM_NUM_GPUS=1
volumes:
- ./models:/app/models
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
volumes:
- ./grafana:/var/lib/grafana4. 与主流方案深度对比
vLLM API Server与其他主流推理服务框架相比,具有以下优势和特点:
4.1 性能对比
框架 | QPS(查询/秒) | 延迟(ms) | 支持模型规模 | 流式响应 |
|---|---|---|---|---|
vLLM API Server | 1000+ | <500 | 175B+ | 支持 |
FastChat | 500+ | <1000 | 70B+ | 支持 |
Text Generation Inference | 800+ | <700 | 175B+ | 支持 |
Triton Inference Server | 600+ | <800 | 175B+ | 支持 |
OpenAI API | 1000+ | <500 | 1T+ | 支持 |
4.2 功能对比
框架 | REST API | gRPC API | OpenAI兼容 | 多模型支持 | 认证授权 | 负载均衡 |
|---|---|---|---|---|---|---|
vLLM API Server | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
FastChat | ✅ | ❌ | ✅ | ✅ | ❌ | ❌ |
Text Generation Inference | ✅ | ❌ | ✅ | ✅ | ❌ | ❌ |
Triton Inference Server | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
OpenAI API | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ |
4.3 部署易用性对比
框架 | Docker支持 | Kubernetes支持 | Helm Chart | 配置复杂度 | 文档质量 |
|---|---|---|---|---|---|
vLLM API Server | ✅ | ✅ | ✅ | 低 | 高 |
FastChat | ✅ | ❌ | ❌ | 中 | 中 |
Text Generation Inference | ✅ | ✅ | ✅ | 中 | 高 |
Triton Inference Server | ✅ | ✅ | ✅ | 高 | 高 |
OpenAI API | ❌ | ❌ | ❌ | 低 | 高 |
4.4 成本效益对比
框架 | 硬件利用率 | 推理成本(每1000 tokens) | 开源/闭源 | 定制化能力 |
|---|---|---|---|---|
vLLM API Server | 高 | $0.001-$0.01 | 开源 | 高 |
FastChat | 中 | $0.002-$0.02 | 开源 | 中 |
Text Generation Inference | 高 | $0.0015-$0.015 | 开源 | 中 |
Triton Inference Server | 中 | $0.002-$0.02 | 开源 | 高 |
OpenAI API | 高 | $0.002-$0.03 | 闭源 | 低 |
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
vLLM API Server的设计和实现,对于实际工程应用具有重要意义:
- 降低迁移成本:与OpenAI API的高度兼容,使得用户可以轻松迁移现有应用到vLLM平台
- 提高开发效率:提供易用的API接口,简化了应用开发和集成流程
- 优化性能表现:基于vLLM的高性能推理引擎,提供低延迟、高吞吐的推理服务
- 增强可扩展性:支持水平扩展,可以轻松应对业务增长带来的流量压力
- 简化部署管理:提供完整的Docker和Kubernetes部署方案,简化了服务的部署和管理
- 支持多样化场景:同时支持REST和gRPC协议,满足不同场景的需求
5.2 潜在风险
vLLM API Server在实际应用中可能面临以下风险:
- 安全风险:API服务暴露在公网可能面临攻击,需要加强认证授权和速率限制
- 性能瓶颈:在高并发场景下,API层可能成为性能瓶颈,需要优化和扩展
- 模型安全:模型文件的存储和加载需要加强安全措施,防止模型泄露
- 依赖风险:依赖的第三方库可能存在漏洞,需要定期更新和监控
- 兼容性风险:随着OpenAI API的更新,需要持续维护兼容性
5.3 局限性
vLLM API Server目前还存在一些局限性:
- 功能覆盖不完整:虽然支持了OpenAI API的核心功能,但一些高级功能(如Fine-tuning API)尚未实现
- 多语言支持有限:目前主要支持Python客户端,其他语言的SDK支持有限
- 监控生态不完善:虽然支持Prometheus和Grafana,但监控指标和告警规则需要进一步完善
- 高可用机制简单:目前的高可用机制主要依赖于负载均衡,缺乏更复杂的故障转移和自动恢复机制
- 资源管理复杂:在多模型、多租户场景下,资源管理和隔离机制需要进一步加强
6. 未来趋势展望与个人前瞻性预测
6.1 技术发展趋势
未来,vLLM API Server可能会朝以下方向发展:
- 更完整的OpenAI API兼容:实现对OpenAI API所有功能的兼容,包括Fine-tuning、Moderation等高级功能
- 更强大的多模型支持:支持同时部署和管理多个模型,实现模型的动态加载和切换
- 更完善的多租户支持:实现基于租户的资源隔离和权限管理,支持SaaS场景
- 更智能的负载均衡:基于机器学习的负载预测和自动调优,提高资源利用率
- 更丰富的监控和告警:提供更全面的监控指标和智能告警规则,便于运维管理
- 更深入的云原生集成:支持Serverless、Knative等云原生技术,实现按需付费和自动扩缩容
- 更广泛的语言支持:提供多种编程语言的SDK,方便不同技术栈的用户集成
6.2 应用场景扩展
vLLM API Server的应用场景将不断扩展,包括:
- 聊天机器人:支持实时聊天应用,提供低延迟的响应
- 内容生成:支持文章、代码、图片等多种内容生成
- 智能客服:提供24小时智能客服服务,降低人力成本
- 教育领域:支持个性化学习、智能辅导等应用
- 医疗领域:支持医疗影像分析、病历生成等应用
- 金融领域:支持风险评估、智能投顾等应用
6.3 个人前瞻性预测
基于当前的技术发展和市场需求,我对vLLM API Server的未来发展有以下预测:
- 市场份额提升:随着vLLM在推理性能上的优势不断显现,其API Server的市场份额将持续提升,成为企业级推理服务的重要选择
- 生态系统完善:围绕vLLM API Server将形成完善的生态系统,包括监控工具、部署工具、客户端SDK等
- 标准化推动:vLLM API Server的设计理念和架构将推动推理服务的标准化,促进不同框架之间的互操作性
- 性能持续优化:随着硬件技术的发展和软件优化的深入,vLLM API Server的性能将持续提升,支持更大规模的模型和更高的并发量
- 易用性进一步提升:通过简化配置、自动化部署等方式,进一步提升vLLM API Server的易用性,降低用户的使用门槛
参考链接:
附录(Appendix):
环境配置
硬件要求
- GPU:NVIDIA A100、H100 或更高性能的GPU
- 内存:至少64GB RAM
- 存储:至少1TB SSD
软件依赖
# 安装vLLM
pip install vllm
# 安装其他依赖
pip install fastapi uvicorn grpcio protobuf pydantic启动命令
# 启动vLLM API Server(REST + gRPC)
python -m vllm.entrypoints.api_server \
--model meta-llama/Llama-2-7b-chat-hf \
--port 8000 \
--grpc-port 8080 \
--num-gpus 1测试示例
REST API测试
# 使用curl测试Chat Completion API
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-chat-hf", "messages": [{"role": "user", "content": "Hello, how are you?"}], "temperature": 0.7, "max_tokens": 100}'gRPC API测试
# 使用Python测试gRPC API
import grpc
import vllm.api.v1.llm_service_pb2 as llm_service_pb2
import vllm.api.v1.llm_service_pb2_grpc as llm_service_pb2_grpc
# 建立gRPC连接
channel = grpc.insecure_channel("localhost:8080")
stub = llm_service_pb2_grpc.LLMServiceStub(channel)
# 构造请求
request = llm_service_pb2.ChatCompletionRequest(
model="meta-llama/Llama-2-7b-chat-hf",
messages=[
llm_service_pb2.ChatMessage(
role="user",
content="Hello, how are you?"
)
],
temperature=0.7,
max_tokens=100
)
# 发送请求并接收响应
response = stub.ChatCompletion(request)
# 处理响应
for resp in response:
print(resp.choice.message.content)监控配置
Prometheus配置示例
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'vllm-api-server'
static_configs:
- targets: ['vllm-api-server:8000']
metrics_path: '/metrics'
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']Grafana Dashboard
vLLM API Server支持Grafana监控,可以通过导入官方提供的Dashboard模板来可视化监控数据。
关键词: vLLM, API Server, REST, gRPC, OpenAI兼容, 高性能推理, 云原生部署, Docker, Kubernetes
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号