BUUCTF通关之路 - Misc Part 5
原创
BUUCTF通关之路 - Misc Part 5
原创
OwenW
修改于 2025-08-28 11:40:53
修改于 2025-08-28 11:40:53
不知不觉也第五篇文章了,感谢大家支持。
1. [HBNIS2018]来题中等的吧
下载题目文件。是一张png格式的图片,内容有点像是摩斯密码。
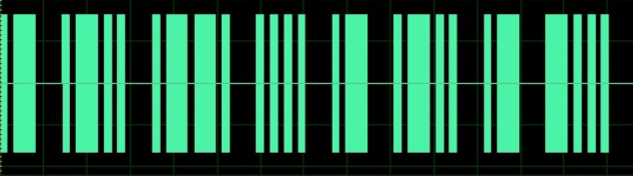
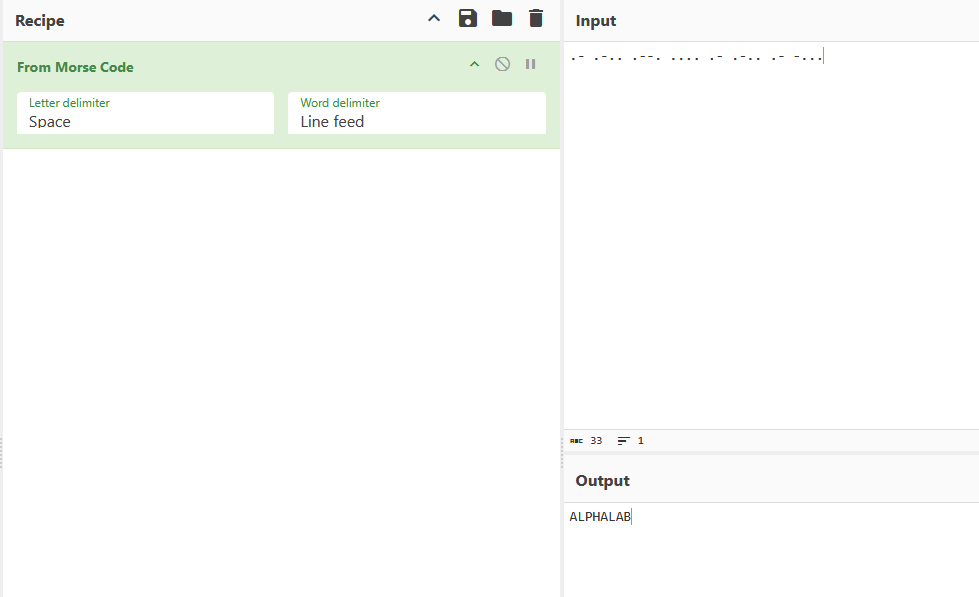
这里手动把其翻译为摩斯密码,细一点的是点,粗一点的是杠。放进CyberChef进行解密,发现解密后的字符串就是答案,只需要小写处理一下。
.- .-.. .--. .... .- .-.. .- -...
类型 | 加密算法 |
|---|---|
工具 | CyberChef |
Flag | flag{alphalab} |
2. 谁赢了比赛?
下载题目文件,是一个棋盘的文件。放进kali用strings看一下可打印字符,发现末尾存在其它文本文件,用binwalk进行分离,分离出了一个有密码的压缩文件。
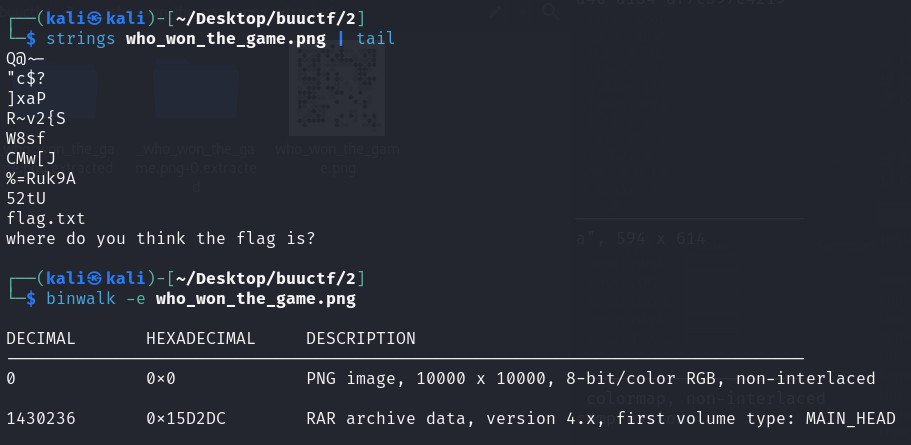
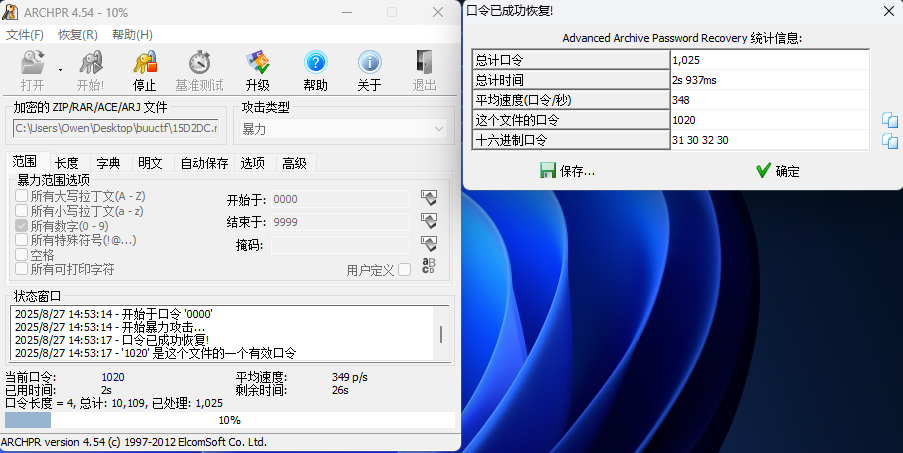
经过判断,该文件不是伪加密,这里没有任何密码信息只能尝试爆破。用ARCHPR中四位数字遍历的方式爆破压缩文件密码,最后发现密码为1020。
压缩文件中可以得到两个文件,一个flag.txt,一个gif图片。前者内容为一个问题,“where do you think the flag is?”,显然这不是flag。gif图片是一个动态的下棋图,一般的思路是把gif内的所有帧拆出来然后单独分析,这里我们用convert命令拆分这个gif。
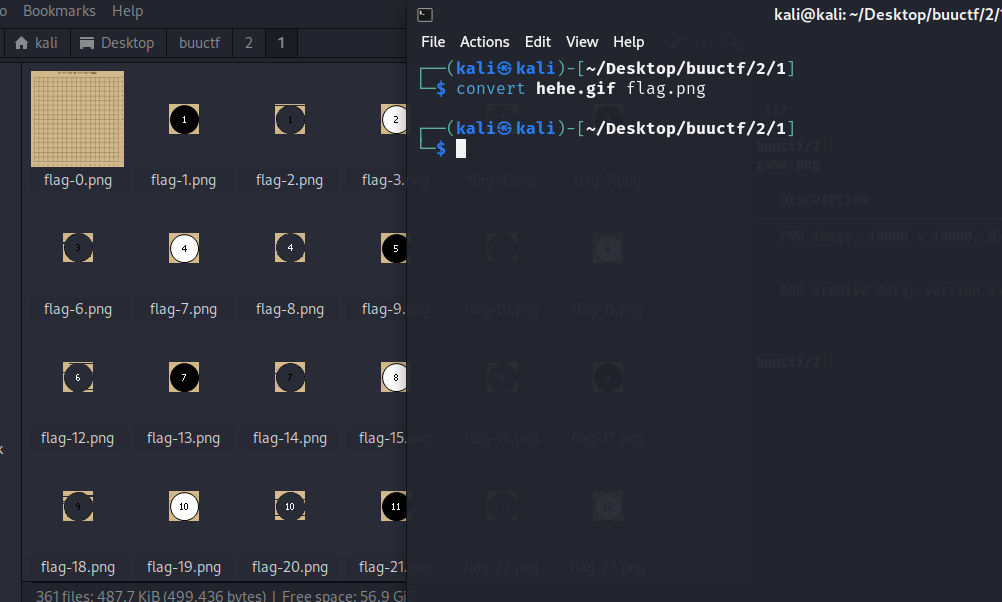
拆分出非常多的棋子图,其中有一张图很特别,是一张纯白的图像,且图像底部有一行字,可惜这行字不是我们要的答案,但它引导了我们去进一步分析这张图片。

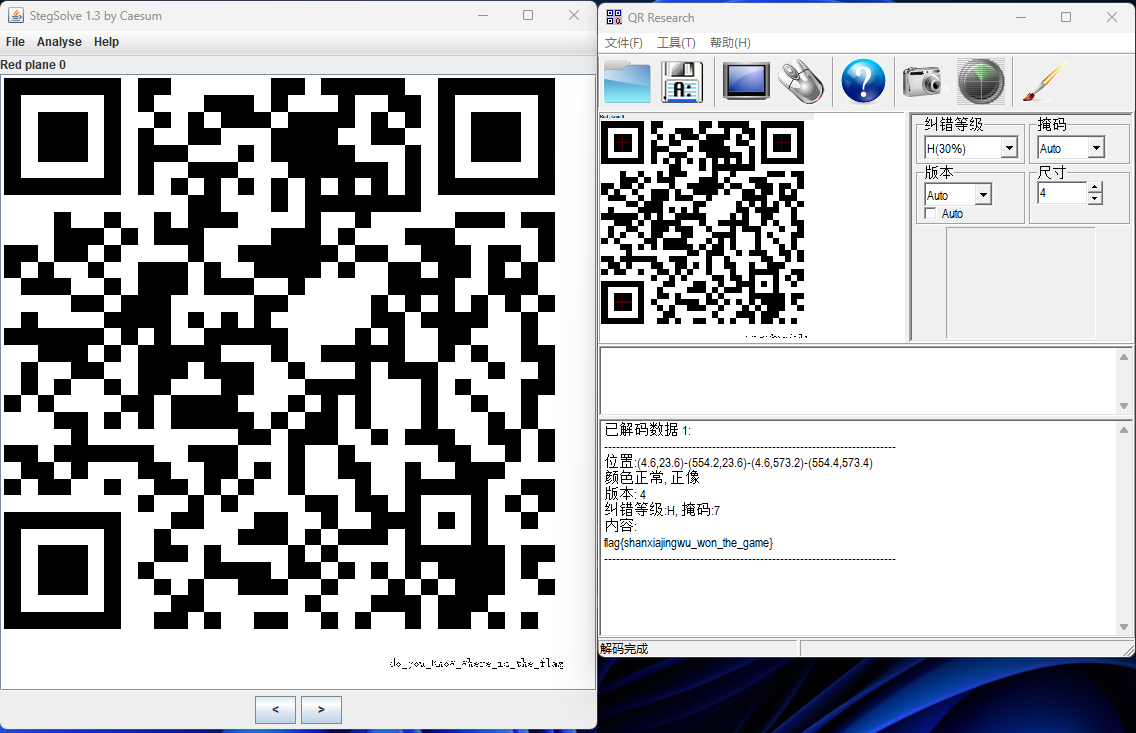
经过一些基本的信息收集无果后,尝试使用stegsolve查看是否存在LSB隐写,结果设置红色通道为0时显示出了一个二维码,用qr_research扫码后出现了答案。
类型 | 图片隐写、压缩文件密码爆破 |
|---|---|
工具 | strings、binwalk、ARCHPR、convert、stegsolve |
Flag | flag{shanxiajingwu_won_the_game} |
3. [ACTF新生赛2020]outguess
题目已经提示了隐写方式,就是使用outguess工具,我是用的kali,在kali上面可以直接apt-get的方式下载outguess。
sudo apt-get update
sudo apt-get install outguess准备好环境后就可以开始做题了,先下载题目文件,压缩文件内包含了一些文件,其中huhuhu文件夹内的内容和huhuhu.zip的内容一样,而压缩文件是一个伪加密,这里原本的题目可能是要考察伪加密,但这里文件已经解压出来了,我们就不去解压了。
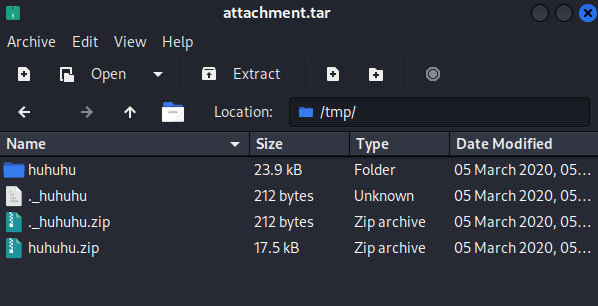
直接看huhuhu这个文件夹,其中包含了一个没有提示信息的文本文件和一张jpg格式的图像,既然我们知道了这道题是outguess,那么我们直接对该图像解密就行。outguess的通用解密命令如下,我们还缺少一个key。
outguess -k [key] -r [stego file name] [output file name]这里用exiftool看一下图片信息,发现有一行明显的评论。
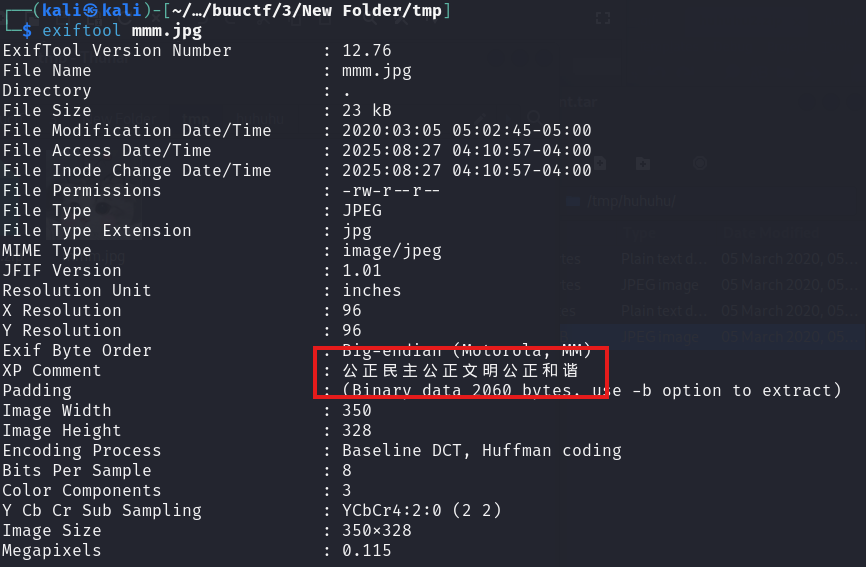
通过无所不能的搜索引擎,我们会找到一个在线编码器叫“社会主义核心价值观编码器”,输入exiftool发现的评论,会返回明文,明文是abc。
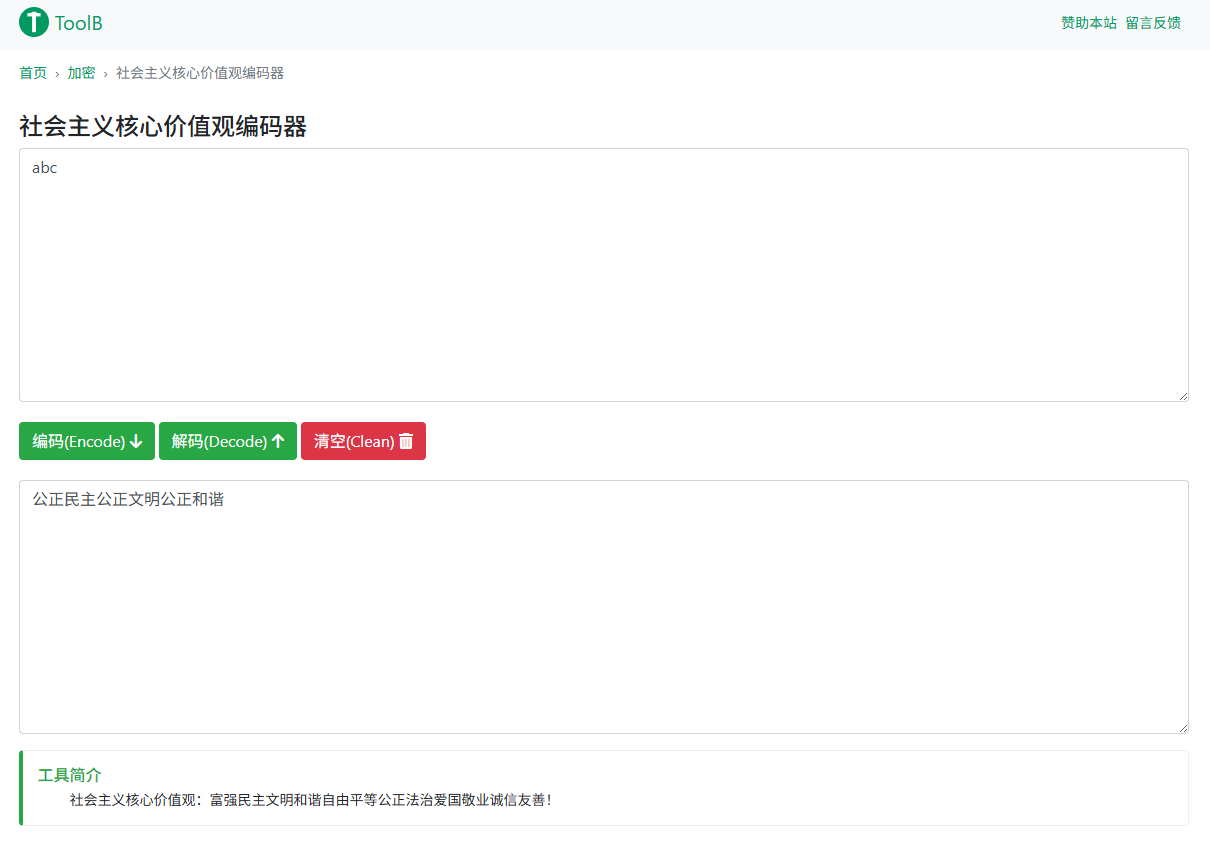
这正式前面解密需要的key,我们输入abc作为key后,就得到了flag。

类型 | 图片隐写 |
|---|---|
工具 | outguess、exiftool、社会主义核心价值观编码器 |
Flag | flag{gue33_Gu3Ss!2020} |
4. 梅花香之苦寒来
下载题目文件,图片上面写着“图穷匕见”,把图片放进“随波逐流”工具内看看,发现图片结尾标识后还有一大串字符串。把这些字符串复制到CyberChef中,发现其本身是16进制表示的一系列坐标。
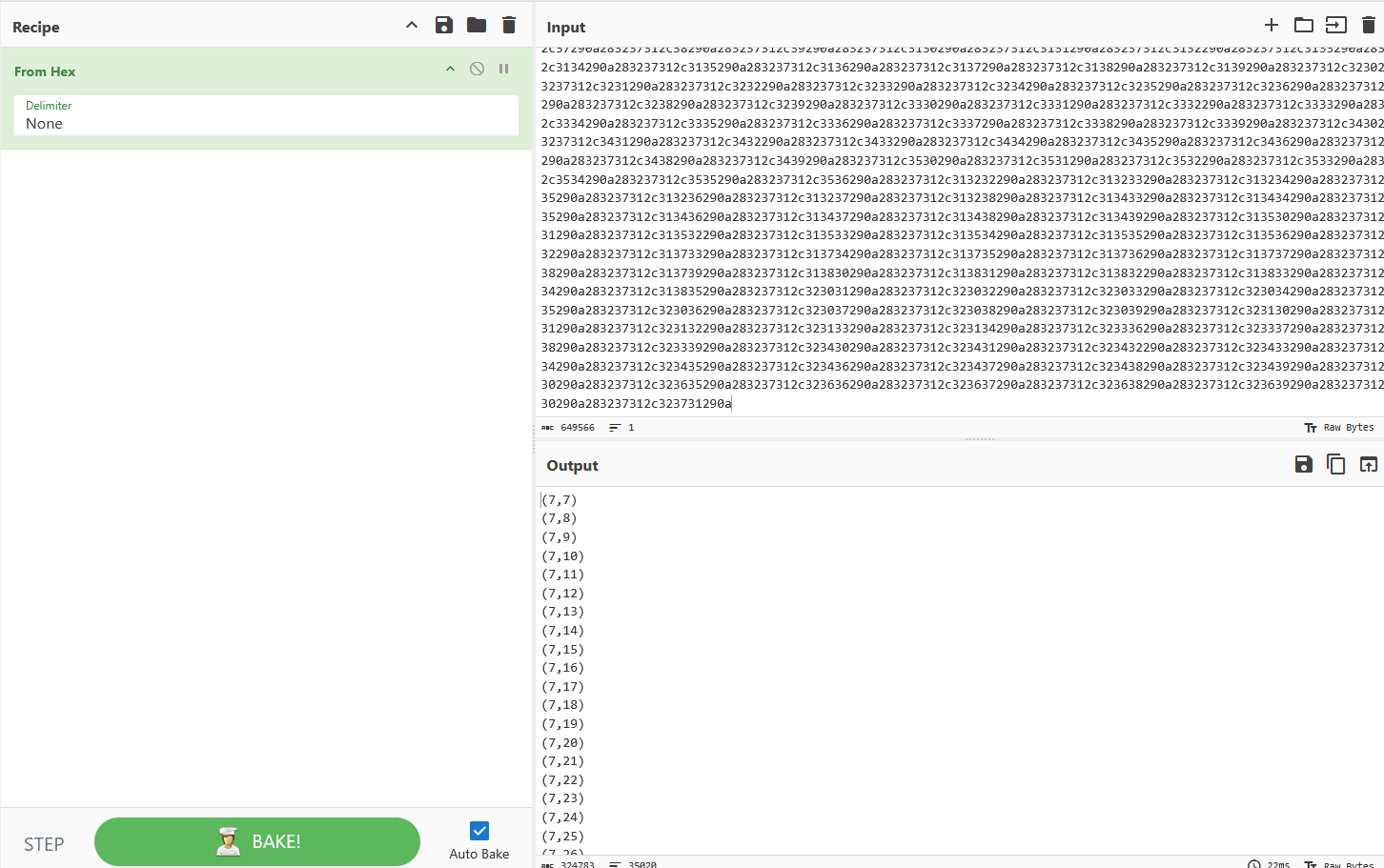
一开始也产生了某种密文格式是坐标的想法,但查了一些资料感觉应该不像。只能老老实实画图,我没找到什么好的在线工具,也实在不想用matlab,写个临时python程序将就一下。坐标太多,放在同目录下的“note.txt”文件中了。
import matplotlib.pyplot as plt
# 读取坐标点
points = []
with open('note.txt', 'r') as f:
for line in f:
x, y = map(float, line.strip()[1:-1].split(','))
points.append((x, y))
# 提取x和y坐标
x_coords = [p[0] for p in points]
y_coords = [p[1] for p in points]
# 绘制图形 - 使用更细的点
plt.plot(x_coords, y_coords, 'ro', markersize=3) # markersize控制点的大小
plt.grid(True)
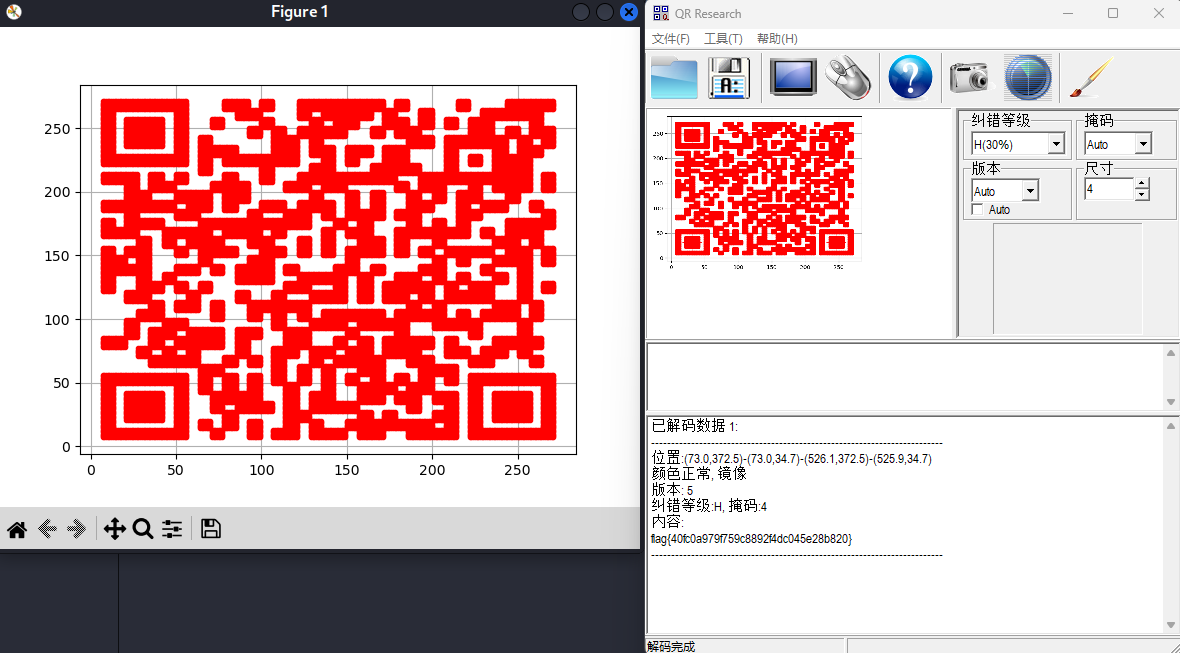
plt.show()绘制出来的图片是一张二维码,用qr_research扫码后就是我们要的答案了。
类型 | 图片隐写 |
|---|---|
工具 | 随波逐流工具、CyberChef、qr_research |
Flag | flag{40fc0a979f759c8892f4dc045e28b820} |
5. [WUSTCTF2020]find_me
建议跳过这道题,这道题解题方法非常简单,但是解密那一步找不到参考资料和工具。这里简单讲一下思路。下载题目文件,是个jpg格式的图片,放进kali中用exiftool看一下文件信息,发现有一串评论。
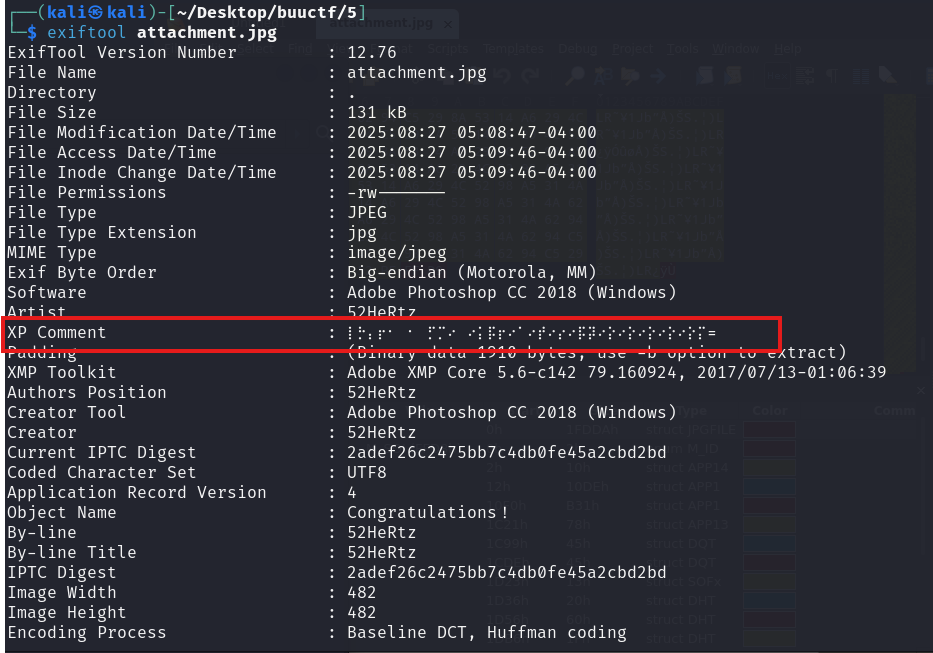
⡇⡓⡄⡖⠂⠀⠂⠀⡋⡉⠔⠀⠔⡅⡯⡖⠔⠁⠔⡞⠔⡔⠔⡯⡽⠔⡕⠔⡕⠔⡕⠔⡕⠔⡕⡍=这个看着很像标准盲文,但是标准盲文是6点的,只能表示数字和字母,这里这个是8点盲文,也叫unicode盲文,它可以用于表示一些符号。这个翻译过去就是flag,可惜我找了很多资料,都没有找到对照表或者工具,看了一些别的大佬写的题目解析,里面的工具都过期失效了,感觉继续耗时间在上面也没有意义,后续如果我找到了会回来填这个坑的。这里直接放上答案,答案是从这位大佬(https://blog.csdn.net/YueXuan_521/article/details/134564840)的文章里拿的。
类型 | 图片隐写、加密算法 |
|---|---|
工具 | exiftool |
Flag | flag{y$0$u_f$1$n$d$_M$e$e$e$e$e} |
6. [GUET-CTF2019]KO
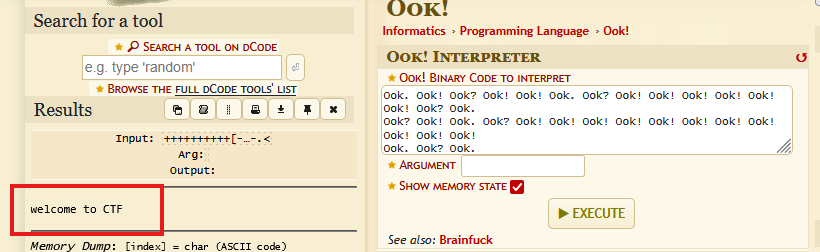
一道简单的签到题,打开题目文件,是一个文本文件,里面是由ook组成的编码。

我们之前遇到过这个编码,直接用在线工具进行解密,结果就是答案。(https://www.dcode.fr/ook-language)
类型 | 加密算法 |
|---|---|
工具 | dcode.fr |
Flag | flag{welcome to CTF} |
7. [ACTF新生赛2020]base64隐写
这里题目已经提示了这道题考察的是base64隐写,注意这里不是base64编码,而是base64隐写。关于base64隐写的原理一两句话讲不清楚,这里不深入了,可以参考这篇文章。我们直接下载题目文件,下载的压缩文件中包含一个文本文件和一个图片,图片是个二维码,指向题目原作者的微信公众号,文本文件内容如下。
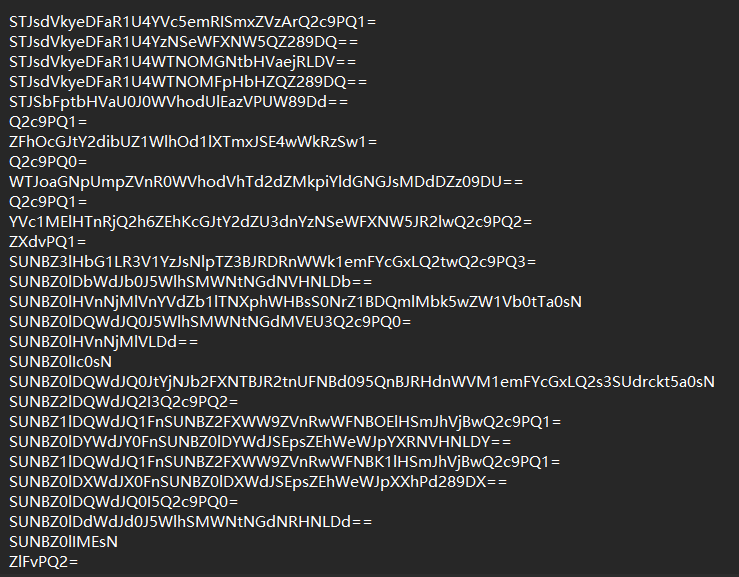
这里我们直接用一个base64隐写解密脚本去跑出答案,这里的input.txt要改为上面的文件名,我这里为了方便改成了input.txt。把python脚本和文本文件放在同一个目录下,就可以得到答案了。
import base64
#coding=utf-8
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
#文件路径
with open('input.txt', 'rb') as f:
flag = ''
bin_str = ''
for line in f.readlines():
stegb64 = str(line, 'utf-8').strip('\n')
rowb64 = str(base64.b64encode(base64.b64decode(stegb64)), 'utf-8').strip('\n')
offset = abs(base64chars.index(stegb64.replace('=', '')[-1]) - base64chars.index(rowb64.replace('=', '')[-1]))
equalnum = stegb64.count('=') # no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
res = [chr(int(bin_str[i:i + 8], 2)) for i in range(0, len(bin_str), 8)]
print(res)

类型 | base64隐写 |
|---|---|
工具 | Python |
Flag | flag{6aseb4_f33!} |
8. 穿越时空的思念
下载题目文件,是一段mp3,直接听听看,发现左右声道明显不同,一边是音乐,另外一边像是摩斯密码,用Audacity打开该音频文件。
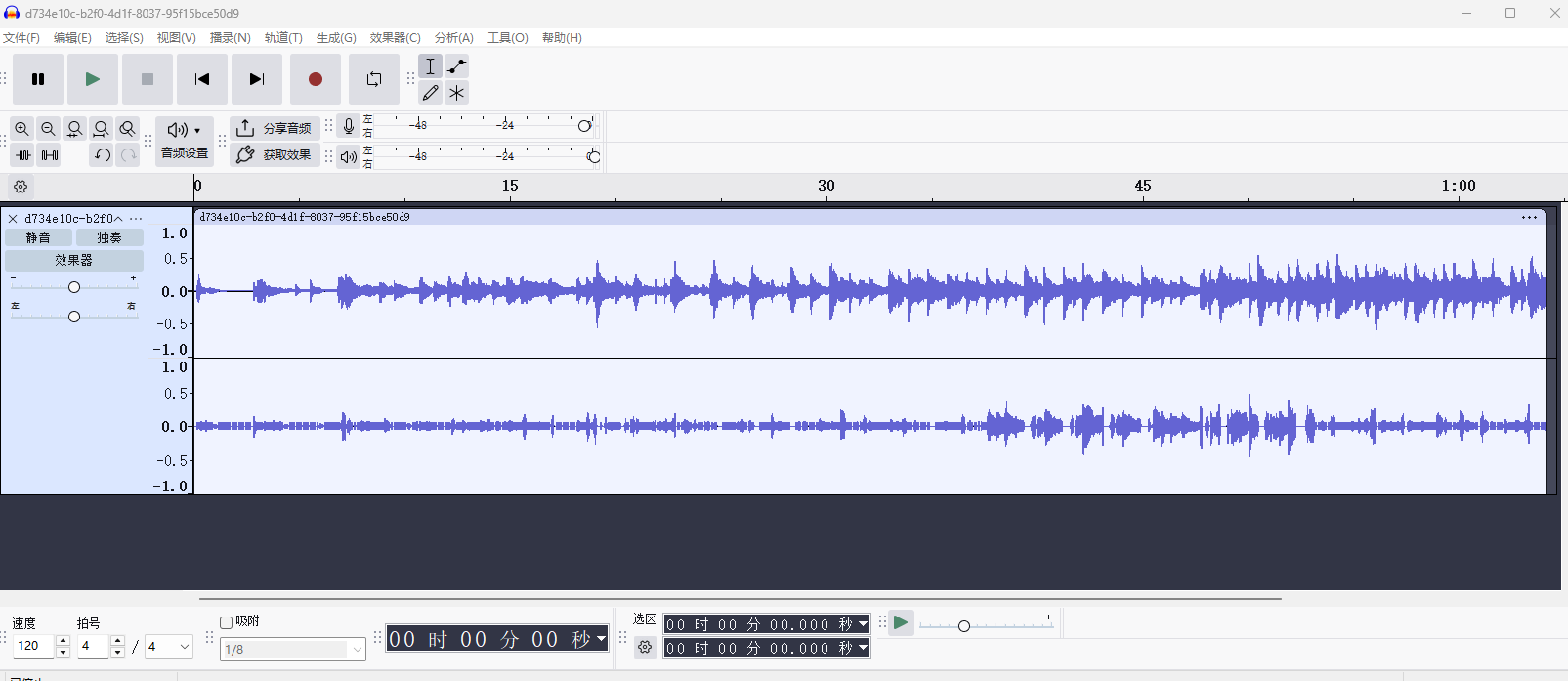
这里显然右边的声道是摩斯密码,我们把声道分离出来。先在轨道左侧选择“分离立体声轨”,然后左侧“x”键删除左声道(上面的声道),最后导出音频文件,得到的就是只有右声道的音频了。
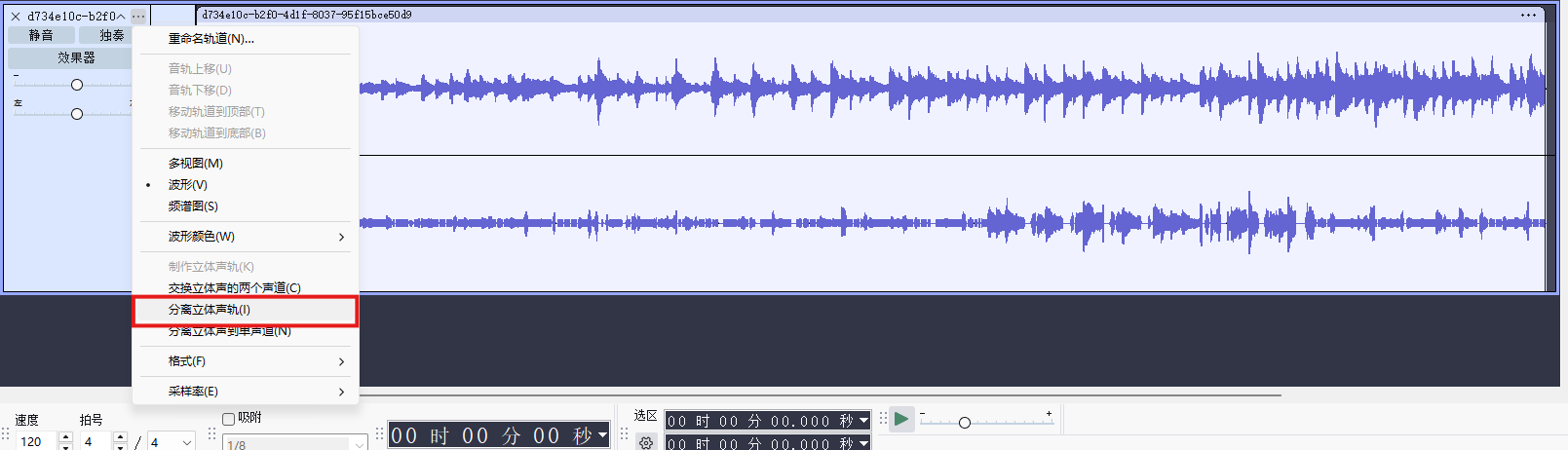
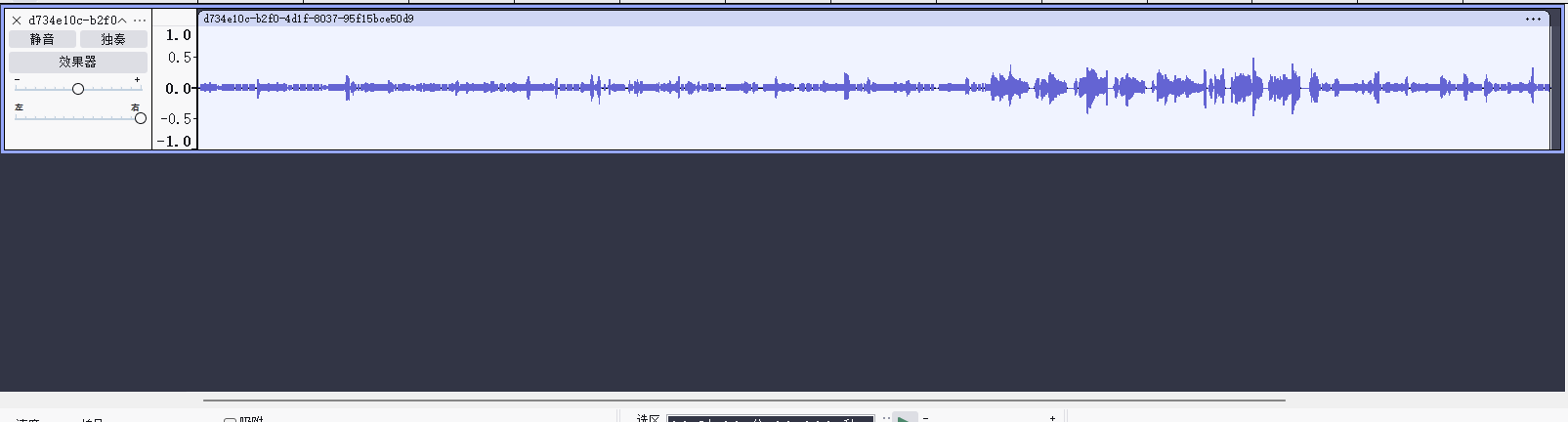
我这里主要想法是,分离出单独的摩斯密码声音轨道,然后用在线工具识别轨道上的摩斯密码,可惜这个音频文件存在杂音,在线工具识别的不够准确,这里只能采用人工识别的方法了,短的是点,长的是线。

中间还有一段纯音乐,我剪掉了,不影响结果判断,最终识别的结果如下:
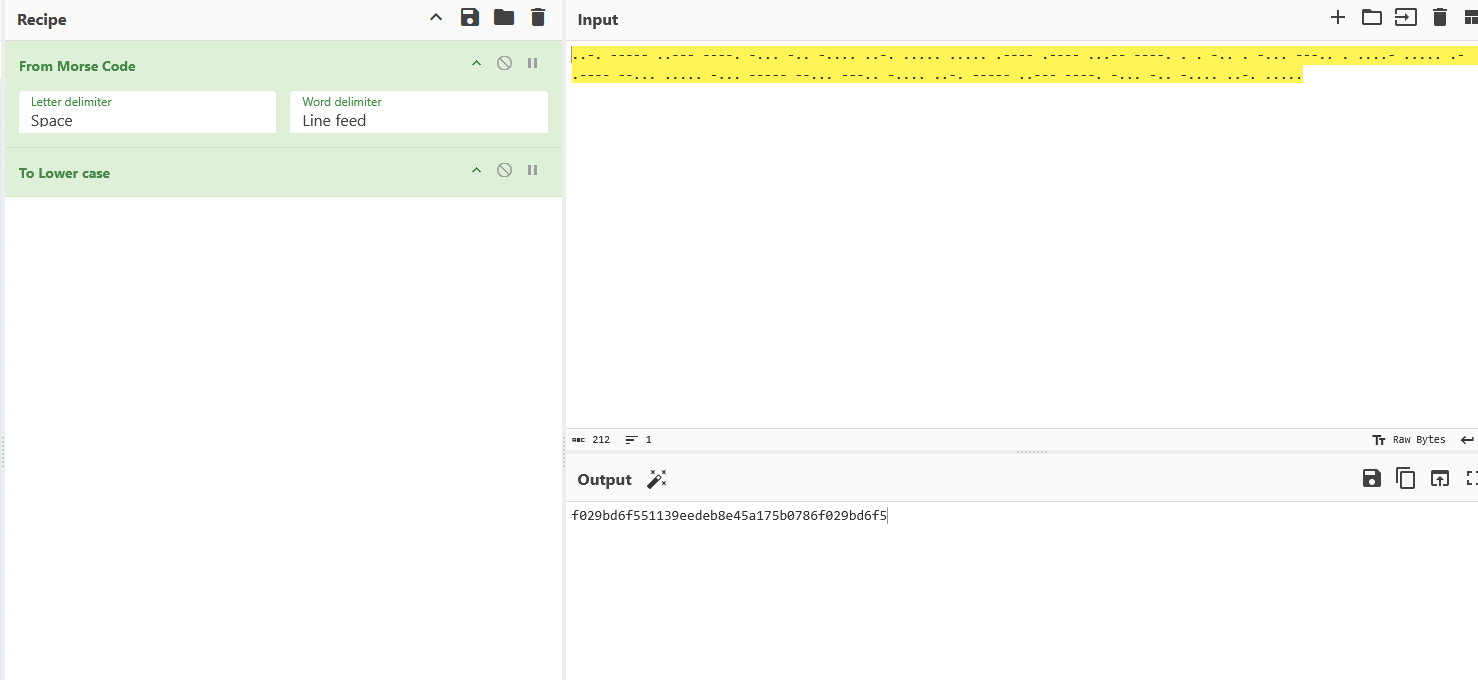
..-. ----- ..--- ----. -... -.. -.... ..-. ..... ..... .---- .---- ...-- ----. . . -.. . -... ---.. . ....- ..... .- .---- --... ..... -... ----- --... ---.. -.... ..-. ----- ..--- ----. -... -.. -.... ..-. .....放进CyberChef解密并小写化处理,得到了一个字符串。题目提示了答案是32位的小写字符,这里数32位后发现后面的位数是重复的,而前面的32位就是我们的答案。
类型 | 音频隐写、加密算法 |
|---|---|
工具 | Audacity、CyberChef |
Flag | flag{f029bd6f551139eedeb8e45a175b0786} |
9. [SWPU2019]我有一只马里奥
下载文件,是一个马里奥图案的exe文件,这里先不急着运行,虽然ctf比赛中出现恶意程序的概率很小,但还是要尽可能小心源头不明的可执行程序。这里先放进随波逐流工具,发现该程序可以binwalk,这里放进kali,binwalk看一下。
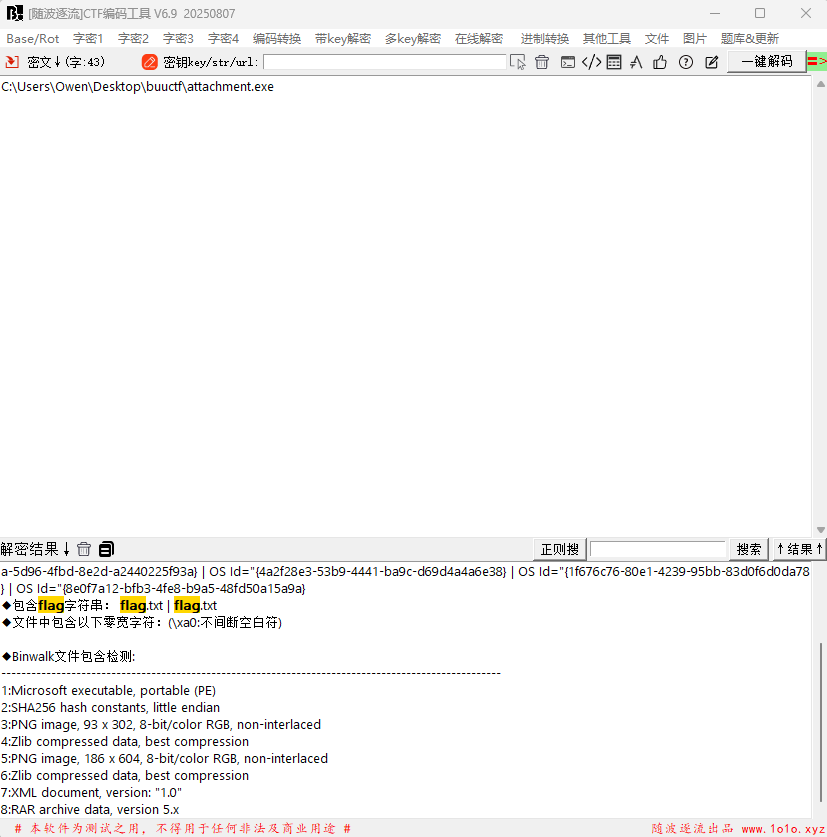
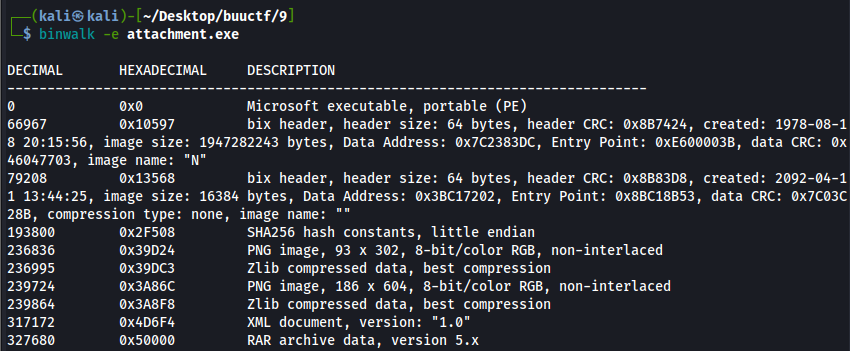
打开后发现只有一个文本文件是可读的,内容如下。
ntfs
flag.txt这里提到了ntfs,并且还有一个名为“flag.txt”的文本文件,很自然想到ntfs隐写。在我们建立NTFS文件时是分为主用数据流和备用数据流的,主用数据流我们可以直接看到,而备用数据流不能直接看到,需要借助一些工具。另外为了防止数据流在传输中被破坏,一般使用WinRAR来对文件夹压缩。所以题目文件本身应该是经过了WinRAR压缩,我们这里把文件后缀改为rar。
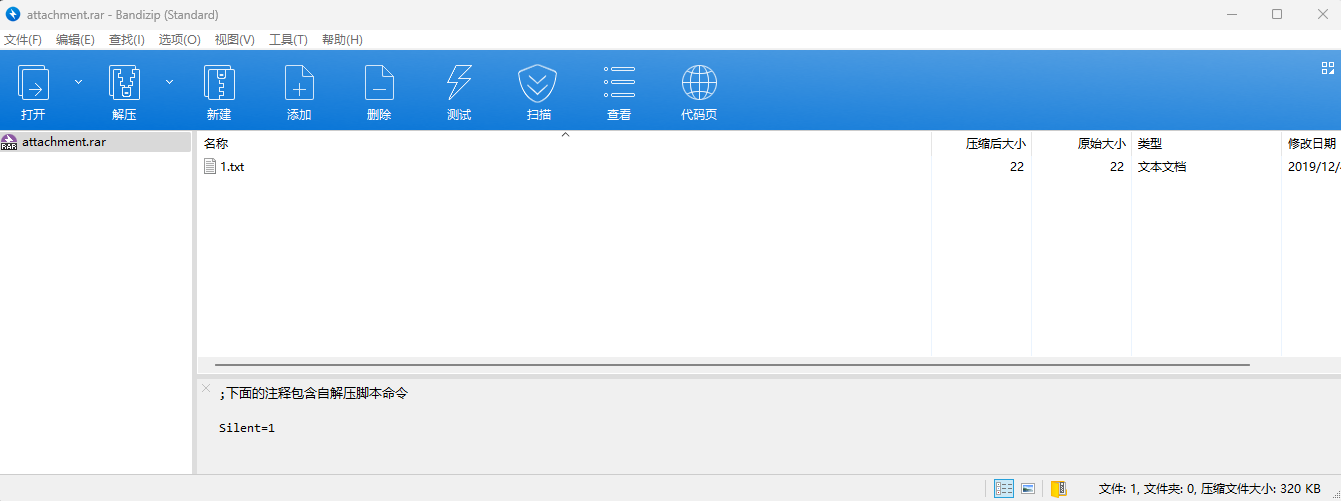
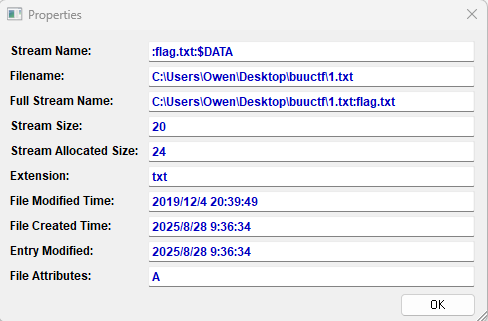
这里需要用到一个查看备用数据流的工具,我这里使用的是AlternateStreamView。把压缩文件中的文本文件提取出来,打开工具并选择文本文件所在路径,就能扫描出该文本文件存在一个备用数据流,名称为“flag.txt”。

这就是我们要的答案,双击打开,复制“Full Stream Name”,打开命令行,并用notepad打开该stream,就能得到我们最终答案了。

类型 | ntfs隐写 |
|---|---|
工具 | 随波逐流工具、binwalk、AlternateStreamView |
Flag | flag{ddg_is_cute} |
10. [MRCTF2020]ezmisc
下载题目文件,放进随波逐流工具里看一下,结果是CRC校验的问题,图片被修改了宽高,关于CRC校验可以参考我上一篇文章,这里随波逐流非常好用,检查到CRC校验问题时会直接对图片原宽高进行爆破,这里也是直接爆破并输出了原图。

类型 | 图片隐写 |
|---|---|
工具 | 随波逐流工具 |
Flag | flag{1ts_vEryyyyyy_ez!} |
11. [GXYCTF2019]gakki
首先下载题目文件,是个png格式的文件,这里直接放进随波逐流工具看一下,发现文件结尾存在其它字符,工具会自动把末尾的字符单独提取出来为一个文本文件。
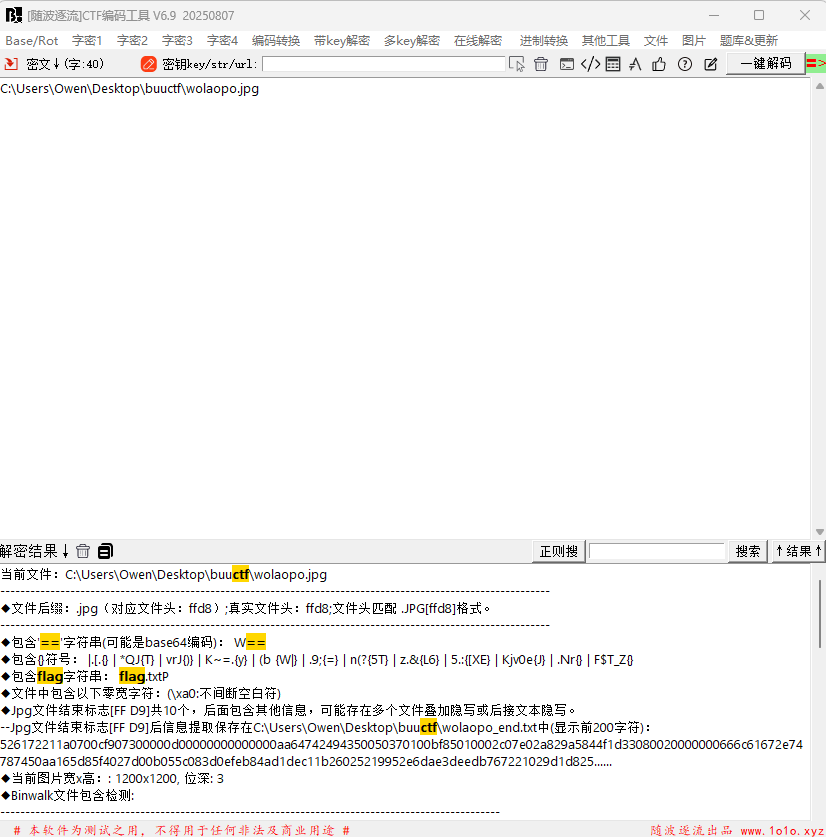
这些字符看上去是16进制的,放进CyberChef,发现原字符是一个压缩文件,这里把数据以压缩文件形式下载下来。
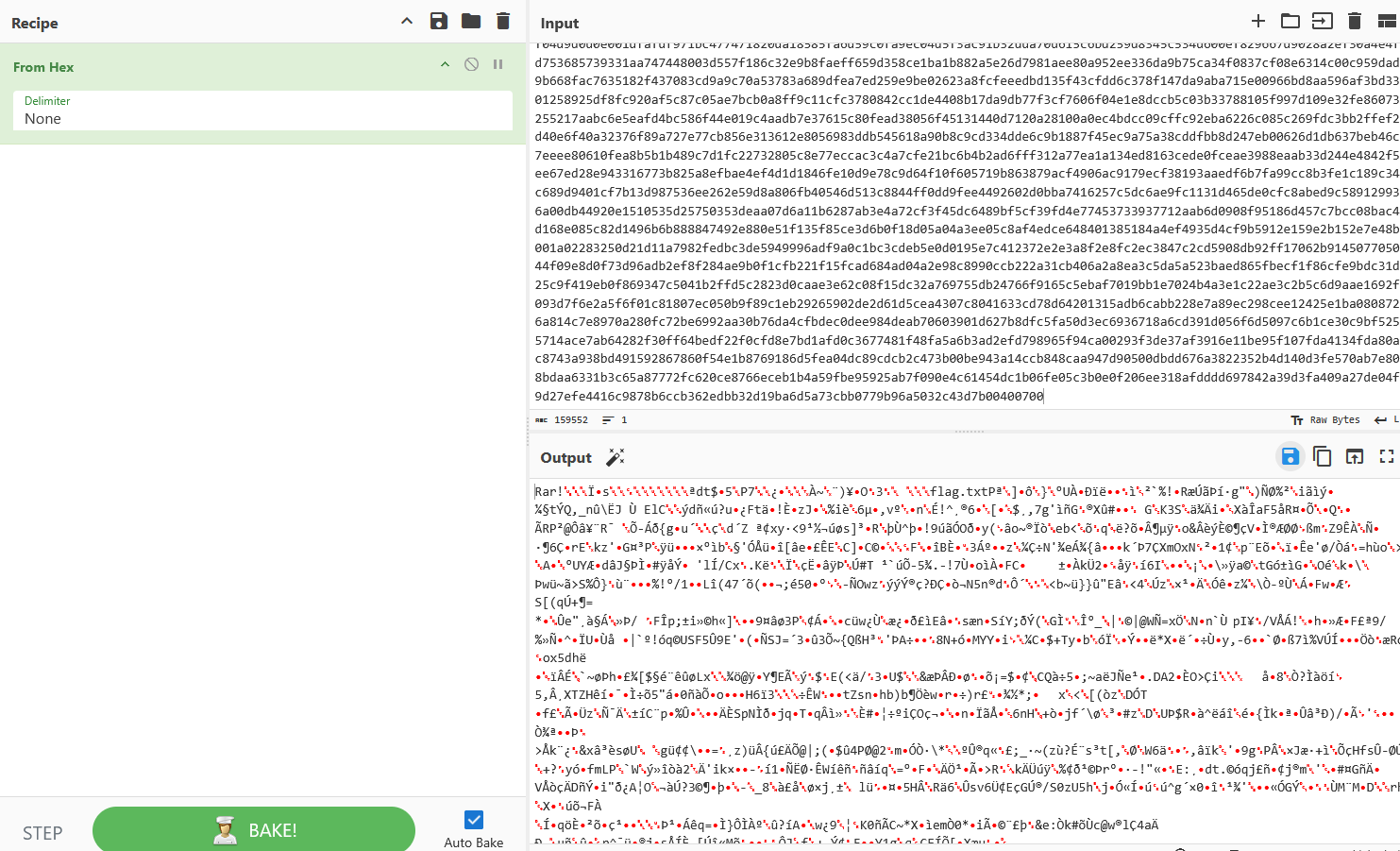
下载后发现该文件加密了,且经过判断不是伪加密,就用ARCHPR遍历四位数字密码爆破压缩文件,最后发现密码为8864。
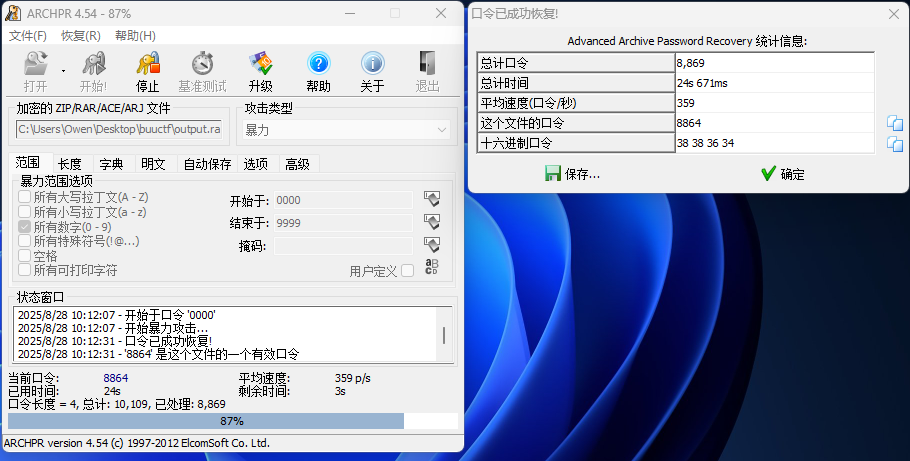
打开文件发现其中的文本文件也是不认识的字符串。这里我走进了一个误区,但最后歪打正着也拿到答案了。首先,我遇到不认识的字符以为是没有见过的加密或者编码方式,就放进decode.dr在线工具分析,结果发现还真有一种加密方式的密文和这个很像,结果发现解密后是乱码,这一步就pass了。
后面我想着也许是用了替代加密,比如a统一换成c,b统一换成e。替代加密最好的解法就是看字母出现频率,因为当文本数据量庞大时,字母的出现频率会接近一个特定比例,比如e的频率是最高的等等。这里我用的频率计算工具是这个在线网站(https://www.browserling.com/tools/letter-frequency)。结果发现答案就在频率字符的依次排序中,高频的字符按照顺序依次排列就是答案。
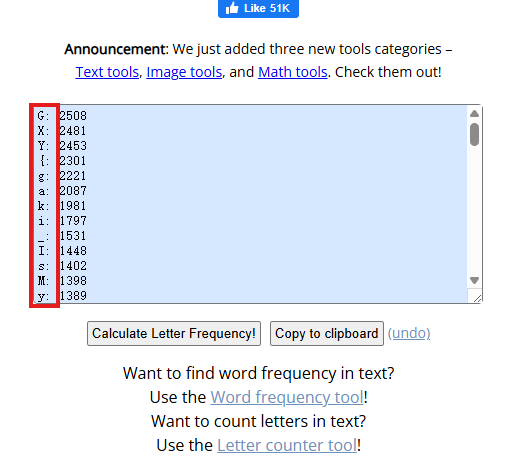
类型 | 图片隐写、压缩文件密码爆破、字符频率 |
|---|---|
工具 | 随波逐流工具、CyberChef、ARCHPR、letter-frequency在线工具 |
Flag | flag{gaki_IsMyw1fe} |
12. [HBNIS2018]caesar
看题目就知道是要考察凯撒密码,这是一种简单的移位加密方式。题目文件就是一串加密后的字符串,“gmbhjtdbftbs”。这里用在线工具枚举解密,这里不知道偏移量只能枚举。枚举后看结果哪一个更像flag,一般就找有语义的,这里就是“flag is caesar”。

类型 | 加密算法 |
|---|---|
工具 | 在线工具 |
Flag | flag{flagiscaesar} |
不知道大家有没有感觉到,这一次12道题好像编码、加密的内容比较多,加密解密和编码解码在Misc中占据很大部分,有时候遇到完全没遇到过的编码往往要花费大量时间去寻找解码方式,所以事先多积累不同种编码格式很重要,当然临场遇到不会的还能使用伟大的搜索引擎或者ai大模型直接对编码字符搜索,有时候有奇效。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号