LLMOps实战(三):浅谈幻觉的产生机制与避免策略
原创

一、幻觉的本质:概率输出的“失控猜测”
- 核心原因: Transformer的概率输出机制(如softmax生成词汇表概率)可能导致模型在信息缺失或矛盾时,基于训练数据的统计规律生成看似合理但违背事实的内容。 接上一篇例子继续,幻觉如同导游在游客未明确说明行程时,根据常见路线“编造”景点信息(如“这条路线经过的雪山叫‘玉龙雪山’”),但实际可能不存在。
- tips:这篇文章重在理解 transformer 的框架下本就是概率输出,意味着你无论用什么方法调试优化,只能降低幻觉产生的概率,并不能杜绝,“transformer”总会有自己想法“不经推敲的假想意识”,在实际生产中一定要认识到这一点,只能放在你的业务能够接受“幻觉”程度的能力范围内使用,而你的调试就是在降低幻觉到你的业务能够接受范围,也并不是说 transformer 不好,人本身在各自的认知层次中也会出现不经推敲的异想中,如:八卦新闻,有多少未经证实被捏造引发舆论,读者被带节奏(内心更容易接受八卦结果→人性),而这种“幻觉”披上“自主意识”不加控制,后果是不可想象的,善用。
二、什么是幻觉?
1、 上下文矛盾→上一个段落说喜欢,下一个段落说不喜欢;
2、 与问题要求不一致→上海有什么美食?东京寿司之神店铺!
3、与事实矛盾→ 企鹅生活在北极,它们穿着羽绒服保暖;
4、荒谬回复→人是狗,狗可以飞;
三、为什么会产生幻觉?
1、数据噪声,网上一些不靠谱,未经事实验证的文章,比如某健康类文章错误声称 "吃香蕉能治抑郁症",模型可能在相关对话中重复这一错误,又比如 5 天云南旅游某攻略错误标注石林景区溶洞开放时间为全年无休,实际因地质维护每年 11 月闭馆。游客按过时信息安排行程,导致当日无法参观核心景点→这也是 rag 出现的必要性。
2、数据缺乏多样性,知识出现盲区,当问题涉及模型未接触过的领域时,会通过 "逻辑拼接" 生成看似合理的错误内容,旅游攻略未收录 2025 年新增的「洱海生态科普馆」,游客错失近距离观察高原湖泊生态系统的机会,仍沿用旧版行程中重复的环湖路线。
3、大模型 rag 过程中,出现过渡拟合陷阱,过度优化训练数据导致模型 "死记硬背" 特定模式。比如云南穷游 5 天,模型过度依赖 "穷游必去清单",行程重复安排大理床单厂艺术区、昆明创库艺术区等同类免费展览。
4、生成过程,自回归生成方式导致错误累积,比如自回归生成优先满足 "低价" 标签,忽视生理健康需求,为凑满 5 天,将昆明→大理→丽江的跨城交通全部安排为凌晨大巴(票价 50 元),导致游客连续三天睡眠不足 4 小时。
5、prompt工程,不够明确,比如,推荐 1500 穷游云南 5 天, 将 "预算" 理解为纯交通 + 住宿费用,未包含餐饮和门票,推荐夜卧大巴(300 元)+ 青旅(200 元),但实际需额外支付苍山门票(40 元)、玉龙雪山进山费(100 元)等刚性支出,实际应该在提示词中涉及预算规划要包含交通、住宿、餐饮、门票,不含购物。
6、没有微调,未经过专业领域微调做预训练的通用模型存在知识断层,比如没有针对高原环境调整行程,将玉龙雪山登顶安排在下午 3 点,此时氧气含量较低且常有云雾遮挡,最佳观赏时段实为日出后 2 小时内→引入微调模型。
这里不得不插播一下 deepseek MoE 的🐂🍺之处
四、 DeepSeek与GPT 架构的区别
1、单向自回归的本质缺陷
核心机制: Transformer解码器采用自回归生成方式,即逐词生成时仅依赖已生成内容,无法全局调整。具体表现:
- 时序依赖固化:生成第N个token时,模型只能基于前N-1个token的隐藏状态进行预测,无法像人类规划行程时反复调整整体逻辑;
- 信息熵累积偏差:早期生成错误会通过注意力机制持续影响后续内容;
- 长程依赖断裂:当生成序列超过模型窗口限制时(如生成 5 天行程的细节),模型无法回溯调整前3天的路线规划;
2、DeepSeek的架构创新
混合专家模型(MoE):
- 细粒度专家划分:将传统FFN拆分为256个微型专家,每个专家专注特定任务(如"高海拔徒步装备建议" vs "古城文化解读");
- 共享专家机制:设置1个全局共享专家处理共性知识(如云南气候特征),与8个路由专家动态组合,解决传统MoE负载不均衡问题;
- 无偏置路由网络:引入可学习偏置项动态调整专家选择概率,避免"雨崩村向导推荐"等关键信息被低频专家遗漏;
五、降低幻觉的方式
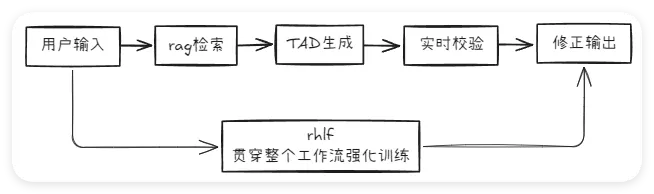
实现基本流程:
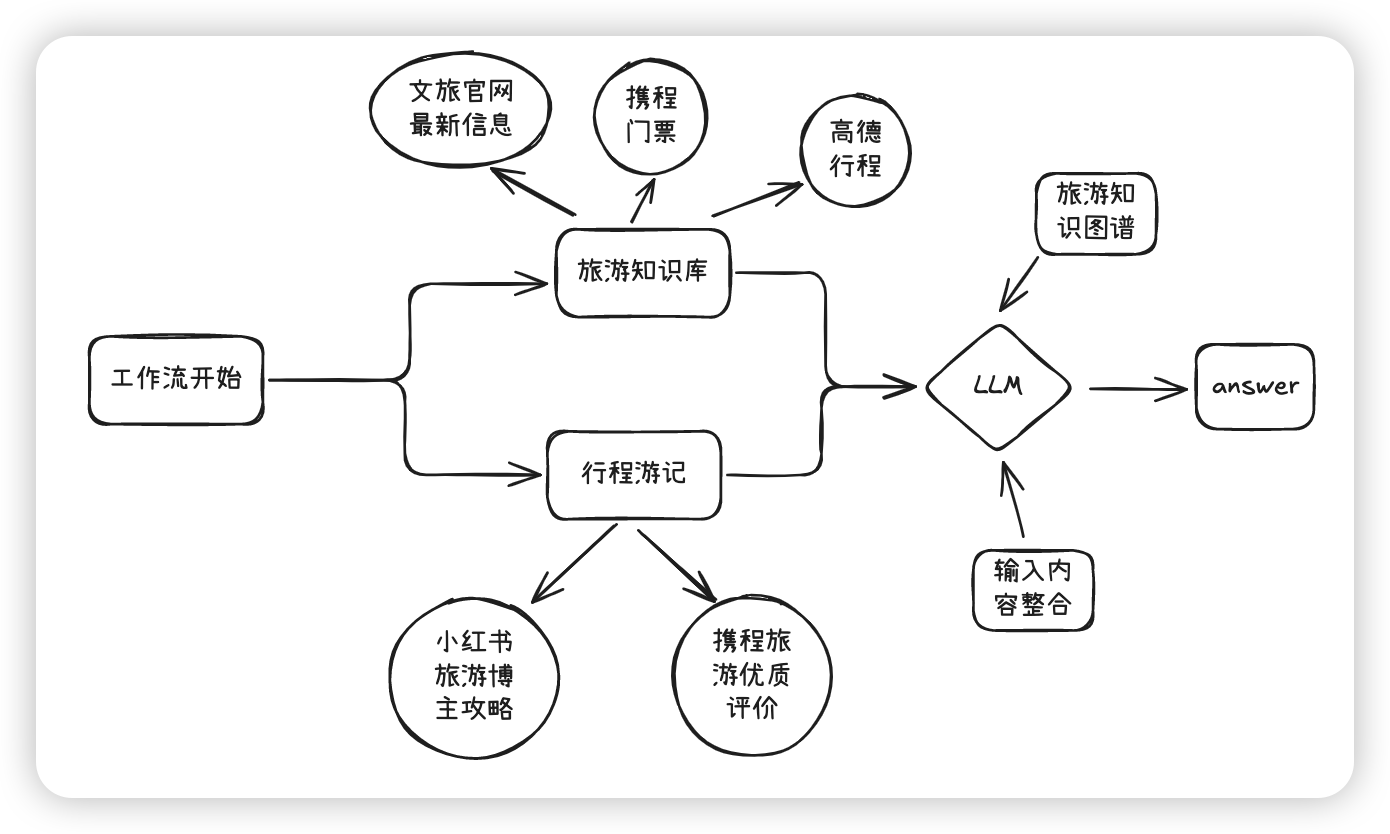
构建思路:
1、rag 工作流架构设计
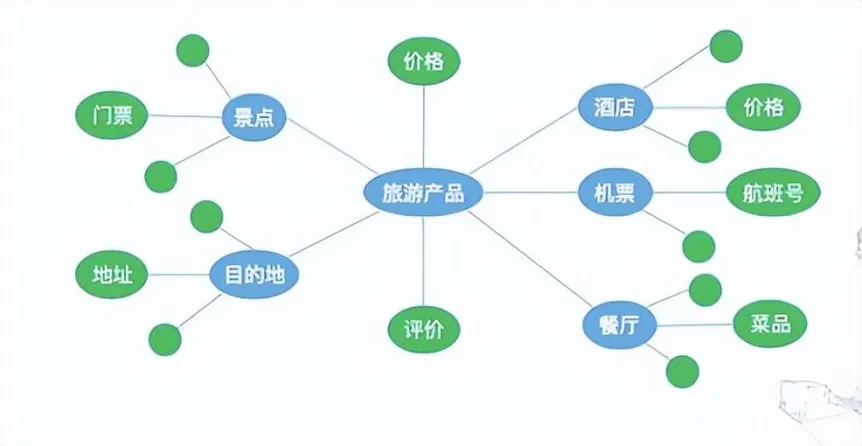
- 知识增强:建立云南旅游知识库(本地没有知识库可以通过联网检索插件、爬虫插件等),整合云南省文旅厅官网、携程 / 飞猪获取实时价格、高德地图通勤时间等权威数据源,过滤低质数据,接入旅游知识图谱,当生成"洱海生态廊道"时自动关联"自行车租赁点位置",丰富知识库检索半径。
- 检索增强:辅助获取一些小红书、旅游评价等插件检索最近3个月的真实用户游记,确保一些近期新增的旅游项目,如"沙溪古镇周五赶集"等动态信息准确,以及丰富内容多样性。
2、注意力机制优化
- 位置感知注意力:在处理"大理古城→喜洲古镇"交通时,强制关注"15元/人"的公交价格而非虚构的"免费接驳车"
- 事实锚定模块:对预算、时间等关键数值添加特殊标记,避免生成"日均消费200元"却包含300元门票的矛盾
3、强化学习(RLHF)
- 方法:引入三阶段训练:监督学习→奖励模型→策略优化。
- 奖励模型训练:训练一个奖励模型(Reward Model),该模型能够模拟人类判断,自动为模型输出生成奖励值。
- 使用近端策略优化(PPO)等算法,根据奖励模型的反馈调整模型参数,持续优化生成结果。例如,在生成旅行计划时,模型通过奖励信号学习如何让内容更丰富,更贴合用户需求。
上述分享内容,皆是我在实践中沉淀而来的心得。关于具体操作方法,我会专门撰写一期文章进行详细的实操讲解,助力大家更好地掌握。最近在做项目,文章更新会慢一些,倘若在这期间,大家遇到任何疑问,欢迎随时与我单独沟通交流。咱们共同探讨、携手学习,在前行的道路上持续成长与进步 。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号