系列终章:Flume 部署 DebeziumMySQLSource 云服务器实战总结
原创
系列终章:Flume 部署 DebeziumMySQLSource 云服务器实战总结
原创
叫我阿柒啊
发布于 2025-07-26 15:42:26
发布于 2025-07-26 15:42:26
前言
在上一篇 使用 Flume 封装 Debezium 采集 MySQL 文章中,我们结合 Flume Source 实现了配置化的 Debezium 采集程序。那么,如何实现配置化、部署?到底是否可以简化我们的工作,体现在哪里?这是大家更为关心的问题。所以本篇文章就通过实际操作来解答这些问题。
程序使用 JDK17,同时已经安装 MySQL 和 Kafka,如果想要跟着实操,可以参考我之前的博客MySQL Binlog 实时同步 Kafka:Debezium 实战笔记,几分钟搭建一个单节点的 Kafka。
Flume 开发
这里的开发其实就是编写两个文件,一个 conf 配置文件和一个 shell 启动脚本。
环境准备
首先我们从 Flume 官网下载安装包。
wget https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz
tar zxvf apache-flume-1.11.0-bin.tar.gz
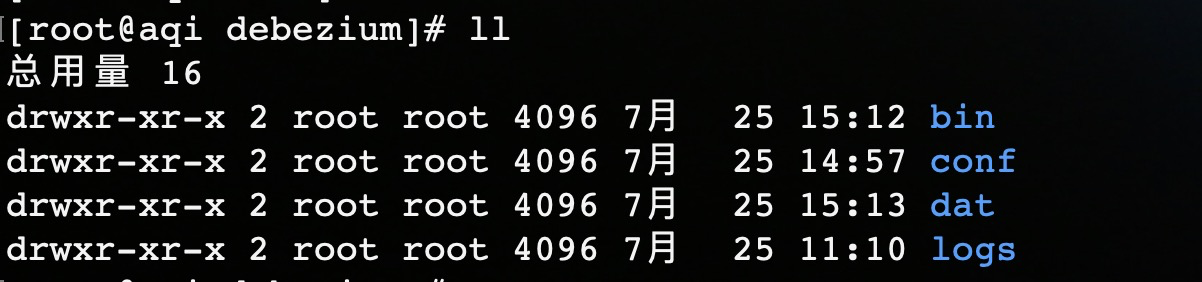
mv apache-flume-1.11.0-bin flume-1.11.0下载解压,改个名字,这样就 ok 了。通常,我个人习惯就是会重新创建一个新目录,来写 flume 的配置文件,这里创建了一个 debezium 目录,其中创建了四个目录,bin 存放启动脚本,conf 是配置文件,dat 用来存放 offset.dat 和 schema-history.dat,logs 存放日志。
配置开发
然后就是开始写 Flume 的配置文件。配置文件主要氛围三个部分:Source、Channel、Sink,在这个配置中,Channel 和 Sink 都是 Flume 自带的,使用 Memory Channel 和 Kafka Sink 就可以了,我们只需要在配置 Source 的时候,指定为 DebeziumSource 就可以了。
在 conf 目录下开发 debezium_test.conf。
debezium_test.sources = s1
debezium_test.channels = c1
debezium_test.sinks = s1
# 配置 Debezium MySQL Source
debezium_test.sources.s1.type = source.DebeziumMySQLSource
debezium_test.sources.s1.mysql.host = 127.0.0.1
debezium_test.sources.s1.mysql.port = 3306
debezium_test.sources.s1.mysql.user = root
debezium_test.sources.s1.mysql.password = 123456
debezium_test.sources.s1.mysql.table = debezium.test
debezium_test.sources.s1.mysql.offsetPath = /root/app/debezium/dat/test_offset.dat
debezium_test.sources.s1.mysql.schemaHistoryPath = /root/app/debezium/dat/test_schema-history.dat
# channel
debezium_test.channels.c1.type = memory
debezium_test.channels.c1.capacity = 1000
debezium_test.channels.c1.transactionCapacity = 100
# Kafka Sink
debezium_test.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink
debezium_test.sinks.s1.kafka.bootstrap.servers = 127.0.0.1:9092
debezium_test.sinks.s1.kafka.topic = aqi
debezium_test.sinks.s1.serializer.class = org.apache.flume.sink.kafka.KafkaEventSerializer
debezium_test.sinks.s1.kafka.producer.acks = 1
debezium_test.sinks.s1.kafka.producer.linger.ms = 100
# 绑定 channel
debezium_test.sources.s1.channels = c1
debezium_test.sinks.s1.channel = c1上面就是 debezium 采集 MySQL 的 debezium.test 表的程序,可以把它当做一个标准化模版,如果你想新增一个表的采集,你就复制一个并修改其中的 table 和 topic 就可以了,反正想改什么改什么。
启动脚本
然后就是在 bin 目录下编写脚本启动程序脚本 debezium_test.sh。
#!/bin/bash
export FLUME_HOME=/root/app/flume-1.11.0
export PATH=$PATH:$FLUME_HOME/bin
nohup flume-ng agent -Xms512m -Xmx1024m \
--conf conf \
--conf-file /root/app/debezium/conf/debezium_test.conf \
--name debezium_test \
-Dflume.root.logger=INFO,console \
> /root/app/debezium/logs/debezium_test.log 2>&1 但是在启动之前,我们是不是忘了应该 把 DebeziumMySQLSource 放入 Flume 中,所以我们下一步要做的是打包程序。
程序部署
目标:将我们实现的 DebeziumSource 部署到云服务器上。
这里可得好好说一下了,本来我想着这个程序不就 debezium-api、debezium-embedded、debezium-connector-mysql 三个依赖吗,我寻思放到 Flume 的 lib 下就行了啊,结果疯狂报错 ClassNotFoundException。
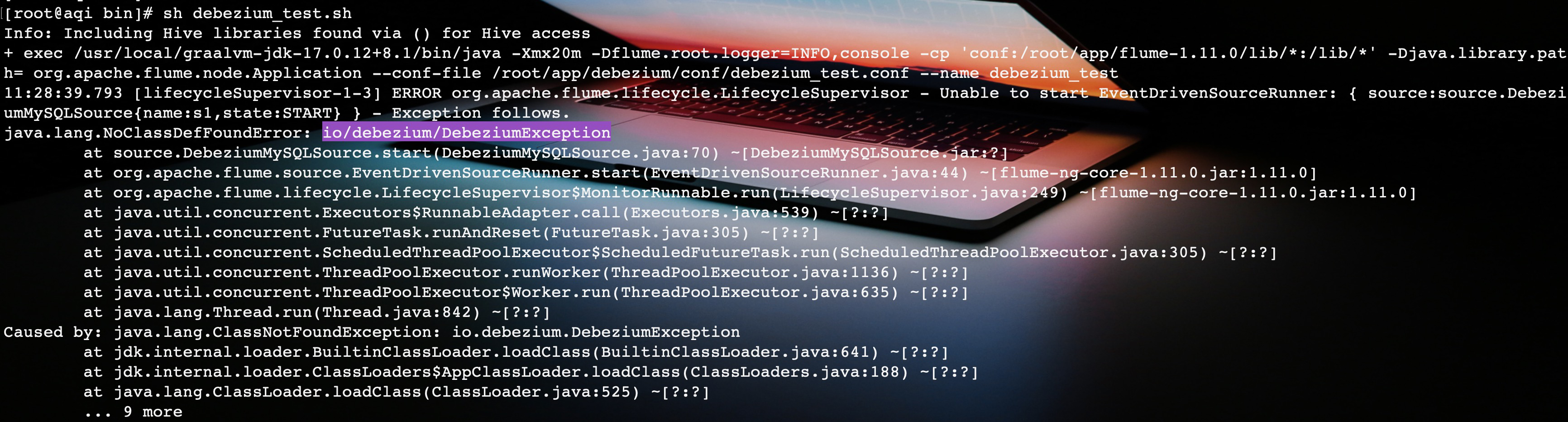
程序打包
刚开始的时候,我还很有耐心的将缺少的 debezium-common、debezium-core 这些类,从本地 maven 仓库上传到服务器上的 Flume lib 目录,本以为可以用耐心换真心,可最终换来的却是变本加厉。

最后 ClassNotFound 就更猖獗了。

这样下去不知道何年何月,于是我就索性将所有依赖直接打入jar包中,在 pom 中添加插件:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.5.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
</execution>
</executions>
</plugin>这样 package 就会生成两个 jar 包,我们只需要将名字中不带 original 的jar上传到 flume 的 lib 目录下即可,大约39MB。下次如果新增一个 Source 或者其他程序的话,就可以只上传不含依赖的 original 包了。
依赖冲突
然后启动程序,结果又是一个报错:com/fasterxml/jackson/databind/util/NativeImageUtil。

这个问题应该是缺失jackson-databind 或 jackson-core 依赖,或者依赖冲突导致的,我们去 Flume 的 lib 目录下查看相关的类,这里的 jackson 使用的2.13.2版本。

我们在程序中分析依赖冲突,发现 flume-core 和 debezium 确实存在关于 jackson 的冲突,一个是2.12,一个是2.16。
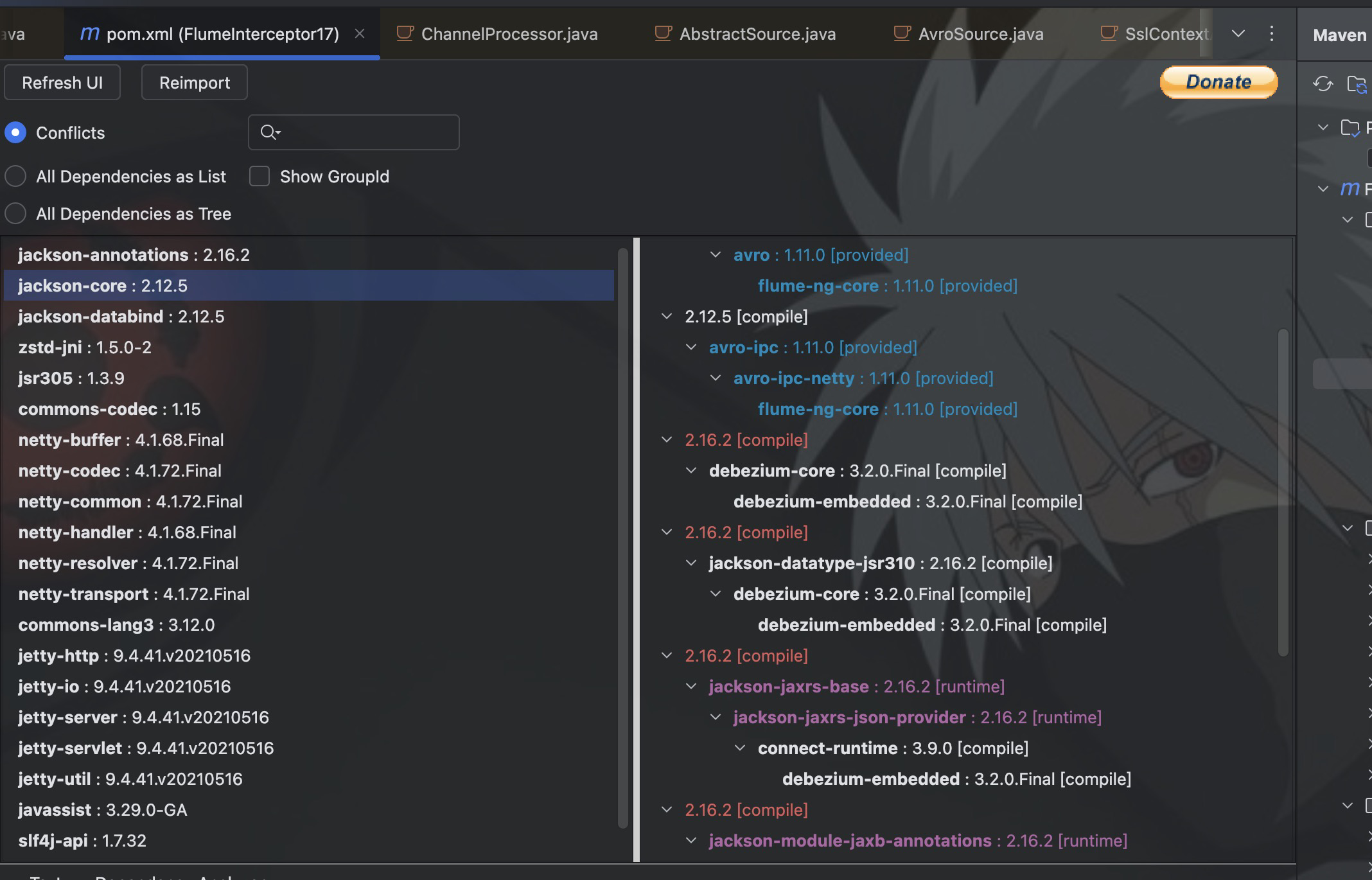
我们直接在 pom 中,指定 jackson 为2.16版本,然后就会被打入 jar 中。
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.16.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.16.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-afterburner</artifactId>
<version>2.16.2</version>
</dependency>然后重新上传就好了。
OOM
在解决了依赖冲突的问题之后,启动时又出现了 OOM 的问题,可以看到 flume-ng 的默认启动内存(Xmx)是20MB。
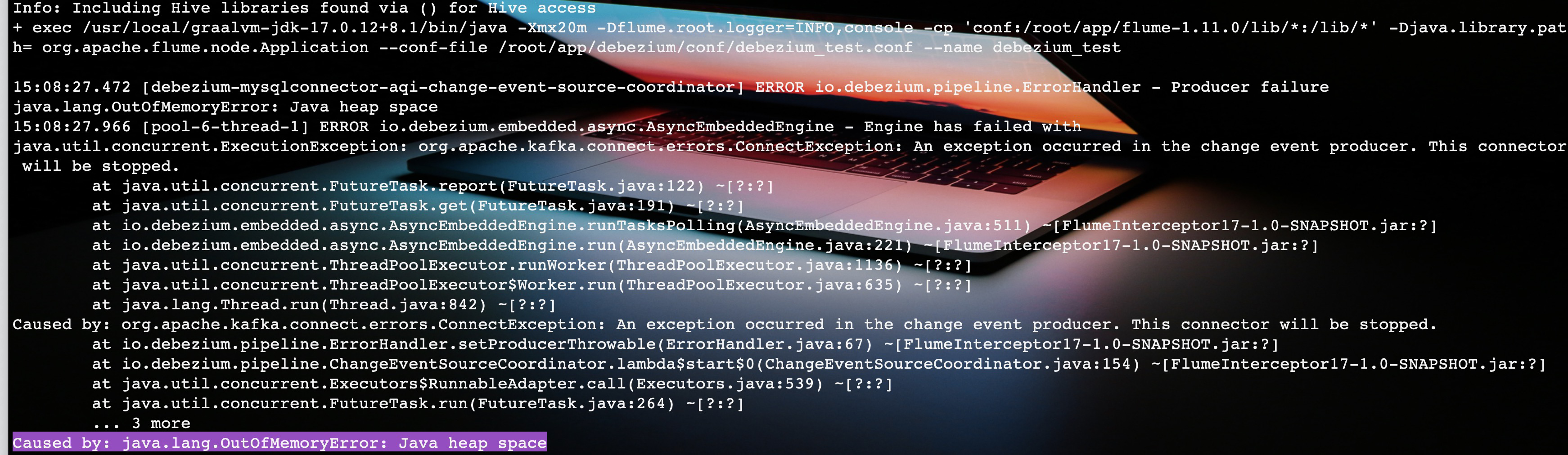
所以在上面的启动脚本中,我添加了 Xms、Xmx 启动参数,将启动内存增加到 512 MB,至此,程序启动成功。
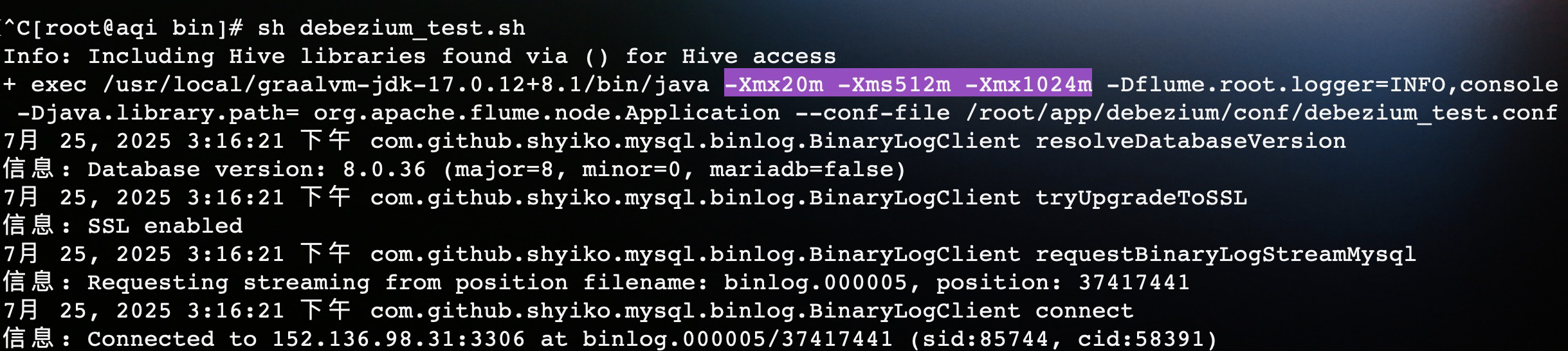
这里顺便提一下,因为我的云服务器只有2G的内存,其他应用占用了1G。当我启动程序之后,服务器就直接卡死了,所以我增加了16G的 swap 就解决了这个问题。
采集测试
首先我们启动消费 Kafka。
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic aqi在程序启动之后,我们可以看到先进行了全量采集,在 Source 开发的时候,也可以把是否全量采集也作为一个参数设置,来满足只需要增量采集的场景。

在 MySQL 中执行了几个 insert 语句,看到了新采集的变更数据写入了 Kafka。
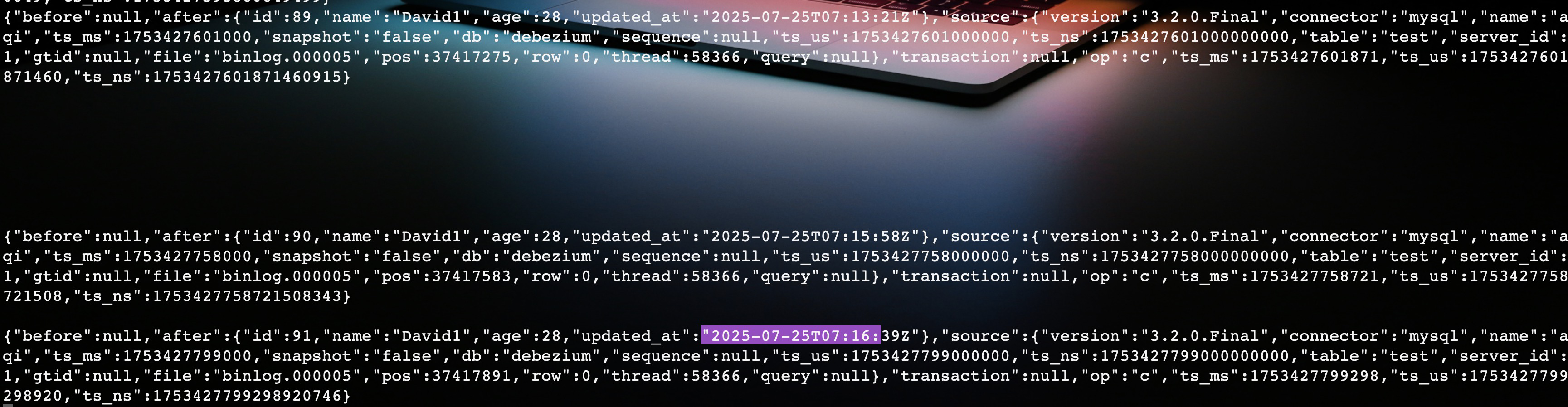
程序的 offset 也成功写入了 dat 目录。

结语
作为S14赛季的最后一篇文章,也是 Debezium 系列的完结篇,成功从最初的学习理论,通过实战应用到了生产。本篇文章主要列举了在 Debezium 部署的时候遇到的各种各样的问题以及解决方法,期待能给你带来一些收获。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号