Deep Research Agent技术 --通义“狐獴家族”(一)
原创
Deep Research Agent技术 --通义“狐獴家族”(一)
原创
languageX
发布于 2025-11-17 11:43:06
发布于 2025-11-17 11:43:06
又快要年底了...今年不知道能写完几篇技术总结,本系列来整理下Tongyi DeepResearch。
什么是Tongyi DeepResearch?
通义技术报告里说了Tongyi Deepresearch---洞察更深层的信息,驱动更智能的决策。

descript
技术报告:
https://tongyi-agent.github.io/zh/blog/introducing-tongyi-deep-research/
git仓库:
https://github.com/Alibaba-NLP/DeepResearch
简单来说,Tongyi团队开源了一套Web Agent代码以及专门为DeepResearch定制的模型DeepResearch‑30B‑A3B,并且在技术报告中分享了一套WebAgent构建方法论。
模型训练方面,分享了从高质量数据合成,Agentic增量预训练(CPT),有监督微调(SFT)冷启动,到强化学习(RL)全流程的方法。

descript
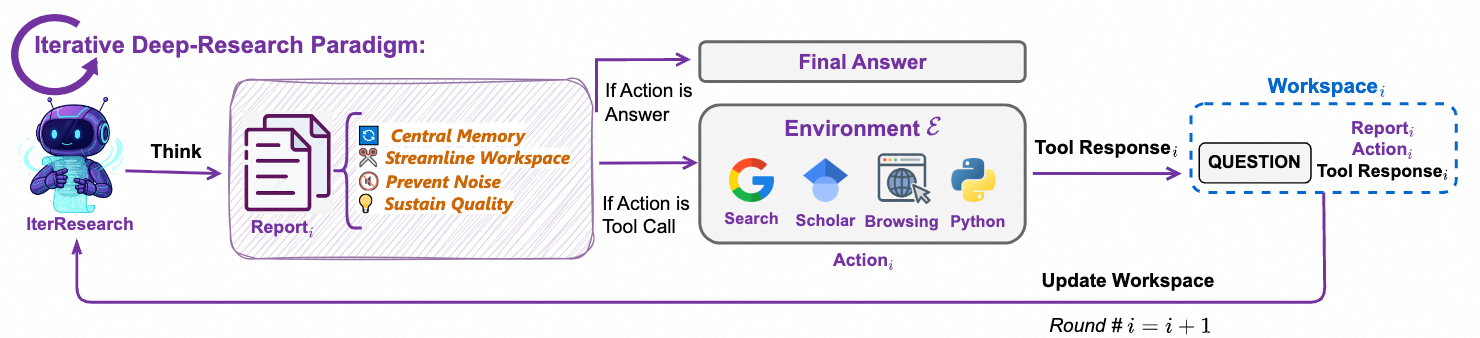
模型推理方面,分享两个模式:
ReAct 模式,严格遵循“思考‑行动‑观察”的循环,通过多次迭代来解决问题;
深度模式,处理极端复杂的多步推理研究任务。
descript
而这篇技术报告的产出是经过了一系列模型优化和工程版本迭代工作的,也就是下面的狐獴家谱(原型应该是狐獴吧?也找不到tongyi团队求证)。

descript
下面我们就来分析“家族进化史”,跟着Tongyi团队的研发路径详细探讨Deepresearch Agent。
由于家族太大,本文作为系列一,先介绍家族第一排,他们聚焦于“数据—轨迹合成—训练”的流程闭环。
如何构建适配深度研究任务的数据集、如何采样高质量行为轨迹、以及如何以 SFT/RL 等方式把能力沉淀进代理。
1. WebWalker
WebWalker: Benchmarking LLMs in Web Traversal (2025-01-14)
论文地址: https://arxiv.org/pdf/2501.07572
1.1 背景和动机
RAG对于开放领域知识已经有比较好的效果,但是这个技术没有办法直接移植到互联网检索。因为传统的互联网搜索引擎只提供浅层信息,没办法直接提供和用户问题最相关的网站子网页内容。这种方法在信息散布于互联网各个角落时非常有效,但对于那些深埋于特定网站内部的内容,却显得力不从心。也就是论文中提到的引擎擅长对查询进行“水平搜索”,但是无无法“深度搜索”。
所以我们需要一个工具来系统性地遍历网站子页面,挖掘更深层的内容。
1.2 论文方案
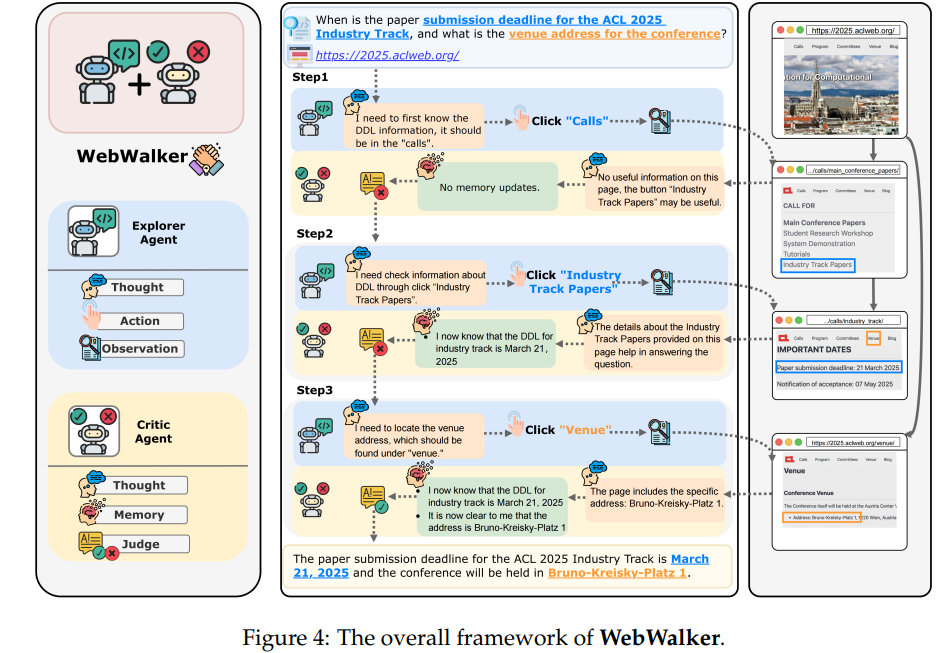
为解决需要深度探索的网页遍历问题,论文提出了的WebWalker,一个模仿人类网页导航行为的多Agent框架, 采用探索-评论(explore-critic)范式,专注于垂直探索,即深入挖掘网站内部的层级链接。
descript
WebWalker 框架由两个核心代理组成:
1. 探索Agent(Explorer Agent)
探索者负责在网页环境中进行实际的遍历。它的思考方式是基于经典的 ReAct 框架,非常像人类解决问题时的逻辑:“思考 -> 行动 -> 观察” (T, A, O), 为了专心评估模型找信息的能力,动作(A)被严格限制为点击,它会通过识别页面上的 HTML 按钮,然后点进去,像人查阅资料一样一层层探索子页面。观察(O)就是点击获取的当前页面的内容信息。
2. 评论Agent(Critic Agent)
评论者在探索者每执行一次动作后启动,承担记忆管理和决策回答的角色。
记忆维护: 初始化并增量式地积累相关信息(Memory M),有效解决了长上下文带来的干扰问题,让信息收集更聚焦。
决策与回答:使用原始问题 Q 和探索者当前的行为 (A,O ) 来评估:我们收集到的信息够不够完整地回答问题了?一旦它判定信息“管够”,它就会直接输出最终答案。
WebWalker 就是靠这种“垂直探索”的策略,通过分析和推理htm按钮数据,模拟人上网点击跳转,从而能够深入地抓取到网站里最相关和最可靠的深度信息。这为 RAG 系统提供了一个有前景的方向,让 LLM 不仅能“广”搜,还能“深”挖。
1.3 主要贡献
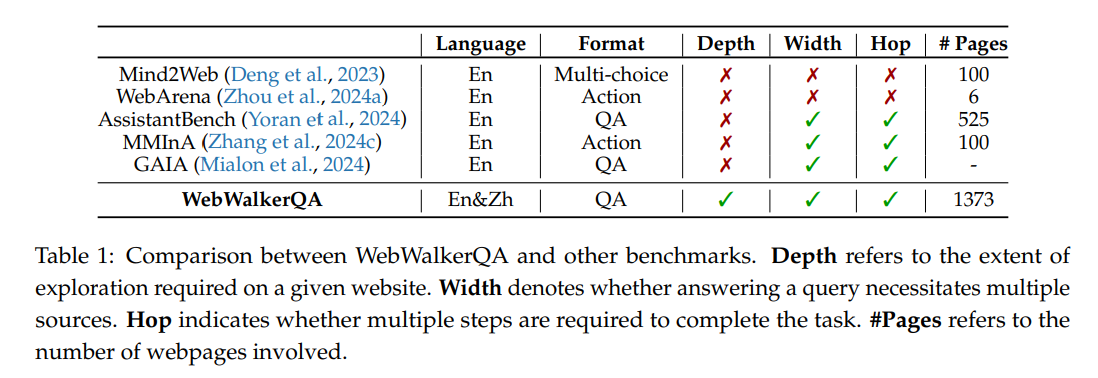
贡献一:贡献WebWalkerQA 基准
构建了 WebWalkerQA 基准,专门用于评估大型语言模型(LLMs)处理复杂的、多步网页交互的能力。
descript
• 数据规模与领域: 包含 680 个查询,覆盖会议、组织、教育、游戏这四个真实世界领域。涉及超过 1373 个网页。
• 评估难度: 侧重于基于文本的推理能力,强调信息源的深度,要求进行多层级交互。数据集包含单源 QA 和需要整合信息的多源 QA。
• 挑战性: 实验证明 WebWalkerQA 极具挑战性,即使是基于最强大的 LLM(如 GPT-4o)的 WebWalker,整体准确率也未超过 40%。
贡献二:推出 WebWalker 框架
WebWalker提出了一套探索-评论(explore-critic)范式,通过多Agent结构实现对复杂任务的记忆管理和深度探索能力。
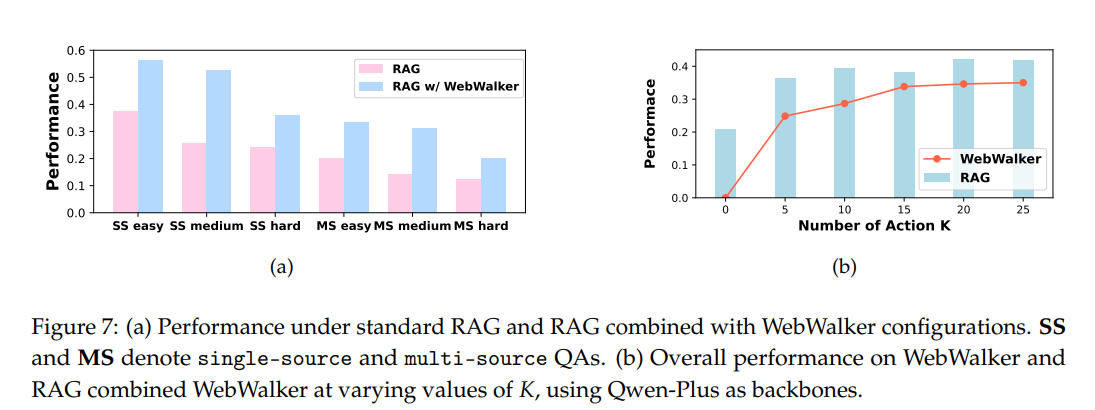
贡献三:实现 RAG 的“水平”与“垂直”强强联合
WebWalker 证明了将传统的 RAG 水平搜索(Horizontal Search)与 WebWalker 的垂直探索(Vertical Exploration)相结合,在Web应用场景中是有效的。
descript
WebWalker总结来说提出了WebWalkerQA测评集;强调了深度、垂直探索在基于网络的任务中的重要性;给RAG系统提供了更具可扩展性和更深度检索的方案。
2 WebDancer
WebDancer: Towards Autonomous Information Seeking Agency(2025-05-14)
论文地址: https://arxiv.org/pdf/2505.22648
2.1 背景和动机
WebWalker 作为 WebAgent 系列的开篇工作,提出了 WebWalkerQA 基准与 WebWalker 框架,为基于网页交互的智能体研究奠定了基础。但是在实际应用中,尤其是在处理需要多步网络检索和复杂多跳推理的任务时,其性能仍难以达到理想效果。
如何使用信息检索智能体的方案主要可分为两类,但各自存在明显局限:
提示工程(Prompt Engineering):通过精心设计的提示直接引导大型语言模型(LLMs)或大型推理模型(LRMs)执行复杂任务。然而,面对需要动态交互、状态记忆和多跳推理的真实场景,此类方法难以有效激发模型内在的推理能力,往往导致规划混乱或信息遗漏。
监督微调(SFT)或强化学习(RL)训练:通过 SFT 或 RL 将网页浏览与搜索能力内化到智能体中。尽管这类方法在一定程度上提升了智能体的自主性,但现有训练与评估数据集普遍较为简单,未能充分反映真实 Web 环境中的复杂性与不确定性。更重要的是,当前的 SFT/RL 范式尚未有效建模信息检索过程中的长期依赖、探索-利用权衡等关键行为,限制了智能体潜力的发挥。
WebDancer 提出从头开始构建一个类似于 Deep Research 的自主多轮信息检索智能体方案,来解决现实web检索中复杂的需要深入信息检索和多步骤的推理的问题。
2.2 论文方案
WebDancer 采用了一个包含四个关键阶段的内聚范式来构建端到端智能体:
2.2.1 阶段 I & II:数据驱动的轨迹生成
构建高质量的问答数据是构建 WebAgent的关键。由于现有挑战性数据集(如 GAIA 和 WebWalkerQA)规模过小,不足以进行有效训练,WebDancer提出了一套自动化合成高质量数据集思路。
QA 对构建(数据合成)
WebDancer 提出了两种数据合成方法以实现更长期的网络探索轨迹:
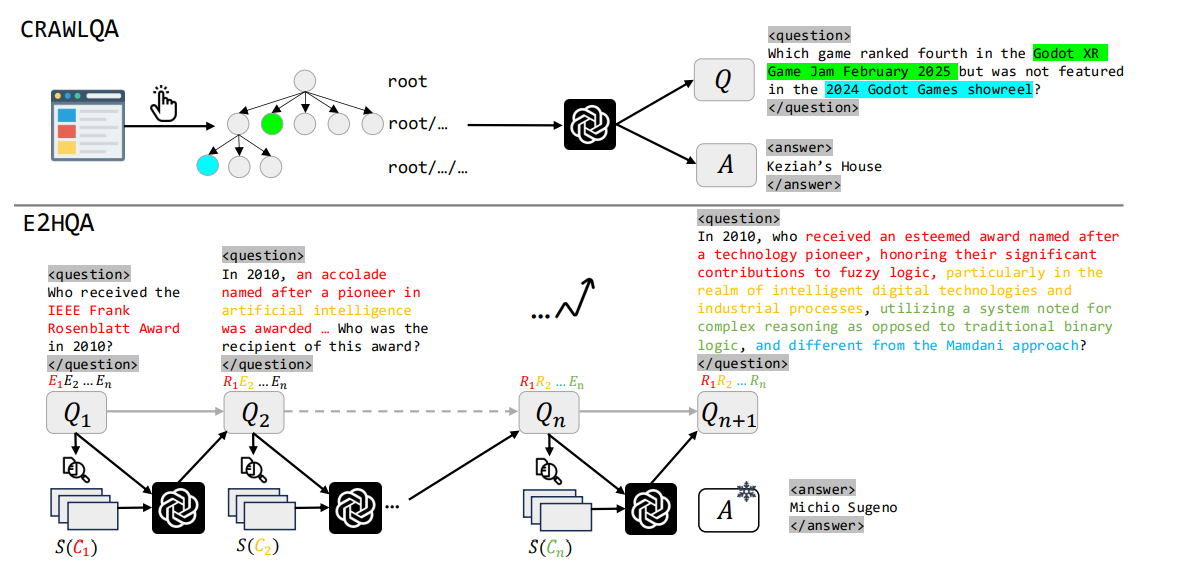
• CRAWLQA (爬取问答对):通过爬取来自权威和知识性网站的根URL。模拟人类浏览行为,递归地点击子页面,并使用 GPT-4o 根据收集的内容合成问答对。
• E2HQA (从易到难问答对):采用反向构建策略,将简单的问答对逐步转化为复杂的多步骤问题。通过迭代地选择实体、搜索相关信息、并使用 LLM重构问题,确保问题的答案不变,同时增加了解决问题所需的步骤数,以此激励智能体能力从弱到强演进。
构建逻辑如下图所示:
descript
智能体轨迹拒绝采样
该阶段目标是生成高质量的ReAct 轨迹数据。
• 动作空间:智能体的行动被限制为两个最关键的信息检索工具:search和 click
• 短/长思维链 (CoT) 构造:通过拒绝采样生成轨迹,使用了两种提示策略:
◦ Short-CoT:直接使用强大的LLM模型 收集 ReAct 轨迹。
◦ Long-CoT:使用大型推理模型 (LRM),在每一步序列化地提供历史行动和观察结果,让其自主决定下一步行动,并将 LRM 的中间推理过程记录为Thought。
• 轨迹过滤:采用三阶段漏斗式过滤框架以确保数据质量和连贯性:
◦ 有效性控制 (Validity Control):过滤掉不符合 ReAct 格式的响应。
◦ 正确性验证 (Correctness Verification):仅保留产生正确结果的轨迹,使用 GPT-4o 进行准确判断。
◦ 质量评估 (Quality Assessment):通过规则和提示来过滤掉存在幻觉、严重重复或不满足信息非冗余等问题的轨迹。
通过以上两个阶段可以看出需要大量调用网络检索API,网页内容visit, 闭源大模型,在造数据阶段的成本是非常高的。
2.2.2 阶段 III & IV:两阶段训练策略
WebDancer 采用了结合 SFT 和 On-policy RL 的两阶段方法进行模型训练。
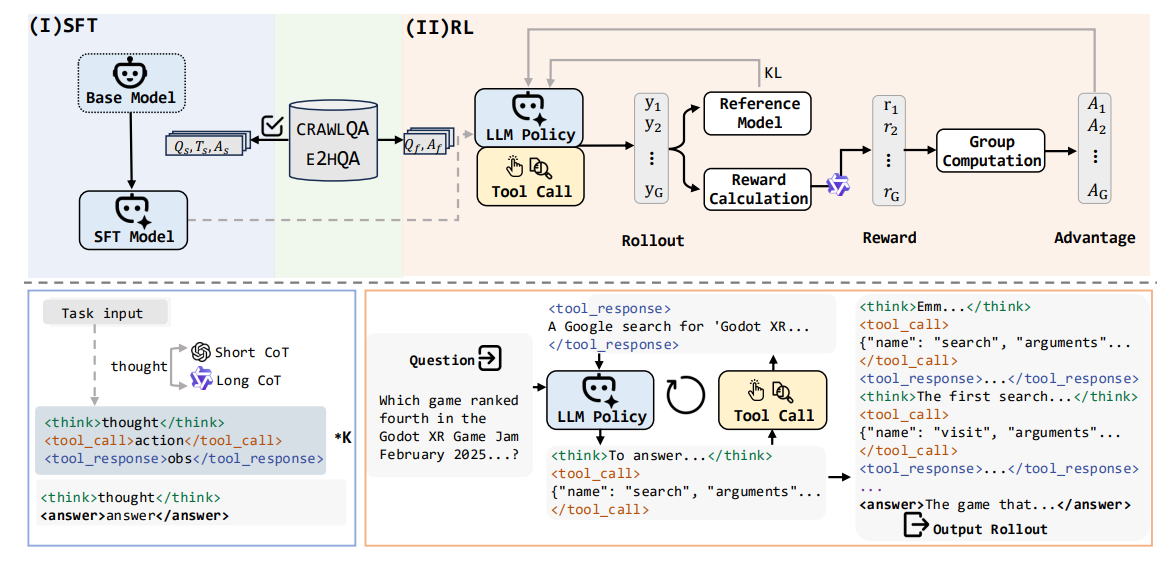
descript
监督微调 (SFT) —— 冷启动
目标:利用 ReAct 格式的高质量轨迹训练策略模型 πθ 。数据格式如上图所示<think>..</think><tool_call>...</tool_call><tool_response>...<tool_response>...<think>...</think><answer></answer>
冷启动增强了模型耦合多步推理和行动的能力,教会了模型交替推理与行动的行为范式和输出格式。
损失函数:在计算损失时,会屏蔽掉来自观测 (Observation) 的贡献,仅计算智能体自主决策步骤的损失。
强化学习 (RL) —— 泛化增强
通过基于结果的奖励,将智能体的能力内化到推理模型中,增强其多轮、多工具使用的能力,其中使用的是DAPO算法具体细节就不做过多介绍了。
奖励设计:奖励系统主要由 scoreformat (格式分数)和 scoreanswer (答案分数)组成。通过 LLM-as-Judge 模型(基于 Qwen-72B-Instruct)判断回答的正确性。
2.3 主要贡献
WebDancer 的主要贡献论文里也有总结:
WebDancer将端到端 Web 智能体构建流程抽象为四个关键阶段:
第一阶段:基于真实网络环境,构建多样化且具有挑战性的深度信息检索问答对;
第二阶段:利用大语言模型(LLMs)和大推理模型(LRMs)从问答对中采样高质量的交互轨迹,以引导智能体的学习过程;
第三阶段:通过微调,使模型适应面向智能体任务与环境的格式化指令遵循能力;
第四阶段:在真实网络环境中应用强化学习(RL),优化智能体的决策能力与泛化性能
WebDancer提出了一套系统化、端到端的长程信息检索型 Web 智能体构建框架。在 GAIA 和 WebWalkerQA 两个 Web 信息检索基准上的大量实验验证了该框架及所提出的 WebDancer 的有效性。
3 WebSailor
WebSailor: Navigating Super-human Reasoning for Web Agent(2025-07-04)
论文地址:https://arxiv.org/pdf/2507.02592
3.1 背景和动机
WebSailor已经可以认为是WebDancer的优化,在 WebDancer 的基础上进一步突破了开源WebAgent在高不确定性、复杂推理任务中的能力瓶颈。通过构建的数据可以看出WebDancer是又局限性的。
WebDancer构建QA的过程过程是是结构比较清晰,以及比较明确的多跳的路径,比如先查A再查B,再得到A和B的区别;但是对于问题模糊,线索分散,没有明确解决路径的认为就表现不佳。
WebDancer在构建推理链的时候是通过LLM和LRM进行采集的,容易产生冗余和啰嗦的思维过程,这会直接影响Agent的推理性能以及可扩展性。
WebDancer在强化学习训练效率慢,奖励稀疏,尤其在复杂任务中几乎无法获得有效反馈,对于困难样本没有更好的利用。
WebSailor针对这些问题提出了 SailorFog-QA 数据合成方法,专门构造大量起点不明、信息模糊、需跨源推理的复杂问题,训练模型在高度不确定环境下进行系统性探索与推理;最终效果超过所有开源WebAgent能力,在一些测评集上效果也逼近先进闭源。
3.2 论文方案
3.2.1 数据方面
SailorFog-QA:可扩展的复杂推理训练数据合成,为了诱导出复杂推理模式,WebSailor 生成了具有高且难以降低的内在不确定性的训练数据。
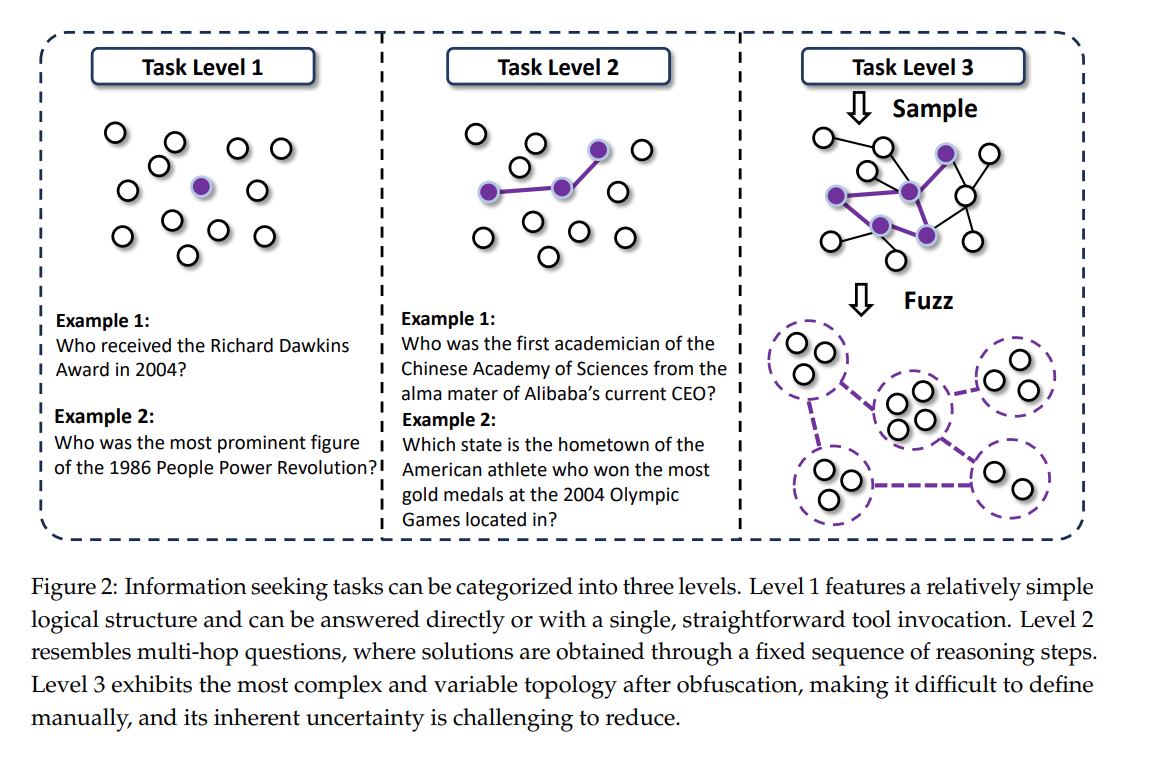
descript
论文中将Web检索的任务分为三个等级:
Level1: 相对简单的问题,可以直接回答或者通过一次简单的工具调用回答。
Level2: 类似多跳问题,虽然不确定高,但是有清晰的解决路径。
Level3: 不确定性极高,而且没有明确的推理路径。在混淆后表现出最复杂和可变的拓扑结构。
为了解决Level3的信息迷雾问题,论文提供了一套数据数据生成的方案:
step1: 构造复杂的知识图谱: 采用随机游走的方式,从真实世界网站中构建出具有复杂、非线性结构的知识图谱。这种方法促进了实体之间密集互联的图结构,避免了 Level 2 任务中的简单线性链。
step2:高不确定性问题生成: 通过采样具有多样拓扑的子图来生成问题和答案。
step3:信息混淆(Obfuscation): 使用精心设计的信息混淆技术进一步增强任务难度。对问题进行刻意的模糊化处理。例如,将精确日期转换为模糊时期,或部分屏蔽名称。
总结来说,通过 随机游走构图 → 子图采样 → 刻意模糊,生成需要深度检索、对比、综合的复杂问题,而不是普通查找题。
训练数据的调用深度呈长尾分布,远比其他数据集难,能更好地模拟实际 Web Agent 的任务场景。
示例:

descript
3.2.2 模型方面
在构建复杂问答对后,冷启动监督需生成高质量的轨迹。
尽管像 QwQ-32B这样的强大开源LRM能产出部分正确轨迹,但直接微调其完整输出反而有害,主要存在两大问题:
风格污染:LRM 推理风格强烈且冗长,直接微调会过度约束代理,抑制其自主探索与泛化能力。
上下文过载:冗长推理链易导致轨迹超出上下文限制,尤其在涉及数十次工具调用的复杂任务中,严重影响性能与可维护性。
WebSailor 提出了一种轨迹重建方法,克服了专家 LRM 输出冗长的问题:
首先,提示专家开源 LRM 生成完整的解决方案轨迹,并保留成功的动作-观察序列(即解决方案路径的“是什么”和“如何做”)。
然后,利用一个独立的、强大的指令遵循模型 π,对轨迹中的每一步,推断出简洁、面向行动的意图(Thought),即“为什么”采取该行动。
最后,通过强制执行“short-CoT”风格,确保推理链足够紧凑,适用于长时序任务。
WebAgent的一些列论文其实都是使用了冷启动+RL的模式。实验对比也说明了冷启动的重要性。
RFT 冷启动和强化学习 WebSailor 的训练方法是一个两阶段过程:
RFT 冷启动: 采用适度的拒绝采样微调(RFT)作为“冷启动”,这被证明是不可或缺的。复杂任务的奖励极其稀疏,直接训练很难起步。SFT为模型配备基本的工具使用能力,并遵循长时序推理框架。通过过滤掉长度超过 32k token 或工具调用少于 5 次的简单轨迹,选择回答正确,长度合适,足够复杂的样本,保证了冷启动数据的质量和复杂度,让模型先知道思考轨迹和工具调用方法。
RL强化学习:使用Duplicating Sampling Policy Optimization (DUPO), 针对智能体 RL 训练速度慢的问题,WebSailor 使用了 DUPO 算法。
DUPO是对DAPO算法的巧妙改进。在训练过程中,对于那些非常简单(所有 rollout 都成功)或非常难(所有 rollout 都失败)的样本,其学习信号很弱。DUPO首先会“精加工”过滤掉那些过于简单的样本。然后,在填充训练批次时,它不会用无意义的padding数据,而是从当前批次中随机复制那些具有“学习价值”的样本。相比于 DAPO 的动态采样,该方法实现了约 2–3 倍的速度提升。
3.3 主要贡献
WebSailor论文最大贡献是提供了一套SailorFog-QA复杂推理问题的数据合成方法,以及高质量的推理轨迹重构方法,给模型训练提供高质量数据。
模型训练上仍然是采用适度的拒绝采样微调(RFT)作为“冷启动”,然后使用DUPO强化学习提升训练效率,在模型训练和实验分析中也有很多宝贵经验。最终效果在高难度基准 BrowseComp-en/zh 上,WebSailor-72B显著超越此前所有开源方案,甚至媲美部分闭源系统(如豆包搜索)。
4 WebShaper
WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization (2025-07-22)
论文地址:https://arxiv.org/pdf/2507.15061
4.1 背景和动机
通过前几篇论文的介绍可以看出,WebAgent的通用开发流程可以归纳为:
(1)为任务构建特定格式的问题-答案轨迹,获取训练数据
(2)通过SFT微调模型,冷启动让模型具有基础能力
(3)通过RL强化学习,提升模型决策的泛化能力
第一步的数据质量直接影响模型的效果,而之前的Information-Seek数据合成方法通常都是由随机游走和序列生成线性信息链再由大模型生成问题,这些方法有两个关键局限性:
(1)使用LLM合成时可能很难完全理解信息的结构,导致问题推理结构不一致甚至答案错误
(2)无序的信息检索导致过多的数据处理,或者收集到冗余的同质化结构信息,从而限制了信息结构的多样性,降低了知识覆盖范围。
WebShaper直接换个数据合成的思路, 创新了一种形式化驱动的新范式,标示了通义的IS任务从启发式理解迈向数据建模的质变。
他们用集合论把IS重新定义,并提出一个核心概念叫KP“知识投影”(Knowledge Projection)。基于这个框架,设计了一个叫 扩展器(Expander) 的智能体,它会从一些简单的“种子问题”出发,像搭积木一样,一步步自动扩展出越来越复杂、但结构清晰的问答对。
4.2 论文方案
个人觉得Shaper最创新重点在数据部分,所以本文也只介绍Webshaper的数据合成。
4.2.1 第一阶段Seed Question Construction
基于维基百科的数据使用WebDancer框架完成了种子问题。基于QwQ模型对每个问题执行了5次rollout,并在至少有一次rollout正确回答问题的情况下保存数据,最后构造了18k个种子问题。
4.2.2 第二阶段--Agentic Expansion
通过n步扩散,逐步将种子问题扩展为复杂问题
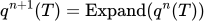
descript
论文引入了KP表示(knowledge Projection Representation)为了更好的表示IS任务的形式结构。
每一个 知识投影(R(S)) 表达式,都可以被表示为一个三元组:[X, r, S]
其中:
- X 是目标变量(最终想找的实体)
- r 是关系名称(如 bornIn, playAt, locatedIn)
- S 是输入实体集合(可以是常量或变量)
- V@... 表示一个 变量名
- C@... 表示一个 常量的自然语言定义

descript
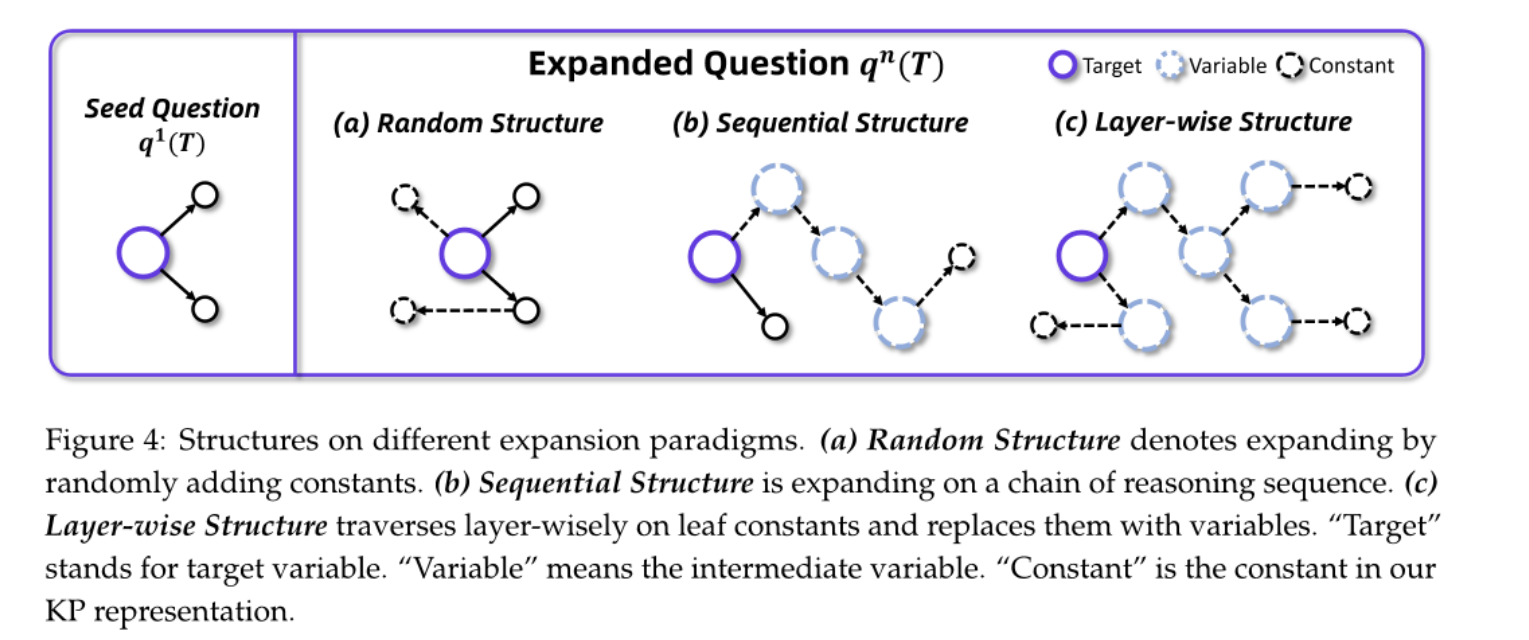
如果我们直接把一个常量和目标答案连起来,模型很容易猜答案,而不是靠理解推理过程,所以论文引入 形式化图表示(KP Triplet Graph) + 分层扩展机制 来避免上述问题。
论文可以把一个问题 q(T) 表示成一个有向图,具体实现逻辑如下:
Step 1: 找出图中所有“叶子常量”
也就是没有出边、在推理链尾部的常量节点(如 {2004}, {Germany} 等,因为这些节点是最容易展开成“子任务”的。
Step 2: 用 Expander 构造一个新子问题 FP
对于每个叶子常量把它变成一个“待查询的目标变量”,然后设计一个新的子问题,使这个常量是它的“答案”
例如:原来是 T = bornIn({90s}) ∩ playAt({2004})
现在拿 {2004} 构造出:T' = locatedIn({Germany}) ∩ hasLeague({Third Division}),使得这个新推理的结果是 {2004}
Step 3: 把这个子问题连接回原问题图中
现在 {2004} 变成了一个子问题的解,你把 {2004} 换成这个新的推理链:
V --playAt--> {2004}
V --playAt--> V1 --locatedIn--> Germany --hasLeague--> ThirdDivision
新的问题图比原来的更深、更复杂,但逻辑完全正确,而且没有捷径。
Step 4: 形式化表达
公式如下:
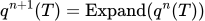
descript
保证:新问题 q_{n+1}(T) 与旧问题 q_n(T) 的目标答案相同,只是结构变复杂了。
Layer-wise Expansion 是 WebShaper 的关键机制,它将自然语言问题转化为结构化推理图,并在每一步扩展时保持逻辑连贯性、避免冗余和捷径,实现高质量的多跳信息检索任务自动生成。
descript
4.2.3 第三阶段--Expander Agent
Expander = 一个自动生成子问题的智能体(Agent),它可以:
给定一个【常量】(如 {2004}),自动去网上搜索、总结信息,再构造一个【关于这个常量的子问题】,最后将这个子问题整合进原问题,得到更复杂的问题结构。
4.2.4 第四阶段-- Trajectory Construction
构建一批完整的“解决信息检索任务”的过程轨迹,用于训练信息检索 agent(监督训练 + 强化学习);
这些轨迹模拟一个 agent 是如何“思考 → 搜索 → 观察 → 决策”直到得到正确答案,生成的数据集 ≈ 高质量搜索推理轨迹。
轨迹生成方式:对于每一个扩展后的任务 q(T):QwQ 会 rollout(运行)5 次,即用不同随机种子或语言模型初始化尝试 5 套解题过程;得到多个候选轨迹(A1、A2、A3...);
但并不似乎所有的行为轨迹都是高质量数据!所以论文还设计了两个重要的过滤策略:正确性过滤和质量过滤。
4.3 主要贡献
WebShaper 的核心在于将数据合成的关注点从被动组织信息(信息驱动)转移到了主动规范任务结构(形式化驱动),通过数学工具保证了数据的高质量、多样性、结构一致性和可控性。 WebShaper 训练出的模型在 GAIA 和 WebWalkerQA 这两个基准测试中都优于所有现有的开源 IS 智能体,并且逼近闭源模型。
5 WebWatcher
WebWatcher: Breaking New Frontiers of Vision-Language Deep Research Agent(2025-09-03)
论文地址:https://arxiv.org/pdf/2508.05748
5.1 背景和动机
WebWatcher的提出是为了应对现有深度研究代理在处理真实世界复杂任务时面临的主要限制和挑战:
1. 现有研究主要以文本为中心 (Text-Centric Limitation): 尽管现有的深度研究代理在解决高难度信息检索问题方面表现出超人的认知能力,但大多数研究进展仍主要局限于文本领域,忽略了在现实世界中普遍存在的丰富视觉信息。
2. 多模态任务难度高:结合视觉与语言进行深度推理,需要更强的感知、逻辑和工具使用能力,远超纯文本任务
3. 现有多模态Agent局限性:
◦ 推理缺乏灵活性: 当前的多模态深度研究依赖于固定的、模板驱动的流程,缺乏解决真实研究挑战所需的灵活推理能力。
◦ 工具集成不足: 现有的视觉-语言(VL)处理主要依赖视觉工具如OCR,但它们难以将视觉推理与深度文本理解和跨模态推理相结合,无法应对需要复杂推理的高难度任务。
◦ 检索限制: 仅使用搜索工具会限制代理停留在检索任务上,无法解决需要额外计算(如执行代码解释图表)、结构化交互或浏览动态网页以提取最新内容的复杂现实任务。
5.2 论文方案
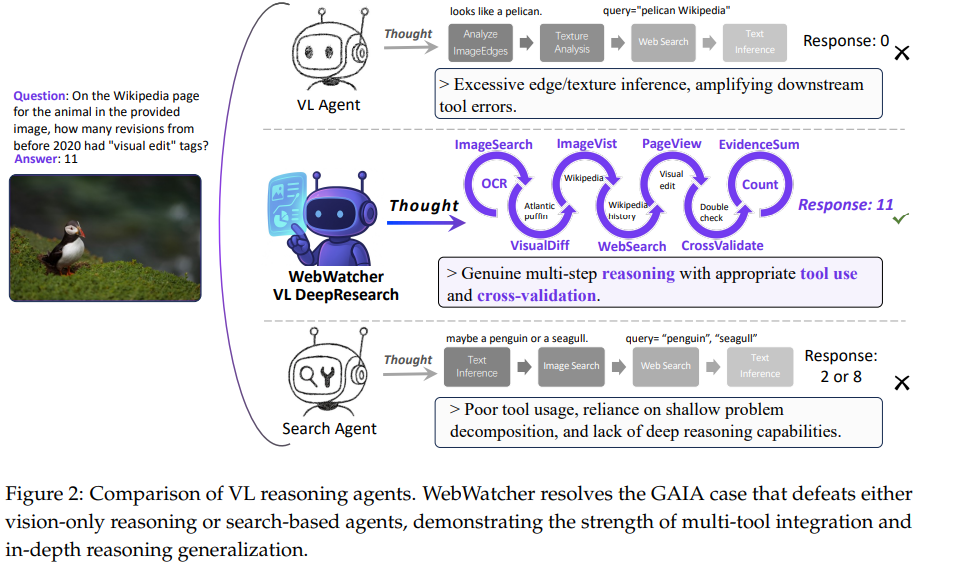
WebWatcher,一个具备增强视觉-语言推理能力的多模态深度研究代理。
descript
其核心解决方案包括数据构建、多工具集成和训练策略:
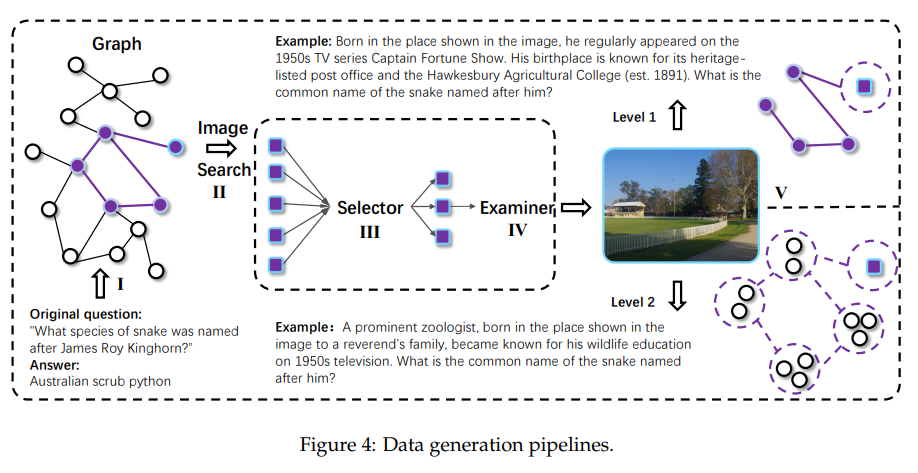
5.2.1 高质量多模态数据构建 (BrowseComp-VL 数据集)
数据集BrowseComp-VL专为在真实网络环境中运行的高级多模态推理智能体而设计。每个示例包含一张事实性图像、一个需要跨模态推理的关联问题,以及关于底层实体和关系的辅助元数据。此外,论文还定义了两个难度级别,以鼓励多样化的推理能力。
descript
Level 1: 需要多跳推理,但仍会明确提及实体。
Level 2:涉及的实体和属性经过故意模糊化或去噪处理。例如,具体日期被替换为模糊的时间段,人名被隐藏,定量属性则被适度模糊化。
具体构建流程如下:
step1 : 生成高难度QA对
首先通从权威源(如 arXiv、GitHub、Wikipedia)递归爬取网页,使用 GPT-4o 生成构建具有多跳推理链的高难度文本QA对。Level 2 中引入模糊实体,要求模型跨模态综合推理而非直接检索。
论文提出了如下两阶段的QA生成框架:
(1)节点选择策略:
- 以维基页面标题为根节点 Broot;
- 构建一个 深度 d=3、分支 k=3 的超链接树;
- 从中采样子图,定义多跳实体路径;
- 每条路径代表一个推理链,用来生成 QA。
(2)问题生成策略:
- 先生成“显式版”(包含实体名);
- 再模糊化实体,替换为模糊描述;
- 迫使模型从语境中“猜出”关系。
step2: QA到VQA的转换
将这些丰富的QA对转化为多模态VQA,通过将文本问答任务与相关视觉内容进行关联。
视觉锚定:首先过滤掉缺乏视觉语义的实体(如时间、抽象概念),然后对保留下来的实体通过 Google SerpApi 检索两张真实、无噪声的图片,以增强任务的现实感。
实体掩码与重写:将问题中的明确实体替换为视觉指代词,并为每张检索到的图片分别配对问题与答案,从而从一个文本问答生成多条视觉问答(VQA)实例。
step3:质量控制
采用多阶段过滤流程(包括选择器和检验器)来确保生成数据的质量和清晰度。
5.2.2 多工具集成和使用 (Multi-Tool Integration)
WebWatcher集成了多种外部工具,以实现跨文本和视觉信息的强大推理能力:
工具列表: 包括Web Image Search(网络图像搜索)、Web Text Search(网络文本搜索)、Visit(访问指定网页并摘要)、Code Interpreter(代码解释器)以及内部的OCR工具。
自动化轨迹生成: 开发了一个完全自动化的流程,使用LLM提示来构造推理轨迹(React模式)
轨迹过滤: 采用三阶段过滤机制,确保轨迹是高质量且具有指导意义的,包括最终答案匹配、步骤一致性检查和最低工具使用要求(不少于三次工具调用),以鼓励多步骤推理。
5.2.3 训练策略 (Training Strategy)
WebWatcher仍然采用两阶段训练方法:SFT 冷启动 (Cold Start)和 强化学习优化 (RL),RL采用PPO的变体GRPO算法来进一步优化决策制定和工具使用,使其适应复杂任务。
5.3 主要贡献
WebWatcher 提出了BrowseComp-VL,一个全新的、高难度的视觉-语言问答(VQA)基准,另外引入了一个可扩展的流程,能够将复杂的文本QA示例转化为高质量的VQA训练数据。WebWatcher能在真实网页与图像环境中完成复杂、多阶段、跨模态的探索任务,标志着多模态 DeepResearch 代理从“感知理解”迈向“推理与规划”的关键一步。
6 WebSailor-V2
WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning (2025-09-17)
论文地址:https://arxiv.org/pdf/2509.13305
6.1 背景和动机
论文指出尽管数据和训练方法上一直在不断进步,但是开源方案与专有系统(如 OpenAI 的 DeepResearch)之间仍存在显著性能差距,而这一差距不在于单一的模型能力,而主要源于构建高性能智能体最关键的两个环节数据与训练面临根本性挑战:
数据挑战:多样性不足,不确定性定义单一
训练挑战:缺乏可扩展的强化学习(RL)环境
为了解决上述挑战,WebSailor-V2 提出了一个完整的开源后训练流程,涵盖了数据构建、监督微调(SFT)和强化学习(RL)。
6.2 论文方案
6.2.1 数据方面:构建 SailorFog-QA-V2 综合数据集
WebSailor-V2 引入了 SailorFog-QA-V2,这是在 SailorFog-QA 基础上改进而来的增强数据集。
(1)知识图谱的密集互联构建: V2 从一个密集互联的知识图谱中构建数据。为了克服传统“从易到难”或迭代扩展策略容易产生树状或无环逻辑结构的局限性,V2 在图扩展阶段进行了重大增强,积极寻求并建立了更密集的节点连接,有意创建循环结构,使其更准确地反映真实世界知识的复杂、非线性性质。
(2)高效子图提取: 鉴于 V2 的图谱密度大幅增加,枚举所有子结构在计算上不可行。因此,团队采用了基于随机游走的方法进行子图提取,从而能够有效地收集代表各种结构复杂性的非同构连通子图。
(3)多样化的不确定性定义: V2 引入了更广泛定义的不确定性类型,超越了常见的混淆方法。这些不确定性旨在激发模型更多样化、更全面的高级推理能力,例如通过上下文推理来消除未明确实体的歧义,并通过迭代信息收集来生成和验证假设。
6.2.2 模型训练:双环境 RL 框架与反馈回路
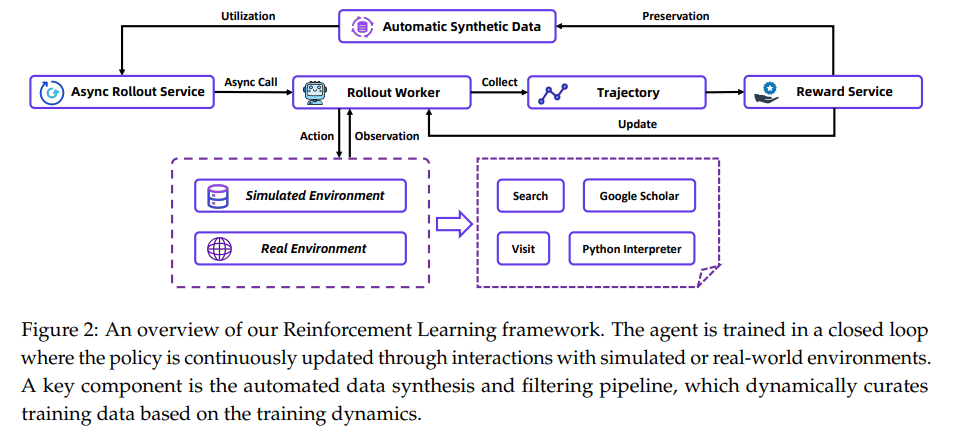
descript
WebSailor-V2 工程化了一个双环境 RL 框架,以应对可扩展性和鲁棒性的需求。
(1) 高保真模拟环境: 真实的网络检索API价格是昂贵的,而且稳定性不可保障,tongyi团队开发了一个专用的模拟环境,基于一个大规模的离线 Wikipedia 知识库。这个平台具有低成本、极快且完全可控的特点,大大加速了开发和迭代过程。
(2)鲁棒的真实环境: 认识到真实环境训练的工程复杂性(特别是外部 API 的波动性),团队系统地管理了工具包,构建了一个统一的工具执行接口。该接口具有强大的并发处理和容错策略,从而将训练循环与真实世界的随机性隔离开来,保证了工具调用的确定性和稳定性。
(3)数据-策略反馈回路: 数据构建和 RL 训练流程被整合到一个共生反馈回路中。这个动态机制能够根据训练动态自动合成和过滤高质量数据,使模型能够持续改进其策略,并从相关信息流中学习,从而更有效、更高效地构建深度研究智能体。
(4)训练基础: WebSailor-V2 基于 Qwen3-30B-A3B 模型进行训练,并将上下文长度增加到 128k。仍然采用 ReAct 框架作为基础架构,同时RL算法采用了 GRPO 。选择工具包括搜索、访问、Google Scholar 和 Python 解释器,这些在上文都有介绍。
6.3 主要贡献
WebSailor-V2 重点扔在数据合成方面,另外也提出应用过程中模型训练环境的重要性,提出了双环境 RL 框架与反馈回路方案。通过“复杂数据构建 + 双环境 RL + 两阶段训练”的端到端工程范式,显著提升开源模型在真实网页深度研究任务中的能力。个人认为关键贡献在于:(1)提供了SailorFog-QA-V2 数据集,提出可诱导强推理的稠密结构化数据的方案;(2)设计了高保真且可复现的训练环境,给模型训练提供了双环境。
总结
最后对家族“祖先”们(第一排)进行下总结。WebWalker,WebDancer,WebSailor,WebShaper, WebWatcher为WebAgent提供了一套基础流程:数据合成--轨迹采样--SFT冷启动--RL强化学习。
数据合成:从“水平搜索”到“深度搜索”,让检索更深入,解决复杂的多跳问题。
轨迹采样:不是使用LLM生成的冗余CoT作为轨迹数据,而是让通过工具调用在真实的检索过程中获取“动作-观察-思考”的高质量推理轨迹。
冷启动:让模型了解WebAgent的基础操作规范,具有合理且可探索的初始策略空间
强化学习:主导模型探索,让模型具备规划,执行和思考能力。
除了算法上SFT以及各种RL上的优化,个人认为更大的贡献在于如何构建和生成高质量的深度检索QA对以及react轨迹的方法,并在多篇论文中贡献了高质量测评集。

descript
- WebWalker (2025-01-14)
WebWalker 构建WebWalkerQA 基准。提出了一个模仿人类网页导航行为的探索-评论(explore-critic) Agent 框架,专注于垂直探索网站内部深层内容,以解决传统搜索引擎无法“深度搜索”的局限性。
- WebDancer (2025-05-14)
WebDancer 提出了一个由易到难的数据构建方法,通过自动化合成高质量 ReAct 轨迹数据并采用 SFT/RL 两阶段训练,增强了模型的自主信息检索能力。
- WebSailor (2025-07-04)
WebSailor提供一套SailorFog-QA复杂推理问题的数据合成方法,以及高质量的推理轨迹重构方法,给模型训练提供高质量数据。
- WebShaper (2025-07-22)
WebShaper 创新性地将信息搜索任务通过知识投影(KP)形式化,将数据合成的关注点从被动组织信息(信息驱动)转移到了主动规范任务结构(形式化驱动),确保自动合成的复杂多跳问答数据具有高质量和逻辑一致性。
- WebWatcher (2025-09-03)
WebWatcher构建了 BrowseComp-VL VQA 基准。提出了一个具备增强视觉-语言推理能力的多模态深度研究代理,通过构建高难度的数据集并集成多工具,标志着深度研究代理从纯文本迈向跨模态推理与规划。
- WebSailor-V2(2025-09-17)
WebSailor-V2引入基于密集知识图谱的复杂合成数据SailorFog-QA-V2基准,以及提出稳定双环境强化学习框架来提升WebAgent的完整后训练流程。
一系列操作下来,WebAgent 构建的问答任务逐渐复杂、工具调用也不断增多,智能体需要执行越来越多轮次的搜索、访问、推理与总结操作,传统基于 ReAct 的线性追加上下文模式让LLM很快面临上下文爆炸问题。 下一篇文章我们来探讨Tongyi的狐獴家族如何通过破解这一挑战。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号