C语言——编译和链接


前言
在ANSIC的任何⼀种实现中,存在两个不同的环境:编译环境和执行环境。
编译环境:C语言代码对于我们程序员来说是易于识别和理解的,但对于计算机来说就是天书。所以需要在编译环境下将我们的代码翻译为计算机能读懂的机器指令(二进制指令)。 执行环境:在此环境下,运行代码生成的可执行程序。
编译环境
而我们今天讲的编译与链接就是发生在编译环境下。
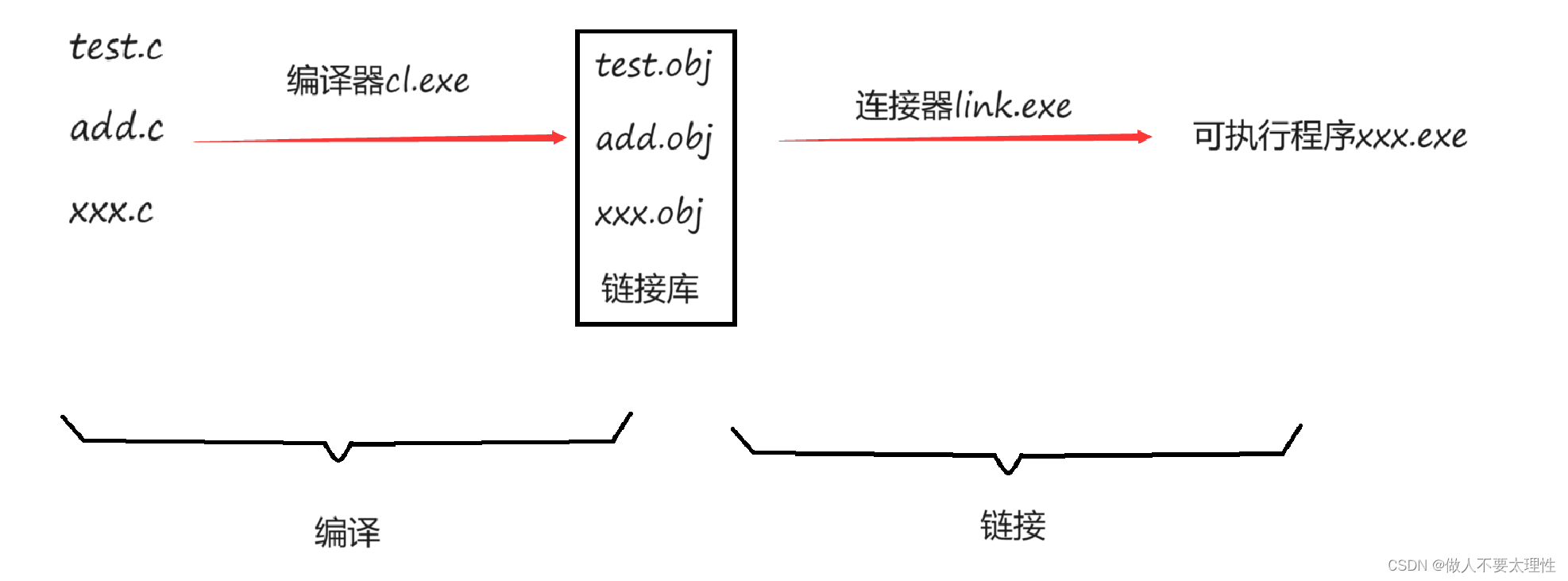
- 在一个项目中可能有多个.c的源文件,多个.c文件单独经过编译器,编译处理后生成目标文件。(在Windows环境下的目标文件的后缀是 .obj ,Linux环境下目标文件的后缀是.o)
- 多个目标文件和链接库一起经过链接器处理后生成可执行程序。
(链接库是指运行时库(它是支持程序运行的基本函数集合)或者第三方库。)
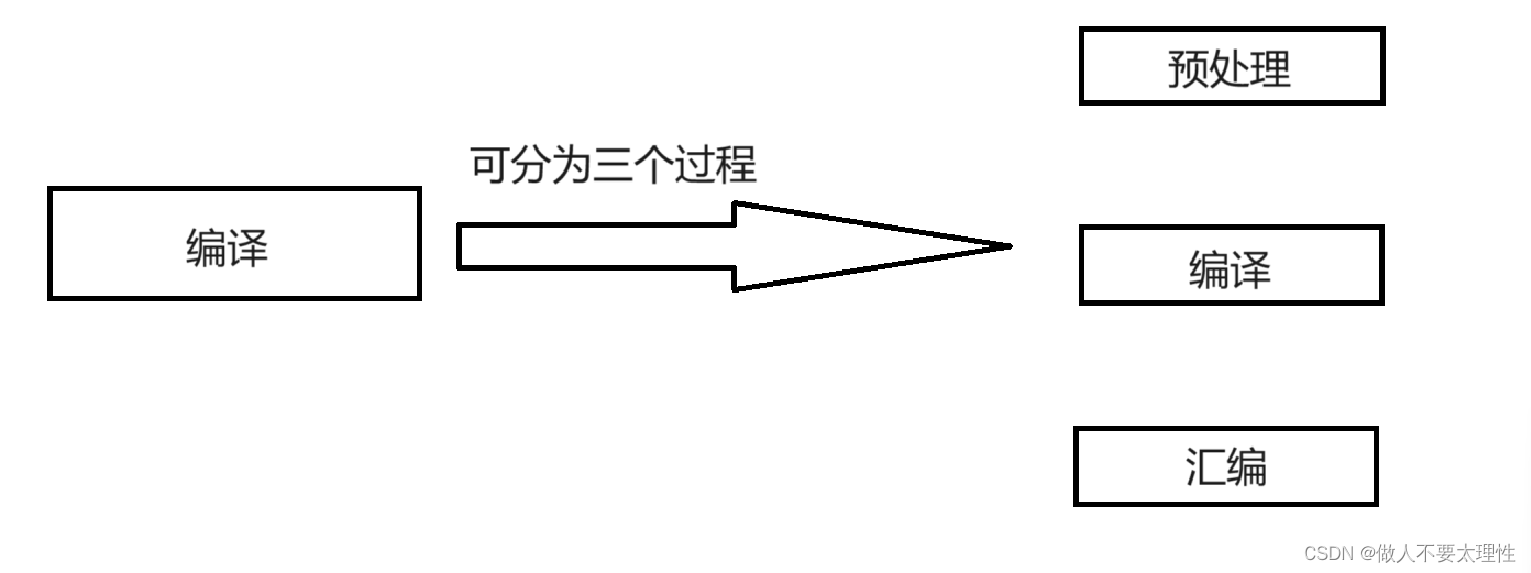
编译
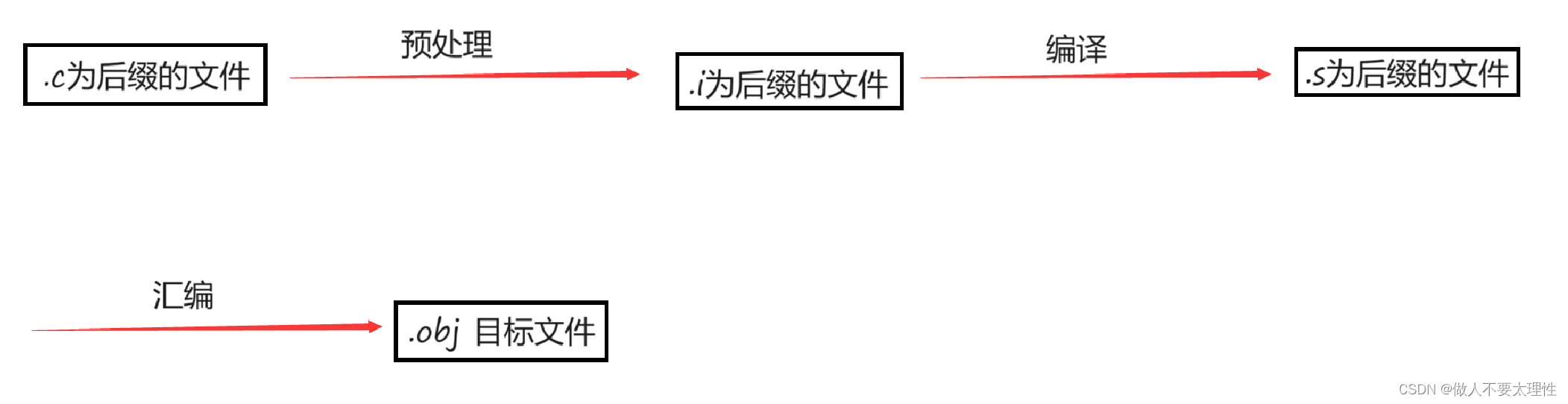
编译又可拆分为3个过程:预处理、编译、汇编
预处理
在预处理阶段,源文件和头文件会被处理成为.i为后缀的文件。
此阶段主要处理那些源文件中#开始的预编译指令。
• 将所有的 #define 删除,并展开所有的宏定义。 • 处理所有的条件编译指令,如: #if 、#ifdef 、#elif 、#else 、#endif 。 • 处理#include预编译指令,将包含的头文件的内容插入到该预编译指令的位置。这个过程是递归进行的,也就是说被包含的头文件也可能包含其他文件。 • 删除所有的注释 • 添加行号和文件名标识,方便后续编译器生成调试信息等。 • 或保留所有的#pragma的编译器指令,编译器后续会使用。
经过预处理后的.i文件中不再包含宏定义。并且包含的头文件都被插入到.i文件中。
所以当我们无法知道宏定义或者头文件是否包含正确的时候,可以查看预处理后的.i⽂件来确认。
编译
此过程就是将预处理后的.i⽂件进行一系列的:词法分析、语法分析、语义分析及优化,生成相应的汇编代码文件。
编译过程的命令:gcc -S test.i -o test.s
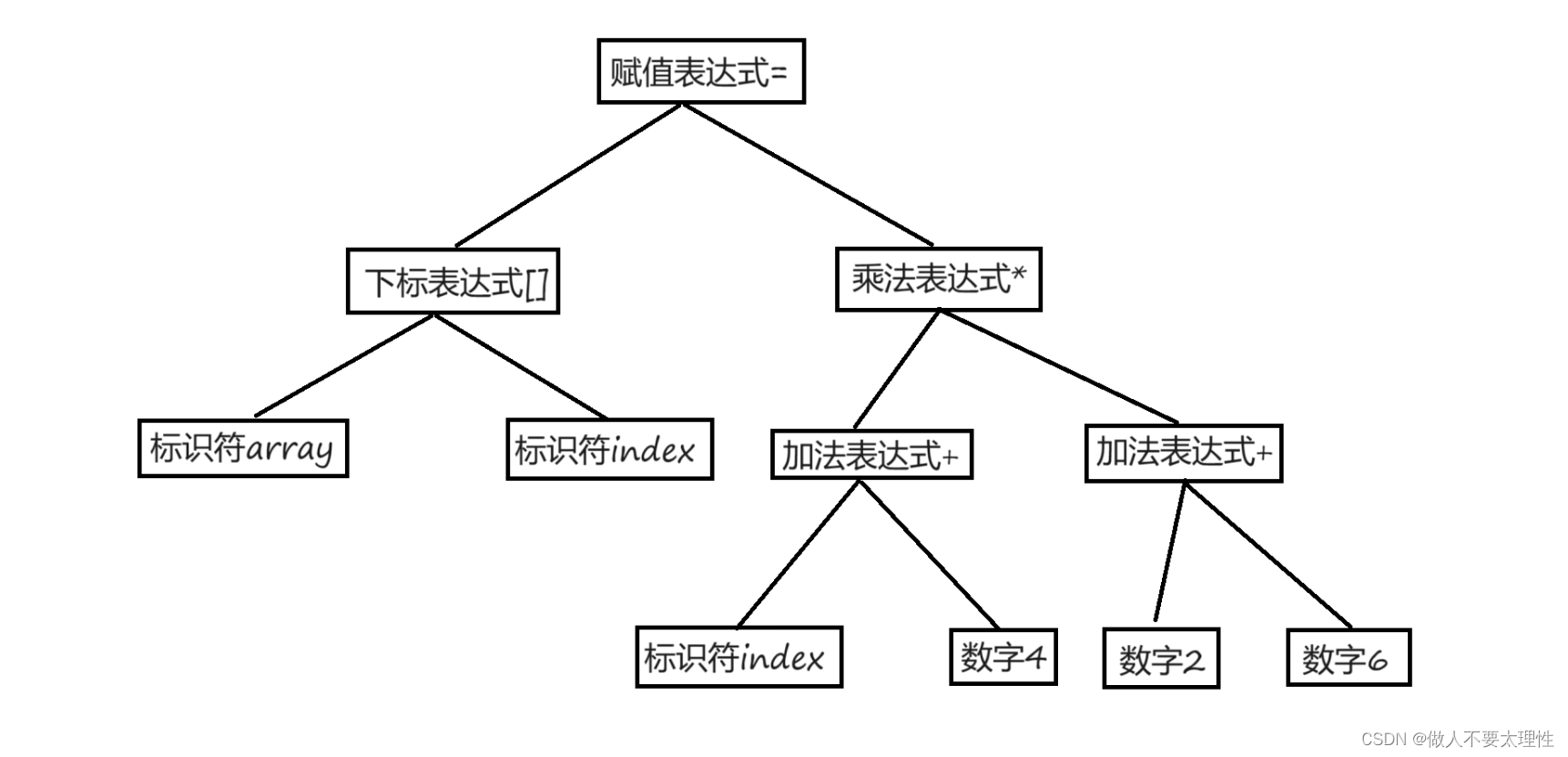
对于下面的代码进行编译会怎么做?
array[index] = (index+4)*(2+6);
词法分析
将源代码程序被输入扫描器,扫描器进行简单的词法分析,把代码中的字符分割成⼀系列的记号(关键字、标识符、字⾯量、特殊字符等)。
对上面的例子进行词法分析后得到16个记号:

语法分析
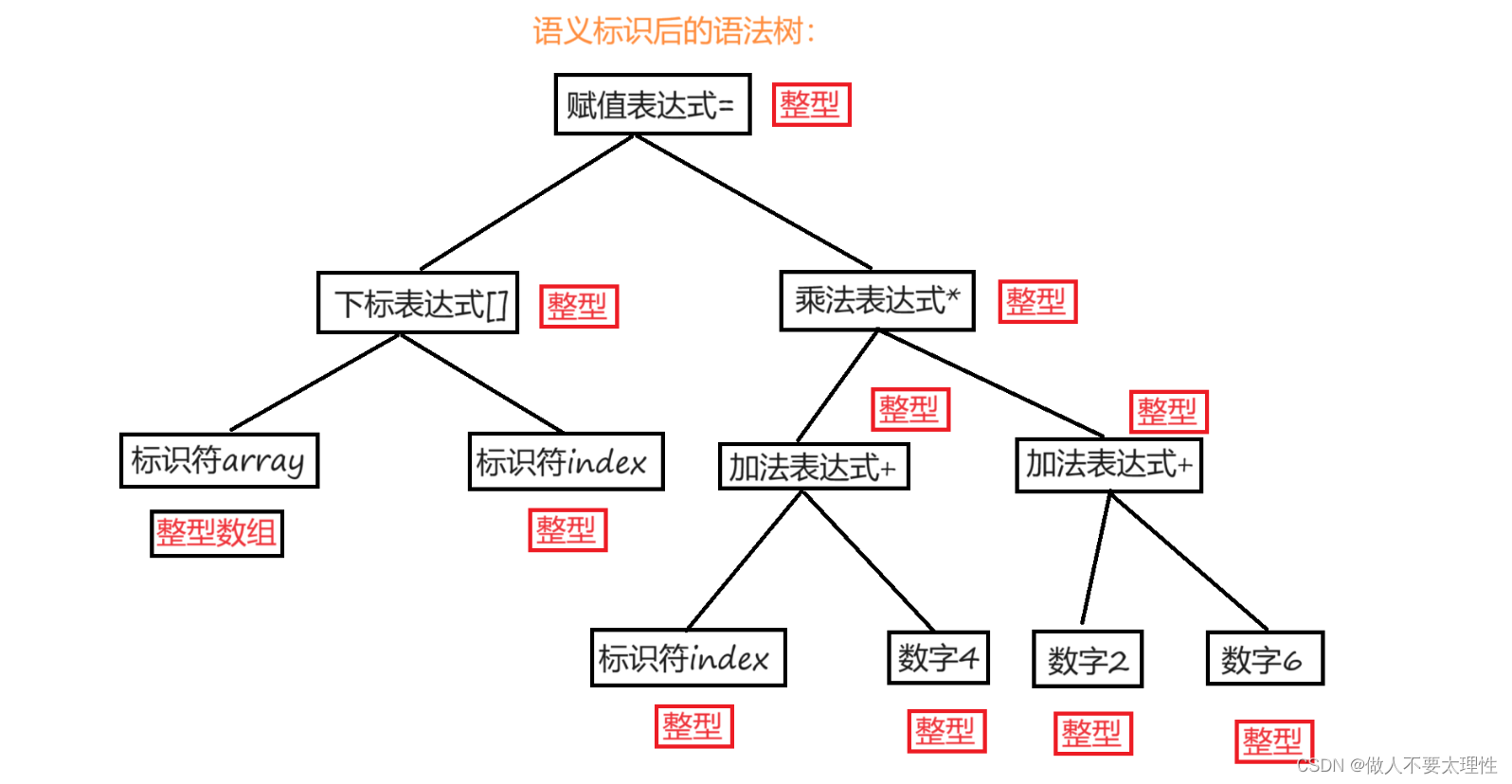
接下来就是经过语法分析器处理,将对扫描产生的记号进行语法分析,从而产生语法树。这些语法树是以表达式为节点的树。
语法树:
词义分析
由语义分析器来完成语义分析,即对表达式的语法层面分析。
编译器所能做的分析是语义的静态分析。
静态语义分析通常包括声明和类型的匹配,类型的转换等。这个阶段会报告错误的语法信息。
汇编
汇编器将汇编代码转变成机器指令(二进制指令),每⼀个汇编语句几乎都对应⼀条机器指令。
就是根据汇编指令和机器指令的对照表⼀⼀的进行翻译,也不做指令优化。
汇编的命令如下:gcc -c test.s -o test.o
链接
我们的源代码经过编译以后,生成目标文件(.obj)的中间文件(临时文件)。
目标文件也是二进制形式的,它和可执行文件的格式是一样的。
编译将我们写的代码转变成二进制形式,它还要需要和系统组件(比如标准库、动态链接库等)结合起来,这些组件都是程序运行所必须的。
链接其实就是由连接器(link.exe) “ 打包” 的过程,它将所有二进制形式的目标文件和系统组件合成一个可执行文件。
(编译是针对一个源文件的,有多少个源文件就要编译多少次,就会生成多少个目标文件。)
运行环境
1. 程序必须载入内存中。在有操作系统的环境中:⼀般这个由操作系统完成。在独立的环境中,程序的载入必须由手动安排,也可能是通过可执行代码置入只读内存来完成。 2. 程序的开始执行,调用main函数。 3. 开始执行程序代码。这个时候程序将使用⼀个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。 4. 终止程序。正常终止main函数;也有可能是意外终止。
有缘再会,拜拜!
摸鱼摸鱼😴✨🎞

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-05-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号