【AI 进阶笔记】LSTM 理解
原创
【AI 进阶笔记】LSTM 理解
原创
繁依Fanyi
修改于 2025-04-10 00:02:53
修改于 2025-04-10 00:02:53
🍵 前言
在神经网络的世界里,RNN(循环神经网络)曾经是处理时序数据的大哥大。但有个致命问题——它记不住事儿!
我们来个生活场景模拟:
你刚吃了一口火锅,过了十分钟,有人问你“刚才那口啥味儿?”,你摇摇头:“???我忘了”。 这就是标准的 RNN 状态。短期记忆有点能力,但长期记忆?对不起,我是条金鱼。

于是 LSTM 横空出世,它是 RNN 家族里的“记忆大师”。今天,我们就来拆解一下这位传说中能记忆上千步的“学霸型”结构是如何一步步登上历史舞台的。
🧠 第一章:RNN 究竟是哪儿不行了?
什么是 RNN?
RNN 的设计初衷是为了处理“序列信息”。比如一句话、一个时间序列、一个音频片段。它的核心逻辑就是“每一步的输出依赖于前一步的隐藏状态”。
输入:
x1, x2, x3, ..., xnundefined输出:y1, y2, y3, ..., yn
每个时刻的隐藏状态是这样计算的:
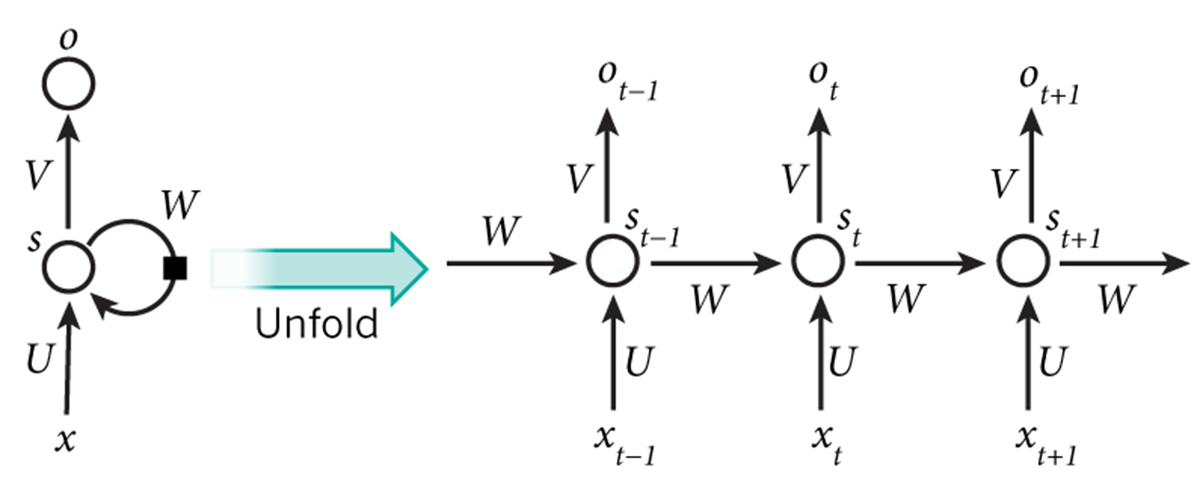
RNN 最大的问题:梯度消失 or 爆炸
在反向传播时,RNN 的链式求导机制导致:
- 如果权重小于 1,会导致梯度越来越小 → 梯度消失
- 如果权重大于 1,会导致梯度爆炸
这就像是你在询问一个老人 50 年前的记忆,结果发现人家只记得“早上吃了鸡蛋”,其他的随时间都消失没了。
🔁 第二章:LSTM 的逆袭之路
LSTM(Long Short-Term Memory)是 Hochreiter 和 Schmidhuber 在 1997 年提出的改进 RNN 的结构。它的最大亮点在于引入了三个门结构 + 一个记忆单元,从而解决了“记不住”的问题。
📦 LSTM 的内部结构全家福:
LSTM 的内部结构可以拆解成以下几个部分:
- 遗忘门 forget gate
- 输入门 input gate
- 候选记忆单元 candidate
- 输出门 output gate
公式如下:
f_t = σ(W_f * [h_{t-1}, x_t] + b_f) # 遗忘门
i_t = σ(W_i * [h_{t-1}, x_t] + b_i) # 输入门
ĉ_t = tanh(W_c * [h_{t-1}, x_t] + b_c) # 候选记忆
c_t = f_t * c_{t-1} + i_t * ĉ_t # 更新记忆
o_t = σ(W_o * [h_{t-1}, x_t] + b_o) # 输出门
h_t = o_t * tanh(c_t) # 最终隐藏状态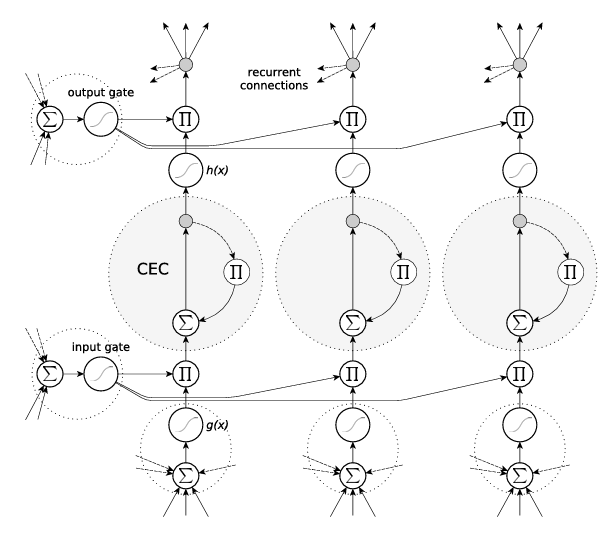
我们逐个拆开讲:
🔓 第三章:“门机制”简解
✂️ 遗忘门 forget gate
作用:决定当前时刻保留多少“旧记忆”
比方说你在复习考研,一年前背的知识点要不要扔掉?遗忘门决定:
f_t = sigmoid(...)如果 f_t=0,完全丢弃;如果 f_t=1,完全保留。
🧾 输入门 input gate + 候选记忆单元
作用:决定当前“新知识”写入多少
你刚刚学习了个新知识点,系统得判断“写还是不写”。
i_t = sigmoid(...)
ĉ_t = tanh(...)新的记忆候选值是 ĉ_t,然后由 i_t 决定写入比例。
🧠 更新记忆单元 c_t
结合遗忘旧的 + 添加新的:
c_t = f_t * c_{t-1} + i_t * ĉ_t这个 c_t 是整个网络的核心——长时记忆核心单元。
📣 输出门 output gate
作用:控制最终输出什么信息给下一个时间步
o_t = sigmoid(...)
h_t = o_t * tanh(c_t)隐藏状态 h_t 是网络的“发声部分”,告诉下一个 LSTM 当前的理解结果。
🔨 第四章:用 PyTorch 实现 LSTM
我们来写个最小实现的 LSTM 版本(字符级文本预测例子):
安装依赖(如果你还没装 PyTorch):
pip install torch构建数据
我们用一句经典台词:
text = "hello pytorch"
chars = list(set(text))
char2idx = {ch: i for i, ch in enumerate(chars)}
idx2char = {i: ch for ch, i in char2idx.items()}LSTM 模型定义
import torch
import torch.nn as nn
class MyLSTM(nn.Module):
def __init__(self, vocab_size, hidden_size):
super(MyLSTM, self).__init__()
self.embed = nn.Embedding(vocab_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x):
x = self.embed(x)
out, _ = self.lstm(x)
out = self.fc(out)
return out是不是感觉比前面讲的复杂好多?但别慌,这其实是 PyTorch 帮我们把那一坨公式都封装好了。
训练模型
model = MyLSTM(len(chars), 128)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)接下来就是标准的训练循环,每轮预测下一个字符,然后回传误差,更新参数。
🔬 第五章:理解 LSTM 的神奇之处
你会发现:
- LSTM 会“记住”前面出现的字符,哪怕间隔较远
- 随着训练次数的增加,模型对未来字符的预测越来越准
- 如果换成普通 RNN,基本学不会太远的依赖(比如前几个字符的信息)
对比项目 | RNN | LSTM |
|---|---|---|
记忆能力 | 容易遗忘过去信息 | 通过门机制长期保留重要信息 |
梯度问题 | 容易梯度消失/爆炸 | 控制式的反向传播,更稳定 |
表达能力 | 难以捕捉长期依赖 | 可以学会远距离依赖(如翻译任务中的主谓一致) |
模型复杂度 | 相对较小 | 多门结构导致参数更多,计算更复杂 |
LSTM 并不是 “记得越多越好”,它的目标是:保留重要信息,丢掉冗余内容。
这点和人的大脑很像:
高效的学习不在于记住每一个细节,而在于记住对未来决策有用的结构性信息。
所以,门机制的核心就是一种信息筛选机制。
希望这篇文章对你有所帮助!下次见!🚀
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号