基于RotatE模型的知识图谱嵌入技术
原创

知识图谱(Knowledge Graph, KG)是一种以图结构形式表示的知识库,通常用于表示实体(如人、地点、物品)及其之间的关系。知识图谱的应用遍及搜索引擎、推荐系统、问答系统等多个领域。随着大数据技术的发展,知识图谱的规模迅速扩大,导致传统的知识表示方法面临挑战。
知识图谱嵌入(Knowledge Graph Embedding, KGE)技术通过将图中实体和关系映射到低维连续向量空间,允许使用向量运算来捕捉实体间的复杂关系。近年来,RotatE模型作为一种新颖的知识图谱嵌入方法,因其有效的相位信息建模能力而受到广泛关注。
RotatE模型将关系建模为复数空间中的旋转,从而实现对关系的丰富表达。
RotatE模型的原理
模型概述
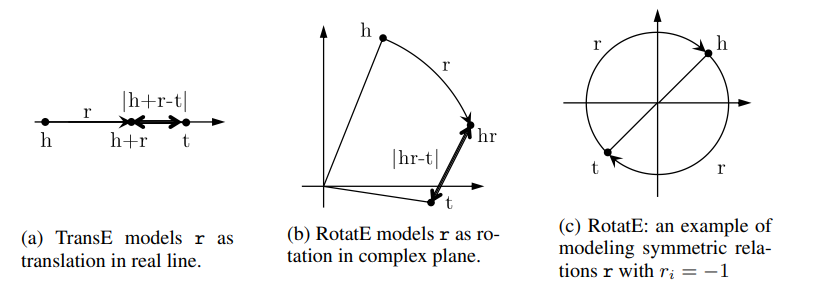
RotatE模型是一种基于复数空间的知识图谱嵌入方法,提出了将关系表示为复数空间中的旋转。该模型的基本思想是:通过将头实体向量绕关系的相位进行旋转,来生成尾实体向量。
特征 | 描述 |
|---|---|
实体表示 | 实体通过低维向量表示,存储在嵌入矩阵中。 |
关系表示 | 每个关系通过一个复数向量表示,复数向量的模长为1。 |
旋转机制 | 关系通过相位(角度)来控制实体之间的关系,旋转操作由复数乘法实现。 |
公式推导
在RotatE模型中,对于每个三元组 (h, r, t) (头实体h、关系r、尾实体t),关系r被表示为一个复数 r = e^{i\theta_r} ,其中 `$\theta_r) 为关系的相位。
头实体h和尾实体t的嵌入表示为 \mathbf{h} 和 \mathbf{t} 。模型的目标是最小化以下损失函数:
L = \sum_{(h, r, t) \in \text{train}} \sum_{(h', r, t') \in \text{neg}} \max(0, \gamma + f(h, r, t) - f(h', r, t'))
其中, f(h, r, t) = || \mathbf{h} \odot r - \mathbf{t} || 是头实体经过旋转后的向量与尾实体向量之间的距离。
模型优势
- 复杂关系建模:RotatE能够捕捉到关系间的方向信息,适合建模多种复杂关系。
- 高效性:在计算上,复数乘法操作比传统的向量运算更为高效,特别是在大规模知识图谱中。
RotatE模型的代码实现
本节将介绍如何实现RotatE模型,包括数据准备、模型构建及训练过程。我们将使用Python和PyTorch框架进行实现。
环境准备
确保安装了必要的库:
pip install torch numpy数据集准备
我们将使用一个简单的知识图谱数据集,假设其包含实体和关系的三元组数据。
import numpy as np
# 定义实体和关系
entities = {'UserA': 0, 'MovieB': 1, 'DirectorC': 2, 'ActorD': 3}
relations = {'likes': 0, 'directed_by': 1, 'acted_in': 2}
# 三元组数据
triples = [
('UserA', 'likes', 'MovieB'),
('MovieB', 'directed_by', 'DirectorC'),
('DirectorC', 'acted_in', 'ActorD')
]
# 将三元组转换为索引
triples_idx = [(entities[h], relations[r], entities[t]) for h, r, t in triples]RotatE模型实现
import torch
import torch.nn as nn
class RotatE(nn.Module):
def __init__(self, num_entities, num_relations, embedding_dim):
super(RotatE, self).__init__()
self.entity_embeddings = nn.Embedding(num_entities, embedding_dim)
self.relation_embeddings = nn.Embedding(num_relations, embedding_dim)
# 初始化嵌入
nn.init.xavier_uniform_(self.entity_embeddings.weight.data)
nn.init.xavier_uniform_(self.relation_embeddings.weight.data)
def forward(self, heads, relations, tails):
# 获取实体和关系嵌入
head_emb = self.entity_embeddings(heads)
relation_emb = self.relation_embeddings(relations)
tail_emb = self.entity_embeddings(tails)
# 将关系嵌入转换为复数表示
relation_emb_real = torch.cos(relation_emb)
relation_emb_imag = torch.sin(relation_emb)
# 计算旋转后的头实体向量
rotated_head = head_emb * relation_emb_real + head_emb * relation_emb_imag * 1j
# 计算尾实体向量的复数形式
tail_complex = tail_emb[:, 0] + tail_emb[:, 1] * 1j
# 计算距离
distance = torch.norm(rotated_head - tail_complex, dim=1)
return distance在上述代码中,RotatE类实现了RotatE模型,使用复数形式进行关系的表示。每个关系的嵌入通过正弦和余弦函数进行复数化处理。
训练模型
# 定义损失函数
def loss_fn(predictions, labels):
return torch.mean(torch.clamp(predictions - labels, min=0))
# 创建训练数据
heads = torch.tensor([h for h, r, t in triples_idx])
relations = torch.tensor([r for h, r, t in triples_idx])
tails = torch.tensor([t for h, r, t in triples_idx])
# 定义模型
model = RotatE(num_entities=len(entities), num_relations=len(relations), embedding_dim=50)
# 模拟训练过程
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 训练轮数
for epoch in range(100):
optimizer.zero_grad()
# 获取模型预测
predictions = model(heads, relations, tails)
# 使用随机生成的负样本
labels = torch.zeros_like(predictions) # 正样本标签
loss = loss_fn(predictions, labels)
# 反向传播
loss.backward()
optimizer.step()
print(f'Epoch {epoch}, Loss: {loss.item()}')在训练过程中,我们使用了随机生成的负样本以促进模型的学习,使用的损失函数为简单的阈值损失。
实例分析
在推荐系统的应用中,RotatE模型通过捕捉用户和项目之间的复杂关系,能够有效地提升推荐的准确性。例如,用户A喜欢电影B,而电影B由导演C执导,那么RotatE模型能够推测出用户A可能还会喜欢其他由导演C执导的电影。
这种基于关系推理的推荐方法可以显著提高用户的满意度,特别是在处理用户历史行为稀疏的情况下,RotatE模型能够利用图结构中的相似性信息进行有效推理。
RotatE模型在知识图谱嵌入技术中展现出良好的性能,但仍有进一步发展的空间:
- 更复杂的关系建模
- 多模态信息整合:当前知识图谱嵌入方法主要关注结构化数据,但现实世界中的信息往往是多模态的。通过将文本(如实体描述、关系说明)和图像(如实体的图片)等非结构化数据与知识图谱嵌入结合,可以捕捉更丰富的语义信息。例如,可以使用深度学习技术(如卷积神经网络)从图像中提取特征,并将这些特征与RotatE模型生成的嵌入向量进行融合,从而提升模型对复杂关系的理解能力。
- 跨领域知识图谱:在不同领域(如医疗、社交网络、电子商务等)中,实体和关系的性质可能有所不同。通过在RotatE模型中引入领域特定的嵌入方式,可以增强模型在特定领域内的推理能力,从而实现更准确的推荐和查询。
- 高效的计算方法
- 大规模知识图谱的训练:随着知识图谱规模的不断扩大,传统的训练方法可能无法满足效率要求。为此,研究人员可以探索分布式计算和并行处理的方法,将训练任务分散到多个计算节点上,以加速训练过程。
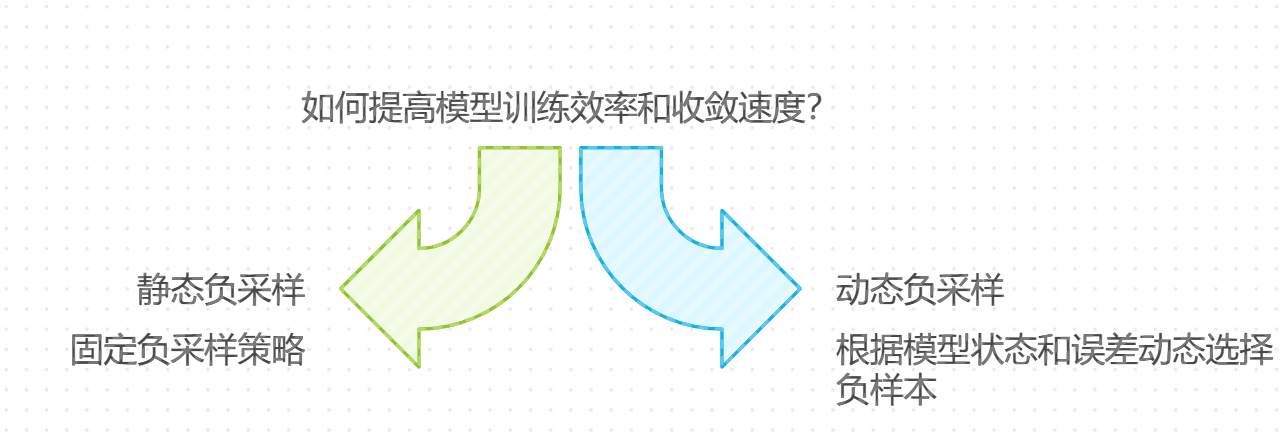
- 动态负采样:在训练过程中,负样本的选择对模型的学习至关重要。通过引入动态负采样策略,即根据当前模型的状态和误差动态选择负样本,可以更有效地训练模型并提高收敛速度。
- 模型压缩与加速:随着模型规模的增大,计算和存储成本也显著增加。可以通过量化、剪枝等技术来实现模型的压缩与加速,从而在保证模型性能的前提下,提高运行效率。
- 模型扩展
- 与图神经网络结合:RotatE模型可以与图神经网络(GNN)结合,进一步增强推理能力。图神经网络能够有效捕捉图结构中的局部信息,而RotatE模型擅长捕捉关系间的全局信息。通过将二者结合,可以实现更深层次的特征学习,进而提高对复杂关系的推理能力。
- 多任务学习:通过设计多任务学习框架,RotatE模型可以同时解决多个任务,如知识图谱补全、关系分类等。这种方法不仅可以提高模型的泛化能力,还能通过任务间的知识共享提升整体性能。
- 自适应学习机制:引入自适应机制,使模型能够根据输入数据的特点动态调整学习策略。例如,可以设计基于注意力机制的嵌入方式,使模型能够自动关注重要的实体和关系,从而优化推理过程。
基于RotatE模型的知识图谱嵌入技术为复杂关系建模提供了一种有效的方法。通过本文的理论介绍、代码实现和实例分析,读者可以深入理解RotatE模型的原理和实际应用方式。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号