[数据分析]断点回归设计:利用自然实验的巧妙设计
原创

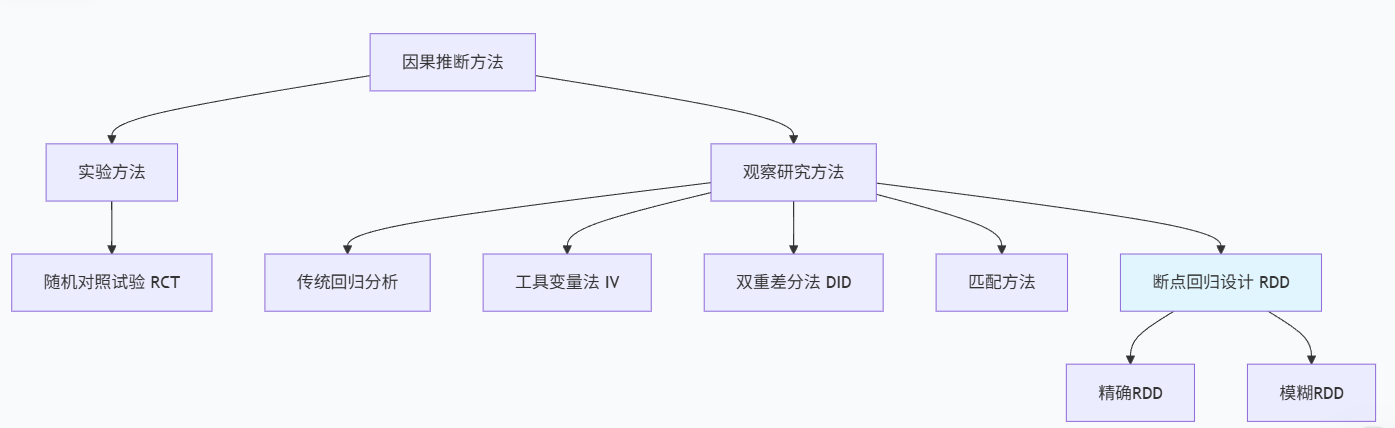
I. 引言
在因果推断的广阔领域中,研究者常常面临一个根本性挑战:如何从观察数据中识别因果关系?当随机对照试验(RCT)因伦理、成本或可行性限制而无法实施时,断点回归设计(Regression Discontinuity Design,RDD)提供了一种严谨的替代方案。这种巧妙的方法利用自然界或社会中存在的"断点"来模拟实验条件,为我们打开了因果推断的新视角。
断点回归设计的核心思想极为直观:当某个连续变量(称为"运行变量"或"分配变量")超过或低于某个特定阈值时,个体接受处理的概率会发生剧烈变化。这种不连续性创造了一个近乎理想的实验环境,使得我们可以比较阈值两侧非常相似的个体,从而估计处理的因果效应。
为什么要关注断点回归设计?
表1:因果推断方法比较
方法 | 核心思想 | 关键假设 | 适用场景 | 主要优势 |
|---|---|---|---|---|
随机对照试验 | 通过随机分配创建可比组 | 随机化成功 | 实验环境 | 黄金标准,内部有效性高 |
双重差分 | 比较处理组和对照组随时间的变化 | 平行趋势假设 | 面板数据 | 控制时间不变混杂因素 |
匹配方法 | 模拟随机化创建相似对照组 | 条件独立假设 | 横截面数据 | 处理可观测混杂 |
断点回归设计 | 利用阈值附近的不连续性 | 连续性假设 | 有明确分配规则 | 内部有效性接近RCT |
断点回归设计的独特优势在于其内部有效性(internal validity)极高,被广泛认为是观察研究中最接近随机实验的设计。当运行变量在阈值附近连续时,阈值两侧的个体在各方面特征都应该是相似的,唯一的系统性差异就是是否接受处理。这一特性使得RDD能够有效避免由选择偏差引起的内生性问题。
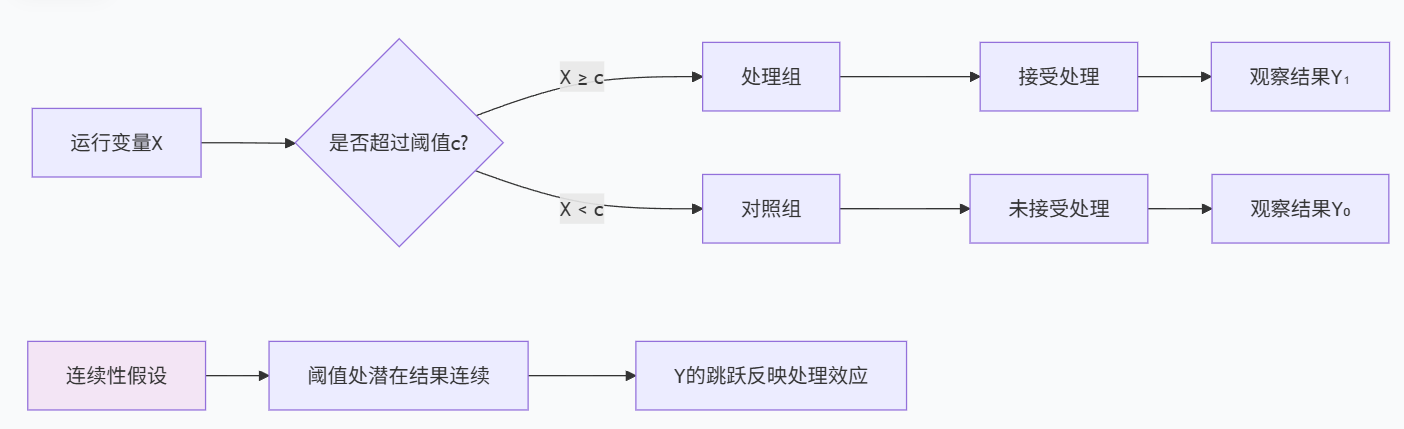
II. 断点回归设计的基本原理
2.1 精确断点回归与模糊断点回归
断点回归设计主要分为两种类型:精确断点回归(Sharp RDD)和模糊断点回归(Fuzzy RDD)。这一区分基于处理分配规则在阈值处的"锐利"程度。
精确断点回归中,处理分配完全由运行变量是否超过阈值决定:
- 如果运行变量 ≥ 阈值,则必定接受处理(D=1)
- 如果运行变量 < 阈值,则必定不接受处理(D=0)
数学表达式为:D = 1(X ≥ c),其中X是运行变量,c是阈值。
模糊断点回归中,阈值影响处理概率,但不是绝对决定因素:
- 如果运行变量 ≥ 阈值,接受处理的概率显著增加,但不是100%
- 如果运行变量 < 阈值,接受处理的概率显著降低,但不是0%
这种情况常见于政策执行不完全、个体自我选择或替代性参与渠道存在的场景。
表2:精确RDD与模糊RDD比较
特征 | 精确RDD | 模糊RDD |
|---|---|---|
处理分配规则 | 确定性:D = 1(X ≥ c) | 概率性:P(D=1│X)在c处跳跃 |
识别策略 | 直接比较阈值两侧结果 | 使用阈值作为工具变量 |
估计方法 | 局部多项式回归 | 两阶段最小二乘法 |
关键假设 | 条件期望函数连续 | 第一阶段存在,排除限制 |
常见场景 | 严格规则执行的政策 | 有不完全遵从的政策 |
2.2 连续性假设:RDD的基石
断点回归设计的有效性依赖于一个关键假设:连续性假设(Continuity Assumption)。该假设认为,在缺乏处理的情况下,结果变量关于运行变量的条件期望函数在阈值处是连续的。
形式化表达为:
lim<sub>ε→0+</sub> EY(0) │ X = c + ε = lim<sub>ε→0-</sub> EY(0) │ X = c + ε
lim<sub>ε→0+</sub> EY(1) │ X = c + ε = lim<sub>ε→0-</sub> EY(1) │ X = c + ε
其中Y(0)和Y(1)分别表示潜在结果(potential outcomes)。
这一假设的直观解释是:如果没有处理效应,运行变量刚刚高于阈值的个体与刚刚低于阈值的个体应该具有相似的结果。任何在阈值处观察到的结果变量的跳跃,都可以归因于处理效应。
2.3 局部随机化解释
断点回归设计的一个强大直觉是"局部随机化"(local randomization)概念。在阈值附近一个很窄的区间内,个体可以近似看作被随机分配到处理组和对照组。这是因为在非常接近阈值时,运行变量的微小变化很大程度上是随机的,不太可能与影响结果的其它变量系统性地相关。
这种解释强调了带宽选择的重要性。带宽越窄,局部随机化的近似越好,但可用的观测值越少,估计精度越低。因此,RDD分析需要在偏差和方差之间进行权衡。
III. 实例分析:班级规模对学生成绩的影响
为了具体说明断点回归设计的应用,我们考虑一个教育经济学中的经典问题:班级规模对学生学业成绩的影响。这个问题具有重要的政策意义,但面临严重的内生性挑战——班级规模往往与学校特征、学生构成等混杂因素相关。
3.1 研究背景与自然实验
我们利用一个基于入学年龄规则的断点设计。在许多教育系统中,学生是否在特定日期前满6岁决定他们能否入学。这创造了一个自然的运行变量:出生日期与截止日期的距离。
具体来说,我们假设以下规则:
- 在9月1日前满6岁的儿童可以入学
- 在9月1日后满6岁的儿童需要等到下一年入学
这导致在截止日期附近出生的儿童(如8月31日 vs 9月1日)在入学时的年龄有近一年的差异,但其他方面应该非常相似。年龄较大的儿童通常被分配到较小的班级,因为这批学生数量较少。
3.2 数据生成过程
我们首先模拟一个接近真实场景的数据集。以下Python代码生成包含关键变量的模拟数据:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
from sklearn.linear_model import LinearRegression
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
# 设置随机种子保证结果可重现
np.random.seed(1234)
# 生成模拟数据
def generate_education_data(n=2000):
"""
生成教育断点回归模拟数据
参数:
n: 样本量
返回:
DataFrame: 包含模拟数据的DataFrame
"""
# 运行变量: 出生日期距离9月1日的天数(-180到180天)
days_from_cutoff = np.random.uniform(-180, 180, n)
# 处理变量: 是否在9月1日前出生(年龄较大)
# 在精确RDD中,这完全由运行变量决定
older = (days_from_cutoff < 0).astype(int)
# 模拟一些协变量(有些可能与运行变量相关)
# 家庭社会经济地位(与出生季节微弱相关)
ses = np.random.normal(0, 1, n) + 0.001 * days_from_cutoff
# 前期学业能力(与年龄相关)
pre_ability = np.random.normal(0, 1, n) + 0.1 * older
# 班级规模(处理变量):年龄较大的学生班级规模较小
# 添加一些随机变异
class_size = 25 - 3 * older + np.random.normal(0, 1, n)
# 结果变量: 标准化测试成绩
# 真实处理效应: 小班级提高成绩0.2标准差
# 同时受能力和SES影响
true_effect = 0.2
test_score = (0.3 * pre_ability + 0.4 * ses +
true_effect * (class_size < 23).astype(int) +
np.random.normal(0, 0.5, n))
# 创建DataFrame
data = pd.DataFrame({
'days_from_cutoff': days_from_cutoff,
'older': older,
'class_size': class_size,
'test_score': test_score,
'ses': ses,
'pre_ability': pre_ability
})
return data
# 生成数据
education_data = generate_education_data(2000)
print("数据前5行:")
print(education_data.head())
print(f"\n数据形状: {education_data.shape}")
print(f"\n变量描述性统计:")
print(education_data.describe())3.3 数据可视化与初步分析
在正式进行断点回归分析前,我们需要直观地检查数据,确认断点的存在:
# 数据可视化
def plot_rdd_data(data, outcome_var, running_var, cutoff=0, bandwidth=None):
"""
绘制断点回归基本图形
参数:
data: 数据框
outcome_var: 结果变量名
running_var: 运行变量名
cutoff: 断点位置
bandwidth: 带宽(如果为None,使用全部数据)
"""
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 子图1: 原始散点图和局部均值
ax1 = axes[0]
# 如果指定了带宽,只绘制带宽内的数据
if bandwidth is not None:
plot_data = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
else:
plot_data = data.copy()
# 区分处理组和对照组
treatment_group = plot_data[plot_data[running_var] >= cutoff]
control_group = plot_data[plot_data[running_var] < cutoff]
# 绘制散点图(添加透明度避免过度绘图)
ax1.scatter(control_group[running_var], control_group[outcome_var],
alpha=0.5, color='blue', s=30, label='对照组 (年轻)')
ax1.scatter(treatment_group[running_var], treatment_group[outcome_var],
alpha=0.5, color='red', s=30, label='处理组 (年长)')
# 计算并绘制局部均值
bin_width = 10 # 每10天一个区间
bins = np.arange(-180, 181, bin_width)
bin_centers = (bins[:-1] + bins[1:]) / 2
means = []
for i in range(len(bins)-1):
bin_data = data[(data[running_var] >= bins[i]) &
(data[running_var] < bins[i+1])]
if len(bin_data) > 0:
means.append(bin_data[outcome_var].mean())
else:
means.append(np.nan)
ax1.plot(bin_centers, means, color='black', linewidth=3, label='局部均值')
# 添加断点线
ax1.axvline(x=cutoff, color='black', linestyle='--', linewidth=2)
ax1.set_xlabel('距离9月1日的天数')
ax1.set_ylabel('标准化测试成绩')
ax1.set_title('断点回归设计: 原始数据与局部均值')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 子图2: 运行变量密度检验(检验操纵)
ax2 = axes[1]
# 绘制运行变量的密度图
sns.kdeplot(data=data[data[running_var] < cutoff][running_var],
ax=ax2, label='对照组', fill=True, alpha=0.5)
sns.kdeplot(data=data[data[running_var] >= cutoff][running_var],
ax=ax2, label='处理组', fill=True, alpha=0.5)
ax2.axvline(x=cutoff, color='black', linestyle='--', linewidth=2)
ax2.set_xlabel('距离9月1日的天数')
ax2.set_ylabel('密度')
ax2.set_title('运行变量密度检验')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 绘制完整数据图形
plot_rdd_data(education_data, 'test_score', 'days_from_cutoff', cutoff=0)3.4 精确断点回归分析
现在我们对模拟数据实施精确断点回归分析。在精确RDD中,处理状态完全由运行变量是否超过阈值决定:
# 精确断点回归分析
def sharp_rdd_analysis(data, outcome_var, running_var, cutoff=0, bandwidth=60):
"""
执行精确断点回归分析
参数:
data: 数据框
outcome_var: 结果变量名
running_var: 运行变量名
cutoff: 断点位置
bandwidth: 分析带宽
返回:
字典: 包含模型结果和诊断信息
"""
# 选择带宽内的数据
subset = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
print(f"带宽内样本量: {len(subset)}")
print(f"处理组样本量: {len(subset[subset[running_var] >= cutoff])}")
print(f"对照组样本量: {len(subset[subset[running_var] < cutoff])}")
# 创建中心化的运行变量(断点为0)
subset['running_centered'] = subset[running_var] - cutoff
# 创建处理指示变量
subset['treatment'] = (subset[running_var] >= cutoff).astype(int)
# 创建运行变量与处理的交互项(允许两侧斜率不同)
subset['running_treatment'] = subset['running_centered'] * subset['treatment']
# 准备回归数据
X = subset[['running_centered', 'treatment', 'running_treatment']]
X = sm.add_constant(X) # 添加截距项
y = subset[outcome_var]
# 执行OLS回归
model = sm.OLS(y, X).fit()
# 输出结果
print("\n=== 精确断点回归结果 ===")
print(model.summary())
# 提取处理效应
treatment_effect = model.params['treatment']
treatment_se = model.bse['treatment']
treatment_pvalue = model.pvalues['treatment']
print(f"\n处理效应估计: {treatment_effect:.4f}")
print(f"标准误: {treatment_se:.4f}")
print(f"P值: {treatment_pvalue:.4f}")
print(f"95%置信区间: [{treatment_effect-1.96*treatment_se:.4f}, "
f"{treatment_effect+1.96*treatment_se:.4f}]")
return {
'model': model,
'subset': subset,
'treatment_effect': treatment_effect,
'standard_error': treatment_se,
'confidence_interval': [
treatment_effect - 1.96 * treatment_se,
treatment_effect + 1.96 * treatment_se
]
}
# 执行精确RDD分析
sharp_results = sharp_rdd_analysis(education_data, 'test_score', 'days_from_cutoff')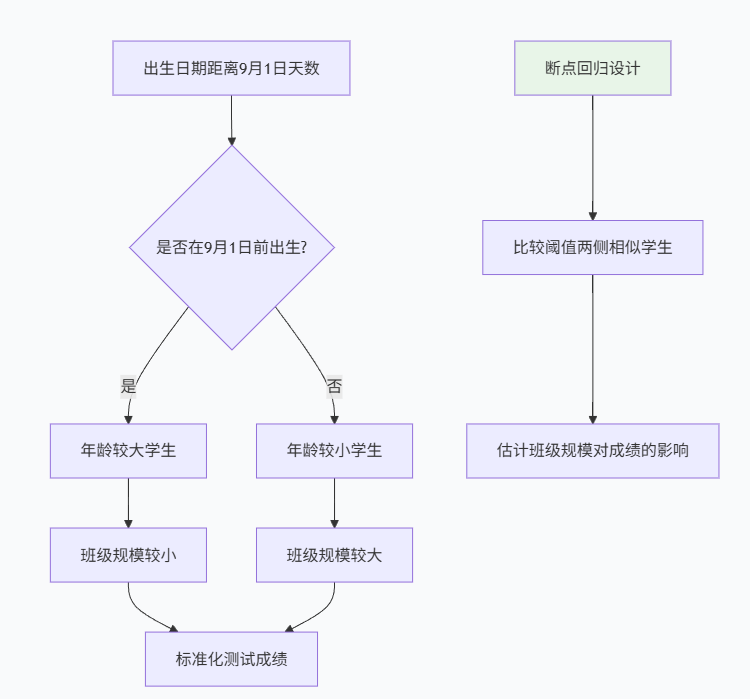
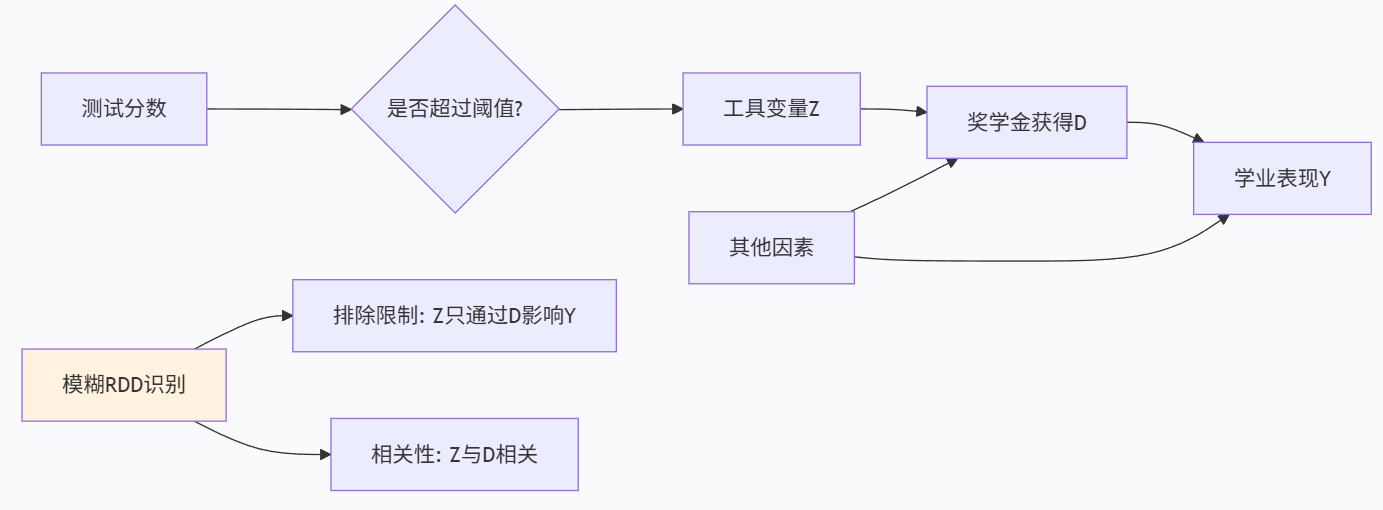
IV. 模糊断点回归设计
4.1 模糊RDD的概念与识别策略
在实际应用中,我们经常遇到模糊断点回归设计的情景。与精确RDD不同,模糊RDD中运行变量超过阈值并不绝对保证接受处理,而是影响处理概率。这种情况更符合现实世界中政策执行的复杂性。
模糊RDD的关键识别策略是将阈值作为处理变量的工具变量(Instrumental Variable)。阈值满足工具变量的关键条件:
- 相关性:阈值与处理变量相关(第一阶段存在)
- 排除限制:阈值只通过影响处理变量来影响结果变量
- 外生性:阈值与误差项不相关(由设计保证)
在模糊RDD中,我们使用两阶段最小二乘法(2SLS)来估计处理效应:
第一阶段:D = α₀ + α₁Z + α₂f(X-c) + α₃Z·f(X-c) + ε
第二阶段:Y = β₀ + β₁D̂ + β₂f(X-c) + β₃Z·f(X-c) + υ
其中Z = 1(X ≥ c)是指示是否超过阈值的变量。
4.2 模糊RDD实例:奖学金对学业表现的影响
考虑一个大学奖学金项目,其中奖学金资格基于标准化测试分数阈值决定。但由于其他因素(如家庭收入、特殊才能等),分数超过阈值的学生不一定获得奖学金,分数低于阈值的学生也可能通过其他渠道获得奖学金。
# 生成模糊RDD数据
def generate_fuzzy_rdd_data(n=2000):
"""
生成模糊断点回归模拟数据:奖学金对学业表现的影响
"""
np.random.seed(1234)
# 运行变量: 标准化测试分数(0-100)
test_score = np.random.uniform(40, 90, n)
# 断点阈值
cutoff = 70
# 是否超过阈值(工具变量)
above_cutoff = (test_score >= cutoff).astype(int)
# 处理变量: 是否获得奖学金(模糊分配)
# 超过阈值的学生有80%概率获得奖学金,低于阈值的有20%概率
base_prob = 0.2
jump_prob = 0.6 # 在阈值处的概率跳跃
scholarship_prob = base_prob + jump_prob * above_cutoff
# 添加一些基于其他因素的变异
scholarship_prob += 0.1 * (test_score - 65) / 25 # 与分数微弱相关
# 确保概率在[0,1]范围内
scholarship_prob = np.clip(scholarship_prob, 0, 1)
# 生成处理变量
scholarship = np.random.binomial(1, scholarship_prob)
# 结果变量: 大学GPA(受奖学金和其他因素影响)
# 真实处理效应: 奖学金提高GPA 0.3点
true_effect = 0.3
# 基础GPA与测试分数相关
base_gpa = 2.5 + 0.03 * test_score + np.random.normal(0, 0.5, n)
# 添加处理效应
final_gpa = base_gpa + true_effect * scholarship + np.random.normal(0, 0.2, n)
# 创建一些协变量
family_income = np.random.normal(0, 1, n) # 家庭收入
motivation = np.random.normal(0, 1, n) # 学习动机
data = pd.DataFrame({
'test_score': test_score,
'above_cutoff': above_cutoff,
'scholarship': scholarship,
'gpa': final_gpa,
'family_income': family_income,
'motivation': motivation
})
return data, cutoff
# 生成模糊RDD数据
fuzzy_data, fuzzy_cutoff = generate_fuzzy_rdd_data(2000)
print("模糊RDD数据描述:")
print(f"断点阈值: {fuzzy_cutoff}")
print(f"超过阈值的学生比例: {fuzzy_data['above_cutoff'].mean():.3f}")
print(f"奖学金获得率: {fuzzy_data['scholarship'].mean():.3f}")
print(f"超过阈值学生的奖学金获得率: {fuzzy_data[fuzzy_data['above_cutoff']==1]['scholarship'].mean():.3f}")
print(f"低于阈值学生的奖学金获得率: {fuzzy_data[fuzzy_data['above_cutoff']==0]['scholarship'].mean():.3f}")4.3 模糊RDD的可视化与分析
def plot_fuzzy_rdd(data, outcome_var, treatment_var, running_var, instrument_var, cutoff, bandwidth=10):
"""
绘制模糊RDD图形
"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 选择带宽内数据
subset = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
# 中心化运行变量
subset['running_centered'] = subset[running_var] - cutoff
# 子图1: 结果变量与运行变量
ax1 = axes[0, 0]
treatment_group = subset[subset[instrument_var] == 1]
control_group = subset[subset[instrument_var] == 0]
ax1.scatter(control_group['running_centered'], control_group[outcome_var],
alpha=0.5, color='blue', s=30, label='工具变量=0')
ax1.scatter(treatment_group['running_centered'], treatment_group[outcome_var],
alpha=0.5, color='red', s=30, label='工具变量=1')
# 计算并绘制局部均值
bin_width = 2
bins = np.arange(-bandwidth, bandwidth + bin_width, bin_width)
bin_centers = (bins[:-1] + bins[1:]) / 2
means_0 = []
means_1 = []
for i in range(len(bins)-1):
bin_data_0 = subset[(subset['running_centered'] >= bins[i]) &
(subset['running_centered'] < bins[i+1]) &
(subset[instrument_var] == 0)]
bin_data_1 = subset[(subset['running_centered'] >= bins[i]) &
(subset['running_centered'] < bins[i+1]) &
(subset[instrument_var] == 1)]
if len(bin_data_0) > 0:
means_0.append(bin_data_0[outcome_var].mean())
else:
means_0.append(np.nan)
if len(bin_data_1) > 0:
means_1.append(bin_data_1[outcome_var].mean())
else:
means_1.append(np.nan)
ax1.plot(bin_centers, means_0, color='blue', linewidth=3, label='工具变量=0均值')
ax1.plot(bin_centers, means_1, color='red', linewidth=3, label='工具变量=1均值')
ax1.axvline(x=0, color='black', linestyle='--', linewidth=2)
ax1.set_xlabel('中心化测试分数')
ax1.set_ylabel('大学GPA')
ax1.set_title('结果变量与运行变量')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 子图2: 处理变量与运行变量
ax2 = axes[0, 1]
ax2.scatter(control_group['running_centered'], control_group[treatment_var],
alpha=0.5, color='blue', s=30, label='工具变量=0')
ax2.scatter(treatment_group['running_centered'], treatment_group[treatment_var],
alpha=0.5, color='red', s=30, label='工具变量=1')
# 计算处理概率的局部均值
prob_0 = []
prob_1 = []
for i in range(len(bins)-1):
bin_data_0 = subset[(subset['running_centered'] >= bins[i]) &
(subset['running_centered'] < bins[i+1]) &
(subset[instrument_var] == 0)]
bin_data_1 = subset[(subset['running_centered'] >= bins[i]) &
(subset['running_centered'] < bins[i+1]) &
(subset[instrument_var] == 1)]
if len(bin_data_0) > 0:
prob_0.append(bin_data_0[treatment_var].mean())
else:
prob_0.append(np.nan)
if len(bin_data_1) > 0:
prob_1.append(bin_data_1[treatment_var].mean())
else:
prob_1.append(np.nan)
ax2.plot(bin_centers, prob_0, color='blue', linewidth=3, label='工具变量=0处理概率')
ax2.plot(bin_centers, prob_1, color='red', linewidth=3, label='工具变量=1处理概率')
ax2.axvline(x=0, color='black', linestyle='--', linewidth=2)
ax2.set_xlabel('中心化测试分数')
ax2.set_ylabel('奖学金获得概率')
ax2.set_title('第一阶段: 工具变量对处理变量的影响')
ax2.legend()
ax2.grid(True, alpha=0.3)
# 子图3: 运行变量密度
ax3 = axes[1, 0]
sns.kdeplot(data=subset[subset[instrument_var]==0]['running_centered'],
ax=ax3, label='工具变量=0', fill=True, alpha=0.5)
sns.kdeplot(data=subset[subset[instrument_var]==1]['running_centered'],
ax=ax3, label='工具变量=1', fill=True, alpha=0.5)
ax3.axvline(x=0, color='black', linestyle='--', linewidth=2)
ax3.set_xlabel('中心化测试分数')
ax3.set_ylabel('密度')
ax3.set_title('运行变量密度检验')
ax3.legend()
ax3.grid(True, alpha=0.3)
# 子图4: 工具变量与处理变量的关系
ax4 = axes[1, 1]
# 计算不同运行变量区间的平均处理概率
full_bins = np.arange(-bandwidth, bandwidth + 1, 1)
full_bin_centers = (full_bins[:-1] + full_bins[1:]) / 2
treatment_probs = []
for i in range(len(full_bins)-1):
bin_data = subset[(subset['running_centered'] >= full_bins[i]) &
(subset['running_centered'] < full_bins[i+1])]
if len(bin_data) > 0:
treatment_probs.append(bin_data[treatment_var].mean())
else:
treatment_probs.append(np.nan)
ax4.plot(full_bin_centers, treatment_probs, 'o-', color='green', linewidth=2, markersize=6)
ax4.axvline(x=0, color='black', linestyle='--', linewidth=2)
ax4.set_xlabel('中心化测试分数')
ax4.set_ylabel('奖学金获得概率')
ax4.set_title('处理概率在断点处的跳跃')
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 绘制模糊RDD图形
plot_fuzzy_rdd(fuzzy_data, 'gpa', 'scholarship', 'test_score', 'above_cutoff', fuzzy_cutoff)4.4 模糊RDD的2SLS估计
def fuzzy_rdd_estimation(data, outcome_var, treatment_var, running_var, instrument_var, cutoff, bandwidth=10):
"""
执行模糊RDD估计(2SLS)
"""
# 选择带宽内数据
subset = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
print(f"带宽内样本量: {len(subset)}")
# 中心化运行变量
subset['running_centered'] = subset[running_var] - cutoff
# 创建工具变量与运行变量的交互项
subset['running_instrument'] = subset['running_centered'] * subset[instrument_var]
# 第一阶段回归: 工具变量对处理变量的影响
X1 = subset[['running_centered', instrument_var, 'running_instrument']]
X1 = sm.add_constant(X1)
y1 = subset[treatment_var]
first_stage = sm.OLS(y1, X1).fit()
print("\n=== 第一阶段回归结果 ===")
print(first_stage.summary())
# 获取预测值
subset['treatment_hat'] = first_stage.predict(X1)
# 第二阶段回归: 预测的处理变量对结果的影响
X2 = subset[['running_centered', 'treatment_hat', 'running_instrument']]
X2 = sm.add_constant(X2)
y2 = subset[outcome_var]
second_stage = sm.OLS(y2, X2).fit()
print("\n=== 第二阶段回归结果 ===")
print(second_stage.summary())
# 使用IV回归包进行更准确的估计(考虑两阶段误差)
from statsmodels.sandbox.regression.gmm import IV2SLS
# 准备变量
endog = subset[outcome_var]
exog = sm.add_constant(subset[['running_centered', 'running_instrument']])
instruments = sm.add_constant(subset[[instrument_var, 'running_centered', 'running_instrument']])
iv_model = IV2SLS(endog, exog, instrument=instruments).fit()
print("\n=== IV/2SLS回归结果 ===")
print(iv_model.summary())
# 计算第一阶段F统计量(检验弱工具变量)
f_statistic = first_stage.fvalue
print(f"\n第一阶段F统计量: {f_statistic:.4f}")
# 计算处理效应
treatment_effect = iv_model.params['treatment_hat'] if 'treatment_hat' in iv_model.params else iv_model.params[treatment_var]
treatment_se = iv_model.bse['treatment_hat'] if 'treatment_hat' in iv_model.bse else iv_model.bse[treatment_var]
print(f"\n模糊RDD处理效应估计: {treatment_effect:.4f}")
print(f"标准误: {treatment_se:.4f}")
print(f"95%置信区间: [{treatment_effect-1.96*treatment_se:.4f}, "
f"{treatment_effect+1.96*treatment_se:.4f}]")
return {
'first_stage': first_stage,
'second_stage': second_stage,
'iv_model': iv_model,
'f_statistic': f_statistic,
'treatment_effect': treatment_effect,
'standard_error': treatment_se
}
# 执行模糊RDD估计
fuzzy_results = fuzzy_rdd_estimation(fuzzy_data, 'gpa', 'scholarship', 'test_score', 'above_cutoff', fuzzy_cutoff)表3:模糊RDD与精确RDD比较
方面 | 精确RDD | 模糊RDD |
|---|---|---|
处理分配 | 确定性规则 | 概率性规则 |
识别假设 | 连续性假设 | 排除限制+连续性 |
估计方法 | 局部多项式回归 | 两阶段最小二乘法 |
处理效应解释 | 平均处理效应 | 局部平均处理效应(LATE) |
适用性 | 规则严格执行 | 规则不完全执行 |
V. 带宽选择与模型设定
5.1 带宽选择的重要性
在断点回归设计中,带宽选择是一个关键决策,它直接影响估计的偏差和方差:
- 较小带宽:减少模型设定依赖,偏差较小,但方差较大
- 较大带宽:增加估计精度,方差较小,但可能引入偏差
理想带宽应该在偏差和方差之间取得平衡。常用的带宽选择方法包括:
- 拇指规则带宽(Rule-of-thumb bandwidth)
- 交叉验证法(Cross-validation)
- 均方误差最优带宽(MSE-optimal bandwidth)
5.2 不同带宽下的敏感性分析
def bandwidth_sensitivity_analysis(data, outcome_var, running_var, cutoff, bandwidths=[20, 40, 60, 80, 100]):
"""
不同带宽下的RDD敏感性分析
"""
results = []
for bw in bandwidths:
# 选择带宽内数据
subset = data[(data[running_var] >= cutoff - bw) &
(data[running_var] <= cutoff + bw)].copy()
# 中心化运行变量
subset['running_centered'] = subset[running_var] - cutoff
# 创建处理变量和交互项
subset['treatment'] = (subset[running_var] >= cutoff).astype(int)
subset['running_treatment'] = subset['running_centered'] * subset['treatment']
# 准备回归数据
X = subset[['running_centered', 'treatment', 'running_treatment']]
X = sm.add_constant(X)
y = subset[outcome_var]
# 执行回归
model = sm.OLS(y, X).fit()
# 提取处理效应
te = model.params['treatment']
se = model.bse['treatment']
ci_lower = te - 1.96 * se
ci_upper = te + 1.96 * se
n_obs = len(subset)
results.append({
'bandwidth': bw,
'treatment_effect': te,
'standard_error': se,
'ci_lower': ci_lower,
'ci_upper': ci_upper,
'n_observations': n_obs
})
# 创建结果数据框
results_df = pd.DataFrame(results)
# 绘制带宽敏感性图
plt.figure(figsize=(10, 6))
plt.errorbar(results_df['bandwidth'], results_df['treatment_effect'],
yerr=1.96*results_df['standard_error'], fmt='o-',
capsize=5, capthick=2, linewidth=2)
plt.axhline(y=0.2, color='red', linestyle='--', linewidth=2, label='真实处理效应 (0.2)')
plt.xlabel('带宽')
plt.ylabel('处理效应估计')
plt.title('带宽敏感性分析')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 打印结果表
print("带宽敏感性分析结果:")
print("="*80)
print(f"{'带宽':<10} {'处理效应':<12} {'标准误':<12} {'95%CI下限':<12} {'95%CI上限':<12} {'样本量':<10}")
print("-"*80)
for _, row in results_df.iterrows():
print(f"{row['bandwidth']:<10} {row['treatment_effect']:<12.4f} {row['standard_error']:<12.4f} "
f"{row['ci_lower']:<12.4f} {row['ci_upper']:<12.4f} {row['n_observations']:<10}")
return results_df
# 执行带宽敏感性分析
bandwidth_results = bandwidth_sensitivity_analysis(education_data, 'test_score', 'days_from_cutoff', 0)5.3 多项式阶数选择
除了带宽选择,多项式阶数也是RDD模型设定的重要方面。线性模型可能不足以捕捉运行变量与结果间的复杂关系,但高阶多项式可能引入过度拟合。
def polynomial_sensitivity_analysis(data, outcome_var, running_var, cutoff, bandwidth=60, degrees=[1, 2, 3, 4]):
"""
不同多项式阶数的敏感性分析
"""
results = []
for degree in degrees:
# 选择带宽内数据
subset = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
# 中心化运行变量
subset['running_centered'] = subset[running_var] - cutoff
# 创建处理变量
subset['treatment'] = (subset[running_var] >= cutoff).astype(int)
# 准备回归数据
# 为对照组创建多项式项
X_poly_control = []
for d in range(1, degree + 1):
X_poly_control.append(subset['running_centered'] ** d)
# 为处理组创建多项式项(允许不同形状)
X_poly_treatment = []
for d in range(1, degree + 1):
X_poly_treatment.append((subset['running_centered'] ** d) * subset['treatment'])
# 组合设计矩阵
X = pd.DataFrame({
'treatment': subset['treatment']
})
for d in range(degree):
X[f'poly_control_{d+1}'] = X_poly_control[d]
X[f'poly_treatment_{d+1}'] = X_poly_treatment[d]
X = sm.add_constant(X)
y = subset[outcome_var]
# 执行回归
model = sm.OLS(y, X).fit()
# 提取处理效应
te = model.params['treatment']
se = model.bse['treatment']
ci_lower = te - 1.96 * se
ci_upper = te + 1.96 * se
n_obs = len(subset)
aic = model.aic
bic = model.bic
results.append({
'degree': degree,
'treatment_effect': te,
'standard_error': se,
'ci_lower': ci_lower,
'ci_upper': ci_upper,
'n_observations': n_obs,
'AIC': aic,
'BIC': bic
})
# 创建结果数据框
results_df = pd.DataFrame(results)
# 绘制多项式阶数敏感性图
plt.figure(figsize=(10, 6))
plt.errorbar(results_df['degree'], results_df['treatment_effect'],
yerr=1.96*results_df['standard_error'], fmt='o-',
capsize=5, capthick=2, linewidth=2)
plt.axhline(y=0.2, color='red', linestyle='--', linewidth=2, label='真实处理效应 (0.2)')
plt.xlabel('多项式阶数')
plt.ylabel('处理效应估计')
plt.title('多项式阶数敏感性分析')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 打印结果表
print("多项式阶数敏感性分析结果:")
print("="*100)
print(f"{'阶数':<8} {'处理效应':<12} {'标准误':<12} {'95%CI下限':<12} {'95%CI上限':<12} {'AIC':<12} {'BIC':<12}")
print("-"*100)
for _, row in results_df.iterrows():
print(f"{row['degree']:<8} {row['treatment_effect']:<12.4f} {row['standard_error']:<12.4f} "
f"{row['ci_lower']:<12.4f} {row['ci_upper']:<12.4f} {row['AIC']:<12.2f} {row['BIC']:<12.2f}")
return results_df
# 执行多项式阶数敏感性分析
polynomial_results = polynomial_sensitivity_analysis(education_data, 'test_score', 'days_from_cutoff', 0)表4:带宽与多项式阶数选择权衡
选择 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
小带宽 | 减少模型依赖,偏差小 | 方差大,估计不精确 | 运行变量与结果关系复杂 |
大带宽 | 估计精度高,方差小 | 可能引入模型设定偏差 | 关系简单,需要更多数据 |
低阶多项式 | 模型简洁,避免过度拟合 | 可能误设函数形式 | 关系接近线性 |
高阶多项式 | 灵活拟合复杂关系 | 可能过度拟合,不稳定 | 非线性关系明显 |

VI. 有效性检验与稳健性分析
6.1 连续性检验:协变量平衡性
断点回归设计的有效性依赖于连续性假设。我们可以通过检验协变量在断点处的连续性来验证这一假设:
def covariate_balance_test(data, covariate_vars, running_var, cutoff, bandwidth=60):
"""
检验协变量在断点处的平衡性
"""
results = []
for covar in covariate_vars:
# 选择带宽内数据
subset = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
# 中心化运行变量
subset['running_centered'] = subset[running_var] - cutoff
# 创建处理变量和交互项
subset['treatment'] = (subset[running_var] >= cutoff).astype(int)
subset['running_treatment'] = subset['running_centered'] * subset['treatment']
# 准备回归数据
X = subset[['running_centered', 'treatment', 'running_treatment']]
X = sm.add_constant(X)
y = subset[covar]
# 执行回归
model = sm.OLS(y, X).fit()
# 提取处理效应(如果不显著,说明协变量平衡)
te = model.params['treatment']
se = model.bse['treatment']
p_value = model.pvalues['treatment']
# 计算标准化差异
treatment_mean = subset[subset['treatment'] == 1][covar].mean()
control_mean = subset[subset['treatment'] == 0][covar].mean()
treatment_std = subset[subset['treatment'] == 1][covar].std()
control_std = subset[subset['treatment'] == 0][covar].std()
pooled_std = np.sqrt((treatment_std**2 + control_std**2) / 2)
standardized_diff = (treatment_mean - control_mean) / pooled_std
results.append({
'covariate': covar,
'treatment_mean': treatment_mean,
'control_mean': control_mean,
'difference': treatment_mean - control_mean,
'standardized_difference': standardized_diff,
'p_value': p_value,
'significant': p_value < 0.05
})
# 创建结果数据框
results_df = pd.DataFrame(results)
# 绘制协变量平衡图
plt.figure(figsize=(10, 6))
y_pos = np.arange(len(covariate_vars))
plt.barh(y_pos, results_df['standardized_difference'], color=['red' if sig else 'blue' for sig in results_df['significant']])
plt.axvline(x=0, color='black', linestyle='-', linewidth=1)
plt.axvline(x=-0.1, color='gray', linestyle='--', linewidth=1, alpha=0.7)
plt.axvline(x=0.1, color='gray', linestyle='--', linewidth=1, alpha=0.7)
plt.yticks(y_pos, covariate_vars)
plt.xlabel('标准化差异')
plt.title('协变量平衡性检验')
plt.grid(True, alpha=0.3, axis='x')
plt.tight_layout()
plt.show()
# 打印结果表
print("协变量平衡性检验结果:")
print("="*90)
print(f"{'协变量':<15} {'处理组均值':<12} {'对照组均值':<12} {'差异':<12} {'标准化差异':<15} {'P值':<10} {'显著':<8}")
print("-"*90)
for _, row in results_df.iterrows():
sig_flag = "是" if row['significant'] else "否"
print(f"{row['covariate']:<15} {row['treatment_mean']:<12.4f} {row['control_mean']:<12.4f} "
f"{row['difference']:<12.4f} {row['standardized_difference']:<15.4f} {row['p_value']:<10.4f} {sig_flag:<8}")
return results_df
# 执行协变量平衡性检验
covariates = ['ses', 'pre_ability'] # 社会经济地位和前期能力
balance_results = covariate_balance_test(education_data, covariates, 'days_from_cutoff', 0)6.2 操纵检验:运行变量密度检验
如果个体能够精确操纵运行变量,断点回归设计的有效性就会受到威胁。我们可以通过检验运行变量在断点处的密度是否连续来检测操纵:
def manipulation_test(data, running_var, cutoff, bandwidth=None):
"""
检验运行变量是否存在操纵
"""
if bandwidth is None:
plot_data = data.copy()
else:
plot_data = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
# 使用McCrary检验(密度连续性检验)
from statsmodels.nonparametric.kde import KDEUnivariate
# 分别估计处理组和对照组的密度
kde_treatment = KDEUnivariate(plot_data[plot_data[running_var] >= cutoff][running_var])
kde_control = KDEUnivariate(plot_data[plot_data[running_var] < cutoff][running_var])
kde_treatment.fit()
kde_control.fit()
# 绘制密度图
plt.figure(figsize=(10, 6))
# 创建更精细的网格点
x_grid = np.linspace(plot_data[running_var].min(), plot_data[running_var].max(), 200)
# 计算密度估计
density_treatment = kde_treatment.evaluate(x_grid)
density_control = kde_control.evaluate(x_grid)
plt.plot(x_grid, density_treatment, color='red', linewidth=2, label='处理组密度')
plt.plot(x_grid, density_control, color='blue', linewidth=2, label='对照组密度')
plt.axvline(x=cutoff, color='black', linestyle='--', linewidth=2, label='断点')
plt.xlabel('运行变量')
plt.ylabel('密度')
plt.title('运行变量密度检验(操纵检验)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 执行正式的密度检验(使用直方图方法)
bin_width = 5 # 根据数据特性调整
bins = np.arange(plot_data[running_var].min(), plot_data[running_var].max() + bin_width, bin_width)
hist_treatment, _ = np.histogram(plot_data[plot_data[running_var] >= cutoff][running_var], bins=bins)
hist_control, _ = np.histogram(plot_data[plot_data[running_var] < cutoff][running_var], bins=bins)
# 计算断点附近的密度比
cutoff_bin = np.digitize(cutoff, bins) - 1 # 找到断点所在的bin
if cutoff_bin > 0 and cutoff_bin < len(hist_treatment) - 1:
# 断点右侧(处理组)的密度
density_right = hist_treatment[cutoff_bin] / (hist_treatment[cutoff_bin] + hist_control[cutoff_bin])
# 断点左侧(对照组)的密度
density_left = hist_control[cutoff_bin-1] / (hist_treatment[cutoff_bin-1] + hist_control[cutoff_bin-1])
density_ratio = density_right / density_left
print(f"断点处密度比(右侧/左侧): {density_ratio:.4f}")
if abs(np.log(density_ratio)) > 0.1: # 经验阈值
print("警告:可能存在运行变量操纵!")
else:
print("未发现明显的运行变量操纵迹象。")
return {
'density_treatment': density_treatment,
'density_control': density_control,
'x_grid': x_grid
}
# 执行操纵检验
manipulation_results = manipulation_test(education_data, 'days_from_cutoff', 0, bandwidth=100)6.3 安慰剂检验:虚假断点分析
安慰剂检验通过将断点放在不应该有处理效应的位置,来验证研究设计的有效性:
def placebo_test(data, outcome_var, running_var, true_cutoff, placebo_cutoffs, bandwidth=60):
"""
安慰剂检验:在虚假断点处检验处理效应
"""
results = []
for placebo_cutoff in placebo_cutoffs:
# 确保安慰剂断点不在真实断点附近
if abs(placebo_cutoff - true_cutoff) < bandwidth:
continue
# 选择带宽内数据
subset = data[(data[running_var] >= placebo_cutoff - bandwidth) &
(data[running_var] <= placebo_cutoff + bandwidth)].copy()
if len(subset) < 50: # 确保有足够样本
continue
# 中心化运行变量
subset['running_centered'] = subset[running_var] - placebo_cutoff
# 创建处理变量和交互项
subset['treatment'] = (subset[running_var] >= placebo_cutoff).astype(int)
subset['running_treatment'] = subset['running_centered'] * subset['treatment']
# 准备回归数据
X = subset[['running_centered', 'treatment', 'running_treatment']]
X = sm.add_constant(X)
y = subset[outcome_var]
# 执行回归
model = sm.OLS(y, X).fit()
# 提取处理效应
te = model.params['treatment']
se = model.bse['treatment']
p_value = model.pvalues['treatment']
results.append({
'cutoff': placebo_cutoff,
'treatment_effect': te,
'standard_error': se,
'p_value': p_value,
'n_observations': len(subset),
'distance_from_true': abs(placebo_cutoff - true_cutoff)
})
# 创建结果数据框
results_df = pd.DataFrame(results)
if len(results_df) == 0:
print("没有合适的安慰剂断点可供检验。")
return None
# 绘制安慰剂检验图
plt.figure(figsize=(10, 6))
# 绘制真实断点处的效应(参考线)
plt.axhline(y=0.2, color='red', linestyle='--', linewidth=2, label='真实处理效应')
plt.axhline(y=0, color='black', linestyle='-', linewidth=1, alpha=0.5)
# 绘制安慰剂断点处的效应
colors = ['green' if p > 0.05 else 'red' for p in results_df['p_value']]
plt.scatter(results_df['cutoff'], results_df['treatment_effect'],
c=colors, s=100, alpha=0.7, edgecolors='black')
# 添加误差线
plt.errorbar(results_df['cutoff'], results_df['treatment_effect'],
yerr=1.96*results_df['standard_error'], fmt='none',
ecolor='gray', alpha=0.7)
plt.xlabel('安慰剂断点位置')
plt.ylabel('处理效应估计')
plt.title('安慰剂检验:虚假断点处的处理效应')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 打印结果表
print("安慰剂检验结果:")
print("="*80)
print(f"{'断点位置':<12} {'处理效应':<12} {'标准误':<12} {'P值':<10} {'样本量':<10} {'距真实断点':<12}")
print("-"*80)
for _, row in results_df.iterrows():
sig_indicator = "**" if row['p_value'] < 0.05 else ""
print(f"{row['cutoff']:<12} {row['treatment_effect']:<12.4f} {row['standard_error']:<12.4f} "
f"{row['p_value']:<10.4f} {row['n_observations']:<10} {row['distance_from_true']:<12.1f}{sig_indicator}")
return results_df
# 执行安慰剂检验(在真实断点以外的位置设置虚假断点)
placebo_cutoffs = [-150, -100, -50, 50, 100, 150] # 真实断点是0
placebo_results = placebo_test(education_data, 'test_score', 'days_from_cutoff', 0, placebo_cutoffs)表5:RDD有效性检验方法
检验类型 | 检验内容 | 原假设 | 通过标准 | 重要性 |
|---|---|---|---|---|
协变量平衡 | 预处理变量在断点处连续 | 协变量无跳跃 | P>0.05,标准化差异小 | 高 |
密度检验 | 运行变量分布在断点处连续 | 无操纵行为 | 密度无显著间断 | 高 |
安慰剂检验 | 虚假断点处无效应 | 无虚假效应 | 效应不显著 | 中 |
带宽敏感性 | 估计结果对带宽选择不敏感 | 估计稳健 | 效应估计稳定 | 中 |
多项式敏感性 | 估计结果对函数形式不敏感 | 模型设定稳健 | 效应估计稳定 | 中 |

VII. 高级主题与扩展应用
7.1 多断点设计
在某些情况下,我们可能会遇到多个断点的情况。例如,不同地区可能有不同的政策阈值,或者同一政策在不同时间有不同阈值。
def multiple_rdd_analysis(data, outcome_var, running_var, cutoffs, bandwidth=60):
"""
多断点RDD分析
"""
results = []
for i, cutoff in enumerate(cutoffs):
print(f"\n=== 断点 {i+1}: {cutoff} ===")
# 选择当前断点带宽内数据
subset = data[(data[running_var] >= cutoff - bandwidth) &
(data[running_var] <= cutoff + bandwidth)].copy()
# 中心化运行变量
subset['running_centered'] = subset[running_var] - cutoff
# 创建处理变量和交互项
subset['treatment'] = (subset[running_var] >= cutoff).astype(int)
subset['running_treatment'] = subset['running_centered'] * subset['treatment']
# 准备回归数据
X = subset[['running_centered', 'treatment', 'running_treatment']]
X = sm.add_constant(X)
y = subset[outcome_var]
# 执行回归
model = sm.OLS(y, X).fit()
# 提取处理效应
te = model.params['treatment']
se = model.bse['treatment']
p_value = model.pvalues['treatment']
results.append({
'cutoff': cutoff,
'treatment_effect': te,
'standard_error': se,
'p_value': p_value,
'n_observations': len(subset),
'model': model
})
print(f"处理效应: {te:.4f} (se: {se:.4f}, p: {p_value:.4f})")
print(f"样本量: {len(subset)}")
# 创建结果数据框
results_df = pd.DataFrame(results)
# 绘制多断点结果图
plt.figure(figsize=(12, 6))
# 绘制运行变量与结果变量的散点图
plt.scatter(data[running_var], data[outcome_var], alpha=0.3, s=20)
# 为每个断点绘制拟合线
colors = ['red', 'blue', 'green', 'orange']
for i, (_, row) in enumerate(results_df.iterrows()):
cutoff = row['cutoff']
model = row['model']
# 在断点附近生成预测点
x_left = np.linspace(cutoff - bandwidth, cutoff, 50)
x_right = np.linspace(cutoff, cutoff + bandwidth, 50)
# 左侧预测
X_left = pd.DataFrame({
'const': 1,
'running_centered': x_left - cutoff,
'treatment': 0,
'running_treatment': 0
})
y_left = model.predict(X_left)
# 右侧预测
X_right = pd.DataFrame({
'const': 1,
'running_centered': x_right - cutoff,
'treatment': 1,
'running_treatment': (x_right - cutoff) * 1
})
y_right = model.predict(X_right)
plt.plot(x_left, y_left, color=colors[i % len(colors)], linewidth=3,
label=f'断点 {cutoff} (左侧)')
plt.plot(x_right, y_right, color=colors[i % len(colors)], linewidth=3,
linestyle='--', label=f'断点 {cutoff} (右侧)')
# 标记断点位置
plt.axvline(x=cutoff, color=colors[i % len(colors)], linestyle=':', alpha=0.7)
plt.xlabel('运行变量')
plt.ylabel('结果变量')
plt.title('多断点回归设计')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
return results_df
# 模拟多断点数据
def generate_multiple_cutoff_data(n=3000):
"""生成多断点模拟数据"""
np.random.seed(1234)
# 运行变量
running_var = np.random.uniform(0, 100, n)
# 三个断点
cutoffs = [25, 50, 75]
# 确定每个观测值所属的断点区间
treatment_group = np.zeros(n)
for i, cutoff in enumerate(cutoffs):
treatment_group[(running_var >= cutoff) & (running_var < (cutoff + 25))] = i + 1
# 结果变量:每个断点处有不同的处理效应
true_effects = [0.3, 0.5, 0.2] # 三个断点处的真实处理效应
base_outcome = 10 + 0.1 * running_var + np.random.normal(0, 2, n)
# 添加处理效应
final_outcome = base_outcome.copy()
for i, effect in enumerate(true_effects):
final_outcome[treatment_group == (i + 1)] += effect
data = pd.DataFrame({
'running_var': running_var,
'treatment_group': treatment_group,
'outcome': final_outcome
})
return data, cutoffs
# 生成并分析多断点数据
multi_data, multi_cutoffs = generate_multiple_cutoff_data()
multi_results = multiple_rdd_analysis(multi_data, 'outcome', 'running_var', multi_cutoffs, bandwidth=15)7.2 断点回归与双重差分的结合
在某些面板数据设置中,我们可以将断点回归设计与双重差分法(Difference-in-Differences)结合,以控制时间固定效应和个体固定效应:
def rdd_did_analysis(panel_data, outcome_var, running_var, time_var, treatment_var, cutoff, event_time):
"""
结合RDD和DID的分析方法
"""
# 选择事件窗口期的数据
event_data = panel_data[
(panel_data[time_var] >= event_time - 2) &
(panel_data[time_var] <= event_time + 2)
].copy()
# 创建相对时间变量
event_data['relative_time'] = event_data[time_var] - event_time
# 创建处理后虚拟变量
event_data['post'] = (event_data[time_var] >= event_time).astype(int)
# 创建处理组虚拟变量(基于运行变量和阈值)
event_data['treated_group'] = (event_data[running_var] >= cutoff).astype(int)
# 创建RDD×DID交互项
event_data['rdd_did'] = event_data['post'] * event_data['treated_group']
# 准备回归数据
# 包括个体固定效应、时间固定效应、RDD项和DID项
X = event_data[['post', 'treated_group', 'rdd_did']]
# 添加运行变量中心化项
event_data['running_centered'] = event_data[running_var] - cutoff
X['running_centered'] = event_data['running_centered']
# 添加运行变量与处理的交互
X['running_treated'] = event_data['running_centered'] * event_data['treated_group']
# 添加个体固定效应(使用虚拟变量)
entity_dummies = pd.get_dummies(event_data['entity_id'], prefix='entity')
X = pd.concat([X, entity_dummies], axis=1)
# 添加时间固定效应
time_dummies = pd.get_dummies(event_data['relative_time'], prefix='time')
X = pd.concat([X, time_dummies], axis=1)
X = sm.add_constant(X)
y = event_data[outcome_var]
# 执行回归
model = sm.OLS(y, X).fit()
print("=== RDD-DID结合分析结果 ===")
print(model.summary())
# 提取关键系数
rdd_effect = model.params['treated_group'] # 横截面RDD效应
did_effect = model.params['post'] # 时间序列DID效应
rdd_did_effect = model.params['rdd_did'] # RDD×DID交互效应
print(f"\n关键系数:")
print(f"RDD效应 (横截面): {rdd_effect:.4f}")
print(f"DID效应 (时间序列): {did_effect:.4f}")
print(f"RDD×DID交互效应: {rdd_did_effect:.4f}")
return {
'model': model,
'rdd_effect': rdd_effect,
'did_effect': did_effect,
'rdd_did_effect': rdd_did_effect
}
# 注意:这里需要面板数据,实际应用中需要准备适当的数据结构
# 以下为函数定义,实际调用需要相应的面板数据表6:RDD扩展应用场景
扩展方法 | 适用场景 | 关键优势 | 实施挑战 |
|---|---|---|---|
多断点设计 | 多个政策阈值 | 提高统计功效,检验效应异质性 | 需要足够样本,效应可比性 |
RDD-DID结合 | 面板数据,政策实施前后 | 控制时间趋势和个体效应 | 需要面板数据,模型复杂 |
分位数RDD | 研究处理效应在整个分布中的异质性 | 提供更全面的效应信息 | 计算复杂,解释难度大 |
多维RDD | 多个运行变量决定处理 | 处理更复杂的分配规则 | 带宽选择复杂,可视化困难 |
动态RDD | 研究效应随时间变化 | 提供动态处理效应 | 需要多期数据,模型设定复杂 |


原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号