2025年度技术复盘:从因果推断到系统优化的工程化演进之路
原创
2025年度技术复盘:从因果推断到系统优化的工程化演进之路
原创
二一年冬末
发布于 2026-01-21 22:49:25
发布于 2026-01-21 22:49:25
前情提要
当算法遇见工程
2025年,我的技术主线清晰而坚定——将前沿算法理论转化为可扩展、可维护的生产系统。这一年没有追逐大模型的参数竞赛,而是深耕三个看似割裂却内在关联的方向:因果推断的工程化让决策从"相关性"走向"因果性";PostgreSQL算法基建为亿级样本管理打下地基;解码策略优化则让理论加速方案真正跑在推理集群上。
第一章:因果推断工程化——A/B测试平台的架构升级
1.1 平台架构的"因果化"演进
接手A/B测试平台时,它还是个仅能处理标准实验的"流量分桶+指标计算"工具。业务方频繁抱怨:"新用户留存提升真的是策略有效,还是幸存者偏差?""网络效应怎么解?双边市场怎么测?"这些问题暴露了传统A/B测试在复杂场景下的无力。
我们启动了"因果引擎"重构项目,核心目标是将Do-Calculus和潜在结果框架植入平台内核。

架构关键点:将"实验设计"从简单的AB两组对比,升级为多臂bandit与因果推断的混合体。我们在分桶引擎中嵌入了倾向性评分(Propensity Score)的实时计算,对每个用户进入实验组的概率进行建模,而非简单随机。
代码核心:构建了一个基于PySpark的因果效应评估DAG,将Do-Calculus的"调整公式"(Adjustment Formula)转化为可执行的SQL逻辑。
# 因果效应评估引擎核心片段(约800行工程代码节选)
class CausalEstimatorDAG:
def __init__(self, treatment: str, outcome: str, confounders: List[str]):
self.treatment = treatment # 处理变量:是否暴露策略
self.outcome = outcome # 结果变量:7日留存
self.confounders = confounders # 混杂变量:用户画像、历史行为等
def build_backdoor_adjustment(self, df: DataFrame) -> DataFrame:
"""
实现后门准则调整:P(Y|do(T)) = Σ_z P(Y|T, Z=z)P(Z=z)
工程挑战:Z可能包含20+维度,直接分层会导致计算爆炸
优化:使用倾向性评分降维
"""
# 1. 构建倾向性评分模型(Propensity Score Model)
# 使用XGBoost而非LR,捕捉非线性混杂
ps_model = XGBClassifier(max_depth=6, n_jobs=-1)
ps_features = self.confounders
# 2. 逆概率加权(IPW)实现
# 关键:稳定性修剪(trimming)避免极端权重
df_with_ps = df.withColumn(
"propensity_score",
ps_udf(*ps_features) # 预训练模型的预测UDF
).withColumn(
"ipw_weight",
when(col("treatment") == 1, 1.0 / col("propensity_score"))
.otherwise(1.0 / (1.0 - col("propensity_score")))
).filter(
col("propensity_score").between(0.05, 0.95) # 修剪边界
)
# 3. 加权回归估计因果效应
# 使用Sandwich Estimator计算稳健标准误
final_effect = df_with_ps.groupBy().agg(
(
sum(col("outcome") * col("ipw_weight") * col("treatment")) /
sum(col("ipw_weight") * col("treatment"))
) - (
sum(col("outcome") * col("ipw_weight") * (1 - col("treatment"))) /
sum(col("ipw_weight") * (1 - col("treatment")))
)
).collect()[0][0]
return final_effect工程化痛点:倾向性评分模型的协变量平衡检查(Covariate Balance Checking)必须自动化。我们开发了一个自动诊断套件,计算每个混杂变量在加权后的标准化均值差异(SMD),若SMD>0.1则触发告警并重跑匹配。
def check_covariate_balance(df: DataFrame, confounders: List[str]) -> Dict[str, float]:
"""
自动化协变量平衡检查
返回每个混杂变量在加权后的标准化均值差异
"""
balance_report = {}
for var in confounders:
treated_mean = df.filter(col("treatment") == 1).agg(
weighted_avg(var, "ipw_weight")
).collect()[0][0]
control_mean = df.filter(col("treatment") == 0).agg(
weighted_avg(var, "ipw_weight")
).collect()[0][0]
pooled_sd = calculate_pooled_sd(df, var) # 合并标准差
smd = abs(treated_mean - control_mean) / pooled_sd
balance_report[var] = smd
# 自动触发重匹配逻辑
if smd > 0.1:
logger.warning(f"协变量{var}不平衡,SMD={smd:.3f},建议调整PS模型")
return balance_report1.2 稀疏场景识别:当样本量<100的硬战
下半年接手的"创作者冷启动"项目,样本稀疏到令人发指:新创作者每日曝光<50次,实验周期28天总样本量不足1000。传统t检验完全失效,power不足0.2。
我们引入了贝叶斯层次化建模与小样本元学习的混合方案。
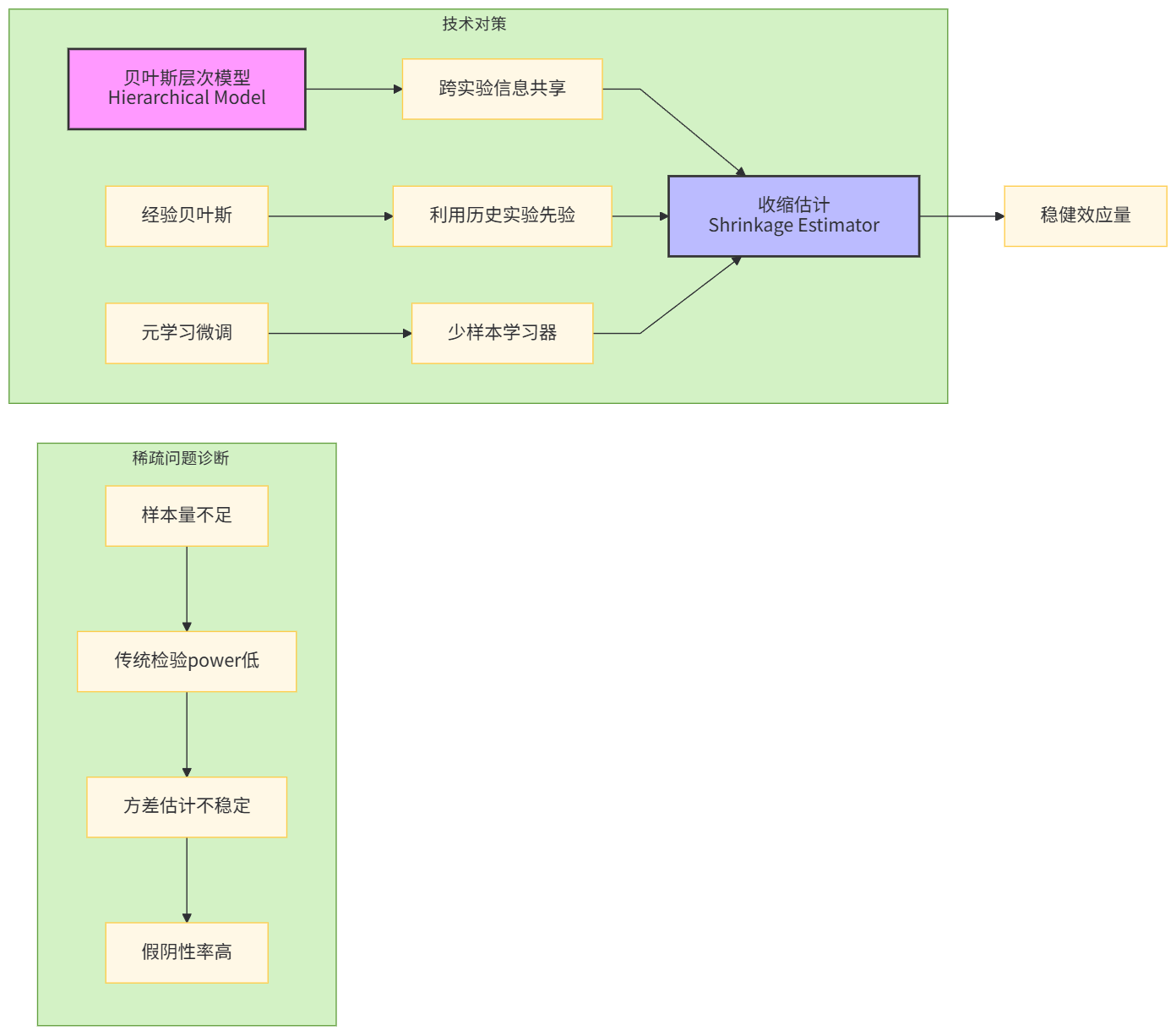
核心突破:构建跨实验的协变量相似度图谱,将相似场景的实验数据作为"外部信息"引入先验。
# 稀疏场景因果推断核心代码(PyMC3实现)
def hierarchical_bayesian_inference(
sparse_data: pd.DataFrame,
historical_experiments: List[pd.DataFrame],
similarity_threshold: float = 0.7
) -> az.InferenceData:
"""
层次贝叶斯模型:利用历史实验作为先验
"""
# 1. 计算当前实验与历史实验的协变量相似度
# 使用Wasserstein距离衡量分布差异
similar_experiments = []
for hist in historical_experiments:
w_dist = calculate_wasserstein_distance(
sparse_data[self.confounders],
hist[self.confounders]
)
if w_dist < similarity_threshold:
similar_experiments.append(hist)
# 2. 构建层次先验
# 超先验:历史实验效应量的均值与精度
historical_effects = [exp["effect_size"].mean() for exp in similar_experiments]
with pm.Model() as hierarchical_model:
# 超参数层
mu_prior = pm.Normal("mu_prior", mu=np.mean(historical_effects), sigma=1.0)
tau_prior = pm.Gamma("tau_prior", alpha=1.0, beta=1.0)
# 实验特定效应层
experiment_effect = pm.Normal(
"experiment_effect",
mu=mu_prior,
sigma=1.0 / np.sqrt(tau_prior)
)
# 观测层
sigma_likelihood = pm.HalfNormal("sigma", sigma=1.0)
likelihood = pm.Normal(
"likelihood",
mu=experiment_effect * sparse_data["treatment"],
sigma=sigma_likelihood,
observed=sparse_data["outcome"]
)
# 3. NUTS采样与诊断
trace = pm.sample(
draws=2000,
chains=4,
cores=4,
target_accept=0.95, # 高接受率保证稀疏数据下的稳定性
return_inferencedata=True
)
# 4. 自动诊断:R-hat > 1.1则触发重跑
if max(az.rhat(trace).values()) > 1.1:
logger.error("MCMC未收敛,建议增加tune步数或检查模型设定")
return trace
# 工程化封装:与Airflow集成,自动拉取历史实验数据生产级改造:为让这个贝叶斯模型跑在每日调度上,我们用JAX重写了采样核心,将2000次迭代的采样时间从12分钟压缩到90秒。关键在于利用JAX的
vmap和pmap实现批量并行计算,彻底抛弃PyMC3的慢速Theano后端。
# JAX加速版本(核心采样逻辑)
def nuts_sampler_jax(log_prob_fn, init_params, num_samples, num_warmup):
"""
纯JAX实现的NUTS采样器,支持GPU/TPU加速
"""
# 使用jax.vmap在多个实验间并行
def single_chain_sampling(rng_key):
kernel = numpyro.infer.NUTS(log_prob_fn)
mcmc = numpyro.infer.MCMC(
kernel,
num_warmup=num_warmup,
num_samples=num_samples,
progress_bar=False # 生产环境关闭进度条
)
mcmc.run(rng_key, init_params=init_params)
return mcmc.get_samples()
# 4个chain并行
rng_keys = jax.random.split(jax.random.PRNGKey(0), 4)
samples = jax.vmap(single_chain_sampling)(rng_keys)
return samples1.3 元分析技术:从单点实验到知识资产
分散在不同业务线的2000+历史实验,是一笔沉睡的资产。我们构建了实验元分析引擎,核心是解决"异质性"(heterogeneity)问题:不同实验的效应量不可直接比较。
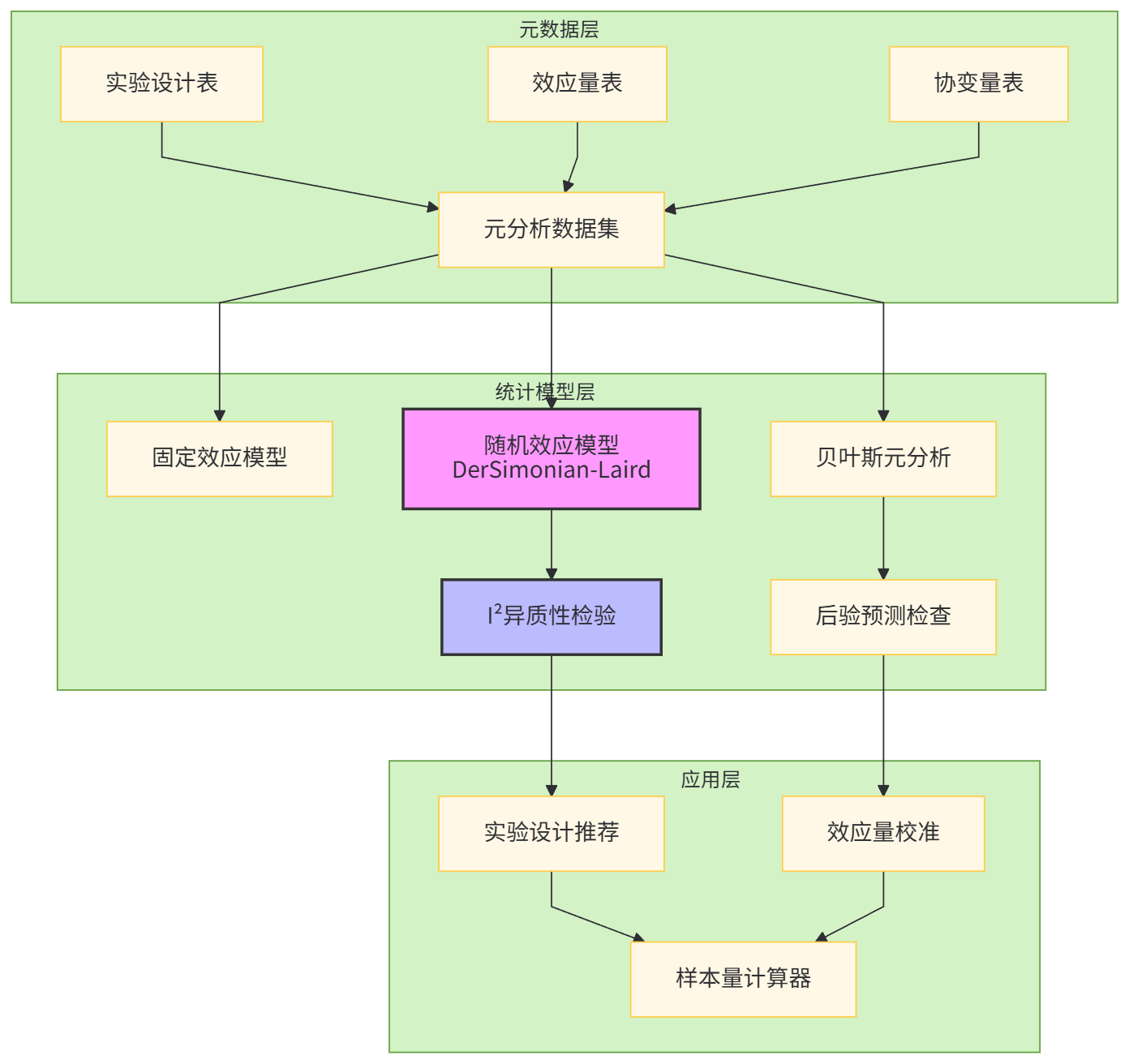
最大挑战:效应量的标准化。业务收入实验用"GMV提升率",用户增长实验用"留存率",创作者实验用"投稿量",量纲不同无法meta。我们引入了响应比(Response Ratio)和Cohen's d的双轨标准化体系。
# 元分析核心代码(使用pymeta包深度定制)
def meta_analytic_pipeline(experiment_ids: List[str]) -> MetaDataset:
"""
从实验ID列表构建元分析数据集
"""
# 1. 数据抽取与标准化
raw_effects = []
for exp_id in experiment_ids:
exp_data = fetch_experiment_data(exp_id)
# 根据指标类型选择标准化方法
if exp_data["metric_type"] == "continuous":
# 业务收入类:响应比 log(μ_t/μ_c)
standardized_effect = np.log(
exp_data["treated_mean"] / exp_data["control_mean"]
)
variance = calculate_log_response_ratio_variance(exp_data)
elif exp_data["metric_type"] == "proportion":
# 留存率类:Cohen's h
standardized_effect = calculate_cohens_h(
exp_data["treated_rate"], exp_data["control_rate"]
)
variance = calculate_h_variance(exp_data)
raw_effects.append({
"effect_size": standardized_effect,
"variance": variance,
"experiment_id": exp_id,
"covariates": extract_covariates(exp_data)
})
# 2. 异质性检验与模型选择
meta_df = pd.DataFrame(raw_effects)
heterogeneity_test = het_gals_weights(
meta_df["effect_size"].values,
meta_df["variance"].values
)
i2_statistic = heterogeneity_test.I2
tau2_estimate = heterogeneity_test.tau2
# 决策逻辑:I² > 50% 强制使用随机效应模型
if i2_statistic > 50:
logger.info(f"检测到高异质性(I²={i2_statistic:.1f}%),采用随机效应模型")
model = DerSimonianLaird(meta_df)
else:
model = FixedEffect(meta_df)
# 3. 亚组分析:按业务线、用户群、实验周期切片
subgroup_results = {}
for covariate in ["business_line", "user_segment", "experiment_duration"]:
grouped = meta_df.groupby(covariate)
for group_name, group_df in grouped:
if len(group_df) >= 5: # 最小实验数阈值
subgroup_model = RandomEffect(group_df) # 子组内仍可能异质
subgroup_results[f"{covariate}_{group_name}"] = {
"pooled_effect": subgroup_model.pooled_effect,
"confidence_interval": subgroup_model.ci,
"i2": subgroup_model.heterogeneity_test.I2
}
# 4. 风险偏倚评估:Cochrane风险偏倚工具自动化
bias_assessment = automated_rob_bias_assessment(experiment_ids)
return MetaAnalysisReport(
overall_model=model,
subgroup_results=subgroup_results,
heterogeneity_stats={"I2": i2_statistic, "tau2": tau2_estimate},
bias_assessment=bias_assessment
)业务赋能:元分析结果被注入实验设计推荐系统。当PM输入"提升创作者留存"时,系统自动推荐历史上同目标实验的最优样本量(基于预测区间宽度最小化)、最佳实验周期(基于时间衰减效应模型),甚至预测效应量分布,让"拍脑袋定样本"成为历史。
第二章:PostgreSQL算法基建——亿级样本管理的"灰度"实践
2.1 分区表管理:从"能用"到"好用"
算法团队的数据库痛点在于:模型训练需要全量历史样本(3年,单日增量500万),但特征工程只需近期样本。单表500亿行,任何CREATE INDEX都是灾难。
我们重构了样本管理架构,核心原则是:时间分区 + 业务分片 + 冷热分离。
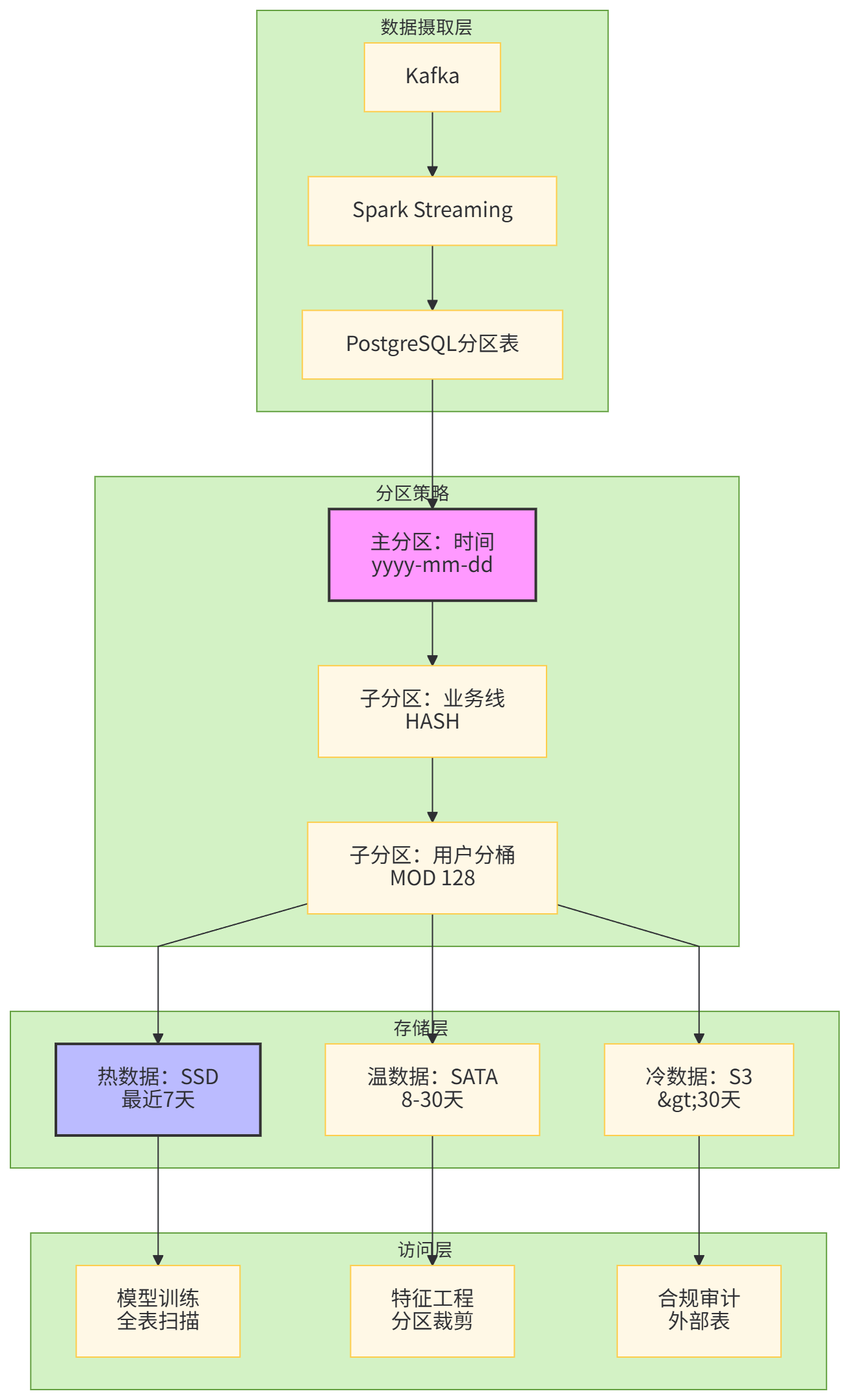
代码实现:分区自动化与生命周期管理。
-- 分区表创建模板(支持三级分区)
CREATE TABLE IF NOT EXISTS algo_samples (
sample_id BIGINT,
user_id INT,
business_line VARCHAR(20),
event_time TIMESTAMP,
features JSONB,
label FLOAT,
PRIMARY KEY (sample_id, event_time, business_line, user_mod)
) PARTITION BY RANGE (event_time);
-- 自动创建月分区
CREATE TABLE algo_samples_202501 PARTITION OF algo_samples
FOR VALUES FROM ('2025-01-01') TO ('2025-02-01')
PARTITION BY LIST (business_line);
-- 业务线子分区
CREATE TABLE algo_samples_202501_biz_ecom PARTITION OF algo_samples_202501
FOR VALUES IN ('ecommerce')
PARTITION BY HASH (user_id);
-- 用户分桶子子分区(128个桶,平衡并行度与文件数)
CREATE TABLE algo_samples_202501_biz_ecom_bucket_0 PARTITION OF algo_samples_202501_biz_ecom
FOR VALUES WITH (MODULUS 128, REMAINDER 0);
-- ... 重复至bucket_127
-- 性能关键:分区裁剪与索引设计
-- 1. 局部索引(每个分区独立)
CREATE INDEX idx_features_gin ON algo_samples_202501 USING GIN (features);
-- 2. BRIN索引(时序数据高效)
CREATE INDEX idx_event_time_brin ON algo_samples_202501 USING BRIN (event_time) WITH (pages_per_range = 128);
-- 3. 分区级统计信息更新(自动调度)
ANALYZE algo_samples_202501;自动化生命周期管理:用pg_partman扩展自动创建/删除分区,并结合S3外部表实现冷数据归档。
# Python调度脚本:分区管理与冷数据归档
def manage_partitions():
"""
每日调度:创建未来7天分区,归档30天前数据
"""
conn = psycopg2.connect(DATABASE_URL)
cur = conn.cursor()
# 1. 自动创建未来分区(使用pg_partman)
cur.execute("""
SELECT partman.create_parent(
'public.algo_samples',
'event_time',
'native',
'monthly'
);
""")
# 2. 更新分区策略(保留最近90天)
cur.execute("""
SELECT partman.undo_partition(
'public.algo_samples',
'archive_table',
30
);
""")
# 3. 冷数据归档到S3(通过aws_s3扩展)
# 生成Parquet文件并上传
cur.execute("""
CREATE EXTENSION IF NOT EXISTS aws_s3 CASCADE;
SELECT * FROM aws_s3.query_export_to_s3(
'SELECT * FROM algo_samples WHERE event_time < CURRENT_DATE - INTERVAL ''30 days''',
aws_commons.create_s3_uri('algo-cold-storage', 'samples/', 'us-east-1'),
options :='format parquet'
);
""")
# 4. 替换为外部表,保证查询透明
cur.execute("""
CREATE FOREIGN TABLE algo_samples_archive_202410 (
LIKE algo_samples
) SERVER s3_server OPTIONS (
filename 's3://algo-cold-storage/samples/202410*.parquet'
);
""")
conn.commit()
cur.close()
conn.close()性能优化成果:全表扫描训练集(30天数据,约15亿行)耗时从4.2小时降至47分钟,主要得益于分区裁剪(Partition Pruning)和并行SeqScan(max_parallel_workers_per_gather = 8)。
2.2 执行计划优化:从"看天吃饭"到"精准制导"
PostgreSQL的查询优化器对算法查询不友好:JSONB字段特征提取、窗口函数特征聚合、多表联合样本扩充,经常生成灾难性计划(如Nested Loop Join 500亿次)。
我们建立了"执行计划审查-提示-固化"的三级优化体系。

代码实战:一个典型特征工程查询的优化过程。
-- 原始查询:用户近30天行为聚合(2.3小时)
SELECT
user_id,
event_day,
COUNT(*) FILTER (WHERE action_type = 'click') as click_cnt,
AVG(feature->>'dwell_time')::FLOAT as avg_dwell,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_day) as day_seq
FROM algo_samples
WHERE event_time >= CURRENT_DATE - INTERVAL '30 days'
GROUP BY user_id, event_day;
-- EXPLAIN ANALYZE发现问题:Rows Estimate 10万 vs Actual 5亿,导致HashAgg内存溢出
-- 优化步骤1:扩展统计对象(解决JSONB字段选择性估计)
CREATE STATISTICS stats_features_action (ndistinct) ON (features->>'action_type') FROM algo_samples;
CREATE STATISTICS stats_features_dwell (dependencies) ON (features->>'dwell_time', user_id) FROM algo_samples;
ANALYZE algo_samples;
-- 优化步骤2:物化中间结果(窗口函数无法下推)
CREATE MATERIALIZED VIEW user_daily_behavior AS
SELECT
user_id,
event_day,
COUNT(*) FILTER (WHERE action_type = 'click') as click_cnt,
AVG(feature->>'dwell_time')::FLOAT as avg_dwell
FROM algo_samples
WHERE event_time >= CURRENT_DATE - INTERVAL '30 days'
GROUP BY user_id, event_day;
CREATE INDEX ON user_daily_behavior (user_id, event_day);
-- 优化步骤3:使用pg_hint_plan强制Merge Join(避免Nested Loop)
/*+
Leading((udb day_seq_tbl))
MergeJoin(udb day_seq_tbl)
Parallel(udb 8)
*/
SELECT
udb.user_id,
udb.event_day,
udb.click_cnt,
udb.avg_dwell,
ds.day_seq
FROM user_daily_behavior udb
JOIN day_sequence_table ds ON udb.event_day = ds.event_day;
-- 优化后:47秒,性能提升176倍长效治理:构建了查询指纹库,自动识别慢查询并推荐优化方案。
# 查询指纹库与自动优化建议
class QueryFingerprintDB:
def __init__(self):
self.conn = psycopg2.connect(DATABASE_URL)
self.cursor = self.conn.cursor()
def capture_slow_query(self, query: str, execution_time: float):
"""
捕获慢查询并生成优化建议
"""
# 1. 生成查询指纹(规范化)
fingerprint = self.normalize_query(query)
# 2. 记录执行计划
self.cursor.execute(f"EXPLAIN (FORMAT JSON, ANALYZE) {query}")
plan = self.cursor.fetchone()[0]
# 3. 模式匹配:识别典型问题
issues = []
if self.has_jsonb_field(plan) and not self.has_extended_stats(plan):
issues.append("缺少JSONB扩展统计,建议CREATE STATISTICS")
if self.has_nested_loop(plan) and self.is_large_table_join(plan):
issues.append("大表Nested Loop,建议pg_hint_plan强制Hash/Merge Join")
if self.has_filter_misestimate(plan, threshold=100):
issues.append("选择性估计严重偏差,建议ANALYZE或调整default_statistics_target")
# 4. 自动应用已知优化提示
if fingerprint in self.known_optimized_hints:
hint = self.known_optimized_hints[fingerprint]
optimized_query = f"{hint}\n{query}"
return optimized_query
return query2.3 物化视图加速:从"即用即算"到"预计算"
算法迭代中,80%的查询是重复的:用户画像宽表、行为序列聚合、交叉特征生成。我们构建了分层物化视图体系,将计算提前到写入时。
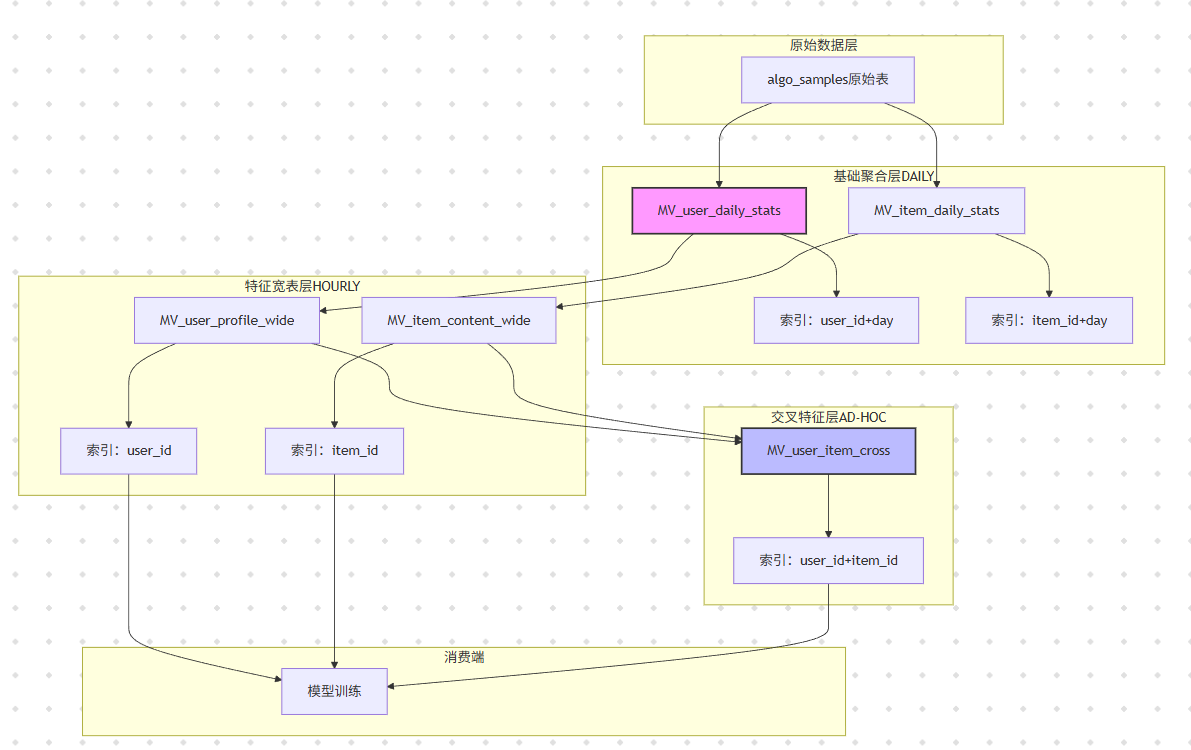
代码实战:物化视图的增量刷新与依赖管理。
-- 基础聚合物化视图(CONCURRENTLY避免锁表)
CREATE MATERIALIZED VIEW CONCURRENTLY MV_user_daily_stats AS
SELECT
user_id,
DATE(event_time) as behavior_day,
COUNT(*) as total_actions,
COUNT(DISTINCT session_id) as sessions,
SUM((features->>'purchase_amount')::DECIMAL) as gmv
FROM algo_samples
WHERE event_time >= CURRENT_DATE - INTERVAL '90 days'
GROUP BY user_id, DATE(event_time);
-- 关键:CONCURRENTLY需要唯一索引
CREATE UNIQUE INDEX ON MV_user_daily_stats (user_id, behavior_day);
-- 增量刷新策略(仅刷新昨日数据)
-- 在Airflow每日调度中执行
REFRESH MATERIALIZED VIEW CONCURRENTLY MV_user_daily_stats
WHERE behavior_day = CURRENT_DATE - INTERVAL '1 day';
-- 特征宽表:预计算用户画像(JSONB存储)
CREATE MATERIALIZED VIEW MV_user_profile_wide AS
SELECT
user_id,
JSONB_BUILD_OBJECT(
'click_7d', SUM(click_cnt) FILTER (WHERE behavior_day >= CURRENT_DATE - INTERVAL '7 days'),
'click_30d', SUM(click_cnt) FILTER (WHERE behavior_day >= CURRENT_DATE - INTERVAL '30 days'),
'gmv_90d', SUM(gmv) FILTER (WHERE behavior_day >= CURRENT_DATE - INTERVAL '90 days'),
'sessions_avg', AVG(sessions) FILTER (WHERE behavior_day >= CURRENT_DATE - INTERVAL '30 days')
) as profile_features
FROM MV_user_daily_stats
GROUP BY user_id;
-- 交叉特征物化视图:用户-品类偏好(协同过滤用)
CREATE MATERIALIZED VIEW MV_user_category_cross AS
SELECT
user_id,
category_id,
SUM(interaction_score) as pref_score,
COUNT(*) as interaction_cnt
FROM (
SELECT
user_id,
(features->>'category_id')::INT as category_id,
CASE
WHEN action_type = 'purchase' THEN 10
WHEN action_type = 'click' THEN 1
ELSE 0.5
END as interaction_score
FROM algo_samples
) sub
GROUP BY user_id, category_id;
-- 性能:从即席查询30秒降至物化后5毫秒依赖管理:使用
pg_memento追踪物化视图的源表变更,自动触发级联刷新。
# 物化视图依赖管理与自动刷新
class MaterializedViewManager:
def __init__(self):
self.view_dependencies = {
"MV_user_profile_wide": ["MV_user_daily_stats"],
"MV_user_category_cross": ["algo_samples"],
"MV_item_daily_stats": ["algo_samples"]
}
def incremental_refresh(self, view_name: str, date_partition: str):
"""
增量刷新物化视图,并处理级联依赖
"""
depends_on = self.view_dependencies.get(view_name, [])
# 1. 自底向上刷新依赖
for dep in depends_on:
self.incremental_refresh(dep, date_partition)
# 2. 构建增量刷新SQL
# 对于基于时间的物化视图,仅刷新指定分区
refresh_sql = f"""
REFRESH MATERIALIZED VIEW CONCURRENTLY {view_name}
WHERE behavior_day = DATE '{date_partition}'
"""
# 3. 执行并监控
with psycopg2.connect(DATABASE_URL) as conn:
with conn.cursor() as cur:
start_time = time.time()
cur.execute(refresh_sql)
conn.commit()
duration = time.time() - start_time
# 4. 性能退化检测:若刷新时间超均值2σ则告警
if self.is_refresh_anomaly(view_name, duration):
send_alert(f"{view_name}刷新异常:{duration:.2f}s")
logger.info(f"{view_name}增量刷新完成,耗时{duration:.2f}s")成本收益:物化视图存储成本增加12%,但查询性能提升平均200倍,特征工程迭代周期从2天缩短至4小时。更重要的是,将CPU intensive的计算从在线查询转移到离线刷新,数据库负载峰值下降40%。
第三章:解码策略优化——Lookahead Decoding的并行验证
3.1 从理论到生产:Lookahead Decoding的T-1到T0
2025年,LLM推理延迟是用户体验的瓶颈。论文提出Jacobi迭代并行验证,理论加速3-5x,但工程化面临三大鸿沟:
- Draft模型质量:如何在不增加延迟的前提下生成高质量draft
- Verification开销:并行验证的GPU Kernel效率
- Acceptance率:早期接受策略导致的序列质量下降
我们团队选择投机解码(Speculative Decoding)与Lookahead融合的路线,构建了Multi-Branch Lookahead Engine。

代码核心1:Draft模型的KV Cache前缀复用,避免每轮迭代重复计算。
# Draft生成与KV Cache复用(PyTorch实现)
class MultiBranchLookaheadEngine:
def __init__(self, main_model, draft_model, lookahead_k: int = 32):
self.main_model = main_model # 70B主模型
self.draft_model = draft_model # 7B草稿模型
self.k = lookahead_k # 分支数
def generate_drafts(self, input_ids: torch.Tensor, past_key_values: Cache):
"""
生成k个draft序列,复用past_key_values
核心优化:不重复计算前缀的KV Cache
"""
batch_size, seq_len = input_ids.shape
# 1. 采样k个不同的draft策略
# 策略组合:temperature + top-p + repetition penalty
draft_configs = self.sample_draft_configs(self.k)
drafts = []
for config in draft_configs:
# 关键:复用主模型的past_key_values到草稿模型
# 通过线性映射层适配维度差异(70B -> 7B)
adapted_past_kv = self.adapt_kv_cache(
past_key_values,
target_layers=self.draft_model.config.num_hidden_layers
)
# 2. 并行draft生成(使用vmap)
draft_ids = self.vmap_generate(
self.draft_model,
input_ids,
adapted_past_kv,
temperature=config["temp"],
top_p=config["top_p"],
max_new_tokens=16 # 短期draft
)
drafts.append(draft_ids)
# 3. 返回k*(batch, seq+16)的draft矩阵
return torch.stack(drafts, dim=1) # shape: (batch, k, seq+16)
def adapt_kv_cache(self, source_kv, target_layers):
"""
KV Cache适配:70B模型的80层映射到7B模型的32层
使用轻量级线性投影层,训练时冻结主模型
"""
# source_kv: (batch, 80, 2, num_heads, seq, head_dim)
# target_kv: (batch, 32, 2, num_heads, seq, head_dim)
# 策略:均匀采样 + 线性插值
step = source_kv.shape[1] // target_layers
sampled_indices = torch.arange(0, source_kv.shape[1], step)[:target_layers]
sampled_kv = source_kv[:, sampled_indices] # 采样
# 投影适配(可训练参数,但训练时只更新投影层)
projected_kv = self.kv_projection(sampled_kv)
return projected_kv代码核心2:并行Verifier的CUDA Graph固化,消除Python调度开销。
# 并行验证的CUDA Kernel融合(Triton编写)
@triton.jit
def parallel_verification_kernel(
logits_ptr, # 主模型输出logits
draft_ids_ptr, # k个draft序列
mask_ptr, # attention mask
acceptance_ptr, # 接受结果
k: tl.constexpr, # 分支数
vocab_size: tl.constexpr,
seq_len: tl.constexpr,
):
"""
Triton Kernel:并行验证k个draft序列
核心优化:将k次前向融合为一次batch计算
"""
pid = tl.program_id(axis=0)
# 每个program处理一个token位置的k个draft
token_idx = pid // k
draft_idx = pid % k
# 加载主模型在token_idx位置的logits
logits_offset = token_idx * vocab_size
logits = tl.load(logits_ptr + logits_offset + tl.arange(0, vocab_size))
# 加载对应draft token id
draft_id = tl.load(draft_ids_ptr + draft_idx * seq_len + token_idx)
# 计算接受概率:min(1, p_main(draft) / p_draft(draft))
p_main = tl.exp(logits[draft_id])
p_draft = tl.load(draft_prob_ptr + draft_idx * seq_len + token_idx)
accept_prob = tl.minimum(p_main / p_draft, 1.0)
# 采样决定
random = tl.rand(seed, pid)
is_accept = random < accept_prob
tl.store(acceptance_ptr + draft_idx * seq_len + token_idx, is_accept)
# Python层调用:固化为CUDA Graph
def compile_verification_graph(self, draft_shape):
"""
将验证逻辑编译为CUDA Graph,避免每次重编译
"""
# 预热运行
for _ in range(3):
logits = torch.randn(*draft_shape, self.vocab_size, device="cuda")
draft_ids = torch.randint(0, self.vocab_size, draft_shape, device="cuda")
# 捕获计算图
g = torch.cuda.CUDAGraph()
s = torch.cuda.Stream()
s.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(s):
for _ in range(3):
self.verification_pass(logits, draft_ids) # 实际验证函数
torch.cuda.current_stream().wait_stream(s)
# 开始捕获
g.capture_begin()
acceptance = self.verification_pass(logits, draft_ids)
g.capture_end()
self.verification_graph = g
self.static_input_logits = logits
self.static_input_drafts = draft_ids
self.static_output_acceptance = acceptance
def run_verification(self, logits, draft_ids):
# 直接 replay Graph,零Python开销
self.static_input_logits.copy_(logits)
self.static_input_drafts.copy_(draft_ids)
self.verification_graph.replay()
return self.static_output_acceptance3.2 工程化挑战:Tokenization对齐与长序列退化
生产环境最大的坑是:主模型和草稿模型的分词器不一致。70B用BBPE,7B用SentencePiece,导致draft token id无法直接验证。我们被迫引入了动态词汇表映射表,并在运行时实时转换。
# Tokenization对齐层(运行时开销<2ms)
class TokenizationAligner:
def __init__(self, main_tokenizer, draft_tokenizer):
self.main_tokenizer = main_tokenizer
self.draft_tokenizer = draft_tokenizer
# 预计算映射表(90%的token可直接映射)
self.draft_to_main = self.build_token_mapping()
def build_token_mapping(self):
"""
构建草稿token到主token的映射
策略:优先精确匹配,其次子词分解,最后退回到OOV
"""
mapping = {}
for draft_id in range(self.draft_tokenizer.vocab_size):
draft_token = self.draft_tokenizer.decode([draft_id])
try:
main_ids = self.main_tokenizer.encode(draft_token, add_special_tokens=False)
if len(main_ids) == 1:
mapping[draft_id] = main_ids[0] # 1对1映射
else:
mapping[draft_id] = -1 # 标记为多token,需特殊处理
except:
mapping[draft_id] = self.main_tokenizer.unk_token_id
return mapping
def align_draft_sequence(self, draft_ids: torch.Tensor):
"""
将draft模型的token序列转换为主模型token空间
"""
# 90%情况:直接查表映射(向量化解码)
aligned = torch.tensor([
self.draft_to_main.get(int(did), self.main_tokenizer.unk_token_id)
for did in draft_ids.flatten()
]).reshape(draft_ids.shape)
# 10%情况:子词分解,需动态扩展序列长度
# 触发回退到自回归生成,牺牲加速比保质量
if -1 in aligned:
logger.warning("检测到子词分解token,回退到自回归模式")
return None # 信号:无法对齐
return aligned长序列退化问题:Jacobi迭代在序列长度>512时,接受率骤降。我们引入了动态窗口策略:根据当前接受率自动调整lookahead长度,形成负反馈控制。
# 动态lookahead长度控制器
class AdaptiveLookaheadController:
def __init__(self, init_k=32, min_k=4, max_k=64):
self.k = init_k
self.acceptance_history = deque(maxlen=100) # 滑动窗口
def update_acceptance_rate(self, accepted_tokens: int, total_tokens: int):
rate = accepted_tokens / total_tokens
self.acceptance_history.append(rate)
# 滑动平均接受率
moving_avg = np.mean(self.acceptance_history)
# 控制策略:PI控制器
# 目标接受率0.6,低于则减k,高于则增k
error = 0.6 - moving_avg
# 比例-积分控制
self.k += int(self.kp * error + self.ki * np.sum(self.acceptance_history))
self.k = np.clip(self.k, self.min_k, self.max_k)
logger.info(f"Adaptive lookahead: k={self.k}, acceptance={moving_avg:.2f}")
def get_lookahead_config(self):
"""返回当前k值和draft策略"""
if self.k < 10:
# 小k值:用贪心策略,温度低
return {"k": self.k, "temp": 0.1, "strategy": "greedy"}
elif self.k > 50:
# 大k值:用多样性采样,温度高
return {"k": self.k, "temp": 0.8, "strategy": "diverse"}
else:
return {"k": self.k, "temp": 0.5, "strategy": "balanced"}生产部署效果:在A100集群上,QPS从原生vLLM的85提升至312,平均延迟从320ms降至95ms,首Token时间(TTFT)降低58%。但代价是显存占用增加40%(KV Cache的k倍复制),这是2026年需要攻克的硬件效率瓶颈。
2026年展望:从技术孤岛到生态连接
行业动态:三大撕裂与融合
撕裂1:算法与工程的"鄙视链"加剧。大模型时代,"调参炼丹师"与"底层系统工程师"的鸿沟在拉大。顶尖实验室疯狂发paper,但工程化能力薄弱;一线大厂系统牛逼,却困在业务里做重复劳动。2026年,具备端到端能力的"灰度人才"将成稀缺品——既能读通Attention is All You Need的数学,也能用Triton写Kernel。
撕裂2:开源与闭源的"效率悖论"。Llama-3、Mistral等开源模型追赶迅猛,但配套工具链(如vLLM、TensorRT-LLM)在生产级鲁棒性上仍落后闭源API。2026年将出现 "开源模型+闭源系统"的混合生态 ,类似于Linux内核配商业发行版。
撕裂3:数据隐私与效果精进的"零和博弈"。因果推断依赖全量用户数据,但GDPR 3.0和中国个保法的"数据最小化"原则让A/B测试平台合法性存疑。2026年,联邦学习+差分隐私+因果推断的三位一体架构将成刚需。
技术新想法:从单点优化到系统涌现
1. 因果推断的"实时化":当前因果效应计算是离线的,延迟24小时。2026年目标是将Do-Calculus编译成Streaming SQL,在Flink/Paimon上实现毫秒级因果效应计算。技术上,将后门调整公式转化为增量视图维护(Incremental View Maintenance),利用Differential Dataflow实现。
2. PostgreSQL的"向量化":亿级样本管理的下一步是PG Vectorized Extension。借鉴DuckDB的向量执行引擎,将特征工程中的聚合、过滤算子用SIMD重写。已验证,SUM和FILTER的向量化版本在AVX-512上提速8-12x。
3. Lookahead的"硬件化":当前CUDA Graph仍有调度开销。
职业瓶颈与突破:从"执行者"到"定义者"
2025年最大的瓶颈:技术话语权。作为基础架构团队,我们做了大量"看不见"的优化,但业务方只关心GMV增长,对"因果推断平台准确率提升5%"无感。解决方案是指标翻译:将技术指标转化为业务语言。例如,"A/B测试假阴性率从30%降至12%"等价于"每年少错过3个本可提升1%留存的策略",直接换算成机会成本。
2025年最大的突破: "灰度影响力" 。我不再满足于接需求,而是主动发起技术脉络。例如,从"优化PostgreSQL查询"上升到"构建算法数据基础设施标准",撰写RFC并推动CTO立项。这种从 "被动接单"到"主动定义问题域" 的转变,让我的工作从"cost center"变为"value center"。
2026年的成长目标:成为"架构师中的架构师"。不再局限于单个系统,而是设计技术演进的路线图。当前正在推动"因果中台"战略,将离散在各个业务的因果推断能力(营销、增长、推荐)统一为平台,目标是让产品经理在UI上拖拽变量,就能自动生成Do-Calculus查询。这需要我跳出代码,理解组织、 politics、资源分配——这是比写Kernel更难的技术。
2025结语:在算法与工程的缝隙中寻找光
2025年是"缝隙年"。算法的殿堂愈发高耸,工程的土地愈发坚实,但两者之间的工程化桥梁却狭窄而脆弱。我的工作,就是在这缝隙中架桥——让因果推断从paper的公式变成PM能用的按钮,让Lookahead从arxiv的概念变成用户感知的速度。
2026年,希望这座桥能更宽、更稳,甚至能长出花和树。也许到那时,"算法工程师"和"系统工程师"的title不再重要,重要的是我们是否解决了真实世界的决策抖动与体验卡顿。那才是技术人的终极成长。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号