重剑江湖:历时 N 月的单体涅槃武林录
原创
重剑江湖:历时 N 月的单体涅槃武林录
原创
黑暗浪子
发布于 2025-12-08 18:50:52
发布于 2025-12-08 18:50:52
感谢腾讯老师邀约写一篇架构师最佳实践案例分享。正好本人对这领域也有一些感兴趣的点。作为一个资深武侠小说迷为了娱乐化,周末匆匆草就一篇武侠风的架构实践笔记。博君一笑尔~
第一回:破局突围
1.1 旧系统的“七年之痒”
2017 年初夏,我作为一名初涉金融支付架构的“少侠”被派来接手这套被称为“太阳系”的 Java 后端系统。
这套系统按太阳系命名:origin 寓意缘起,负责所有基础框架和工具;sun 是中央的业务底座,照亮所有模块;mercury、venus、europa
承担通用组件和技术工具;earth 是主 Web 网关与前端;mars
负责对接第三方支付;saturn、jupiter、neptune、pluto、hydra、ganymede 等分舵各自承载不同业务域;moon 与
watergate 处理大数据和定时任务;watchman、owlman、watchman-message 构成监控与智能分析;callisto
提供动态编译能力。听起来庞大而壮观,但在我接手时,它更像是一座层层包浆的武林古堡。
模块分层架构如下(共 23 个 Maven 模块):
- origin: 基础框架层,所有基础框架类,不涉及具体业务代码(象征文明起源)
- sun: 业务代码基础层,所有业务组件的底层类(象征太阳,照耀所有业务)
- mercury/venus: 通用业务组件层,具有业务含义但有通用性的组件
- phobos: 快速处理器组件,高性能业务处理
- firefly: 轻量级业务组件
- watchman: 监控和守护服务模块
- deimos: 数据处理和存储服务
- callisto: 动态源码编译引擎,支持业务规则热更新
- europa: 欧洲支付业务扩展模块
- earth: 主要 Web 应用模块,包含完整的前后端系统
- mars: 第三方支付接口集成模块,包含各种支付渠道的 SDK
- watergate: 数据流控制和处理模块
- watchman-message: 消息监控服务模块
- owlman: 智能分析处理模块
- jupiter/saturn/uranus/neptune/pluto/ganymede/hydra: 多个业务服务模块,覆盖信托、清结算、营销等不同域
- moon: 定时任务和数据分析模块,使用 Spark 进行大数据处理
而当时的代码是典型的老式 Spring + Hibernate 搭法:23 个 Maven 模块、3,966 个 Java 文件,sun 模块一个人就吞下
1,544 份脚本,earth 前端后端合体也堆了 436 篇经书。最熟悉这套体系的初代研发几乎走得干干净净,连原来的架构师也失联,只留一地
XML Bean 定义和硬编码的配置。
系统上线多年只服务一家基金公司,所有流程因为“只为一个客户”而深度耦合,导致任何需求都得在
origin、sun、saturn、hydra、mars 等分舵之间硬扯;我当时的直观感受就是:这头“踩在淤泥里的大象”稍微抖动,就会让身上的铠甲跟着嘎吱乱响。
更糟糕的是性能:核心支付接口的 p95(95% 请求的延迟阈值)常年在 3.8 秒左右,p99(99% 请求的延迟阈值)动辄突破
11 秒;批量对账一跑就是 6.5 小时,凌晨一点 CPU 还稳在 90% 以上;saturn 的订单服务 TPS(Transactions Per
Second,每秒交易数)仅 180,只有竞品券商系统的三分之一。业务方抱怨“用户下单像排长队”,而我只能透过监控看到数据库连接池在半夜被打爆。
我把这副江湖经脉重新绘制在作战手札里,方便后来者看清这个庞然巨兽的骨骼:
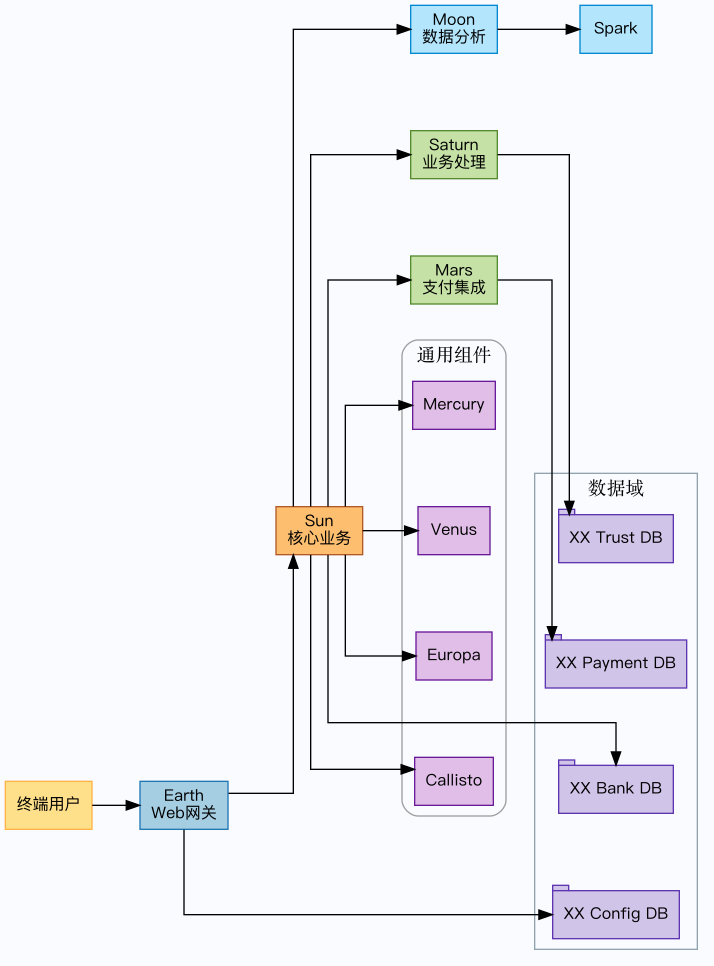
图1:太阳系业务星图
这幅“星图”清楚地表示:origin、sun、mercury 更像内功心法,saturn、hydra、pluto、mars
则是各个分舵,所有经脉紧紧缠绕在一起,任何一次改动都像在经络上硬生生开刀。
1.2 量化痛点,赢得支持
为了让高层真正意识到风险,我把每一处伤筋写进账册:
- 需求交付:2017Q1 的 CI 报表显示,轻量需求平均交付时间从 0.8 天涨到 5.9 天,开发时间有 57% 用来解读遗留代码。
- 故障稽核:高峰月里每周两起 P1(Priority 1,最高等级)告警,人均 17 人天泡在线上救火,mars 支付适配器因 NPE(NullPointerException,空指针异常)触发的重启至少 6 次。
- 性能劣势:saturn 核心订单接口吞吐量只有 180 TPS,大约是竞品的三分之一;moon 的大数据任务夜里经常冲爆 watergate 的队列,导致第二天早会必然“检讨”。
最刺耳的是,领导希望把这套系统扩展为能够对接全国券商和投资机构的通用产品,而眼前的代码却只认那家基金公司的业务流程。如果不彻底脱胎换骨,任何面向多客户的计划都会胎死腹中。
1.3 明确战略目标
我在议事堂前立下三面战旗:
- 产品化与多客户适配:把只服务单客的流程改造为模块化、可插拔的产品形态,earth 网关要能同时服务券商、基金、私募多入口,mars 支付集成必须像换兵器一样轻松。
- 交付与稳定翻倍:迭代节奏要从“月更”走向“周更”,核心交易链(sun + saturn + hydra)的可用性提升到 99.99%,批量窗口压缩到 2 小时以内。
- 数据与安全零失守:满足金融安全合规的同时,确保任何迁移都不丢一单数据,核心链路的 RT 只许持平或者更快。
换句话说,我要把这座老宅铸成面向全市场的通用兵器。安全是刀脊,业务零感知是刀锋,后面所有章节都是围绕这三面战旗展开。
第二回:谋定后动
2.1 核心原则
我把门规写在议事堂大门上:
- 渐进而非激进——先拆外围、再触核心,每次改动都要可回滚;
- 可控而非碰运气——每个步骤要有监控指标、回退预案、双人复核;
- 业务无感而非豪赌——无论内部换了多少肌腱,前台客户和渠道都不该察觉;
- 安全第一而非事后补救——任何设计讨论都必须回答“数据如何保护”“访问如何审计”。
这四条原则贯穿后续全部动作,任何提案只要违背其中一条,就会被我“拍”回去重写(哥就是这么跋扈)。
2.2 架构决策:微内核 + 插件化 & 绞杀者模式
我首先给未来的“太阳系”画了一幅新蓝图:把 sun
里那团千丝万缕的业务拆成“核心交易微内核”和一圈插件化域服务。微内核负责账务、清结算等最底层的事实记录;周围的插件则对应用户认证中心、订单编排、渠道支付、风控哨兵、营销增值等职能,每个插件独立部署、通过事件或
API(Application Programming Interface,应用编程接口)与核心协作。模块与数据分层大致如下:
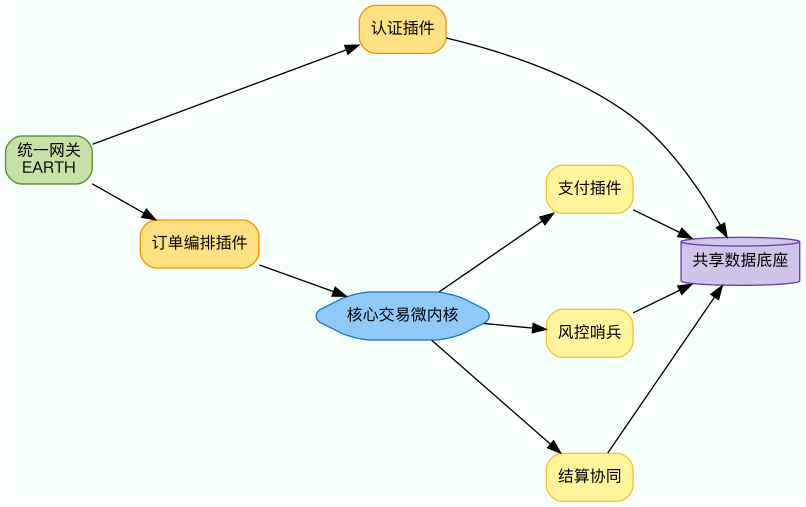
图2:微内核 + 插件化目标架构
然后我采取了那时流行的微服务中的绞杀者模式来拔刺。
之所以选择绞杀者模式,是因为它像修一条新驿道:先在旧官道旁并行铺好新路、让组件先在暗处咬合,再一点点把流量与数据迁走。这样做有三大好处:
- 随时可退:无论是认证服务还是订单插件,只要新路出现异状,可以立即把流量切回原单体,不必大面积回滚;
- 天然隔离:每次只拆一个“堂口”,风险封装在本模块内,测试也更聚焦;
- 便于产品化:插件式结构让我们未来接入任意券商/投资机构时,都能像换兵器一样插拔相应插件,而无需碰微内核。
为了让绞杀者模式真正落地,我给每个拆分阶段制定“迁移脚本 + 流量切换 +
监控回传”三件套:数据迁移严格双写、流量按百分比灰度、指标实时上报 watchman 与 Grafana,一旦指标异常立即执行回退脚本。
2.3 制定安全红线
蓝图只有在严格的安全边界内才算成立,因此我立下如下红线:
- 数据不可丢:任何迁移都必须双写+对账,出现一条差异就终止切流;
- RT 不得下降:核心链路(交易、支付、结算)的 p95、p99 延迟不能比旧系统更差,必要时先扩容再拆分;
- 合规常驻:加密、审计、访问控制必须在新旧系统同时生效,禁止因重构而“暂时放松”;
- 回滚脚本必备:上线剧本里必须包含 5 分钟内可执行的回退步骤,并经过演练;
- 监控与告警到位:拆出的每个插件都要纳入 watchman、owlman 的指标体系,令牌、权限、接口调用全程追踪。
这五条戒律写进每个项目计划,一旦有人试图偷工减料,我就用它们逐条质询。毕竟我们的使命是“安全第一、业务零感知”,所有策略都必须在这两个维度上交出答卷。
第三回:见招拆招
限于篇幅,我挑两场最具代表性的硬仗来说:一是拆出“用户认证与权限”分舵(既能练手又能打牢安全底色),二是重塑“核心订单流程”(系统的命根子)。其他模块如流水、计费、报表、风控也做了类似的功课,这里就不一一展开。
3.1 案例一:首战“用户认证与权限”分舵
3.1.1 为什么先拆它
用户认证天然边界清晰、依赖少、又是安全基石,是最适合用来立威和验证微内核策略的模块。我们只要把登录、会话、权限判定从
sun 的泥潭里挖出来,就能为后续的所有插件建立统一入口。
3.1.2 数据双写 + 点穴校验
我们先在旧库旁架设新库,登录请求先同步写旧库,再由后台作业异步写入新库;Watchman
会对比每一条用户记录,一旦发现数据不一致就立刻报警并中断写入。整体流程如下:
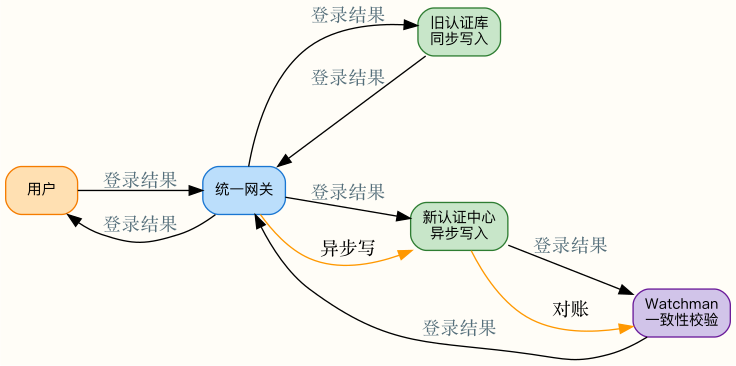
图3:认证双写与一致性校验流程
3.1.3 灰度行军与安全加固
- 灰度策略:网关按 30%-60%-10% 的比例逐步引导流量,新旧认证同时在线,任何异常都能立即把流量切回旧系统。
- 安全加固:新认证中心统一 PBKDF2(Password-Based Key Derivation Function 2,口令派生算法)与盐策略,会话改成集中式 token(短期令牌)管理,ACL(Access Control List,访问控制列表)从 sun 抽离出来集中管理,同时引入字段级加密、FIDO(Fast IDentity Online,硬件多因子)风格多因子抽检。
- 可观测性:watchman、owlman 监控成功率、延迟、异常类型,链路追踪把登录全过程串起来,方便比对新旧差异。
3.2 案例二:攻坚“核心订单流程”
3.2.1 为什么难
订单链路横跨 saturn、hydra、watergate、mars,里面塞满了数据库大事务、同步
RPC、共享表结构,一旦处理不好就会直接影响资金安全。这是最难、也是最能体现微内核价值的一仗。
3.2.2 Saga(长事务编排)+ 补偿机制
我们先把原来“一口气”提交的数据库事务拆成 Saga 步骤,并为每个步骤配置补偿动作、持久化流水:
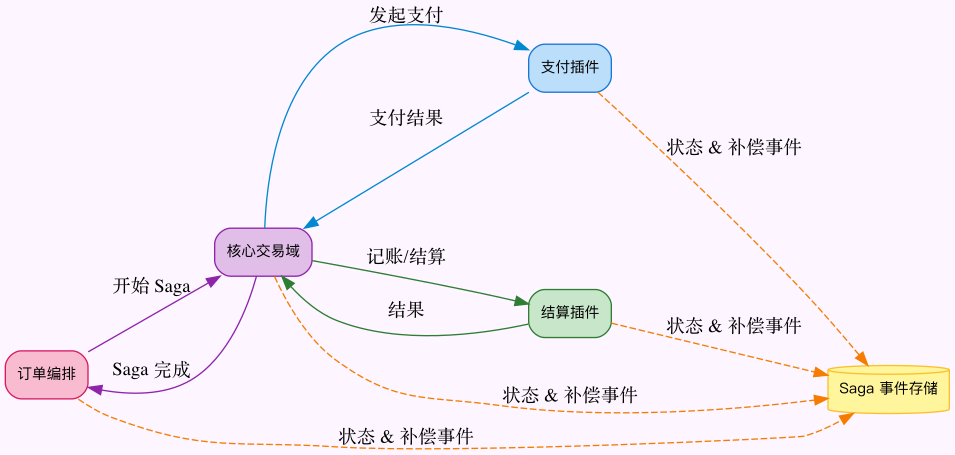
图4:订单 Saga 长事务编排
每个步骤的状态都写入事件存储,失败时通过补偿消息回滚过往操作,保证最终一致并可追溯。
3.2.3 依赖治理与敏感数据保护
- 熔断/限流/降级:在 hydra、saturn、watergate 之间布下熔断、限流、降级策略,防止一个插件的抖动牵连整条链路。
- 敏感数据加固:订单中的 PII(Personally Identifiable Information,可识别个人信息)数据统一走 KMS(Key Management Service,密钥管理服务)加密存储,传输层采用 mTLS(mutual TLS,双向传输层安全协议),日志只打印脱敏 Token;访问控制由统一权限服务负责,任何调用都必须带上链路 ID(Identifier,标识符)供审计追踪。
- 回滚与演练:为每一条业务路径编写回滚脚本并定期演练,确保在出现严重异常时可以在 5 分钟内切回旧流程。
这两个案例只是整个重构旅程的缩影。通过它们,我们验证了微内核 + 插件架构的可行性,也把“安全第一、业务无感”的要求落实到了每一行流程之中。
第四回:一以贯之
上一章我讲的是“拆”,这一章我来讲“护”。如果没有稳定性与安全体系的护航,再漂亮的架构也撑不住金融业务的刀光剑影。
4.1 可观测性如明镜
我把监控、日志、链路追踪合成一面“照妖镜”,让任何请求轨迹都逃不过我们的视线。整体观测架构如下:
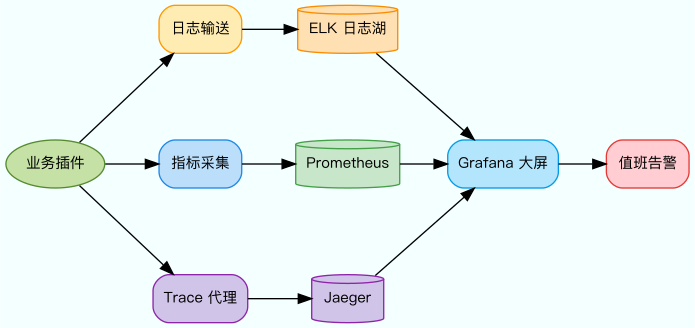
图5:可观测性与告警体系
- 统一埋点:所有插件统一使用 MDC(Mapped Diagnostic Context,映射诊断上下文)+ TraceID(链路唯一标识),把用户、订单、通道等关键字段放进日志与指标;
- 多维可视:Grafana 大屏展示资源、业务、体验三层指标,成功率、延迟、错误类型一目了然;
- 快速定位:当链路异常时,Jaeger 的 Trace 直接指出是哪个插件耗时异常,再结合日志上下文即可还原现场。
日志链路使用 ELK(Elasticsearch + Logstash + Kibana)组合沉淀原始事件,指标管道由 Prometheus
集群负责抓取,Trace 则落在 Jaeger 上统一查询,三者在 Grafana 中汇流成为作战大屏。
4.2 自动化安全门禁
我把 CI/CD(Continuous Integration/Continuous Delivery,持续集成与持续交付)水车变成一座“安全城门”:凡是想进制品库的构建,都要依次通过以下守卫:
- 静态扫描:代码提交后先跑 SAST(Static Application Security Testing,静态应用安全测试,包含硬编码秘密探测、依赖漏洞扫描、SQL 注入规则等);
- 依赖体检:BOM(Bill of Materials,依赖清单)自动对比 CVE(Common Vulnerabilities and Exposures,通用漏洞披露)数据库,发现高危版本直接阻塞 pipeline;
- 自动化安全测试:关键接口会跑一轮基于 Playwright(浏览器自动化框架)/REST(Representational State Transfer,表述性状态转移)的安全用例(鉴权绕过、越权、重放等);
- 制品签名:通过的镜像/包都要签名并记录版本指纹,后续部署只能引用受信制品;
- 环境基线检查:部署前自动校验配置是否符合安全基线(TLS(Transport Layer Security,传输层安全协议)版本、密钥长度、日志级别等)。
如此一来,安全真正“左移”:问题在 pipeline 被挡下,线上环境只接收已经过关的工件。
4.3 变更管理与应急预案
每一次拆分上线都当“重大手术”执行,我们制定了完整的变更流程:

图6:变更与回滚闭环
- 方案评审:所有变更必须写清风险、指标、回滚策略,经过架构、安全、业务三方确认;
- 灰度与监控:上线必走灰度,watchman 与 Prometheus 的指标一旦越界立刻执行回滚;
- 复盘闭环:每次上线后 24 小时内完成复盘,记录成功经验与告警数据,补齐文档;
- 演练制度:回滚脚本按月演练,确保真正需要时不至于手忙脚乱。
这条“生命线”贯穿整个重构旅程,确保我们在拆解旧骨、缝合新肌的同时,仍然握得住金融系统的安全与稳定。
第五回:复盘回顾
5.1 量化战果
为了让掌门老板对成果一目了然,我把关键指标前后对比列在账册之中:
指标 | 改造前 | 改造后 | 变化 |
|---|---|---|---|
发布节奏 | 月均 2 次 | 周均 1.5 次 ≈月 6 次 | ↑3 倍 |
需求 Lead Time 需求前置时间 | 5.9 天 | 1.2 天 | ↓79% |
核心交易链可用性 | 99.3% | 99.99% | +0.69% |
P1 故障/月 | 8 起 | 0 起 | -100% |
MTTR Mean Time To Recovery,平均恢复时间 | 2 小时 | 18 分钟 | ↓85% |
数据安全风险项 | 25 条 | 8 条 | ↓68% |

图7:重构前后发布节奏对比
- 效率:模块化后,我们组建的“特种兵小队”(由多名经验丰富的开发少侠组成)能在一周内完成开发、测试、灰度与复盘;CI/CD 管线自动生成部署清单,平均一天可跑 4 次 pipeline(流水线)。
- 稳定:核心链路引入熔断与同城双活后,把可用性推到 99.99%,订单相关的重伤事故归零;批量窗口缩短至 1.8 小时。
- 安全:渗透测试报告显示高危漏洞清零,中危项减少到个位数;用户认证的异常登录检测命中率提升 210%。
5.2 无形财富
- 团队心法沉淀:把认证拆分、Saga 编排、灰度策略等经验写成 12 篇 playbook(作战手册),后来任何模块拆分都能套用模板。
- 跨域协同:业务、工程、运维建立“作战联合体”,例会不仅看功能,还看指标、风险、恢复计划。
- 文化升级:从“救火文化”转向“指标文化”,讨论任何需求都先带着 SLA(Service Level Agreement,服务等级协议)、SLO(Service Level Objective,服务等级目标)与安全红线;年轻侠客开始主动申请值班,说明他们对系统有信心。
- 市场信誉:多家券商在试用环境中插入自家插件,一次集成平均周期从 6 周缩短至 2 周,组织得以真正迈向产品化。
5.3 成功因子
我把真正的制胜要素总结成“四柄重剑”:
- 清晰蓝图:在动刀之前就把目标架构、拆分顺序、监控指标画成图纸,整个团队都按同一份地图行军;
- 数据驱动:每个里程碑都靠可量化指标说话——延迟、发布频次、故障率、转化率,没有指标就不允许结项;
- 安全执念:无论进度多紧,安全红线一条不让;所有迁移方案先过安全审查,再谈上线窗口;
- 跨界同盟:业务、运维、安全、开发组成联合战队,任何灰度或回滚都有对应的负责人、剧本与演练;这比单一团队作战可靠得多。

图8:重构成功的四柄重剑
5.4 给后来者的箴言
重构是一场漫长的炼骨术,我的感受是:

图9:重构炼骨循环
- 评估:先摸清债务、性能瓶颈、核心依赖,再轻举妄动;
- 拆分:每次只拆一个业务能力,能独立部署、测试、回滚;
- 护栏:把安全、CI/CD、监控当成“默认配置”,而不是锦上添花;
- 观测:指标与日志要能实时对比新旧系统,出现波动马上定位;
- 回滚:永远准备好回滚按钮,任何上线都要演练“如何回滚”。
让业务零感知、让安全先落地,这才是对金融系统最侠义的守护!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号