YOLOv13改进:卷积魔改 | DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,助力检测
原创
YOLOv13改进:卷积魔改 | DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,助力检测
原创
AI小怪兽
修改于 2025-07-18 13:15:49
修改于 2025-07-18 13:15:49
💡💡💡本文独家改进:DCNv4更快收敛、更高速度、更高性能,完美和YOLOv13结合,助力涨点
DCNv4优势:(1) 去除空间聚合中的softmax归一化,以增强其动态性和表达能力;(2) 优化存储器访问以最小化冗余操作以加速。这些改进显著加快了收敛速度,并大幅提高了处理速度,DCNv 4实现了三倍以上的前向速度。
💡💡💡如何跟YOLOv13结合:1)和C3k2创新性结合
《YOLOv13魔术师专栏》将从以下各个方向进行创新:
链接:
【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【小目标性能提升】【前沿论文分享】【训练实战篇】
订阅者通过添加WX: AI_CV_0624,入群沟通,提供改进结构图等一系列定制化服务。
定期向订阅者提供源码工程,配合博客使用。
订阅者可以申请发票,便于报销
💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、25年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏原价299,越早订阅越划算⭐⭐⭐
💡💡💡 2025年计算机视觉顶会创新点适用于YOLOv12、YOLO11、YOLOv10、YOLOv8等各个YOLO系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
1.YOLOv13介绍

论文:[2506.17733] YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception
摘要—YOLO 系列模型因其卓越的准确性和计算效率在实时目标检测领域占据主导地位。然而,无论是 YOLO11 及更早版本的卷积架构,还是 YOLOv12 引入的基于区域的自注意力机制,都仅限于局部信息聚合和成对相关性建模,缺乏捕捉全局多对多高阶相关性的能力,这限制了在复杂场景下的检测性能。本文提出了一种准确且轻量化的 YOLOv13 目标检测器。为应对上述挑战,我们提出了一种基于超图的自适应相关性增强(HyperACE)机制,通过超图计算自适应地利用潜在的高阶相关性,克服了以往方法仅基于成对相关性建模的限制,实现了高效的全局跨位置和跨尺度特征融合与增强。随后,我们基于 HyperACE 提出了全链路聚合与分配(FullPAD)范式,通过将相关性增强特征分配到整个网络,有效实现了全网的细粒度信息流和表征协同。最后,我们提出用深度可分离卷积代替常规的大核卷积,并设计了一系列块结构,在不牺牲性能的前提下显著降低了参数量和计算复杂度。我们在广泛使用的 MS COCO 基准测试上进行了大量实验,结果表明,我们的方法在参数更少、浮点运算量更少的情况下达到了最先进性能。具体而言,我们的 YOLOv13-N 相比 YOLO11-N 提升了 3.0% 的 mAP,相比 YOLOv12-N 提升了 1.5% 的 mAP。

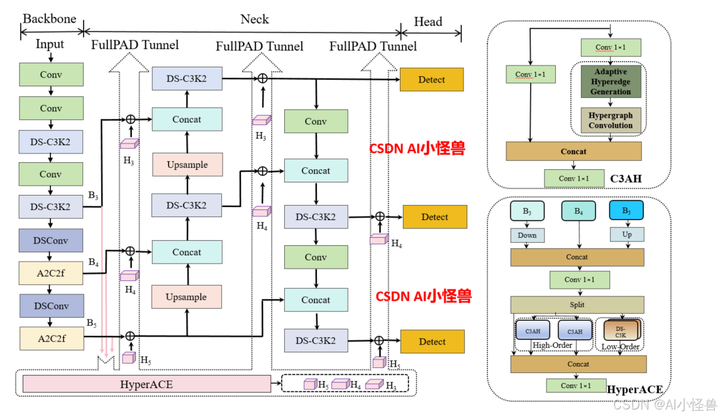
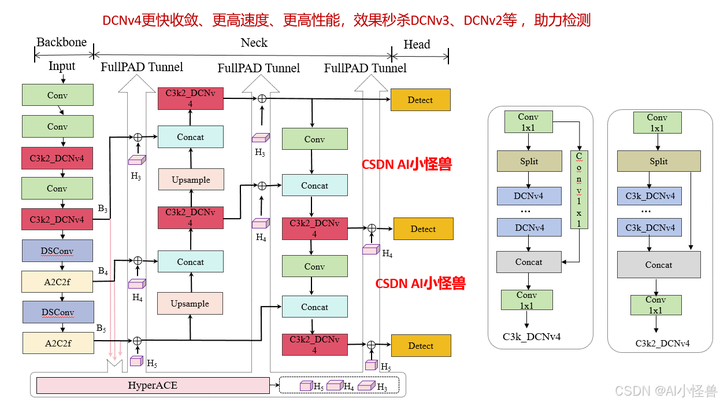
以往的 YOLO 系列遵循 “骨干网络 → 颈部网络 → 检测头” 的计算范式,这本质上限定了信息流的充分传输。相比之下,我们的模型通过超图自适应关联增强(HyperACE)机制,实现全链路特征聚合与分配(FullPAD),从而增强传统的 YOLO 架构。因此,我们提出的方法在整个网络中实现了细粒度的信息流和表征协同,能够改善梯度传播并显著提升检测性能。具体而言,如图 2 所示,我们的 YOLOv13 模型首先使用类似以往工作的骨干网络提取多尺度特征图 B1、B2、B3、B4、B5,但其中的大核卷积被我们提出的轻量化 DS-C3k2 模块取代。然后,与传统 YOLO 方法直接将 B3、B4 和 B5 输入颈部网络不同,我们的方法将这些特征收集并传递到提出的 HyperACE 模块中,实现跨尺度跨位置特征的高阶关联自适应建模和特征增强。随后,我们的 FullPAD 范式利用三个独立通道,将关联增强后的特征分别分配到骨干网络与颈部网络的连接处、颈部网络的内部层以及颈部网络与检测头的连接处,以优化信息流。最后,颈部网络的输出特征图被传递到检测头中,实现多尺度目标检测。
ultralytics/cfg/models/v13/yolov13.yaml
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov13n.yaml' will call yolov13.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # Nano
s: [0.50, 0.50, 1024] # Small
l: [1.00, 1.00, 512] # Large
x: [1.00, 1.50, 512] # Extra Large
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2, 1, 2]] # 1-P2/4
- [-1, 2, DSC3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2, 1, 4]] # 3-P3/8
- [-1, 2, DSC3k2, [512, False, 0.25]]
- [-1, 1, DSConv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, DSConv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
head:
- [[4, 6, 8], 2, HyperACE, [512, 8, True, True, 0.5, 1, "both"]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [ 9, 1, DownsampleConv, []]
- [[6, 9], 1, FullPAD_Tunnel, []] #12
- [[4, 10], 1, FullPAD_Tunnel, []] #13
- [[8, 11], 1, FullPAD_Tunnel, []] #14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 12], 1, Concat, [1]] # cat backbone P4
- [-1, 2, DSC3k2, [512, True]] # 17
- [[-1, 9], 1, FullPAD_Tunnel, []] #18
- [17, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 13], 1, Concat, [1]] # cat backbone P3
- [-1, 2, DSC3k2, [256, True]] # 21
- [10, 1, Conv, [256, 1, 1]]
- [[21, 22], 1, FullPAD_Tunnel, []] #23
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 18], 1, Concat, [1]] # cat head P4
- [-1, 2, DSC3k2, [512, True]] # 26
- [[-1, 9], 1, FullPAD_Tunnel, []]
- [26, 1, Conv, [512, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P5
- [-1, 2, DSC3k2, [1024,True]] # 30 (P5/32-large)
- [[-1, 11], 1, FullPAD_Tunnel, []]
- [[23, 27, 31], 1, Detect, [nc]] # Detect(P3, P4, P5)1.1 HyperACE
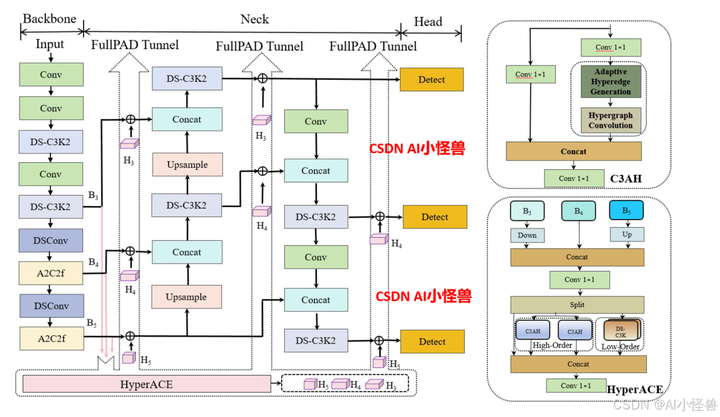
超图自适应相关性增强机制 HyperACE
- 超图理论借鉴与创新 :借鉴超图理论,将多尺度特征图的像素视为超图顶点,不同的是,传统超图方法依赖手工设定参数构建超边,而 HyperACE 设计了可学习的超边生成模块,能自适应地学习并构建超边,动态探索不同特征顶点间的潜在关联。
- 超图卷积操作 :在生成自适应超边后,通过超图卷积操作进行特征聚合与增强。每条超边先从其连接的所有顶点处聚合信息形成高阶特征,再将这些高阶特征传播回各个顶点,更新与增强顶点特征,从而实现高效地跨位置和跨尺度的特征融合与增强,强化不同尺度特征间的语义关联,对小目标和密集目标检测效果显著。
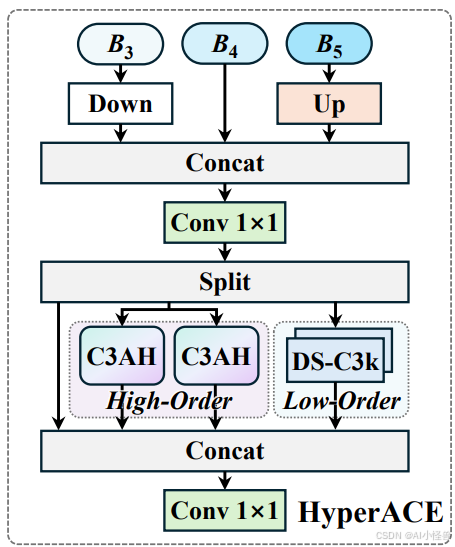
代码位置ultralytics/nn/modules/block.py
1.2 FullPAD_Tunnel
全流程聚合 - 分发范式 FullPAD
- 多通道特征传递 :打破传统的 “骨干→颈部→头部” 单向计算范式,通过三条独立通路传递特征,即主干 - 颈部连接层、颈部内部层、颈部 - 头部连接层,将 HyperACE 聚合后的多尺度特征,通过这些 “隧道” 分发回网络的不同位置,实现细粒度信息流与全流程表征协同。
- 改善梯度传播 :该范式有效解决了梯度消失或爆炸问题,显着改善了梯度传播效率,从而提升模型整体的检测性能,使模型在复杂场景下能够更好地捕捉目标特征,提高检测的准确性和稳定性。

代码位置ultralytics/nn/modules/block.py
1.3 DSC3k2
基于深度可分离卷积的轻量化模块
- 模块创新与替代 :采用深度可分离卷积构建了 DSConv、DS-Bottleneck、DS-C3k 等模块,替代传统的大核卷积。例如使用 DS-C3k2 模块作为轻量化的骨干网络提取多尺度特征,在保持感受野的同时,大幅降低了参数量与计算量,提高了模型的计算效率。
- 性能与效率平衡 :在几乎不牺牲性能的前提下,显著减少了模型的参数量和计算复杂度,使得 YOLOv13 能够在保持较高检测精度的同时,具备更快的推理速度,适合实时目标检测应用场景,降低了模型的部署难度和资源消耗。
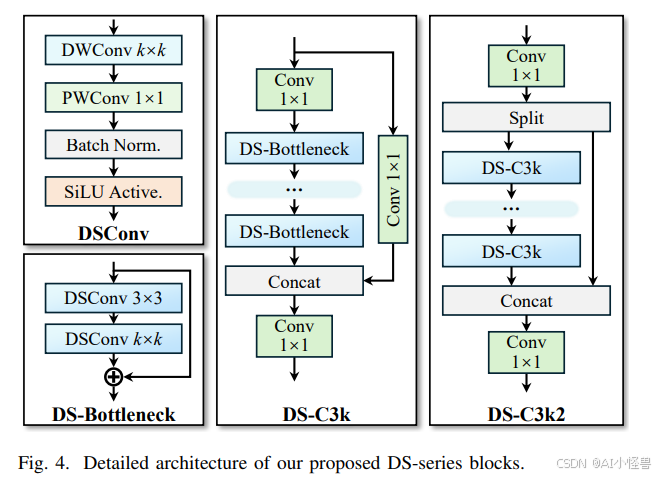
代码位置ultralytics/nn/modules/block.py
2.DCNv4介绍

论文: https://arxiv.org/pdf/2401.06197.pdf
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
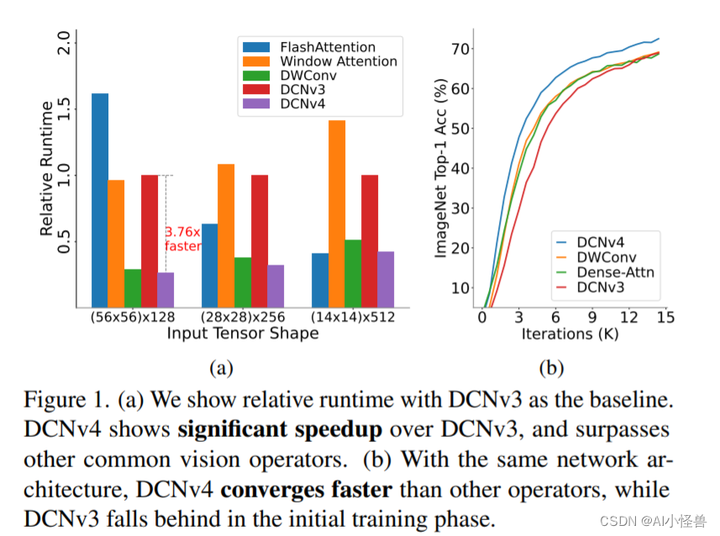
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。
为了克服这些挑战,我们提出了可变形卷积v4 (DCNv4),这是一种创新的进步,用于优化稀疏DCN算子的实际效率。DCNv4具有更快的实现速度和改进的操作符设计,以增强其性能,我们将详细说明如下: 首先,我们对现有实现进行指令级内核分析,发现DCNv3已经是轻量级的。计算成本不到1%,而内存访问成本为99%。这促使我们重新审视运算符实现,并发现DCN转发过程中的许多内存访问是冗余的,因此可以进行优化,从而实现更快的DCNv4实现。 其次,从卷积的无界权值范围中得到启发,我们发现在DCNv3中,密集关注下的标准操作——空间聚合中的softmax归一化是不必要的,因为它不要求算子对每个位置都有专用的聚合窗口。直观地说,softmax将有界的0 ~ 1值范围放在权重上,并将限制聚合权重的表达能力。这一见解使我们消除了DCNv4中的softmax,增强了其动态特性并提高了其性能。 因此,DCNv4不仅收敛速度明显快于DCNv3,而且正向速度提高了3倍以上。这一改进使DCNv4能够充分利用其稀疏特性,成为最快的通用核心视觉算子之一。
我们进一步将InternImage中的DCNv3替换为DCNv4,创建FlashInternImage。值得注意的是,与InternImage相比,FlashInternImage在没有任何额外修改的情况下实现了50 ~ 80%的速度提升。这一增强定位FlashInternImage作为最快的现代视觉骨干网络之一,同时保持卓越的性能。在DCNv4的帮助下,FlashInternImage显著提高了ImageNet分类[10]和迁移学习设置的收敛速度,并进一步提高了下游任务的性能。
图2。(a)注意力(Attention)和(b) DCNv3使用有限的(范围从0 ~ 1)动态权值来聚合空间特征,而注意力的窗口(采样点集)是相同的,DCNv3为每个位置使用专用的窗口。(c)卷积对于聚合权值具有更灵活的无界值范围,并为每个位置使用专用滑动窗口,但窗口形状和聚合权值是与输入无关的。(d) DCNv4结合两者的优点,采用自适应聚合窗口和无界值范围的动态聚合权值。
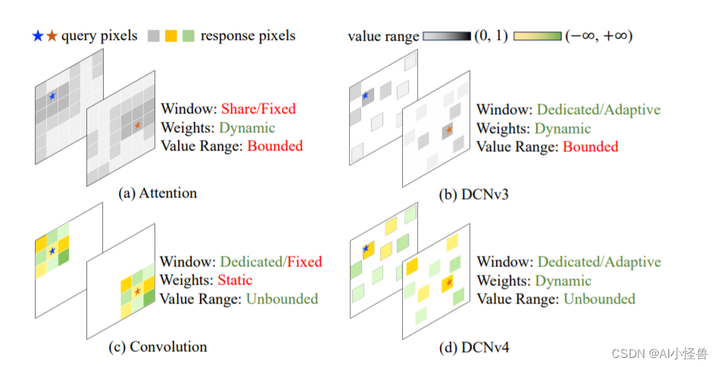
图3。说明我们的优化。在DCNv4中,我们使用一个线程来处理同一组中的多个通道,这些通道共享采样偏移量和聚合权重。可以减少内存读取和双线性插值系数计算等工作负载,并且可以合并多个内存访问指令。
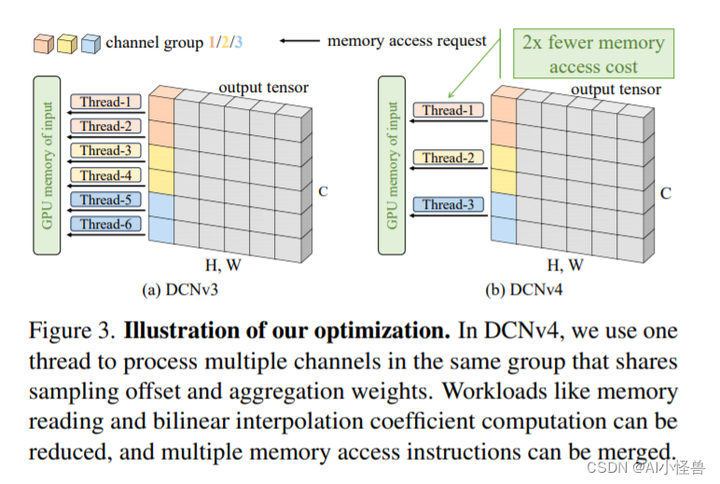
表2。具有各种下采样率的标准输入形状的运算级基准。当实现可用时报告FP32/FP16结果。在不同的输入分辨率下,我们的DCNv4可以超越所有其他常用运算符。
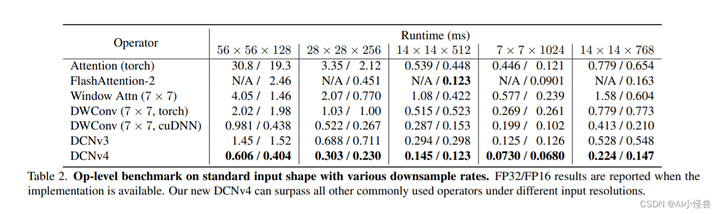
表3。具有各种下采样率的高分辨率输入形状的运算级基准。DCNv4作为稀疏算子表现良好,优于所有其他基线,而密集的全局关注在这种情况下速度较慢。
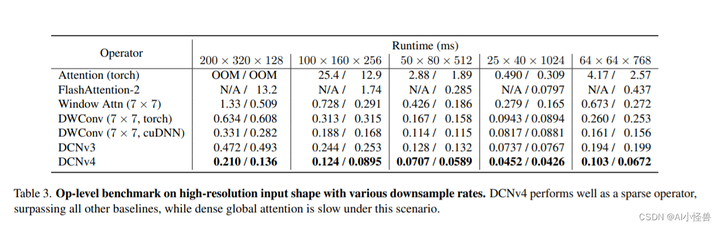
表4。ImageNet-1K上的图像分类性能。我们展示了FlashInternImage w/ DCNv4和它的InternImage对应版本之间的相对加速。DCNv4显着提高了速度,同时显示了最先进的性能。
2.如何将DCNV4将入到YOLOv13
3.1 源码下载
将 DCNv4_op文件夹放入ultralytics\nn目录下
3.2 编译DCNv4
在DCNv4_op文件夹下执行以下命令:
python setup.py build install编译通过

3.3 新建ultralytics/nn/Conv/dcnv4.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules.conv import Conv,autopad
from ultralytics.nn.modules.block import Bottleneck, C2f,C3k
try:
from DCNv4.modules.dcnv4 import DCNv4
except ImportError as e:
pass
class DCNV4_YOLO(nn.Module):
def __init__(self, inc, ouc, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
if inc != ouc:
self.stem_conv = Conv(inc, ouc, k=1)
self.dcnv4 = DCNv4(ouc, kernel_size=k, stride=s, pad=autopad(k, p, d), group=g, dilation=d)
self.bn = nn.BatchNorm2d(ouc)
self.act = Conv.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
if hasattr(self, 'stem_conv'):
x = self.stem_conv(x)
x = self.dcnv4(x, (x.size(2), x.size(3)))
x = self.act(self.bn(x))
return x
class Bottleneck_DCNV4(Bottleneck):
"""Standard bottleneck with DCNV4."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv2 = DCNV4_YOLO(c_, c2, k[1])
class C3k2_DCNv4(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck_DCNV4(self.c, self.c) for _ in range(n)
)详见:
https://blog.csdn.net/m0_63774211/article/details/1493884153.5 yolov13-C3k2_DCNv4.yaml
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov13n.yaml' will call yolov13.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # Nano
s: [0.50, 0.50, 1024] # Small
l: [1.00, 1.00, 512] # Large
x: [1.00, 1.50, 512] # Extra Large
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2, 1, 2]] # 1-P2/4
- [-1, 2, C3k2_DCNv4, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2, 1, 4]] # 3-P3/8
- [-1, 2, C3k2_DCNv4, [512, False, 0.25]]
- [-1, 1, DSConv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, DSConv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
head:
- [[4, 6, 8], 2, HyperACE, [512, 8, True, True, 0.5, 1, "both"]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [ 9, 1, DownsampleConv, []]
- [[6, 9], 1, FullPAD_Tunnel, []] #12
- [[4, 10], 1, FullPAD_Tunnel, []] #13
- [[8, 11], 1, FullPAD_Tunnel, []] #14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 12], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2_DCNv4, [512, True]] # 17
- [[-1, 9], 1, FullPAD_Tunnel, []] #18
- [17, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 13], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2_DCNv4, [256, True]] # 21
- [10, 1, Conv, [256, 1, 1]]
- [[21, 22], 1, FullPAD_Tunnel, []] #23
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 18], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2_DCNv4, [512, True]] # 26
- [[-1, 9], 1, FullPAD_Tunnel, []]
- [26, 1, Conv, [512, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2_DCNv4, [1024,True]] # 30 (P5/32-large)
- [[-1, 11], 1, FullPAD_Tunnel, []]
- [[23, 27, 31], 1, Detect, [nc]] # Detect(P3, P4, P5)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号